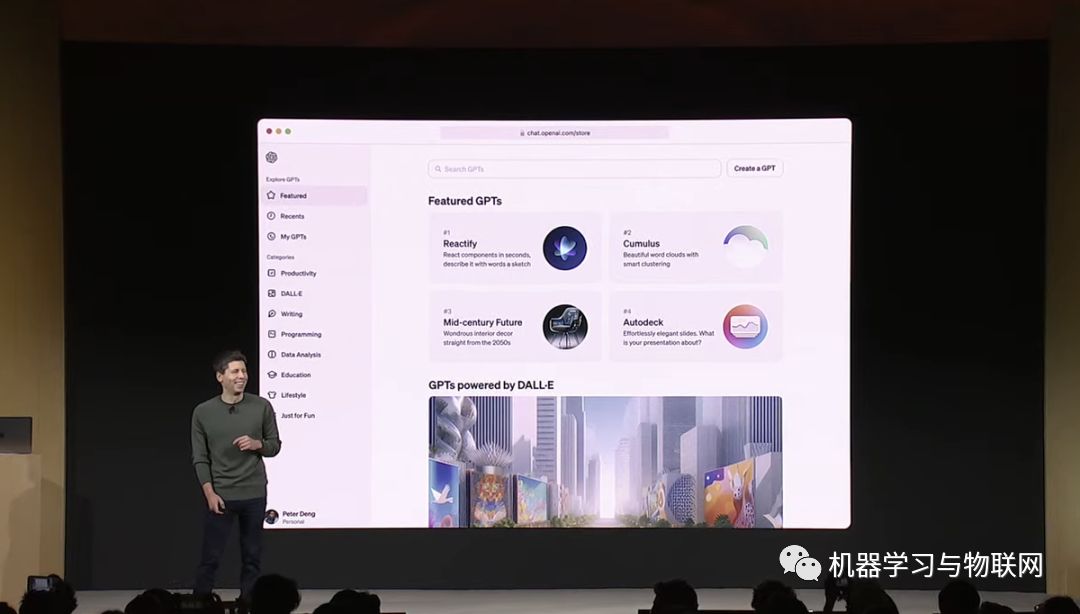
目录
一、脚本适用范围
二、将脚本配置到浏览器
三、脚本用法
四、脚本原理
一、脚本适用范围
脚本适用范围:一次性提取任意网站的布局类似的数据,例如 淘宝的商品价格、微博的热搜标题、必应搜索的图片链接

