中文分词指的是将一个汉字序列切分成一个一个单独的词。分词就是将连续的字序列按照一定的规范重新组合成词序列的过程。在英文的行文中,单词之间是以空格作为自然分界符的,而中文只是字、句和段能通过明显的分界符来简单划界,唯独词没有一个形式上的分界符,虽然英文也同样存在短语的划分问题,不过在词这一层上,中文比之英文要复杂的多、困难的多。
例如,对于句子“我爱北京天安门”,中文分词的任务是将这句话切分成一个一个单独的词。根据中文分词的规则,这句话可以被切分成“我”、“爱”、“北京”、“天安门”四个词。
1.英文分词
英文分词是将英文文本切分成一个个单独的单词。英文单词之间通常以空格作为自然分界符,因此英文分词相对比较简单。常用的英文分词工具包括NLTK、spaCy等。以下是一个简单的例子:
import nltk
text = "Hello, how are you? I'm fine, thank you."
tokens = nltk.word_tokenize(text)
print(tokens)输出结果:
['Hello', ',', 'how', 'are', 'you', '?', 'I', "'m", 'fine', ',', 'thank', 'you', '.']在这个例子中,我们使用了NLTK库的word_tokenize函数对文本进行分词。分词结果以列表的形式返回,每个单词作为一个独立的元素。

2.中文分词
中文分词的标准存在不同的版本和依据。
- 意义标准:最早可追溯到马建忠的《马氏文通》,其分词标准是以意义为依据,将词语根据其词汇意义进行划分。
- 形态标准:在中文语法学中,传统分词方法是按照词的意义划分词类,并照搬印欧语的词类划分方法。这种分词方法简单地将汉语的词类与句子成分对应起来,认为汉语中作主语、宾语的是名词,作定语的是形容词,作谓语的是动词,作状语的是副词。
- 功能标准:词的语法功能主要表现一方面是组合能力,主要包括实词与实词的组合能力、实词与虚词的组合能力。不同词类之间是否能够组合、以什么方式组合、组合后发生什么样的语法关系等。另外一方面是词在句子中充当句法结构成分的能力,实词都能充当句子成分,例如名词的显著特点就是可以作主语和宾语,形容词的显著特点是可以作谓语、定语等。

3.分词方法
分词方法主要有以下几种:
- 基于规则的分词方法:基于规则的分词方法通常采用一组预定义的规则或模式,对文本进行分词。这些规则可以基于词法、语法、语义等语言学特征,也可以基于特定的领域知识和应用需求。例如,基于正则表达式的分词方法可以根据预定义的规则将文本切分成符合特定模式的词序列。
