在智能客服系统中,数据预处理是进行自然语言处理(NLP)的关键步骤之一。它是对用户输入的文本数据进行分析、处理和转换的过程,目的是将原始文本数据转化为计算机可理解的语言,为后续的智能回答提供支持。
1.什么是数据预处理?
数据预处理的主要内容包括分词、去停用词、词性标注、命名实体识别、依存句法分析等任务,旨在将文本转化为计算机可处理的数据格式。例如,分词可以将一句话拆分为单个词语,去停用词可以去掉无用的标点符号、语气词等,词性标注可以标注每个词语的词性,命名实体识别可以识别出人名、地名、机构名等实体信息,依存句法分析可以分析出句子中的语法结构和关系。
这些预处理任务可以帮助智能客服系统更好地理解用户的问题和需求,从而提供更准确、更有针对性的回答。同时,数据预处理还可以将不同渠道、不同格式的数据进行统一和规范,提高数据的可读性和可用性。
2.举例
2.1预处理任务案例
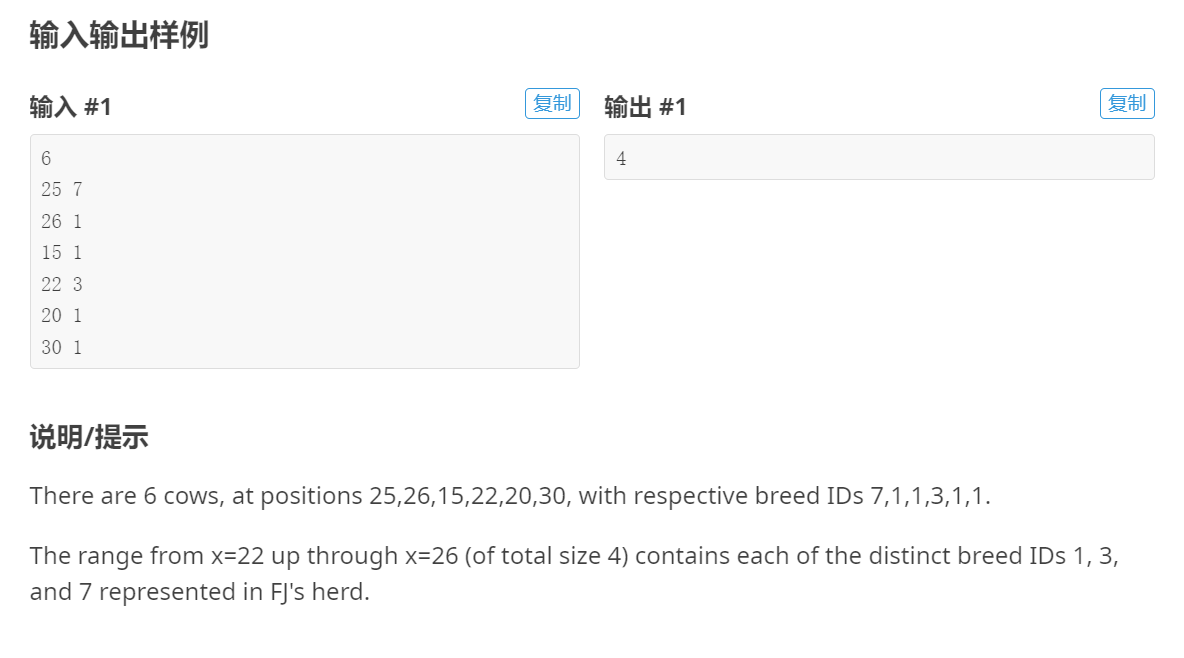
假设有一个智能客服系统,用户输入的文本是:“我在北京朝阳区,明天要去机场,怎么走最快?”
