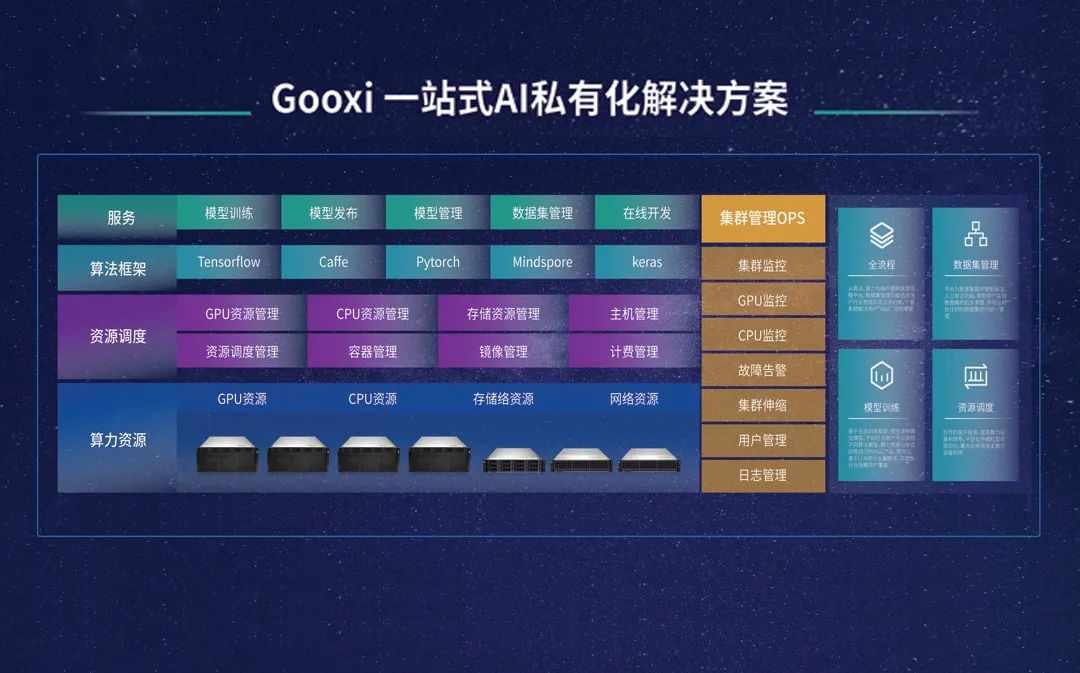
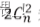LLM近期研究是井喷式产出,如此多的文章该处何处下手,他们到底又在介绍些什么、解决什么问题呢?“为学日增,为道日损”,我们该如何从如此多的论文中找到可以“损之又损以至于无”的更本质道或者说是这个方向的核心模型。只有有了这样的更核心根本的模型,我们才能更容易的把控LLM的发展方向,不至于“乱花渐欲迷人眼”,把自己丢失在论文的海洋。
LLM建模
LLM是对什么的建模
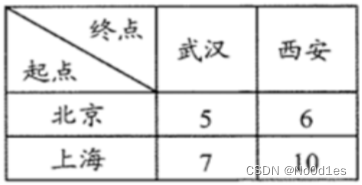
从点击率预估说起
熟悉广告营销的朋友应会很熟悉 ctrcvrcpm 这个公式,其实互联网的一大半的员工也是围绕这个公司生存。所谓的黑客增长、用户生命周期、活动运营、内容运营…基本都绕不开这个公式。
那么这个公式到底是怎么来的呢,为何有如此魔力可以养活成千上万的员工呢。其实这个公式就是对营销的3阶段的一个建模:
**促达用户:**通过什么手段可以把东西促达用户,促达用户后您能吸引到多少用户看你表演
**用户转化:**吸引到的用户经过你的一些列表演,有多少用户为之买单
**成本收益:**为了这次在用户面前露脸表演的机会你付出多少成本,你能得到多少收入,收益比是否正向
对营销业务过程建模完后,接下来要做的事就是如何完善和提高每个模块的性能;让商业活动可以正向循环。也就是说互联网的员工基本都在围绕这个大的业务建模,在每个模块下构建更牛逼高效系统来去的竞争也优势。举例来讲:
促达用户转化率提升:
1.找到人数更多的流量路口,提高覆盖的人口基数——内容吸引搞流量增长、权益激励吸引流量、活动营销吸引流量、服务入口吸引流量…
2.找到更符合自己业务的流量入口,提高匹配率——用户画像、look like、社区发现、点击率预估系统…
3.发现流量中人群特点迎合流量制造服务,发现制造机会——人群洞察、舆情洞察、新物种造货、事件营销、意图理解…
用户转化率提升:
1.提高服务和用户需求点匹配度——点击率预估、购买用户意图分析、购买用户相似人群发现、服务个性化呈现、粉丝经济…
2.提高有需求用户复购的机会——复购时机发现、关联推荐、沉默用户激活、会员运营、大促活动、618、1111…
3.制造需求消费机会——私域运营、种草、粉丝营销、短视频营销、场景化营销、演绎营销、新物种、根据用户需求造货…
成本收益:
1.田忌赛马,点击率广告竞价——DSP、DMP提高预测准确率获得更多下沉高价值竞争