- 基于统计的分词方法:基于统计的分词方法通常利用机器学习或自然语言处理技术,对大量的语料库进行训练和学习,从而自动地进行分词。这些方法通常会根据词频、语境等信息,对文本中的词汇进行概率计算和预测,从而自动地将文本切分成符合语言规则的词序列。例如,最大匹配法、HMM模型、CRF模型等都是基于统计的分词方法。
- 基于深度学习的分词方法:基于深度学习的分词方法通常利用神经网络模型,对大量的语料库进行训练和学习,从而自动地进行分词。这些方法通常会采用循环神经网络(RNN)、长短时记忆网络(LSTM)、卷积神经网络(CNN)等模型,对文本进行逐字的编码和解码,从而自动地将文本切分成符合语言规则的词序列。例如,基于Bi-LSTM的分词方法就是一种基于深度学习的分词方法。
实践证明,基于规则的分词系统效果比不上基于统计学习的分词系统。未登录词造成的分词精度失落至少比分词歧义大5倍以上,基于字的标注系统能够大幅度提高未登录词的识别能力。
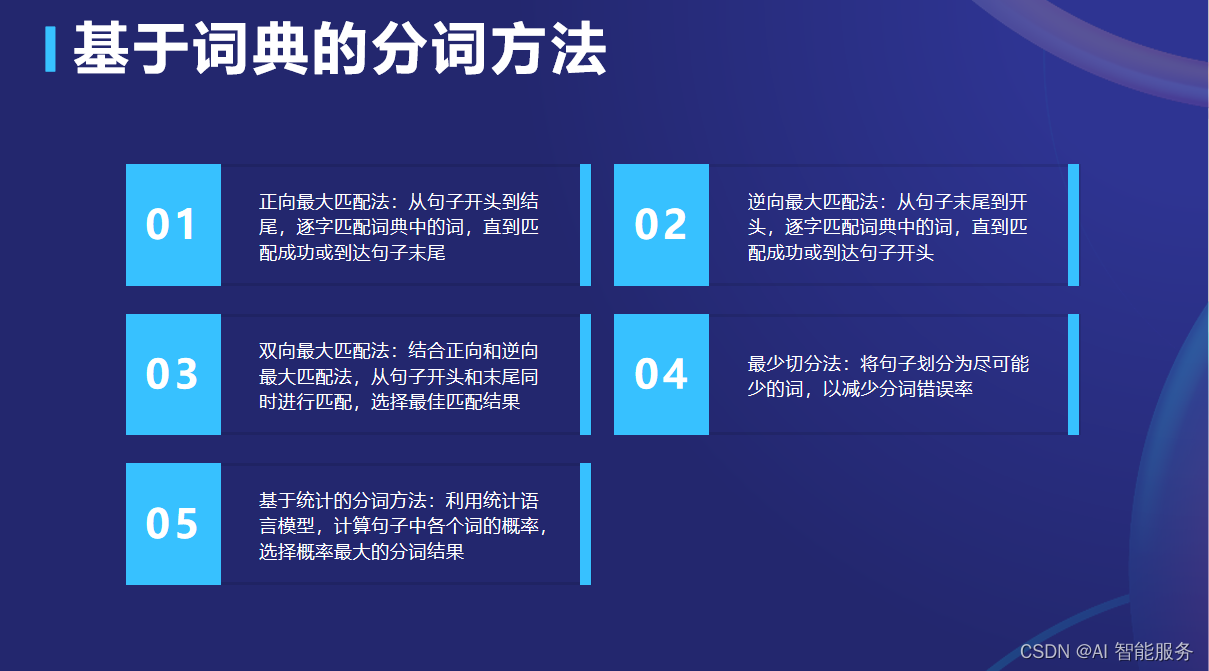
3.1基于词典的分词方法
基于词典的分词方法是基于规则的分词方法中的一种,它通常使用一个包含常见词汇的词典,并根据词典中的词汇对文本进行分词。
基于词典的分词方法的基本原理是将待分词文本与词典进行匹配,根据匹配结果进行分词。其分词过程包括以下步骤:
- 构建词典:建立一个包含常见词汇的词典,词典中的每个词汇都是一个基本的语义单位。
- 匹配过程:将待分词的文本与词典中的词汇逐个进行匹配。匹配时可以采用正向最大匹配、逆向最大匹配或双向最大匹配等方法。
- 确定分词结果:根据匹配的结果确定分词的位置,并将分词结果输出。
基于词典的分词方法具有以下特点:
- 简单高效:基于词典的分词方法不需要依赖大量的语料库,只需要一个词典即可进行分词。因此,它的分词速度较快,适用于对实时性要求较高的场景。
- 准确性高:由于基于词典的分词方法是根据词典进行匹配,因此可以保证分词的准确性。同时,词典可以不断更新,以适应新词汇的出现。
- 存在歧义:基于词典的分词方法存在一定的歧义问题。当待分词文本中的词汇不在词典中时,就无法进行匹配,导致分词失败。此外,一些词汇具有多种含义,可能会导致歧义的出现。
常用的基于词典的分词方法包括正向最大匹配法(Maximum Matching)、逆向最大匹配法(Reverse Maximum Matching)、双向最大匹配法(Bi-directional Maximum Matching)等。这些方法根据不同的匹配方向和匹配长度优先级来进行分词,具有较高的准确性和效率。
