目录
编辑
前言:
关于双向循环带头链表:
模拟实现双向循环带头链表:
1.typedef数据类型
2.打印链表
3.初始化链表:
4.创建节点
5.尾插
6.头插
7.尾删
8.头删
9.寻找节点
10.在节点前插入
11.删除指定节点
单链表和双链表的区别:
链表和顺序表的区别:
对于顺序表的优势:
顺序表的问题:
链表的优势:
链表的不足:
总结:
前言:
我们在上一篇blog中,对于单向链表且不带哨兵位的头节点有了初步的认识,具体内容可以参考以下blog:《单链表》的实现(不含哨兵位的单向链表)-CSDN博客
今天我们将要对于双向链表的进行模拟实现,由于代码实现起来简单,并且大部分与单链表内容相似,所以我在这里我会进行过多的赘述,我们只是来讲解双向带头链表是什么,剩下的内容将是全部的代码模拟。
关于双向循环带头链表:

简化一点就是:
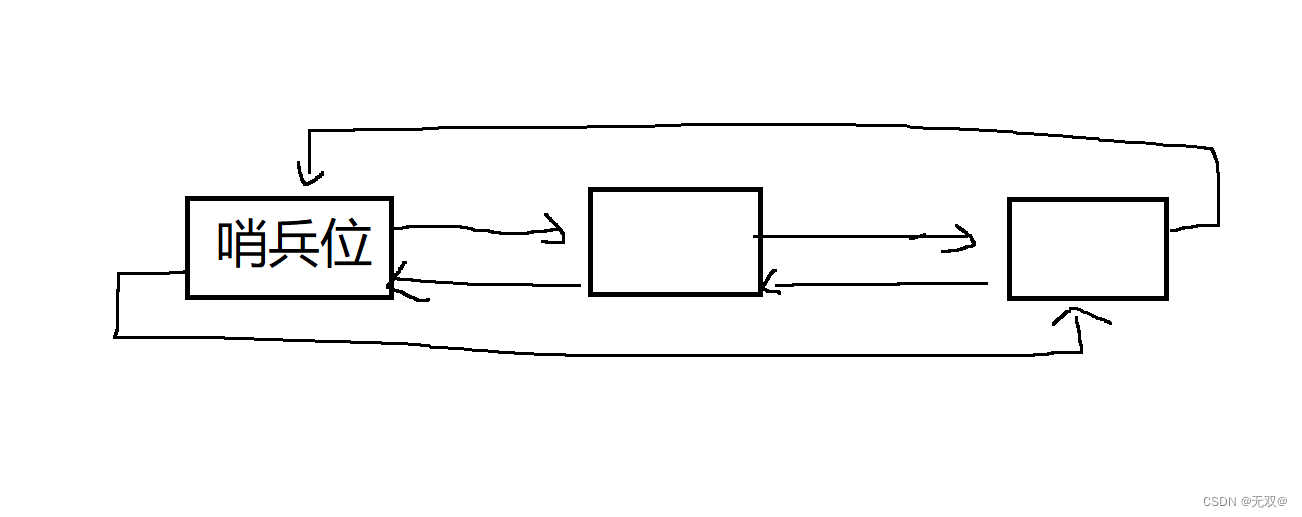
我们会在节点里面再多定义一个指针——prev,指向上一个节点,这样方便我们进行操作。
因为有了上一个节点的地址,我们不管在尾删还是头删都可以在不保存任何节点的情况下对该节点进行操作,因此我们就会简化一系列操作。
下面将是各个模块的详细代码:
模拟实现双向循环带头链表:
1.typedef数据类型
typedef int LTDataType;
typedef struct ListNode
{
struct ListNode* next;
struct ListNode* prev;
LTDataType data;
}LTNode;2.打印链表
void LTPrint(LTNode* phead)
{
assert(phead);
printf("哨兵位<=>");
LTNode* cur = phead;
while (cur!=phead)
{
printf("%d<=>", cur->data);
cur = cur->next;
}
printf("\n");
}3.初始化链表:
LTNode* LTInit()
{
return CreatLTNode(-1);
}4.创建节点
LTNode* CreatLTNode(LTDataType x)
{
LTNode* tmp = (LTNode*)malloc(sizeof(LTNode));
if (tmp == NULL)
{
perror("CreatNode -> malloc");
exit(-1);
}
tmp->data = x;
tmp->next = tmp;
tmp->prev = tmp;
return tmp;
}5.尾插
void LTPushBack(LTNode* phead, LTDataType x)
{
assert(phead);
LTNode* newnode = CreatLTNode(x);
if (phead->next == phead)
{
phead->next = newnode;
phead->prev = newnode;
newnode->next = phead;
newnode->prev = phead;
}
else
{
newnode->next = phead;
phead->prev->next = newnode;
newnode->prev = phead->prev;
phead->prev = newnode;
}
}6.头插
void LTPushFront(LTNode* phead, LTDataType x)
{
assert(phead);
LTNode* newnode = CreatLTNode(x);
phead->next = newnode;
phead->prev = newnode;
newnode->next = phead;
newnode->prev = phead;
}7.尾删
void LTPopBack(LTNode* phead)
{
assert(phead);
assert(phead->next != phead);
LTNode* tail = phead->prev;
tail->prev->next = phead;
phead->prev = tail->prev;
free(tail);
tail = NULL;
}8.头删
void LTPopFront(LTNode* phead)
{
assert(phead);
assert(phead->next != phead);
LTNode* tmp = phead->next;
phead->next = tmp->next;
tmp->next->prev = phead;
free(tmp);
tmp = NULL;
}9.寻找节点
LTNode* LTFind(LTNode* phead, LTDataType x)
{
assert(phead);
LTNode* cur = phead->next;
while (cur != phead)
{
if (cur->data == x)
{
return cur;
}
cur = cur->next;
}
return NULL;
}10.在节点前插入
void ListInsert(LTNode* phead, LTNode* pos, LTDataType x)
{
assert(pos);
LTNode* newnode = CreatLTNode(x);
newnode->prev = pos->prev;
pos->prev->next = newnode;
pos->prev = newnode;
newnode->next = pos;
pos->prev = newnode;
}11.删除指定节点
void ListErase(LTNode* phead, LTNode* pos)
{
assert(phead);
pos->prev = pos->next;
pos->next->prev = pos->prev;
free(pos);
}单链表和双链表的区别:
对于单链表我们想要进行找尾操作,十分困难,时间复杂度为O(N)
而在双向链表中,我们想要进行找尾操作则直接利用phead->prev就可以找到尾结点,时间复杂对为O(1)。
在我们以后的面试中,如果我们的面试官对我们提出,如何在10min之内创建一个链表。
这时候我们就可以信心满满的写出双线带头循环链表,并且只需要写出ListErase 与 ListInsert即可,因为这两个函数不需要进行分类讨论。
链表和顺序表的区别:
学习了链表与顺序表,这两种均属于线性表的产物,那么我们该如何选择呢?
对于顺序表的优势:
1.支持下标的随机访问。
2.CPU高速缓存命中率较高
顺序表的问题:
1.头部或中间插入删除效率低,需要挪动数据O(N)
2.空间不够需要扩容,扩容一定要消耗,且可能存在一定的空间浪费。
3.只适合尾插尾删。
链表的优势:
1.任意位置插入删除都是O(1)。
2.按需申请释放,合理利用空间,不存在浪费
链表的不足:
-
随机访问性差:链表中的元素并不存储在连续的内存位置上,因此要访问链表中的任意元素需要遍历整个链表,时间复杂度为O(n)。
-
存储空间浪费:链表中每个节点需要额外的一个指针来指向下一个节点,这样会使链表中存储的数据量比较少,占用的存储空间较大。
-
插入和删除操作的效率较高:虽然插入和删除操作都是链表的优点,但是在处理大量数据时,频繁的插入和删除操作会导致链表不断地重新分配内存空间,影响性能。
-
不支持随机访问:链表的遍历方式只能是从头节点开始,依次访问每个节点,不能直接访问某个节点的位置。
-
不利于缓存:由于链表中的元素在内存中的存储位置是随机的,所以在对链表进行遍历时,缓存命中率较低,效率较差
总结:
以上就是我们的双向带头链表的实习,以及对于顺序表和链表之间的区别,学习完后下来可以及时整理整理,在之后我们会对顺序表和链表进行综合运用,我们将在后面实现《栈》《队列》的模拟操作,也会对于相应的题目进行分析。
记住
“坐而言不如起而行”
Action speak louder than words!