SELF-RAG: 让LLM集检索,生成跟评判等多种能力于一身
提纲
1 简介
2 SELF-RAG
3 实验结论
4 讨论
参考文献
1 简介
尽管基础能力出众,但是大模型只能依赖于被压缩到模型参数中的知识,所以经常会生成不符合事实的回复。针对这种事实性错误,目前主流的解决方案是知识增强,引入外部的知识源来引导模型生成。但是不考虑具体情形,一味地去检索外部文档可能会损害语言模型的多样性,生成不合适的回复。基于此,有研究人员提出了Self-Reflective Retrieval-Augmented Generation(SELF-RAG),一种新的大模型知识增强框架,可以通过检索跟自我反思提升大模型生成的质量跟事实可靠性。
2 SELF-RAG
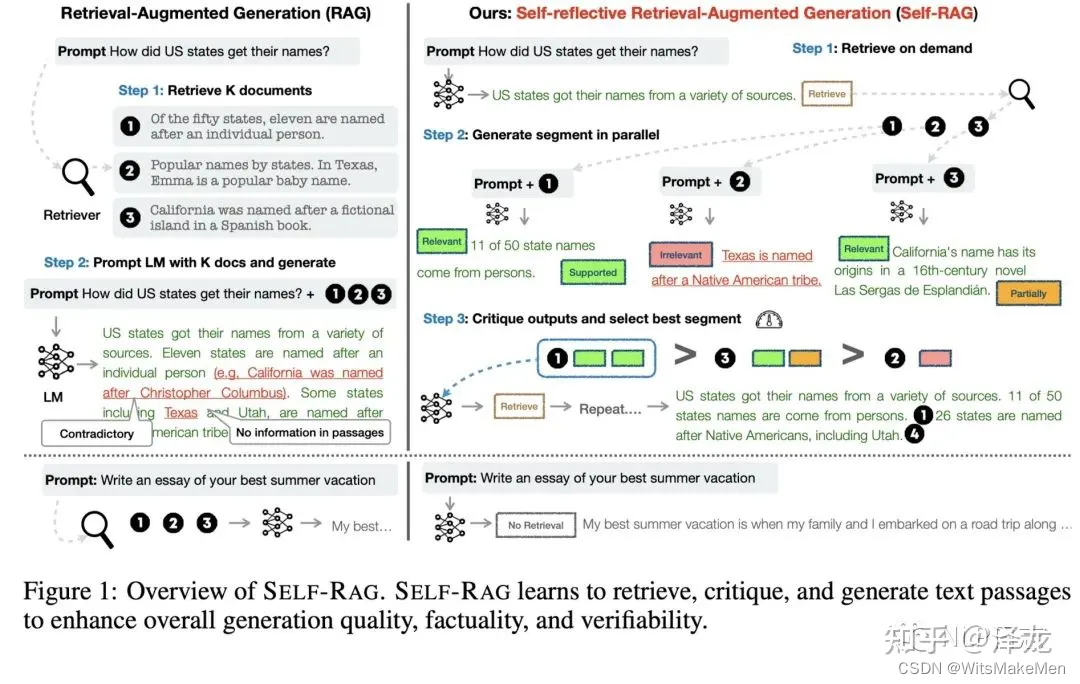
SELF-RAG的框架如下图所示,SELF-RAG往语言模型的词表中引入了4种新类型的reflection tokens,分别是Retriver, IsRel, IsSup, IsUse,对应四种不同的子任务,每个子任务下包括多个对应的reflection tokens。以Retriever为例, 该任务用户判断当前问题下是否需要检索模型支持,对应的reflection tokens有yes,no跟continue,分别对应不同选择。通过让语言模型生成对应的reflection token,使得语言模型具备判断是否需要检索以及评判生成结果的能力。

模型训练
SELF-RAG的训练过程涉及到两个模型,分别是评判模型C跟生成模块M。在该框架下评判模型C有4种用途,需要根据不同情形生成对应的判别结果,分别对应前面提到的4种类型的reflection token。其一是给定输入x后,判断是否需要引入检索模块。其二是给定输入x跟检索文档d后,判断输入x跟文档d的相关性。其三是给定输入x,检索文档d,跟模型输出y后,判断输出y是否可以由文档d支撑。其四是给定输入x跟模型输出y后,判断输出y是否可以作为x的有价值回复。