3.1.1正向最大匹配法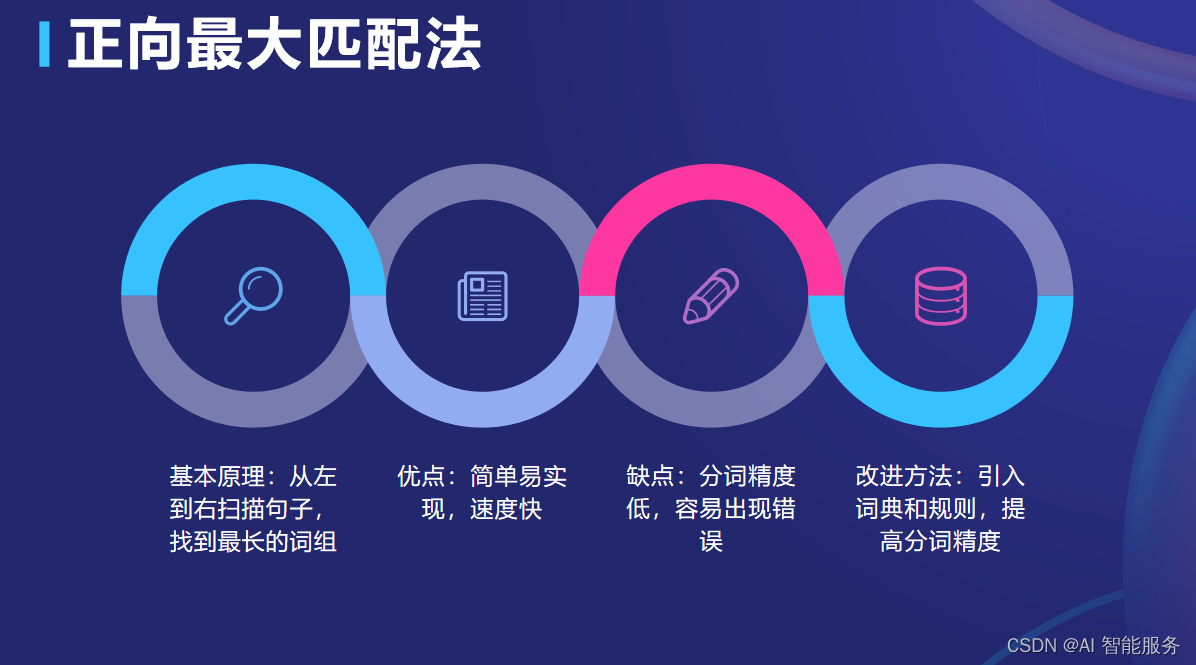
3.1.2逆向最大匹配法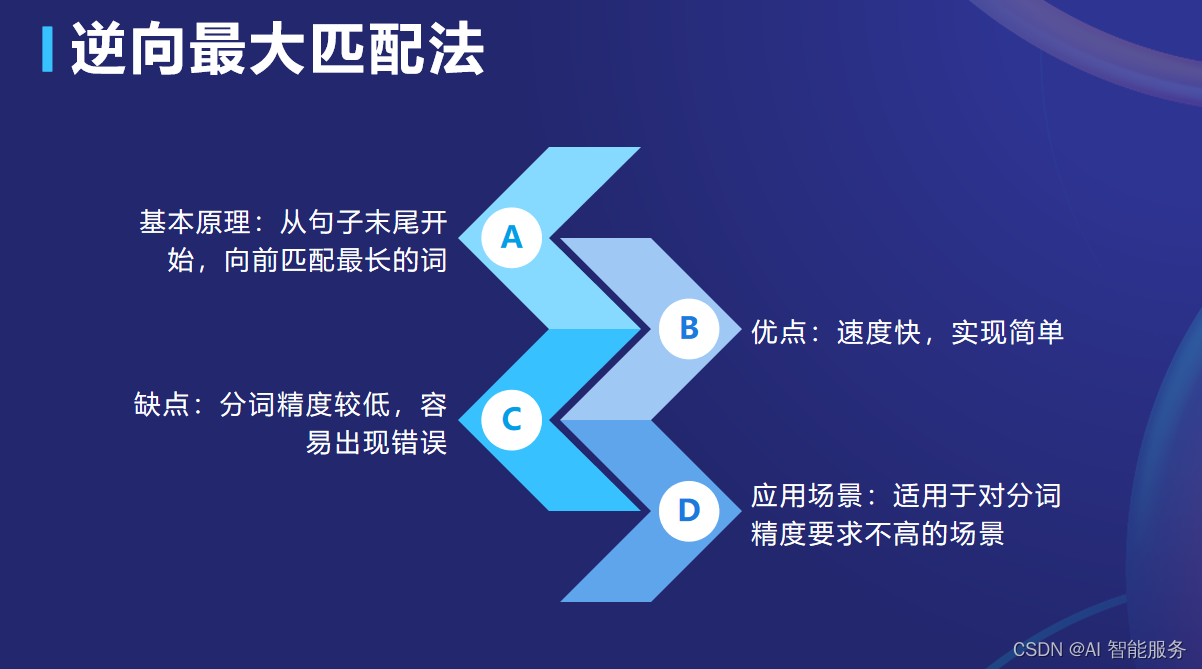
3.1.3双向匹配分词法
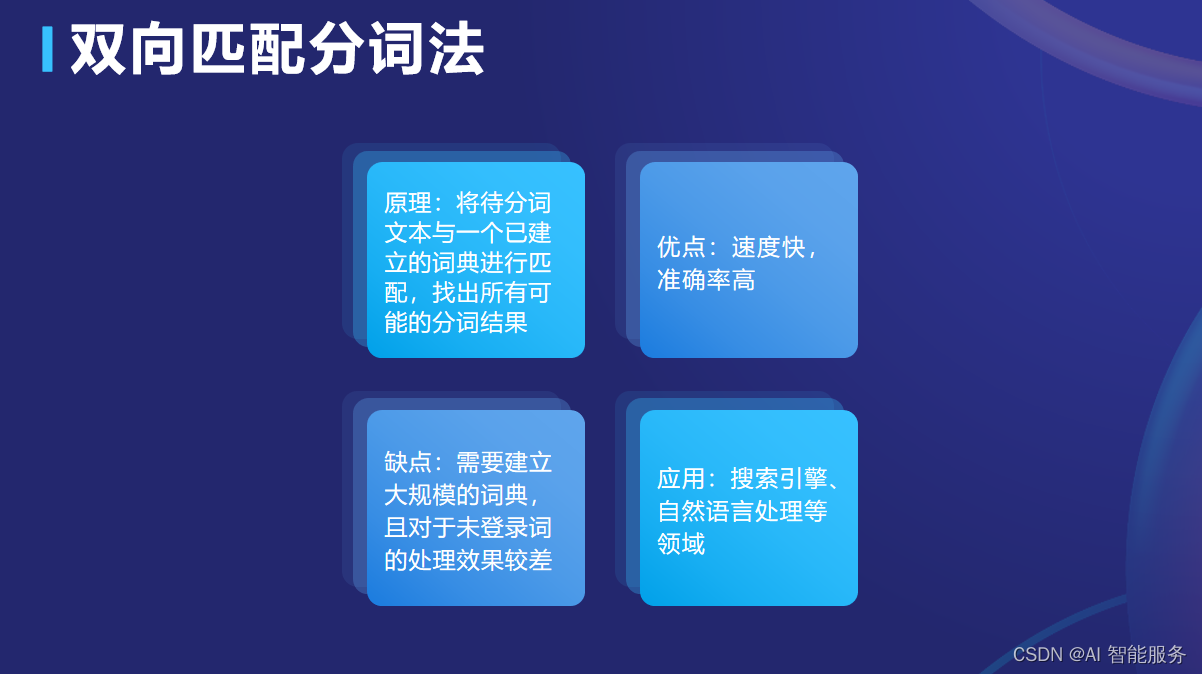
3.2基于统计的分词方法
基于统计的分词方法是基于统计模型的分词方法,利用训练文本中的统计信息进行分词。其基本原理是根据上下文出现的频率来计算词汇之间的概率,然后根据这些概率来切分词语。
基于统计的分词方法通常采用隐马尔可夫模型(HMM)或条件随机场(CRF)等模型,通过一定的优化方法来进行分词。
基于统计的分词方法具有以下特点:
- 准确性较高:基于统计的分词方法利用了大量的文本数据,可以较为准确地切分出词汇。
- 适用于不同领域:基于统计的分词方法可以适用于不同的领域和语言,只要具备足够的训练数据就可以进行分词。
- 模型复杂度高:基于统计的分词方法需要建立复杂的统计模型,计算量大,需要较高的计算资源。
- 需要大量训练数据:基于统计的分词方法需要大量的训练数据来训练模型,才能取得较好的分词效果。
案例说明:
假设我们有一段文本:“我爱北京天安门”,我们希望将其分词为“我”、“爱”、“北京”、“天安门”。
首先,我们需要对文本进行预处理,将其转换为词频统计结果。对于“我爱北京天安门”这句话,统计结果如下:
| 词 | 出现次数 |
|---|---|
| 我 | 1 |
| 爱 | 1 |
| 北京 | 1 |
| 天安门 | 1 |
接下来,我们可以利用HMM模型进行分词。首先,我们需要确定模型中的状态和转移概率。在这个例子中,我们的状态就是上述的四个词,转移概率可以通过训练文本进行学习。具体来说,我们可以利用Baum-Welch算法来估计HMM模型的参数,包括转移概率和发射概率。
假设我们已经得到了转移概率矩阵和发射概率矩阵,接下来就可以利用Viterbi算法来计算最可能的分词结果。根据计算,最可能的分词结果为“我”、“爱”、“北京”、“天安门”。
具体来说,Viterbi算法是一种动态规划算法,用于在HMM模型中寻找最可能的状态序列。在我们的例子中,Viterbi算法的过程如下:
- 初始化:对于每个状态Si(i=1,2,3,4),设置一个初始概率P(Si),表示在当前位置为Si的概率。对于所有的状态,设置一个初始概率P(S0),表示在当前位置开始出现Si的概率。根据这些初始概率,我们可以得到一个初始的路径概率P(S0)。
- 递推:对于每个时间t(t=1,2,3,4),遍历所有的状态Si,计算在时刻t,以Si为当前状态时的最大路径概率P(Si)。在计算路径概率时,我们需要考虑当前状态Si的发射概率和从上一个时刻转移到当前时刻的转移概率。
