MapRdeuce编程示例——词频统计
一、MapRdeuce的词频统计的过程
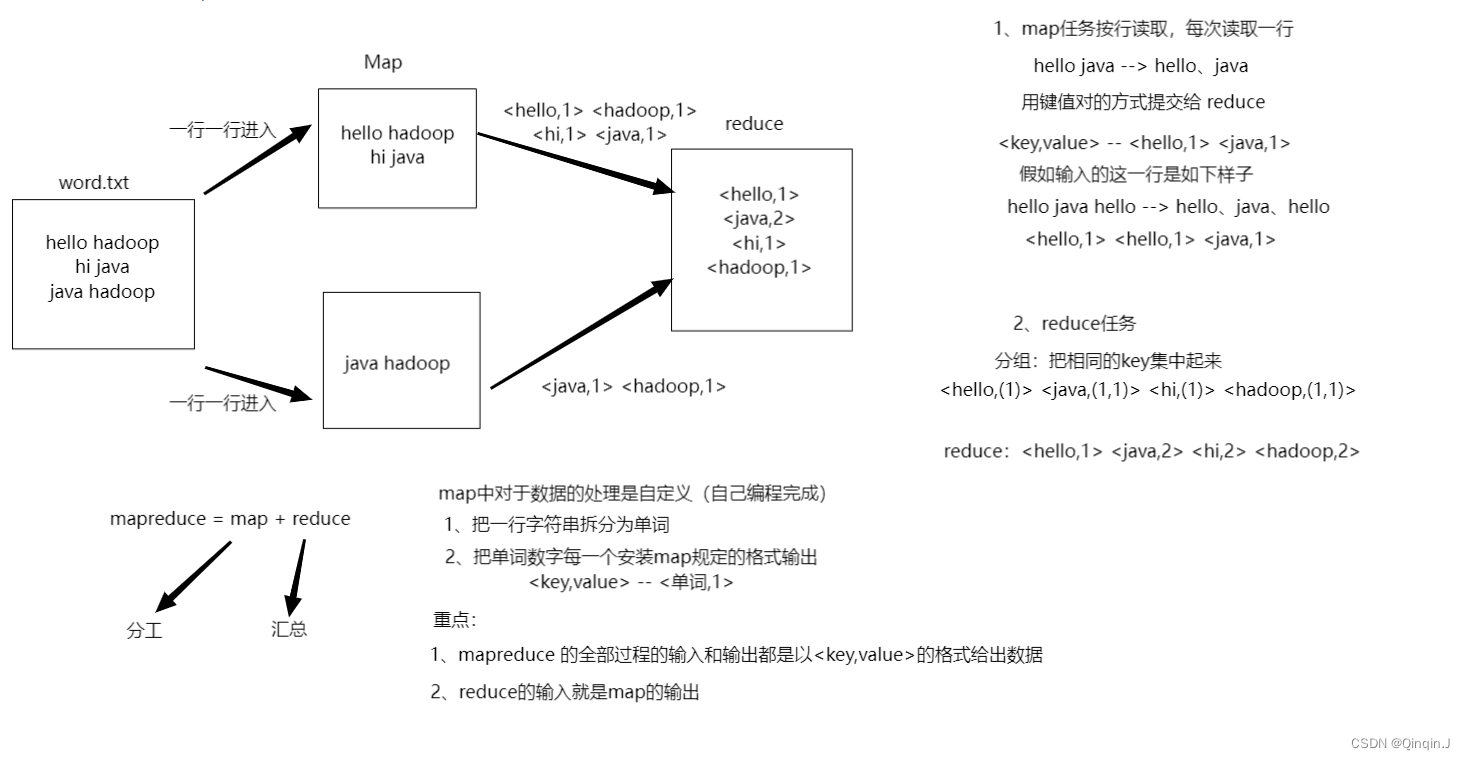
二、编程过程
1、Mapper 组件
WordcountMapper.java
package com.itcast.mrdemo;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* Map 需要指定四个泛型,用来限定输入和输出的 key 和 value 的类型
*
* hadoop 有自己的数据类型,不使用 java 的数据类型,对应的 java 类型名字后面 + Writable 就是 hadoop 类型
* String 除外,String 对于的 hadoop 类型叫做 Text
* <2, "java">
* */
public class WordcountMapper extends Mapper<LongWritable, Text,Text,IntWritable> {
//重写Ctrl+o
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
/**
* 1、把一行字符串拆分成单词 "hello java"
* 2、把单词、数字每一个按照 map 规定的格式输出
*/
// 把 hadoop 类型转换为 java 类型(接收传入进来的一行文本,把数据类型转换为 String 类型)
String line = value.toString();
// 把字符串拆分为单词
String[] words = line.split(" ");
//使用 for 循环把单词数组胡每个单词输出