判别模型判别模型的训练数据是利用GPT-4生成得到的,对于每一种任务类型,给定对应的输出后,设置合适的任务指令instruction跟示例demonstration,让GPT4生成相应的reflection token,从而得到4种不同任务下的(input, response)数据,再利用标准的条件语言模型训练目标优化评判模型即可。
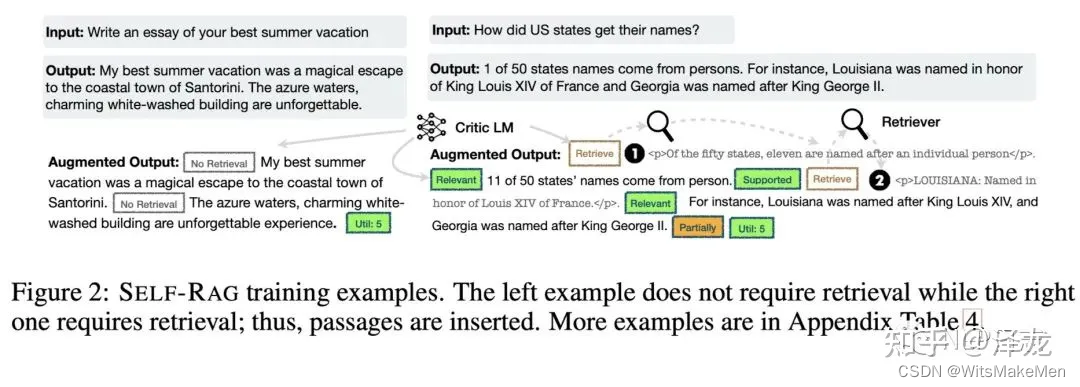
在完成评判模型C的训练后,需要利用其来生成训练生成模型M的数据。具体做法为给定初始的训练数据(x,y),首先利用评判模型C判断回复x是否需要引入检索模块,如果需要的话,就将Retriver对应的reflection token加入到之前的输出中,然后利用检索模块召回若干文档,对于每个文档,利用critic模型判断文档跟问题是否相关,即IsRel任务,若相关,则利用评判模型C判断结果y是否由文档所支撑,即IsSup任务,将召回文档以及这两个任务对应的reflection token依次加入到前面的输出中,最后再利用评判模型C判断结果y是否有用,即IsUse任务,将前面的文档,reflection token跟结果y按照顺序拼接到一起作为增强过的y,从而构建出对应的训练数据(x,augmented y)。具体流程可以参考图中样例。在完成训练数据构建后,按照标准的自回归任务训练生成模型即可,从而可以得到生成模型M。
模型推理
生成模型M首先会判断当前问题是否需要使用检索,如果需要的话,就会检索召回多个相关文档,通过并行的方式同时处理多个文档,并生成对应回复,再通过排序选择其中最合适的回复作为最终结果。

