一、推荐系统流程
典型的推荐系统包括3个部分,即召回层( Recall )、排序层( Rank )和重排层( ReRank )。
1.召回层( Recall )
召回层主要是从全量库中首先获取用户可能感兴趣的候选集,是推荐系统的基础。从业务角度而言,召回层是在准备后续可能满足用户需求的候选集。很多内容分发产品的召回层,一次会召回10000~50000条用户可能感兴趣的内容,后续再从这些内容中挑选出用户可能点击和购买的内容。
召回层有两个最著名的推荐算法﹣- CF 和 CB ,即协同过滤和基于内容召回。
CF ,协同过滤,当要为用户 A 做推荐时,先找到和用户 A 有相似兴趣的其他用户,然后把那些用户喜欢的而用户 A 未浏览过的作为候选集;
CB ,基于内容召回,给用户推荐那些和他们之前浏览或购买过的物品相似的物品。
这两种算法是经典的推荐算法,很多推荐系统搭建之初都会先用这两种算法做出基础推荐策略。但是这两种算法效果并不那么好, CF 是基于相似用户的共同兴趣来推荐,它的核心逻辑是"人以群分",辑上没问题,实施起来有点强人所难,毕竟没有兴趣完全一致的两个人; CF 在用户经营中最常见的字眼就是"其他用户也在看"“和您一样的用户也在买”。 CB 是基于相似内容来推荐,它的核心逻辑是"物以类聚",CB 适合高频消费场景,不适合中低频消费。
召回层还会设置兜底策略,即当推荐系统突然无法服务时,召回层将保留一条策略为用户提供热点和最新内容,保证用户层面始终有内容可看可用。当用户刷视频刷得开心时,突然发现连着几条甚至十几条都是相似视频,这种情景叫"跑火车",大概率是推荐系统出问题而触发了兜底策略。
2.排序层( Rank )
召回层中各个召回策略召回的原始数据之间并不具备可比性,无法在用户场景中应用。道理很简单,大家都一样,到底该推荐谁?所以需要在排序层中按照某种规则进行统一计算和排序。例如我的兴趣是汽车和娱乐,召回时会把汽车和娱乐视频一并召回,但用户兴趣是有权重的,即我对汽车的兴趣权重是0.97,对娱乐的兴趣权重是0.96,同时汽车视频的历史 CTR 为8%,娱乐视频的历史 CTR 为7.6%,那么在排序层将给汽车类视频更高的排序序列,同时将排序序列倒数的,即经过算法判断不太可能被用户点击的内容删除。所以在排序层会将召回层召回的1000050000条内容精简到100500条,可以认为排序后留下的都是用户最感兴趣的精华内容。
排序层也是推荐系统最为重要的层级,在推荐系统的策略运营中,绝大部分时间都是在优化和实验排序层策略。
如果说召回层和排序层是强调模型、算法和技术,那么重排层就是妥妥的业务运营最常打交道的地方。在重排层,重点是从用户体感出发,保证用户良好的体验,几乎不涉及模型、算法和技术。用户体感的含义是指重排层
3.重排层( ReRank )
用户也在看"“和您一样的用户也在买”。 CB 是基于相似内容来推荐,它的核心逻辑是"物以类聚",你看了手工耿的视频, CB 认为你也喜欢看和手工耿一样打造无用产品的视频,逻辑上没问题,放在短视频这样的内容分发上也没问题,可放到电商产品就不适合了。 CB 适合高频消费场景,不适合中低频消费。
召回层还会设置兜底策略,即当推荐系统突然无法服务时,召回层将保留一条策略为用户提供热点和最新内容,保证用户层面始终有内容可看可用。当用户刷视频刷得开心时,突然发现连着几条甚至十几条都是相似视频,这种情景叫"跑火车",大概率是推荐系统出问题而触发了兜底策略。