for (String word : words){
context.write(new Text(word), new IntWritable(1));
}
}
}
2、Reducer 组件
WordcountReducer.java
package com.itcast.mrdemo;
import org.apache.hadoop.io.IntWritable;
//import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* Reduce 需要指定四个泛型,用来限定输入和输出的 key 和 value 的类型
* 1、Map 的输出就是 Reduce 的输入
* 2、Reduce 的输出是 <"java", 2>
*/
public class WordcountReducer extends Reducer<Text,IntWritable,Text,IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable value : values){
sum ++;
}
context.write(key,new IntWritable(sum));
}
}
3、MapRdeuce 运行模式
MapRdeuce 程序的运行模式主要有两种
(1)本地运行模式
在当前的开发环境模拟 MapRdeuce 执行环境,处理的数据及输出结果在本地操作系统WordcountDriver.java
package com.itcast.mrdemo;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class WordcountDriver{
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//通过 Job 来封装本次 MR 的相关信息
Configuration conf = new Configuration();
//System.setProperty("HADOOP_USER_NAME","root");
//配置 MR 运行模式,使用 local 表示本地模式,可以省略
conf.set("mapreduce.framework.name","local");
Job job = Job.getInstance(conf);
//指定 MR Job jar 包运行主类
job.setJarByClass(WordcountDriver.class);
//指定本次 MR 所有的 Mapper Reducer 类
job.setMapperClass(WordcountMapper.class);
job.setReducerClass(WordcountReducer.class);
//设置业务逻辑 Mapper 类的输出 key 和 value 的数据类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//设置业务逻辑 Reducer 类的输出 key 和 value 的数据类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//使用本地模式指定处理的数据所在的位置
FileInputFormat.setInputPaths(job,"D:/homework2/Hadoop/mr/input");
