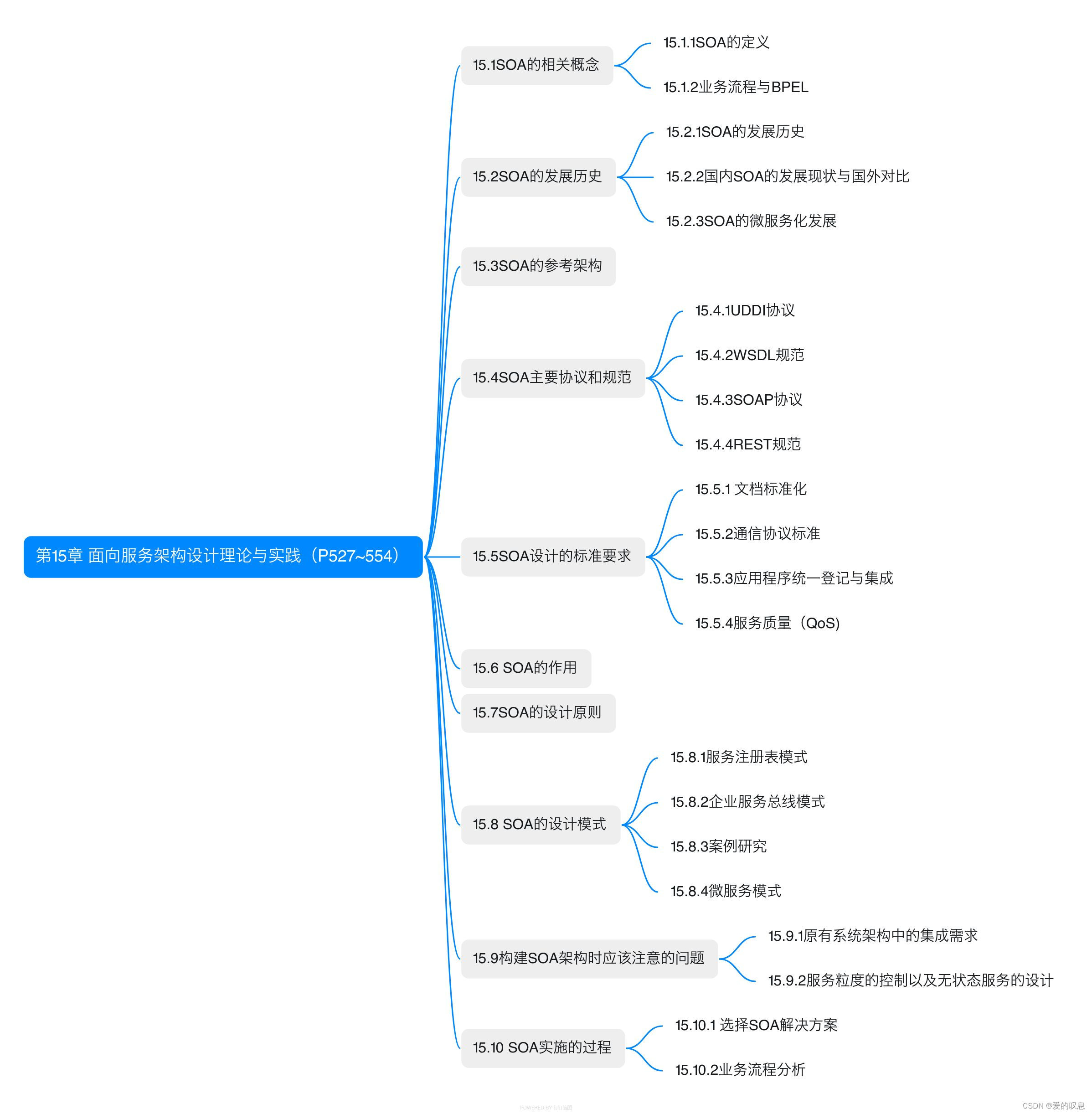
目录
一、灰色预测的原理
二、灰色预测的应用及python实现
一、灰色预测的原理
灰色预测是以灰色模型为基础,灰色模型GM(n,h)是微分方程模型,可用于描述对象做长期、连续、动态的反应。其中,n代表微分方程式的阶数,h代表微分方程式的变化数目。在诸多的灰色模型中,以灰色系统中单序列一阶线性微分方程模型GM(1,1)最为常见。
下面说明GM(1,1)模式:
设有原始数据列,n为数据个数,则可以根据以下步骤来建立GM(1,1)模型:
步骤一:
与原来统计累加以便减弱随机数据序列的波动性与 随机性,从而得到新数据序列:
其中,中各数据表示前几项的相加,即:
步骤二:
令为
的紧邻均值生成序列:
其中,
步骤三:
建立GM(1,1) 的灰微分方程为:
灰微分方程的白化方程为:
其中,a为发展系数,b为内生控制系数。
步骤四:
模型求解:构造矩阵B和向量Y:
,
步骤五:
设为待估参数向量,即:
这是利用正规方程得到的闭式解。
步骤六:
求解白化方程,可得到灰色预测的离散时间响应函数:
那么相应的时间相应序列为:
取,则所得的累加预测值为:
将预测值还原为:

二、灰色预测的应用及python实现
某公司根据2015-2020年的产品的销售额,试构建GM(1,1)预测模型,并预测2021年的产品销售额。
原始数据为:
Python实现代码:
import numpy as np
class GM:
def __init__(self,N,n,data):
'''
:param N: the number of data
:param n: the number of data that is needs to be predicted
:param data: time series
'''
self.N=N
self.n=n
self.data=data
def prediction(self,a,b):
'''
:param a: parameter a of the grey prediction model
:param b: parameter b of the grey prediction model
:return: a list of prediction
'''
# a list to save n predition
pre_data=[]
# calculating the prediction
for i in range(self.n):
pre=(self.data[0]-b/a)*(1-np.exp(a))*np.exp(-a*(self.N+i))
pre_data.append(pre[0])
return pre_data
def residual_test(self,a,b):
'''
:param a: parameter a of the grey prediction model
:param b: parameter b of the grey prediction model
'''
# prediction od raw data
pre_rawdata=self.sequence_prediction(a,b)
# calculating absolute residual
abs_residual=[]
for i in range(self.N):
r=abs(pre_rawdata[i]-self.data[i])
abs_residual.append(r)
# calculating relative residual
rel_residual=[]
for i in range(self.N):
rel=abs_residual[i]/abs(self.data[0])
rel_residual.append(rel)
# calculating average relative residual
avg_residual=0
for i in range(self.N):
avg_residual=avg_residual+rel_residual[i]
avg_residual=avg_residual/self.N
print("average relative residual: {}".format(avg_residual[0]))