2.排序层( Rank )
召回层中各个召回策略召回的原始数据之间并不具备可比性,无法在用户场景中应用。道理很简单,大家都一样,到底该推荐谁?所以需要在排序层中按照某种规则进行统一计算和排序。例如我的兴趣是汽车和娱乐,召回时会把汽车和娱乐视频一并召回,但用户兴趣是有权重的,即我对汽车的兴趣权重是0.97,对娱乐的兴趣权重是0.96,同时汽车视频的历史 CTR 为8%,娱乐视频的历史 CTR 为7.6%,那么在排序层将给汽车类视频更高的排序序列,同时将排序序列倒数的,即经过算法判断不太可能被用户点击的内容删除。可以认为排序后留下的都是用户最感兴趣的精华内容。
排序层也是推荐系统最为重要的层级,在推荐系统的策略运营中,绝大部分时间都是在优化和实验排序层策略。
如果说召回层和排序层是强调模型、算法和技术,那么重排层就是妥妥的业务运营最常打交道的地方。在重排层,重点是从用户体感出发,保证用户良好的体验,几乎不涉及模型、算法和技术。用户体感的含义是指重排层
3.重排层( ReRank )
能够满足内容新颖性,尽可能推荐最新的、近期的内容,过滤掉用户浏览、购买、点赞过的内容,同时降低低频内容的权重;内容多样性,推荐策略是精准的,需要将相似内容打散,或人工插入其他内容,以及尽可能让用户每天看到不同的推荐结果。今天给用户推了苹果发布会上新品的内容,明天不仅适当减低这部分内容的推荐权重,同时还降低推荐数量。
二、四个常见的推荐运营场景
1.用户/内容冷启动
冷启动是推荐系统第一优先级需要解决的问题。推荐系统是基于用户行为等特征数据来判断用户兴趣继而进行精准推荐,可是当用户第1次进入产品,尚未有任何特征数据时,或内容第1次下发到用户,还未有任何点击数据可供参考时,理论上推荐系统是不会有任何作为的,与之矛盾的是此时又需要推荐系统能够让第1次进入产品的用户看到感兴趣的内容,并使第1次下发的内容可以让正确的用户看到,这种场景我们统称为用户冷启动和内容冷启动。
用户冷启动,即用户首触产品后,应当为其推荐感兴趣的内容,目的是提升留存和降低流失,但因此时用户特征数据空白,无法启动推荐策略,故常见两种解决方案:一是产品功能场景策略,用户首次打开产品后,引导用户补充完善其兴趣特征,大部分内容分发产品会让用户选择感兴趣内容的标签和分类,即兴趣预选,部分产品也会引导用户导入手机通讯录的好友联系方式,如果用户的通讯录好友已经是产品用户,则通过 CF 策略给用户推荐好友关注的内容。如果用户在兄弟产品已有特征数据,通过统一 ID 等将用户在兄弟产品的特征直接拿过来做推荐策略,某信息流产品的推荐策略会借用用户在其浏览器产品上的特征数据来完成冷启动。二是内容策略,如果用户彻彻底底以一张白纸进入产品,既没有选择感兴趣的标签和分类,也没有导入其他辅助判断信息,推荐系统将为用户推荐产品中大部分用户浏览、点击、评论的内容,一般推荐热点、时事、娱乐等,核心逻辑是"大部分人都喜欢看的你也可能喜欢看"。
内容冷启动,即新内容第1次下发时,应当推荐给感兴趣的用户,特别是对于 UGC 的内容冷启动尤为重要,否则 UGC 内容点击率低、流量低,会造成创作者的流失。和用户冷启动不同,内容冷启动相对复杂,其完整的流程和策略是:
■提取内容的标签等特征信息。
■按照标签匹配相应的用户群体,例如有100万人。
■将内容下发给这个用户群体中的一部分用户,即灰度下发,例如先给100万人中的10万人下发。