//使用本地模式指定处理完成之后的结果所保存的位置
FileOutputFormat.setOutputPath(job, new Path("D:/homework2/Hadoop/mr/output"));
//提交程序并且监控打印程序执行情况
boolean res = job.waitForCompletion(true);
//执行成功输出 0 ,不成功输出 1
System.exit(res ? 0 : 1);
}
}
运行结果为:

(2)集群运行模式
-
*在HDFS中创建文件
在HDFS中的/input目录下有word.txt文件,且文件中编写有内容(内容随意编写)

-
*对 WordcountDriver.java 修改
修改WordcountDriver.java中的路径为HDFS上的路径
package com.itcast.mrdemo;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class WordcountDriver{
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//通过 Job 来封装本次 MR 的相关信息
Configuration conf = new Configuration();
//System.setProperty("HADOOP_USER_NAME","root");
//配置 MR 运行模式,使用 local 表示本地模式,可以省略
conf.set("mapreduce.framework.name","local");
Job job = Job.getInstance(conf);
//指定 MR Job jar 包运行主类
job.setJarByClass(WordcountDriver.class);
//指定本次 MR 所有的 Mapper Reducer 类
job.setMapperClass(WordcountMapper.class);
job.setReducerClass(WordcountReducer.class);
//设置业务逻辑 Mapper 类的输出 key 和 value 的数据类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//设置业务逻辑 Reducer 类的输出 key 和 value 的数据类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//使用本地模式指定处理的数据所在的位置
FileInputFormat.setInputPaths(job,"/input");
//使用本地模式指定处理完成之后的结果所保存的位置
FileOutputFormat.setOutputPath(job, new Path("/output"));
//提交程序并且监控打印程序执行情况
boolean res = job.waitForCompletion(true);
//执行成功输出 0 ,不成功输出 1
System.exit(res ? 0 : 1);
}
}
-
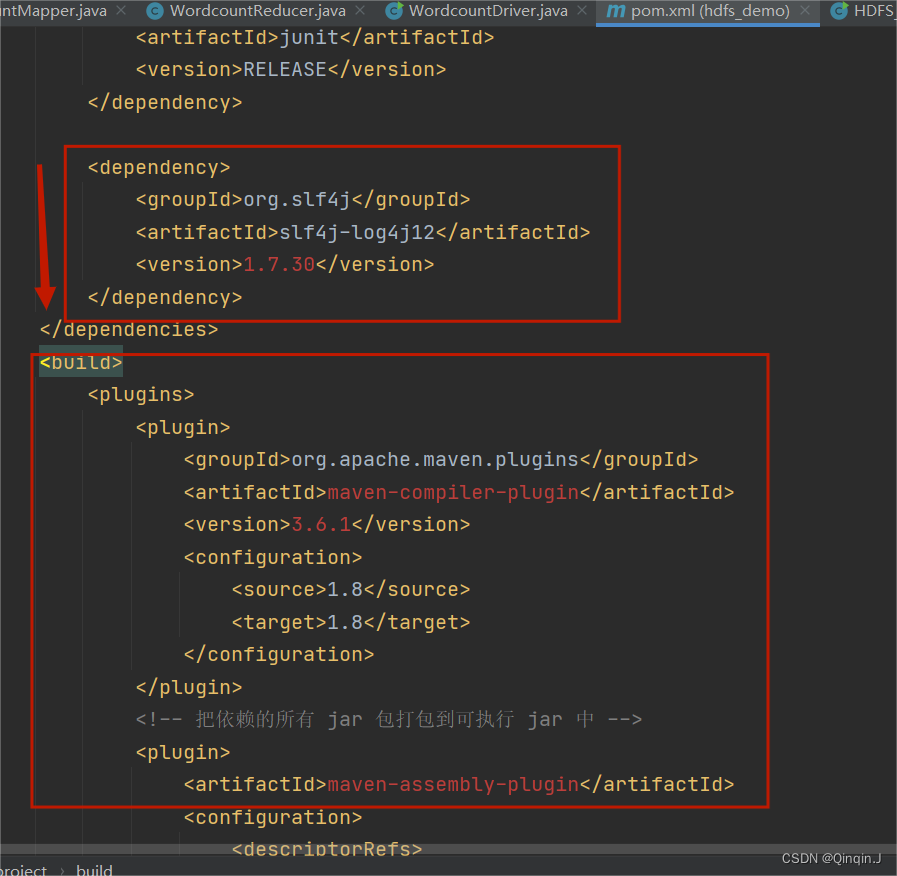
*对pom.xml添加内容