2.高价值机会发现——品牌广告(汽车、耐用品、莆田系、牙科…)
3.提高产品价值,个性化服务——软文广告、和高热up合作定向营销、出教程普及逐步把自己产品变标准(微软各种产品、各种云厂商解决方案)…
LLM建模了什么
上面对广告点击率预估这个已经很成熟的产业做了介绍,介绍了这个产业事如果对营销业务进行建模,抽象成三个模块。然后整个产业是如何围绕折三个建模的模块在精进、精耕细作产生出一个可以养活几千万人的产业。对于现在大火的LLM模型如果要从火逐步转变成可以产业化,成为一个可以容纳几千万人就业的产业构建一个业务建模似乎也是必须的。然而现在的LLM还处在技术发展阶段,虽然已经有很多的应用但是很多使用者只是围绕LLM浅显的技术能力在开展。个人觉得这个阶段的LLM业务建模似乎是困难和非必要的,反倒是对LLM的技术建模能够更深刻的认识LLM是一个什么技术、在解决什么问题、后续可以如何改进是更有意义的。
LLM个人觉得其实就是对信息在做整理、总结、表达,它不只是具备信息整理、总结、表达的处理能力、同时具备把它见过的信息整理组织成他可以使用的数据来源,也就是说他拥有知识和知识加工的能力。当然现在的LLM还是初级阶段,处理知识、知识表示、知识表达能力还是不太完美的。
我们尝试对上面的描述做一个更结构化的表述:
1.LLM具备知识表示能力
2.LLM具备知识抽取、存储组织能力
**
这三个能力其实在LLM里面并非是可以剥离开来的,而是全部的混在LLM参数里面,也就是说LLM具备知识存储、知识整理、知识检索、联想、组织、表达的能力,并且是一体的全部存在它巨大的参数里面。
看起来这个业务建模是不是挺复杂的,比广告营销的模型复杂好多。并且感觉这个东西还没法想广告营销模型那样可以分成比较明显的阶段模块,全部都混在一起。
pretrain、sft、rlhf在讲什么
接触过LLM的同学应该对pretrain、sft、rlhf这几个词不陌生,那么为什么LLM的训练一定要经过这三个阶段?市面上能看到的解释都是从word2vec–elmo–in content这条路线来解释。但是感觉解释完好像还是没有特别让人置信。
针对这个问题我思考了很久,个人觉得其实用高中学过的齐次方程求解的方法来解释是比较合适的。齐次方程的求解包括了3种:齐次方程组通解、特解、约束解;其实pretrain过程对应的就是齐次方程的通解、sft过程对应的就是齐次方程的特解、RLHF过程对应的就是齐次方程的约束解。
那么如何去构建这个齐次方程呢,里面的未知数x、y、z…或者说求解空间的表示基是谁呢?又是用什么来构建出求解的等式的呢?这个齐次方程式对应的物理意义又是什么呢?