■灰度下发时评估核心指标, CTR 、 PV 、 UV 等。
■核心指标低于这个100万人客群的平均水平,则内容退场,冷启动结束。可以看出,内容冷启动的第1步,即选择冷启动客群非常重要,这个依赖于内容特征、用户特征,及标签的准确率、覆盖率和召回率。在很多 UGC 平台,创作者发布新内容时,可以明显感觉出推荐量或下发量是阶梯式增加的,有时候推荐量或下发量到几千或几万就不再增加,意味着内容在冷启动阶段被退场,可能被其他热点或更优质的内容 PK 下去,其中既有推荐信号的质量问题,也有内容是否优质的问题。
前文提过推荐系统的新颖性,故在部分产品中用户每次进入产品后进行下拉刷新操作时,前2~5次刷出的都是新内容场景,即内容冷启动场景。
2.槽位策略
槽位是推荐系统中 ReRank 层的术语,类似于产品运营中的楼层坑位。在 ReRank 层一般会给用户510条内容,即510个槽位,形象理解就是信息流产品。用户每次下拉刷新时,产品会提示"为您推荐了10条内容",然后会一次性给用户下发10条内容,就是10个槽位,每个槽位都有不同的流量权重和运营策略。
槽位是直接触达用户的重要场景,承担着活跃、留存、营收以及用户体验等重要职责,和楼层的营销布局一样,槽位也按区域划分职责和运营,如图所示。

槽位从区域上可以分为强兴趣区、弱兴趣区、热点区和兴趣探索区。强兴趣区,即强关联于用户的即时兴趣、短期兴趣和主兴趣内容,通常占40%50%的槽位,可以认为40%50%的流量都会在这个区域消费,在图文和视频混排的槽位中,点击了槽位中的视频,在接下来的几次刷新中都会在强兴趣区下发视频内容;弱兴趣区,即关联于用户的长期兴趣以及关联兴趣的内容,通常占20%的槽位,主要承担兴趣多样性需求;热点区,通常占20%的槽位,保留一部分流量给站内热点内容;兴趣探索区,即用来探索用户未知兴趣的内容,是最灵活的槽位,这里会不断尝试下发一些非已知用户兴趣的内容来试探用户兴趣。
除了上述槽位外,信息流产品中还会保留动态槽位,留给人工运营,例如置顶或突发内容等,例如微信看一看的"置顶话题"。
3.频道运营
内容分发产品无一例外都有"频道",或者叫内容分类。由于推荐流是内容分发产品的主场景,流量池有限,不可能将优质内容全都呈现给用户,

频道内部的运营和推荐流运营没有本质差别,可以认为在推荐流加上当前垂类或频道的分类约束,推荐流上的策略大部分也可以复用在频道内。除了频道内的运营,频道和频道之间也存在运营策略,常见的有:专题频道,指临时创建的频道或专题,例如"双11""618"“抗疫专题"等,这类频道存在一定的生命周期,周期结束后即下架,频道中的内容通过算法动态聚合,更像是标签体系中提到的"主题词”;动态频道,频道的位置是可以动态调整的,通常出于运营目标考虑而将频道位置进行前置或后置,前置意味着频道被流量加权,此时频道内的流量增加,务必关注 CTR 等的变化以及其对大盘的贡献,后置意味着频道被流量降权,后置较少见,通常在产品上线初期来逐步稳定频道排序中出现;频道半露出,属于产品策略,通常为了引导用户浏览中长尾的频道,在视觉区域内半露出频道的文字。
频道还承担了本地化运营的职责。对于互联网产品,用户覆盖面非常广,故会保留一个地域频道,通过 LBS 来为用户提供本地化服务,常见于020产品。同时国际化产品如果涉及多语种,也会在频道中保留本地语种,例如某些小语种泛滥的国家,就会在产品中保留小语种的专属频道。