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.30</version>
</dependency> <build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.6.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<!-- 把依赖的所有 jar 包打包到可执行 jar 中 -->
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>在这个位置进行添加
-
*在resources创建文件
在resources创建文件log4j.properties
添加以下内容
log4j.rootLogger=INFO, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spring.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n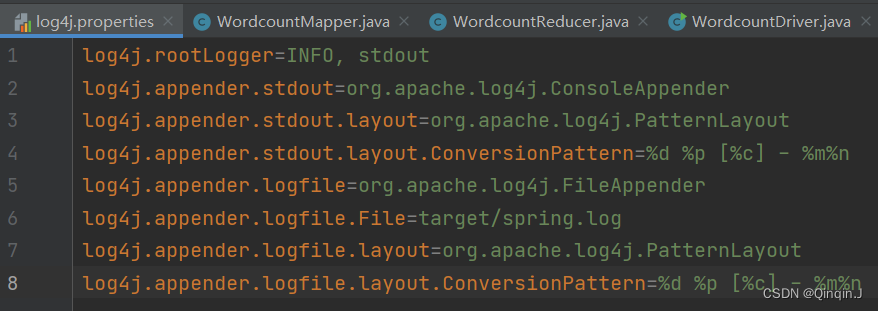
-
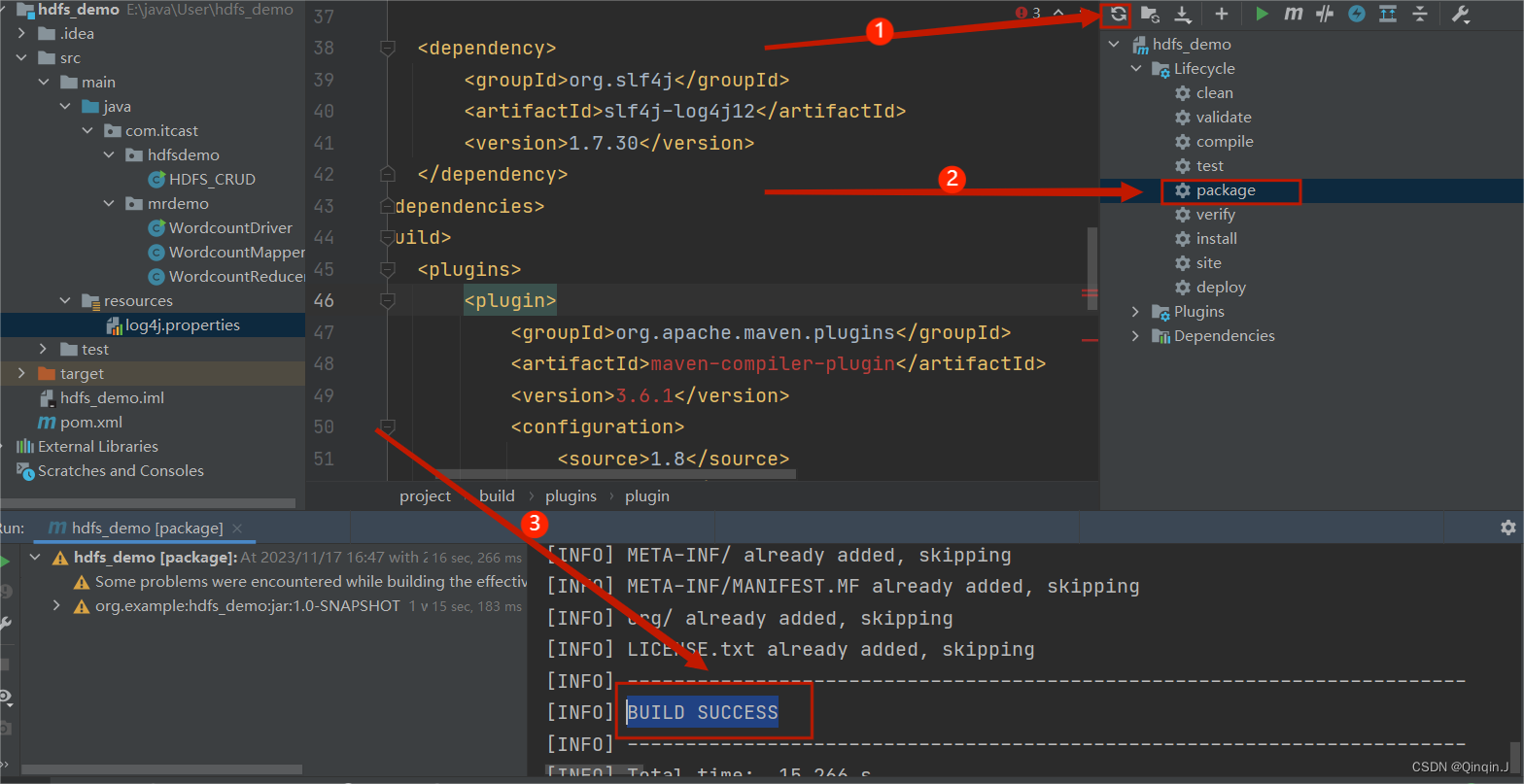
*打包成jar包
双击,进行打包
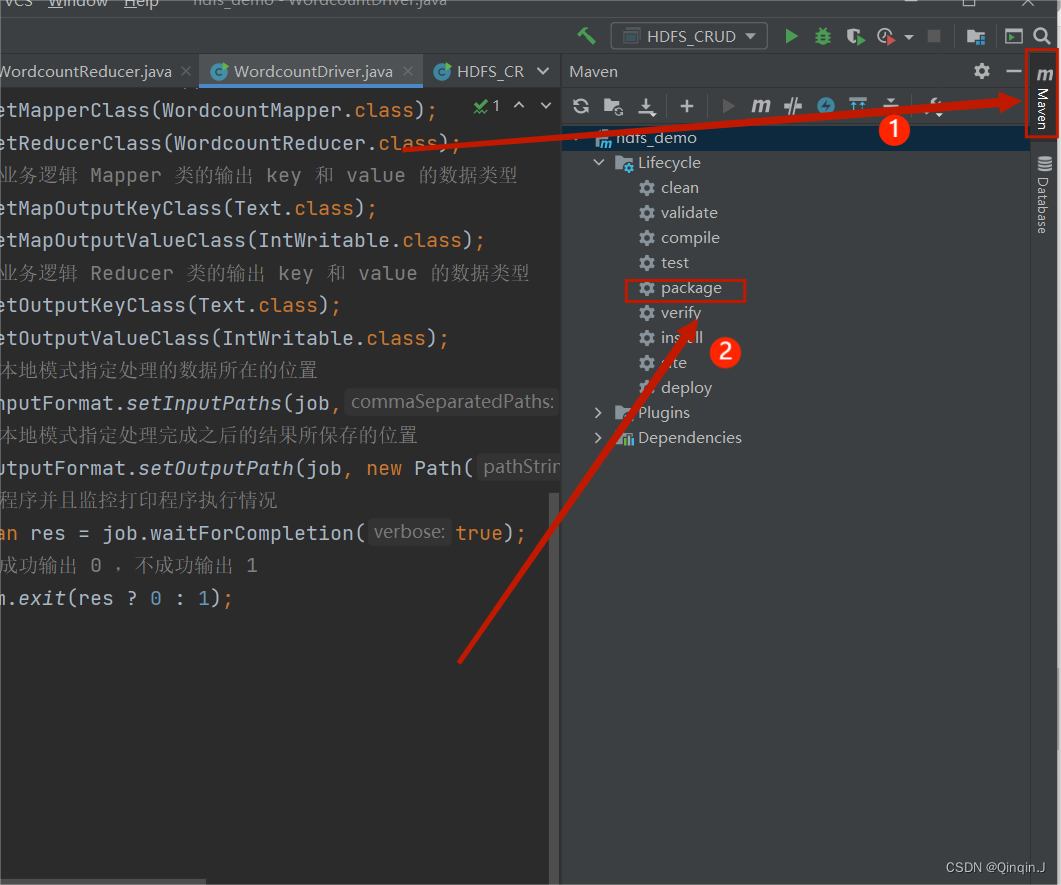
结果出现以下字段则打包成功
-
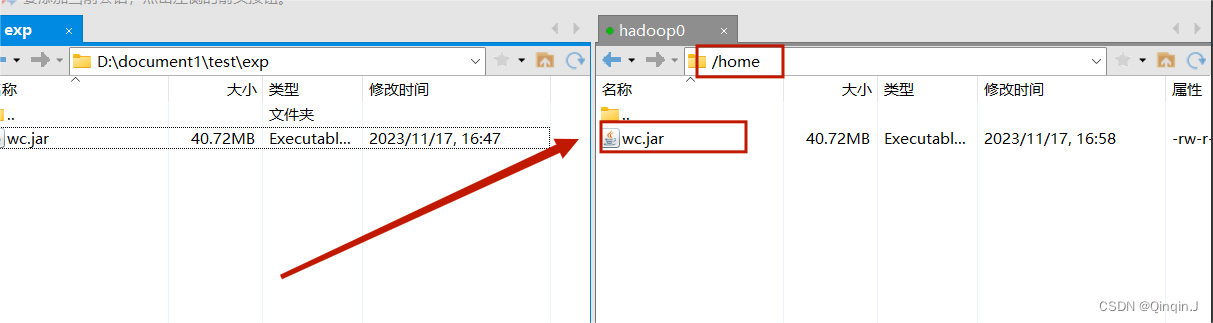
*上传到虚拟机的home目录下
右键打开

重命名为wc

随便复制到一个目录下
使用远程连接工具(Xshell或者SecurityCRT)进行上传
-