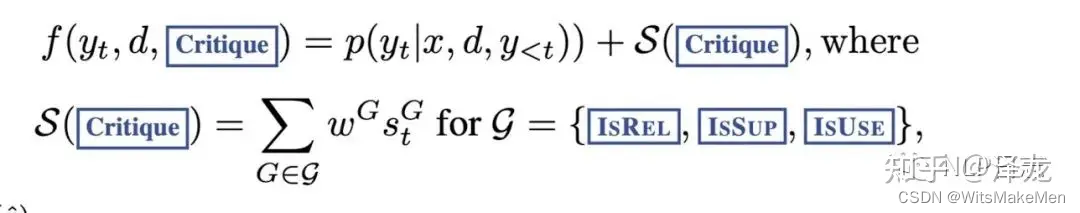
由于reflection token的设置,使得SELF-RAG整个推理过程更加可控,可以通过调整检索的阈值或者最终排序时的不同reflection token的权重参数,来控制模型整体行为。对于那些需要更高事实准确性的场景,可以让模型更多地去召回相关文档从而让生成结果更加有依据,对于那些开放性问题,可以限制模型调用检索模块,更多的发挥大模型本身的创造性。可以看到,SELF- RAG中的评判模型C的用途是为了构建生成模型M所需要的训练数据,当生成模型训练完成后,在具体推理时只会用到生成模型M。
3 实验结论
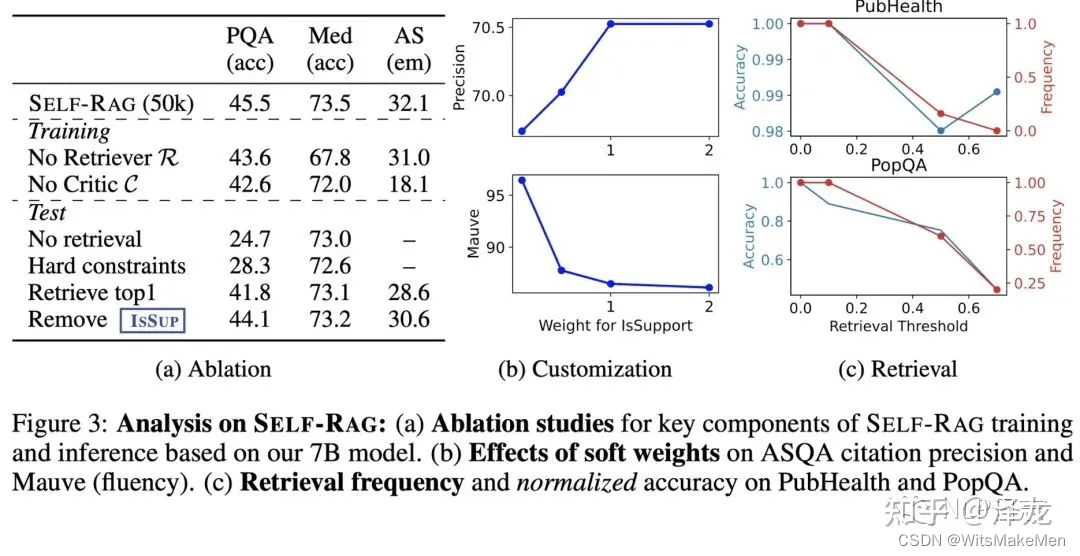
a) 研究人员在包括多选推理数据集,开放域问答等6个任务上进行了评测,发现SELF-RAG在大多数任务上都领先于不加检索的模型跟现存的知识增强模型。其中Llama2-FT(7B)使用了跟SELF-RAG同样的训练数据,但是效果明显不如SELF- RAG,这说明了SELF-RAG的收益不仅来源于训练数据,也来源于整体框架的有效性。
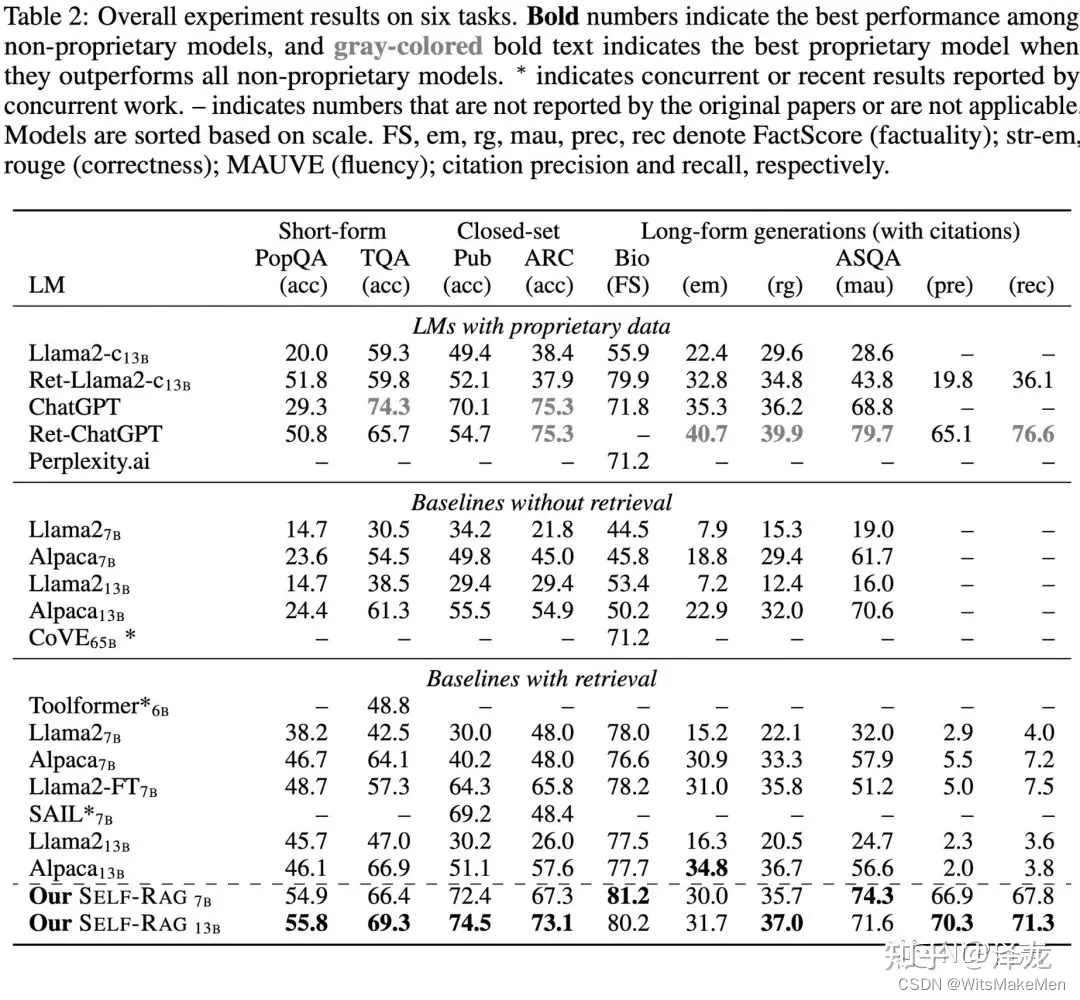
b) 通过消融实验可以观测SELF- RAG中各个模块对于整体的贡献,尤其是可以看到相比于推理时只检索返回1个文档的做法,SELF-RAG有显著提升,说明SELF- RAG本身具备根据多种细粒度评判指标选择生成结果的能力,并不会过于依赖检索返回的结果。
4 讨论
