PyTorch保存计算图导致内存泄漏
- 1. 内存泄漏定义
- 2. 问题发现背景
- 3. pytorch中关于这个问题的讨论
1. 内存泄漏定义
内存泄漏(Memory Leak)是指程序中已动态分配的堆内存由于某种原因程序未释放或无法释放,造成系统内存的浪费,导致程序运行速度减慢甚至系统崩溃等严重后果。
2. 问题发现背景
在使用深度学习求解PDE时,由于经常需要计算高阶导数,在pytorch框架下写的代码需要用到torch.autograd.grad(create_graph=True)或者torch.backward(create_graph=True)这个参数,然后发现了这个内存泄漏的问题。如果要保存计算图用来计算高阶导数,那么其所占的内存不会被释放,会一直占用。也就是如果设置create_graph=True,那么其保存的计算图所占的内存只有在程序运行结束时才会释放,这样导致了一个问题,即如果在循环中需要保存计算图,例如每个循环都需要计算一次黑塞矩阵,那么这个内存占用就会越来越多,最终导致out of memory报错。
3. pytorch中关于这个问题的讨论
官网中关于这个问题的讨论见https://github.com/pytorch/pytorch/issues/7343,这里提出的内存泄漏的例子如下:
import torch
import gc
_ = torch.randn(1, device='cuda')
del _
torch.cuda.synchronize()
gc.collect()
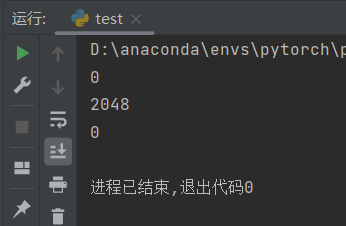
print(torch.cuda.memory_allocated())
x = torch.randn(1, device='cuda', requires_grad=True)
y = x.tanh()
y.backward(torch.ones_like(y), create_graph=True)
del x, y
torch.cuda.synchronize()
gc.collect()
print(torch.cuda.memory_allocated())
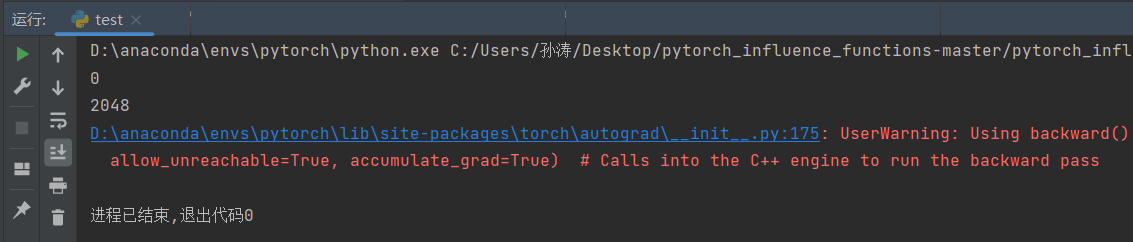
可以看到虽然删除了变量,依然造成了内存泄漏。这里红色的警告就是关于这个内存泄漏的问题。
UserWarning: Using backward() with create_graph=True will create a reference cycle between
the parameter and its gradient which can cause a memory leak. We recommend using autograd.grad
when creating the graph to avoid this. If you have to use this function, make sure to reset
the .grad fields of your parameters to None after use to break the cycle and avoid the leak.
(Triggered internally at C:\cb\pytorch_1000000000000\work\torch\csrc\autograd\engine.cpp:1000.)
allow_unreachable=True, accumulate_grad=True)
# Calls into the C++ engine to run the backward pass
看这个UserWarning,提示我们使用torch.autograd.grad()函数可以避免这个梯度泄漏,然后对代码进行改动:
import torch
import gc
from torch.autograd import grad
_ = torch.randn(1, device='cuda')
del _
torch.cuda.synchronize()
gc.collect()
print(torch.cuda.memory_allocated())
x = torch.randn(1, device='cuda', requires_grad=True)
y = x.tanh()
z = grad(y, x, retain_graph=True, create_graph=True)
# y.backward(torch.ones_like(y), create_graph=True)
del x, y, z
torch.cuda.synchronize()
gc.collect()
print(torch.cuda.memory_allocated())
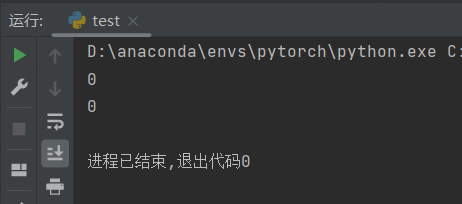
结果显示没有梯度泄漏。进一步,我们求一下二阶导数:
import torch
import gc
from torch.autograd import grad
_ = torch.randn(1, device='cuda')
del _
torch.cuda.synchronize()
gc.collect()
print(torch.cuda.memory_allocated())
x = torch.randn(1, device='cuda', requires_grad=True)
y = x.tanh()
z = grad(y, x, retain_graph=True, create_graph=True)
print(torch.cuda.memory_allocated())
q = grad(z, x)
del x, y, z, q
torch.cuda.synchronize()
gc.collect()
print(torch.cuda.memory_allocated())
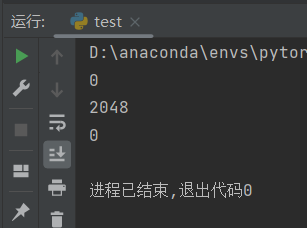
结果也没有内存泄漏。但是,如果我们不删除结果二阶导数q,这样是出于如果写在一个函数中,需要将q作为return值返回的情况。
import torch
import gc
from torch.autograd import grad
_ = torch.randn(1, device='cuda')
del _
torch.cuda.synchronize()
gc.collect()
print(torch.cuda.memory_allocated())
x = torch.randn(1, device='cuda', requires_grad=True)
y = x.tanh()
z = grad(y, x, retain_graph=True, create_graph=True)
print(torch.cuda.memory_allocated())
q = grad(z, x)
del x, y, z
torch.cuda.synchronize()
gc.collect()
print(torch.cuda.memory_allocated())
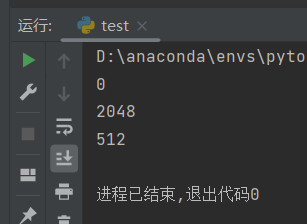
可以看到,这还是会导致一部分内存泄漏。那如果我们一定要返回q,又不想内存泄漏,这里本人想到一直办法,就是将q转换成numpy数据类型,返回这个numpy数组,就不会导致内存泄漏了。
import torch
import gc
from torch.autograd import grad
_ = torch.randn(1, device='cuda')
del _
torch.cuda.synchronize()
gc.collect()
print(torch.cuda.memory_allocated())
x = torch.randn(1, device='cuda', requires_grad=True)
y = x.tanh()
z = grad(y, x, retain_graph=True, create_graph=True)
print(torch.cuda.memory_allocated())
q = grad(z, x)
k = q[0].cpu().numpy()
del x, y, z, q
torch.cuda.synchronize()
gc.collect()
print(torch.cuda.memory_allocated())