*进行集群运行
进入home目录
cd /home
ll
在 WordcountDriver.java下复制路径

hadoop jar wc.jar com.itcast.mrdemo.WordcountDriver运行结果
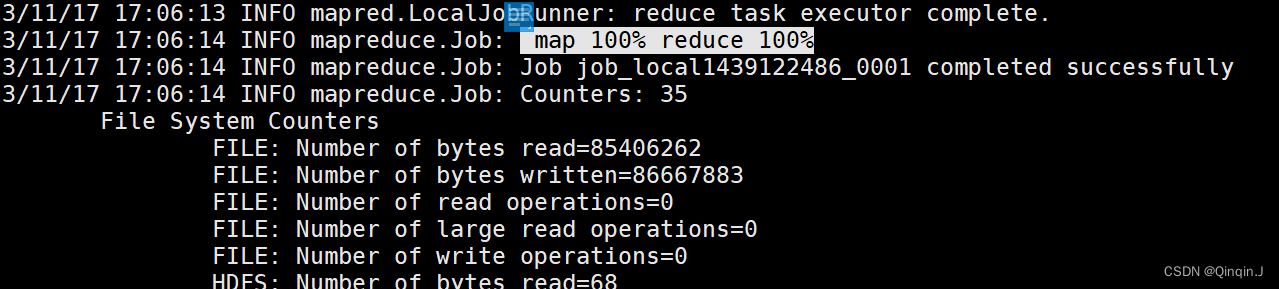
-
*查看HDFS 集群
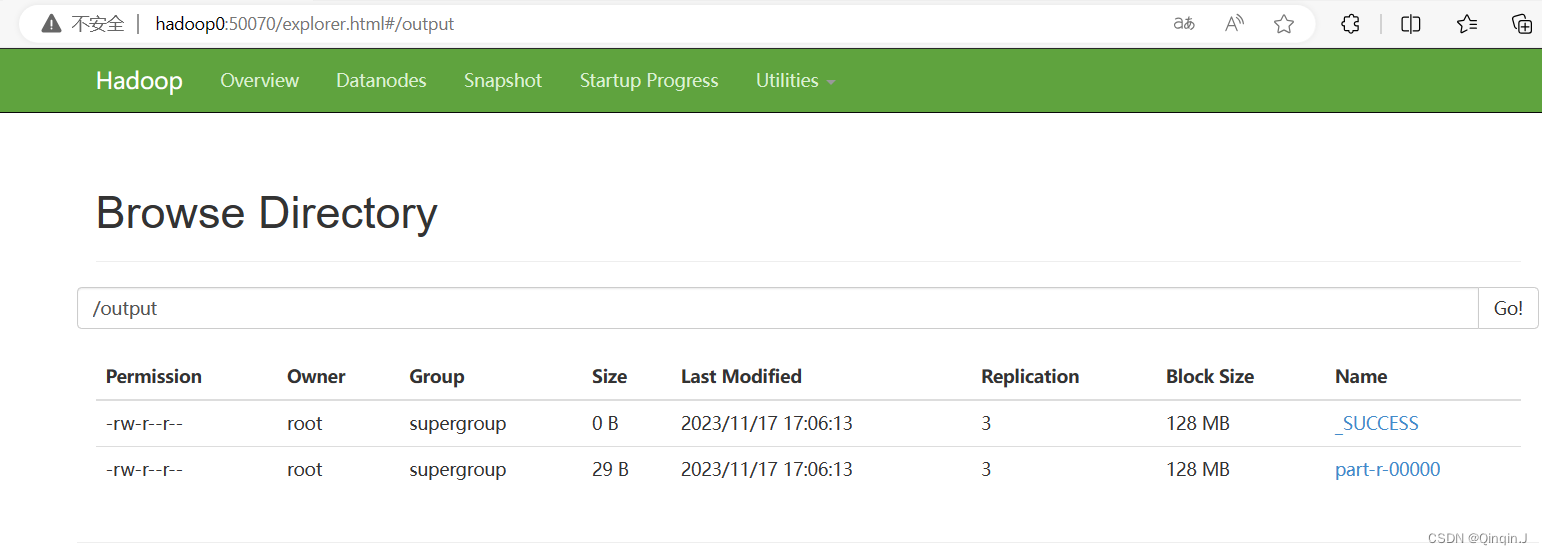
进行查看
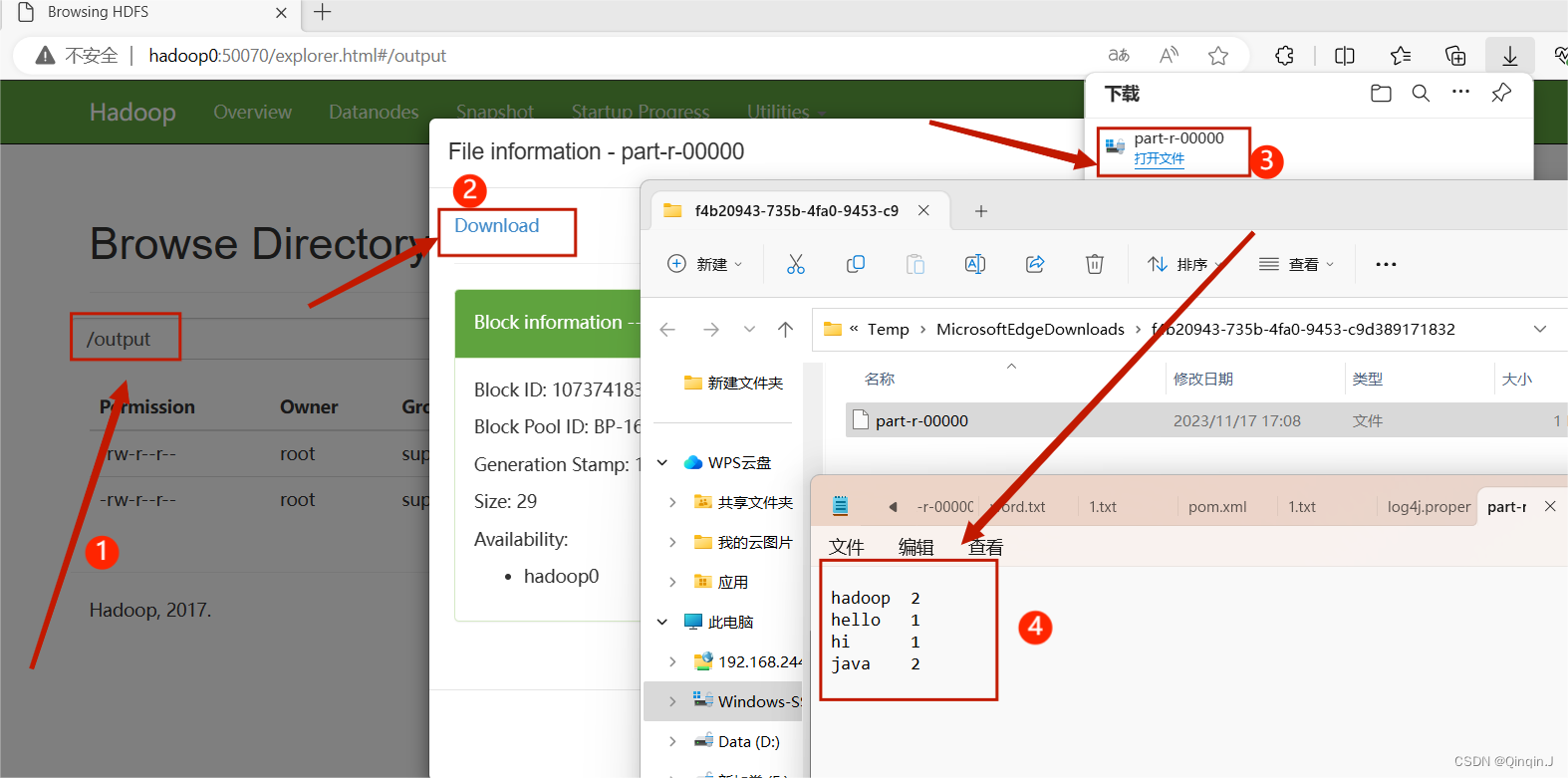
集群运行成功
4、运行前准备操作
现在目录下创建一个文本
编写内容(随意编写)

5、Error while running command to get file permissions : java.io.IOException: (null) entry in command string: null ls -F D:\homework2\Hadoop\mr\input\word.txt
出现以下错误

解决方法一
下载winutils.exe和hadoop.dll放到C:\Windows\System32
链接:https://pan.baidu.com/s/1XwwUD9j3YT2AJMUNHmyzhw
提取码:q7i7
解决方法二
输入指定文本路径

然后运行













![23111701[含文档+PPT+源码等]计算机毕业设计javaweb点餐系统全套餐饮就餐订餐餐厅](https://img-blog.csdnimg.cn/img_convert/5ba3b2e41f5bf233bf4cddda4a3181af.png)