4.兴趣探索
因为用户兴趣多样且复杂,需要推荐系统在满足用户已知兴趣基础上探索可能的未知兴趣。如果推荐系统持续为用户提供精准的推荐服务,那么就会陷入"信息茧房"的困境,即推荐越精准则推荐范围越窄,而越来越窄的推荐范围又与用户多样和复杂的兴趣相违背。爱美之心人皆有之,无聊的时候推几条热舞视频无伤大雅,可是发现用户对此很感兴趣之后就持续地、源源不断地推这类视频也是对用户的极大伤害,所以推荐系统需要建立兴趣探索的机制。
兴趣探索实际上是"损耗型"业务模式,因为要从流量蛋糕中切一小块出来,而且这一小块蛋糕是否符合用户口味还不得而知。如果兴趣探索能够命中用户未知需求,引发用户点击,那么皆大欢喜;如果兴趣探索无法命中,用户不去点击,直接会造成 CTR 0.1%~0.6%的损耗,对于 DAU 超过千万的产品,则是几十万级别的变化,所以兴趣探索务必谨慎。
兴趣探索为了能在探索用户兴趣以及流量影响两者间达到平衡,采用了很多种方。保留兴趣探索槽位,一般至多1个且放在最后,同时结合用户连续刷新下发的策略,当连续几次刷新下发在兴趣探索槽位的内容用户没有点击,则下次暂停兴趣探索一段时间,避免流量浪费;开辟纯探索流量区,与正常推荐槽位混合限制和约束比较大,部分产品会将兴趣探索独立出来,内容详情页中的"相关推荐"“你可能也想看”,以及"广场"均属此种;强化即时兴趣信号,兴趣探索非常依赖用户即时兴趣,故信息流产品中如果用户命中兴趣探索的内容(搜索或点击了兴趣探索的内容),则在主信息流动态插入这个即时兴趣内容,新浪微博的即时推、淘宝 APP 的主信息流以及头条都是如此。
三、个性化推荐是如何做到如此精准的
我们总是惊叹于推荐系统如此精准,好像能够读透我们的大脑似的,大神们的回答是:推荐系统是基于用户行为,通过机器学习和人工智能来判断用户偏好和兴趣,继而做到精准推荐。这句话非常清晰地诠释了什么叫无意义的废话。事实上,推荐系统做到如此精准,肯定是通过收集用户行为数据来分析用户偏好和兴趣,问题是,怎么收集,又怎么分析的呢。精准推荐的技术原理很复杂,但业务原理清晰易懂。
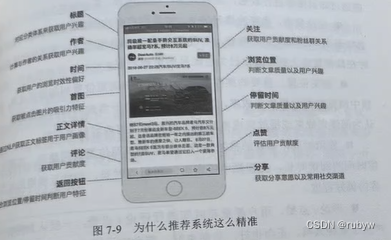
当用户点击查看一篇图文内容的详情时,推荐系统就开始从11个方面收集用户行为来做分析了:
■图文标题,其背后是完整的分类体系,包括一级分类、二级分类和三级分类(如果有)。当用户进入图文详情页时,推荐系统会记录当前图文标题后对应的一级分类、二级分类和三级分类,用来判断用户在分类体系上的偏好。例如上图所示,用户偏好的是【汽车】分类下的【 SUV 】。
■作者,无论 UGC 、 PGC 、 OGC 还是 PUGC ,都拥有一个创作者账号,面创作者账号在申请时都要关联"擅长领域",同时创作者自身有等级。当用户进入图文详情页时,推荐系统会记录当前文章创作者所在的擅长领域和星级,用来间接判断用户的兴趣偏好以及对创作者的喜好。
■发布时间,用来判断用户是否对内容时效性敏感。有的用户就是不喜次看历史内容,总想看新的,意味着用户更偏好新闻;有的用户对于发布时新旧无所谓,意味着用户更关注内容本身。
■首图,图片同样可以从中提取各类特征,比如色调、场景、类型等,以判断用户偏好明亮还是黑色图片,偏好抽象还是实景图片等。
■正文,直接过 NLP 提取标签,就能获取用户对于标签的偏好,在推系统中可以直接应用。现在知识图谱应用也越来越深,用户偏好的标签还能通过知识图谱进行联想,关联到更广泛的内容。