- 终止:在最后一个时刻,选择路径概率最大的状态作为最终的状态。在我们的例子中,最终的状态就是“天安门”。
- 回溯:从最终的状态开始,根据转移概率矩阵回溯到起始状态,得到最可能的分词结果。
最后,我们输出最可能的分词结果“我”、“爱”、“北京”、“天安门”。
实际的分词任务可能需要更复杂的模型和算法,以及更多的训练数据。由于语言模型的复杂性和数据的不充分性,基于统计的分词方法也存在一定的误差率和挑战。
4.举例
4.1科大讯飞的分词方法
科大讯飞公司采用基于大数据和用户行为进行分词。其分词系统具备多种功能,包括分词、词性标注和命名实体识别等,旨在全面支撑机器对基础文本的理解与分析。
在分词方面,科大讯飞公司的分词系统可以切分成词序列。对于汉语中的词,它是承载语义的最基本的单元。分词是信息检索、文本分类、情感分析等多项中文自然语言处理任务的基础。
例如,原文:科大讯飞是一家专注于智能语音和人工智能领域的公司。
分词结果:科大/讯飞/是/一家/专注于/智能/语音/和/人工智能/领域/的/公司。
词性标注结果:科大/ORG讯飞/ORG是/v一家/m专注于/v智能/n语音/n和/c人工智能/n领域/n的/u公司/n。
其中,“科大”和“讯飞”是公司名,“是”是动词,“一家”是数量词,“专注于”是动词,“智能”和“语音”是名词,“和”是连词,“人工智能”是名词,“领域”是名词,“的”是助词,“公司”是名词。
此外,科大讯飞公司的分词系统还具备词性标注和命名实体识别等功能。词性标注是指为自然语言文本中的每个词汇赋予一个词性的过程,例如动词、名词、形容词等。命名实体识别则是指在句子的词序列中定位并识别人名、地名、机构名等实体。
这些功能可以帮助机器更好地理解文本,并进行更准确的分析和处理。科大讯飞公司的分词系统基于大数据和用户行为进行训练和优化,以提高其分词的准确性和效率。
4.2代码实战
举个例子,我们可以使用jieba分词库来进行中文分词。jieba分词库是一个基于Python的中文分词工具,支持三种分词模式:精确模式、全模式和搜索引擎模式。
下面是一个使用jieba分词库进行中文分词的例子:
import jieba
text = "我爱自然语言处理技术"
seg_list = jieba.cut(text, cut_all=False)
print(" / ".join(seg_list))输出结果为:
我爱 / 自然语言 / 处理 / 技术详细代码:
import jieba
import jieba.analyse