数据预处理的任务包括:
- 分词:将文本拆分为单个词语,例如“我”、“在”、“北京”、“朝阳区”、“明天”、“要去”、“机场”、“怎么”、“走”、“最快”。
- 去停用词:去掉无用的标点符号、语气词等,例如“我”、“了”、“在”、“和”等。
- 词性标注:标注每个词语的词性,例如“我”是代词,“北京”是地名,“机场”是地名,“怎么”是疑问词,“走”是动词,“最快”是形容词。
- 命名实体识别:识别出人名、地名、机构名等实体信息,例如“北京朝阳区”、“机场”。
- 依存句法分析:分析出句子中的语法结构和关系,例如主语是“我”,谓语是“要去”,宾语是“机场”,状语是“明天”、“最快”。
2.2预处理代码展示
import jieba
from jieba.analyse import cut_for_search
# 待处理的文本数据
text = "我在北京朝阳区,明天要去机场,怎么走最快?"
# 分词
seg_list = cut_for_search(text)
print("分词结果:", "/".join(seg_list))
# 去停用词
stopwords = ["在", "和", "我", "了"]
filtered_seg_list = [word for word in seg_list if word not in stopwords]
print("去停用词结果:", "/".join(filtered_seg_list))
# 词性标注
import jieba.posseg as pseg
tags = pseg.cut(text)
print("词性标注结果:", "/".join([word + " " + tag for word, tag in tags]))这段代码使用了 jieba 库进行分词和词性标注,并去除了指定的停用词。输出结果如下:
分词结果: 我/在/北京/朝阳区/,/明天/要/去/机场/,/怎么/走/最快/?
去停用词结果: 北京/朝阳区/明天/要/去/机场/怎么/走/最快
词性标注结果: 我/rb/ 在/v/北京/LOC/朝阳区/LOC/ ,/w/ 明天/TIME/ 要/v/去/v/机场/LOC/ ,/w/ 怎么/r/走/v/最快/a/ ?/w 其中,rb 表示副词,v 表示动词,TIME 表示时间,LOC 表示地点,w 表示虚词,a 表示形容词。
经过数据预处理后,用户输入的文本被转化为计算机可理解的语言,可以作为输入传递给后续的模型进行智能回答。模型可以根据用户的地理位置、出行需求等信息,提供最优的出行方案。
3.其他应用场景
数据预处理在许多应用案例中都非常重要,特别是在机器学习和数据分析领域。以下是一些数据预处理应用案例:
- 垃圾邮件识别:通过对邮件文本进行预处理,包括分词、去停用词、词性标注等任务,可以提取出邮件的关键信息,并判断其是否为垃圾邮件。
- 社交媒体分析:社交媒体上的文本数据包含大量的噪声和无关信息,通过数据预处理技术,可以提取出有用的特征,例如情感、主题、关键词等,用于舆情监控、品牌形象分析等应用。
- 智能客服系统:智能客服系统需要对用户输入的文本进行自然语言处理,包括分词、词性标注、命名实体识别、依存句法分析等任务,以提供准确的回答和解决方案。
- 文本分类和聚类:文本分类和聚类是自然语言处理中的常见任务,通过对文本进行预处理,提取出有用的特征,可以训练出高效的分类和聚类模型,用于文本分类、主题建模等应用。
- 图像分类和目标检测:在计算机视觉领域,图像预处理是必不可少的步骤之一,包括图像去噪、增强、变换等任务,以提取出图像中的关键特征,并用于训练目标检测、分类等模型。
- 语音识别和合成:语音识别和合成是自然语言处理中的重要应用,通过对语音信号进行预处理,例如滤波、分帧、特征提取等任务,可以提取出语音的特征表示,用于语音识别、语音合成等应用。
数据预处理是机器学习和数据分析中的重要步骤之一,通过对数据进行清洗、转换和特征提取等操作,可以提高数据的质量和可用性,为后续的模型训练和数据分析提供更好的支持。
基础课6——开放领域对话系统架构-CSDN博客文章浏览阅读149次,点赞6次,收藏2次。开放领域对话系统需要具备更广泛的语言理解和生成能力,以便与用户进行自然、流畅的对话。https://blog.csdn.net/2202_75469062/article/details/134428523?spm=1001.2014.3001.5501