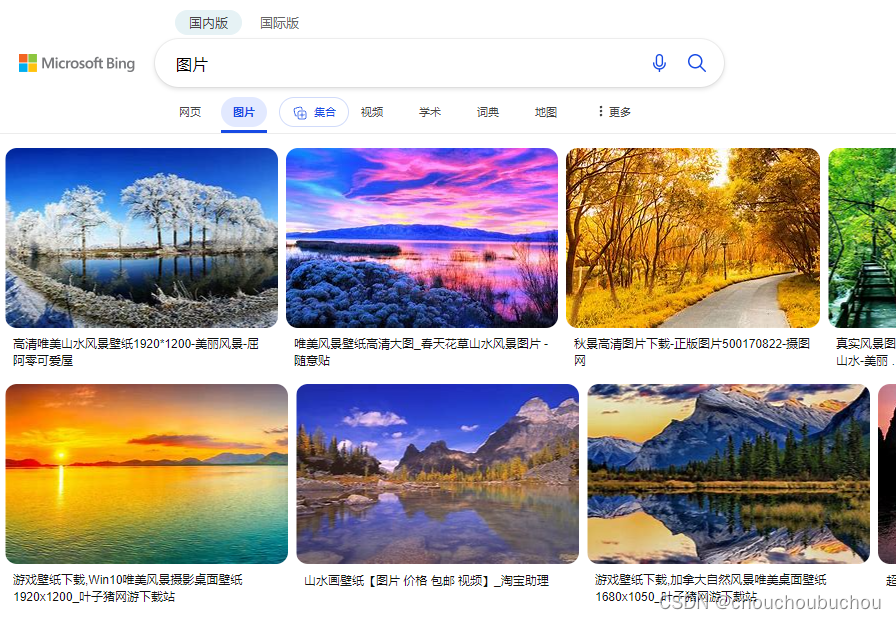
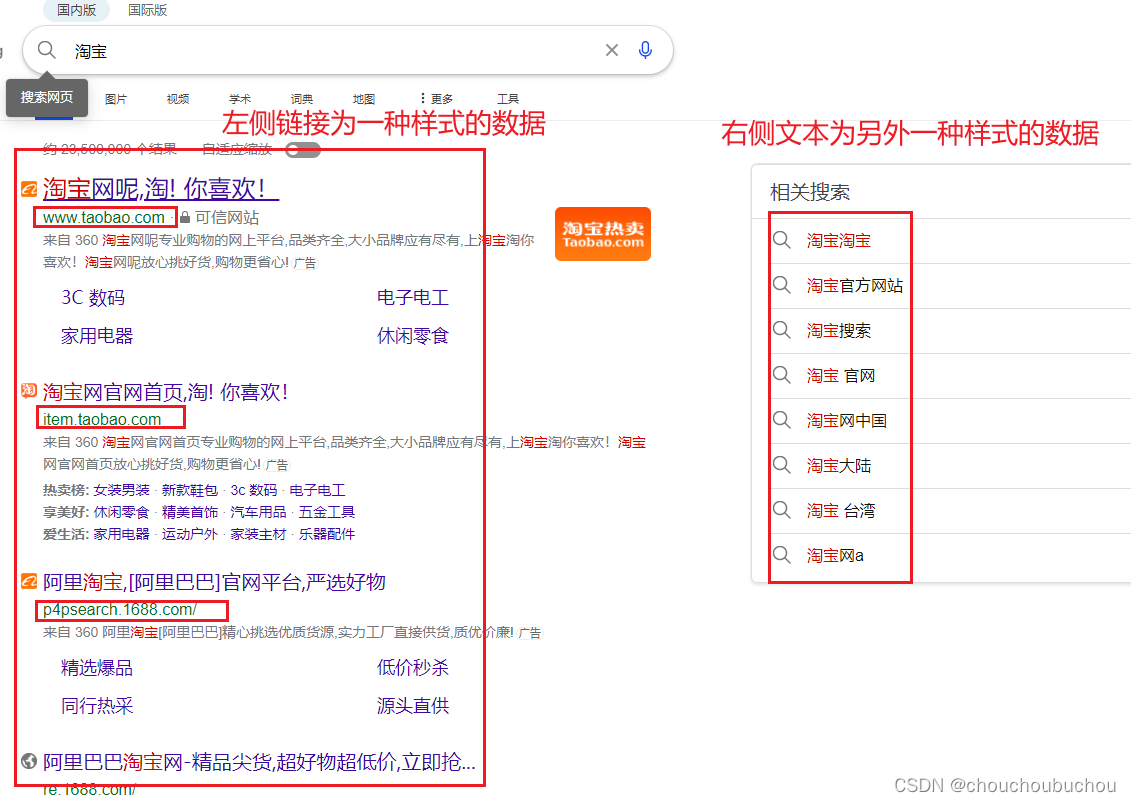
脚本不适用范围:页面布局不相似的数据。如下图圈出了两种样式的数据,不能一次性提取,需要手动分两次提取。
二、将脚本配置到浏览器
步骤:
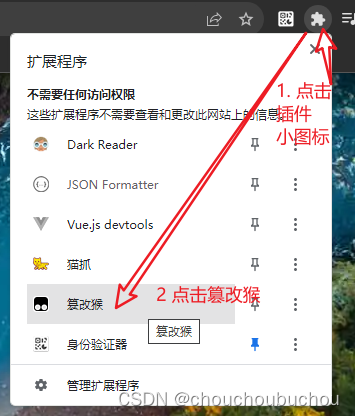
(1)浏览器安装Tampermonkey(中文名 油猴、篡改猴)(可参考:油猴(Tampermonkey)安装教程-CSDN博客)
(2)JavaScript 代码保存到 Tampermonkey (中文名 油猴、篡改猴)中(可参考:)


(3)之后每次打开任意一个网页,浏览器页面右下角会出现三个输入框和一个按键,如下图

三、脚本用法
步骤:
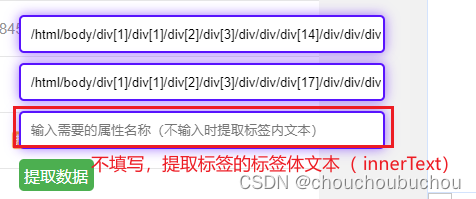
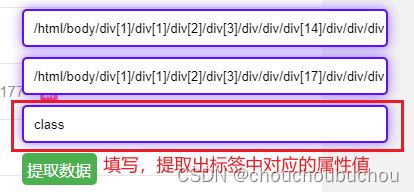
(1)从类似的数据中选择两条,拷贝它们的 xpath 粘贴到脚本生成的前两个输入框中



(2)填入数据对应的标签的属性名称到第三个框中,如果不填,则提取标签体的文本(innerText)
(3)点击提取数据,会出现弹窗,说明结果。提取出的数据以及拷贝到了粘贴板,直接Ctrl+V即可粘贴

四、脚本原理
如果元素样式类似,则它们在HTML源码的标签树路径应该是类似的(xpath路径就是寻找元素的一种方式)。
给定两个xpath:
/html/body/div[1]/div[1]/div[2]/div[3]/div/div/div[14]/div/div/div/div/span[2]/span[1]
/html/body/div[1]/div[1]/div[2]/div[3]/div/div/div[17]/div/div/div/div/span[2]/span[1]
找出它们的数字差异,删除,得到的xpath即可匹配页面中所有类似的元素
/html/body/div[1]/div[1]/div[2]/div[3]/div/div/div/div/div/div/div/span[2]/span[1]
再给出需要提取的数据在标签中对应的属性名称,就可以提取出需要的数据

![[pybind11] debug C++代码](https://img-blog.csdnimg.cn/a8b519da62b44e79a0e3af5cb540231e.png)