if avg_residual<0.01:
print("model accuracy: excellent(Level I)")
elif avg_residual<0.05:
print("model accuracy: qualified(LevelⅡ)")
elif avg_residual<0.10:
print("model accuracy: barely qualified(Level Ⅲ)")
else:
print("model accuracy: unqualified(Level Ⅳ)")
def sequence_prediction(self,a,b):
'''
:param a: parameter a of the grey prediction model
:param b: parameter b of the grey prediction model
:return: prediction of raw data
'''
pre_rawdata=[]
pre_rawdata.append(self.data[0])
for i in range(1,self.N):
pre_raw=(self.data[0]-b/a)*(1-np.exp(a))*np.exp(-a*(i))
pre_rawdata.append(pre_raw)
return pre_rawdata
def GM11(self):
'''
:return: n prediction if the grey prediction model can be used
and parameter a and parameter b
'''
# accumulate raw data
cumdata=[]
for i in range(self.N):
s=0
for j in range(i+1):
s=s+self.data[j]
cumdata.append(s)
# calculating the nearest neighbor mean generation sequence
Z=[] # len(Z)=N-1
for i in range(1,self.N):
z=0.5*cumdata[i]+0.5*cumdata[i-1]
Z.append(z)
# construct data matrix B and data vector Y
B=np.array([[-Z[i],1] for i in range(self.N-1)])
Y=np.array([[self.data[i]] for i in range(1,self.N)])
# calculating parameter a and parameter b
A=np.dot(np.dot(np.linalg.inv(np.dot(B.T,B)),B.T),Y)
a=A[0]
b=A[1]
# determine whether the grey prediction model can be used
if (-1)*a>1:
print("the grey prediction model can not be used")
else:
#print("a={}".format(a[0]))
#print("b={}".format(b[0]))
# derive a prediction model and predict
pre_data=self.prediction(a,b)
return pre_data,a,b
if __name__=="__main__":
data=[2.67,3.13,3.25,3.36,3.56,3.72]
N=6
n=1
# create object
grey_prediction=GM(N,n,data)
# get prediction
pre_data,a,b=grey_prediction.GM11()
# get average relative residual
avg_residual=grey_prediction.residual_test(a,b)
print("predicted data: {}".format(pre_data[0]))运行结果: