近日,和鲸旗下数据科学协同平台 ModelWhale 成功入驻华为蓝鲸应用商城,这也是继和鲸与华为发布数据分析建模实训联合解决方案后的再度携手,标志着双方的合作进入更全面、更深入的新阶段。
华为蓝鲸应用商城是华为数据存储面向客户提供的一站式应用解决方案集成平台,致力于为客户提供多样的应用选择、智能的应用匹配、一键的应用部署和全栈的应用管理,为伙伴提供应用与 IT 基础设施深入集成的解决方案。

数据科学协同平台 ModelWhale 是和鲸科技自主研发的数据科学生产力工具,平台基于 ModelOps 理念,深度融合计算基础设施、模型开发环境与团队协同管理,打通数据、算力、模型、成果应用全流程,为数据驱动型组织提供一站式数据科学服务,加速组织数智化升级进程。

AI 大模型带来了生产力革命, ModelWhale 平台凭借全面而强大的数智化能力,可成为大模型时代 AI 基础设施的入口,助力各行各业打通数据的价值闭环,真正实现 AI 赋能应用落地。
平台特点
连接多源数据,从分析需求出发打破数据孤岛
ModelWhale 平台支持用户通过上传本地数据、连接数据库、数据仓库等多种方式接入数据使用并统一管理:逐级开放的数据权限保障数据开放时的数据安全,DOI 标识实现数据可追溯与数据可描述,更进一步提升数据价值利用的科学性与可持续性。使用数据时,用户可直接基于数据创建数据分析项目,或为项目添加关联数据,提升数据调用效率的同时结构化沉淀数据与项目的关系。


即开即用,多人、多角色、随时随地进行数据驱动的协同研究与创新
ModelWhale 平台提供开箱即用的数据科学镜像环境,支持 Python 、 R、Julia 等多种语言,内置常用机器学习框架与数据分析研究过程中的常用工具包,助力用户根据分析需求快速自定义镜像。平台将云原生架构的优势融入到产品化的数据分析工作流中,并基于 Jupyter 的引擎设计了 Canvas 图形化拖拉拽建模工具,做到了从拖拉拽建模到 Jupyter Notebook 建模的转化,同时打通机器学习平台 IDE 与 交互式 Notebook ,两种不同编辑模式共享文件系统,拓宽了数据工作的受众面。

ModelWhale 平台重构了围绕数据的生产关系,支持不同工程能力的研究者协同参与数据的探索。数据、算法、模型等数据驱动的研究中所有涉及到的生产要素都具备基于版本、权限管理的协同链路,针对开发协作流程提供的项目管理工具便于研究者沉淀生产资料与工作流。此外,Notebook 与 Canvas 的互动进一步扩大了数据驱动的决策参与角色范围。

强大的计算引擎管理,最大化利用算力资源
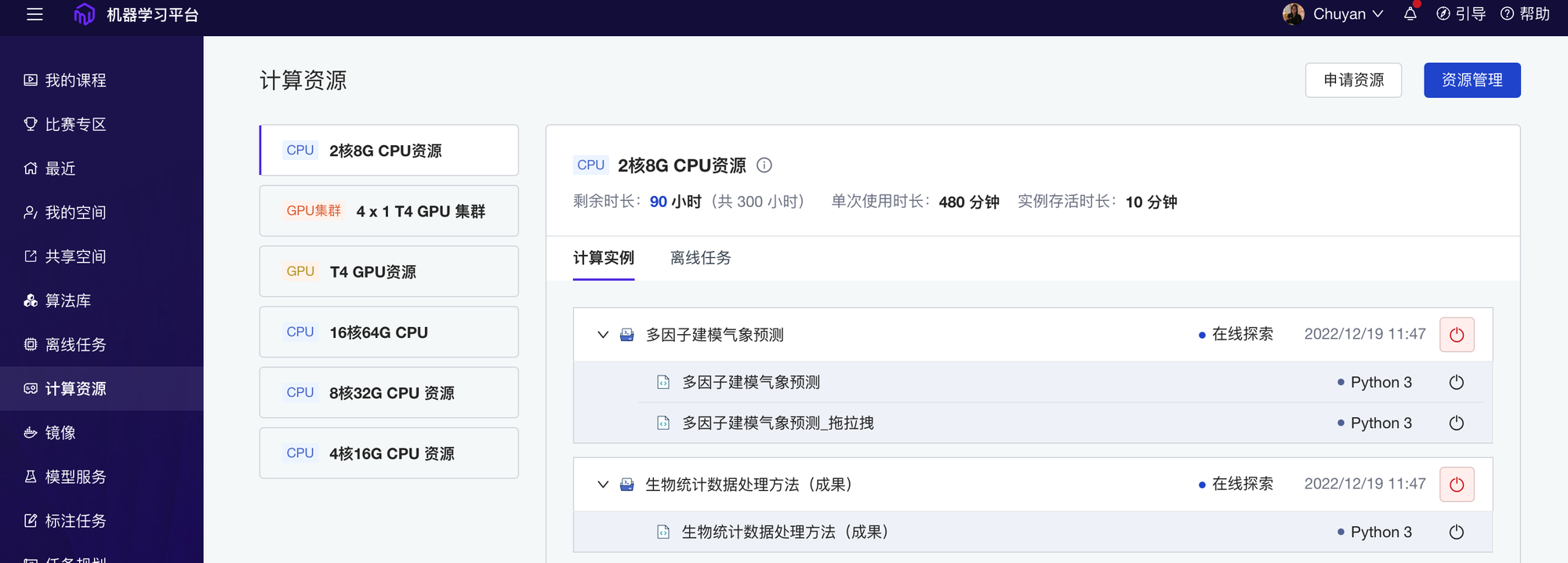
针对人工智能应用的大规模计算需求, ModelWhale 平台具备强大的算力资源管理能力,助力研究者从容应对不同复杂度的算力需求。平台采用 Kubernetes 网络架构、Docker 容器引擎技术构建实例运行环境,支持多种 CPU、GPU 算力规格的调度,无需配置繁琐信息,联网即用,关闭后又自动释放,提升利用率的同时降低算力成本。
平台支持将算力根据核数与内存大小进行细粒度拆分,或将多机多卡的 GPU 组成集群算力。面对长时间的训练或大规模分析任务,研究者即可利用离线训练同时启动多台机器、GPU 集群算力,实现多线程、多进程的项目运行,快速检验代码效果,训练结果及资源使用情况也可实时查看。
迄今为止,包含地球科学、生命科学、金融、通信、能源、服装零售等多个领域,高校、科研单位、企业等众多组织都在使用和鲸 ModelWhale 数据科学协同平台开展数据驱动的研究。例如,和鲸与某国家级科研机构共同构建气象大模型,支撑气象业务对数据挖掘及数据建模的需要,满足气象业务各类应用场景的数据挖掘分析、建模、运行等,为“气象智脑”提供新动能;与清华大学、中国人民大学、山东大学、中国石油大学(华东)、协和医学院、暨南大学、楚雄师范学院等数十家高校共同构建数据科学人才培养体系。
携手共进,AI 赋能。此次 ModelWhale 平台入驻华为蓝鲸应用商城,对和鲸开拓市场无疑是一大利好,更多有数智化转型的客户将有机会了解到和鲸。未来,和鲸也将不断精进技术实力,与华为一起提供更优质的平台、方案与服务,为各行业实现 AI 大模型的融合应用与产业落地贡献力量。




![[C/C++]数据结构 栈和队列()](https://img-blog.csdnimg.cn/3bdc76488476481ca9ae0838209053a9.png)