from tkinter import *
# 预处理数据
def pre_process(text):
# 去除停用词
stopwords = ["的", "了", "在", "是", "我", "有", "和", "就", "不", "人", "都", "一", "一个", "上", "也", "很", "到", "说", "要", "去", "你", "会", "着", "没有"]
text = [word for word in text if word not in stopwords]
return text
# 训练模型
def train_model(text):
# 使用jieba库训练模型
jieba.analyse.set_stop_words(stopwords)
jieba.analyse.set_idf_path("idf.txt")
seg_list = jieba.cut(text)
return seg_list
# 实现分词算法
def segment(text):
# 预处理数据
text = pre_process(text)
# 训练模型
seg_list = train_model(text)
# 对新文本进行分词
new_seg_list = jieba.cut(text)
return new_seg_list
# 可视化界面
def visualize():
root = Tk()
root.title("中文分词工具")
label = Label(root, text="请输入待分词的文本:")
label.pack()
entry = Entry(root)
entry.pack()
button = Button(root, text="分词", command=lambda: segment(entry.get()))
button.pack()
label2 = Label(root, text="分词结果:")
label2.pack()
result = Text(root)
result.pack()
root.mainloop()
# 调用可视化界面进行分词处理
visualize()该示例代码包括预处理、训练、实现分词算法和可视化界面的实现。其中,预处理函数pre_process用于去除停用词,训练函数train_model使用jieba库训练模型,实现分词算法函数segment对新的文本进行分词处理,可视化界面函数visualize使用Python的GUI库Tkinter创建一个简单的界面,用户可以输入待分词的文本,并显示分词结果。