1.知识表示能力
每个知识点的表示对应的就是齐次方程的基,也就是是说这个方程的定义域集合中的每个元素可以认为是每个知识表示。
当然这个知识点的表示是隐式的,并非我们显示给进去的定义好的,所以实际做模型训练时候并没有输入这么一个知识表示(embbeding和token.json输入的不是显示独营这部分)。
2.如何去构建求解等式
输入训练的语料就是为了构建求解等式方程,所以也就是为什么语料构建需要多样化、语料不能够过多重复。过多重复的语料相当于很多求解方程是重复的,求解过程中会把很多知识表示维度变小导致模型过拟合。语料构建多样性其实就是为了构建更多差异化的求解方程,让齐次方程求解能够得到唯一解。
3.对应的物理意义
pretrain过程包含了对知识表示(基维度的确认)、知识抽取和存储组织能力的训练,也具备一定的知识检索、联想、组织能力训练。
sft过程更多是对LLM表达能力的训练,通过给定有监督的答案组来调教LLM具备检索、联想、组织能力。
RLHF过程其实就是让知识表述遵循人类约束(安全、道德、风格…)。
为什么要RAG+LLM
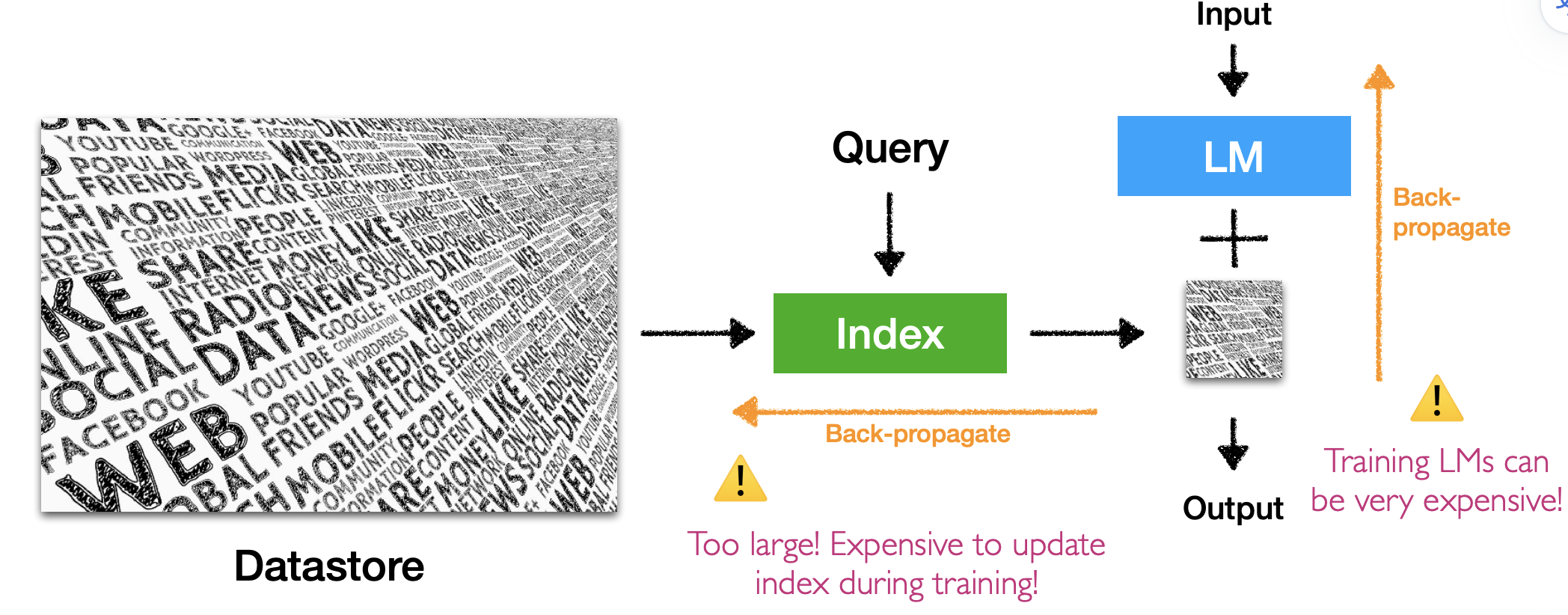
已经有了可以对知识表示、抽取、存储组织、知识检索、联想、组织表达的LLM,那为什么还需要RAG链路呢?RAG本质上又是在做什么事呢?
有了LLM之所以还需要RAG原因很简单,LLM解决不了RAG能解决的问题。那么RAG到底帮助LLM解决了什么问题,又是如何解决、为何能够解决的呢?RAG其实就是对LLM的检索、联想能力的外扩,之所以把这些部分外扩原因就在于如果完全依赖LLM的能力来解决,解决成本会很高,并且不容易控制。所以我们可以花更小的代价把有一些环节外扩出来,把信息检索、组织好想当于有一个底稿然后在让LLM做组织表达以更可控和高效的解决实际问题。
换句话讲RAG的目的就是让LLM更容易控制、更高效精准生成,通过外扩来控制单一建模的LLM,让生成更可控。对于一些知识有可能是私域或者是时事类的信息,LLM没有组织表示,如果不给输入很可能就没法给出准确答案。还有可能是LLM知识点太多,通过RAG检索到的线索来约束LLM生成边界。又或者可以通过RAG更精准可控的检索到控制条件,来约束LLM生成;或者是约束LLM生成结果的匹配度以约束下一轮持续生成。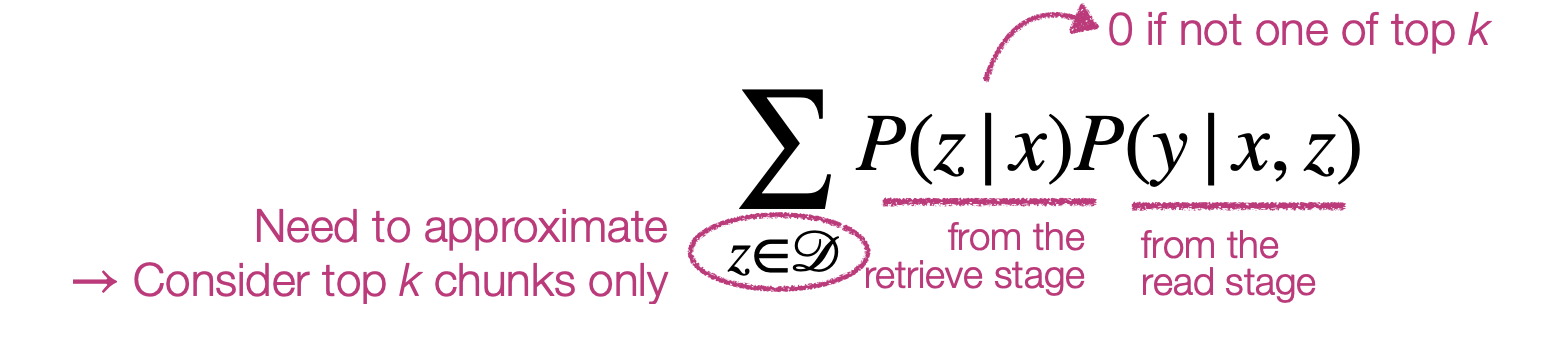
通过retrieve回来的信息来控制LLM生成的效果。
如何做RAG+LLM