■关注状态,重要的推荐信号,如果用户多次浏览了已关注账号的内容,意味着用户更偏好此类内容,运营商会更多引导用户关注更多的创作者,同时在推荐策略上更多露出已关注账号的更新内容。
■浏览位置,重要的推荐信号,在图文中浏览位置叫阅读完成率,在视频中浏览位置叫播放完成率,直接反映用户对于当前内容的偏好程度,一般认为阅读完成率或播放完成率越高,用户对当前内容越感兴趣。
■停留时间,重要的推荐信号,一般和浏览位置共同使用,在图文中停留时间叫阅读时长,在视频中停留时间叫播放时长,同样反映用户对当前内容的偏好程度。
■评论/点赞,用户愿意花时间进行评论/点赞,一般认为内容与用户产生了某种共鸣,正向也好,负向也好,都命中了用户的某些兴趣点。
■分享,本身和评论/点赞一样,但是分享的渠道是可以反映用户平时的社交渠道的,在未来做促活或留存的时候,可以通过用户偏好的分享渠道来进行。
请注意,这只是1篇图文详情页能够采集到的用户特征,如果用户看了不止1篇,而是10多篇,压根不需要复杂的机器学习,简单统计一下这10多篇文章标题后对应的一级分类和二级分类就能大差不差地知道用户对于内容分类的偏好了。
当年今日头条讲过,用户只要使用5分钟,今日头条就能知道用户的兴趣和偏好。事实上,5分钟都长,用户启动产品,1分钟内看过10多篇文章,基本的兴趣和偏好轮廓就出来了。
四、推荐系统的原罪:不仅推荐,还在探索
推荐系统和基于推荐的用户场景已经覆盖99%的产品,几乎所有的产品都有"推荐"“您可能喜欢”“大家都在看"以及"广场”,连坚守时间流的微信订阅号也在灰度测试推荐策略。
推荐系统给我们推荐想看和爱看的内容,对于用户而言更能获得精准推荐的消费快感,今日头条的人均使用时长早已超过60分钟,而抖音、快手等更是设计了沉浸式视频场景。
但是,推荐系统不满足于推荐,还在探索用户的兴趣,它在提供满足用户需求内容的同时,还以显式和隐式的方式来试探用户兴趣,目的是提升推香效果,这也是推荐系统的原罪。
1.显式的兴趣反馈
几乎所有的推荐场景下,都会留有"不感兴趣"“减少此类内容”"不喜欢"尊,用户一旦点击即告诉推荐系统:这不是我要的内容。推荐系统会果断减少此类内容的推荐,更会将"用户不喜欢 xx “刻入用户画像永久保存。
2.隐式的兴趣探索
隐式的兴趣探索是对显式兴趣反馈的补充,因为显式兴趣反馈对于用户操作成本还是太高,效果不一定理想,所以隐式的兴趣探索横空出世。
隐式的兴趣探索,即用户在无感知情况下通过算法策略来试探用户兴趣。例如信息流产品,通常存在两种内容更新方式:无限下拉和顶部下拉。无论哪种更新方式,用户在每次更新时均会从内容库拉回8条新内容(常见5~10条),我们8条内容叫8个槽位。这8个槽位各司其职,博大精深,十分玄妙。
一般的,倒数1~2个槽位用来进行兴趣探索,是这么玩的:
■第一次刷出8条内容,槽位7呈现了汽车评测;
■我没有点击;
■第二次刷出8条内容,槽位7又呈现了汽车评测;
■我没有点击;
■第三次刷出8条内容,槽位7不再出汽车评测类内容,而是其他内容。这样,推荐系统就会知道"这个用户不喜欢汽车评测”,并更新到用户特征库中。


![洛谷 P1064 [NOIP2006 提高组] 金明的预算方案 python解析](https://img-blog.csdnimg.cn/474721e0951e47928dc969b09ecb5b2a.png)