对于构建训练数据时候利用GPT-4生成reflection token以及推理时利用这些对应的reflection token概率值作为细粒度评判指标,模型预测的结果是否可信?研究人员对比了这些模型生成的结果跟人工标注结果,发现两者存在高度的一致,这也跟前面很多文章观点一致,只要使用妥当,可以利用GPT-4这类语言模型来构建数据,语言模型生成的标注质量是非常高的。
总体感觉SELF-RAG跟上半年清华的webcpm框架有诸多相似之处,都是希望利用一个大模型通过恰当的训练,可以独立完成知识增强里的所有任务,让模型更加智能地决定何时引入检索模块,选择哪个检索文档以及评判生成回复的质量。最大的特别之处在于SELF- RAG更加可控,可以通过对4种类型reflection token所对应的子任务进行调控来实现对整个生成过程的微调,根据不同场景让模型选择更加自由发挥或者更加依据事实。除了更加可控外,引入reflection token的方式是否比之前的通过不同prompt让模型做不同任务的方式更加高效,这一问题,文中并没有通过实验论证。个人猜测还是有提升的,通过reflection token可以把前面任务的评判结果加入到模型输入中,应该是更有利于后续任务的。
SELF-RAG还有个与众不同的地方在于,它会根据多个检索文档生成多个回复(每个文档对应1个回复),通过一定的打分规则从中选择其中一个回复。这种设计不就处理不来那些需要模型同时依赖于多个文档的问题了嘛?为此所带来这种并行生成多个回复的处理手段不就意味着需要更多算力资源了嘛?文中为何不试下把所有检索文档一同作为模型输入去生成回复,这种方式不应该很符合当下主流嘛?
参考文献
1 SELF-RAG: LEARNING TO RETRIEVE, GENERATE, AND CRITIQUE THROUGH SELF-REFLECTION
https://arxiv.org/pdf/2310.1151