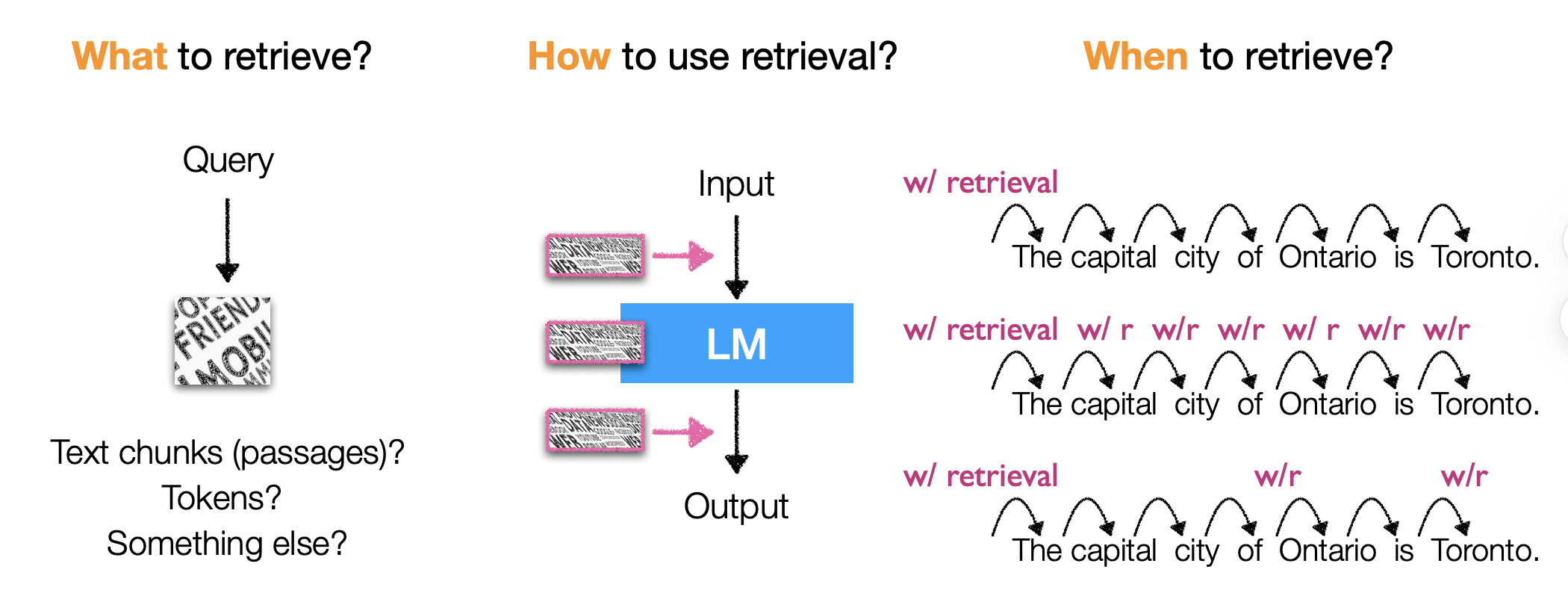
RAG+LLM看起来似乎是比较工程化的事情,这里面还有什么可以讲究的吗?确实可以把RAG做的很工程化,但是RAG+LLM能够发挥出很好的作用,更多在于个模块的相互配合,所以个人是不太建议单纯把这件事当成是一件工程化的事,否则你很快会发现这东西感觉加个RAG并不能够起到多大作用。个人觉得RAG应该是一个控制模块,如何和LLM配合好才是重点。
上图总结了最近的一些论文在做的工作,主要是围绕三个方面:
1.RAG检索回什么,是chunk、token、信息的二阶标签还是内容的语义表示;这个其实代表的定义域空间的约束
2.检索如何控制LLM生成,是作为上下文、还是作为控制权柄对生成信息做过滤、还是把检索回来信息作为控制参数嵌入LLM控制生成
3.检索的触发时间是什么时候,LLM每生成一个词就检索一次、还是生成一段话再检索约束一次、还是检索一次一直约束到生成结尾
检索如何控制LLM生成

把检索回的信息作为上下文,通过prompt方式控制LLM生成
检索回的信息作为控制参数,嵌入LLM控制生成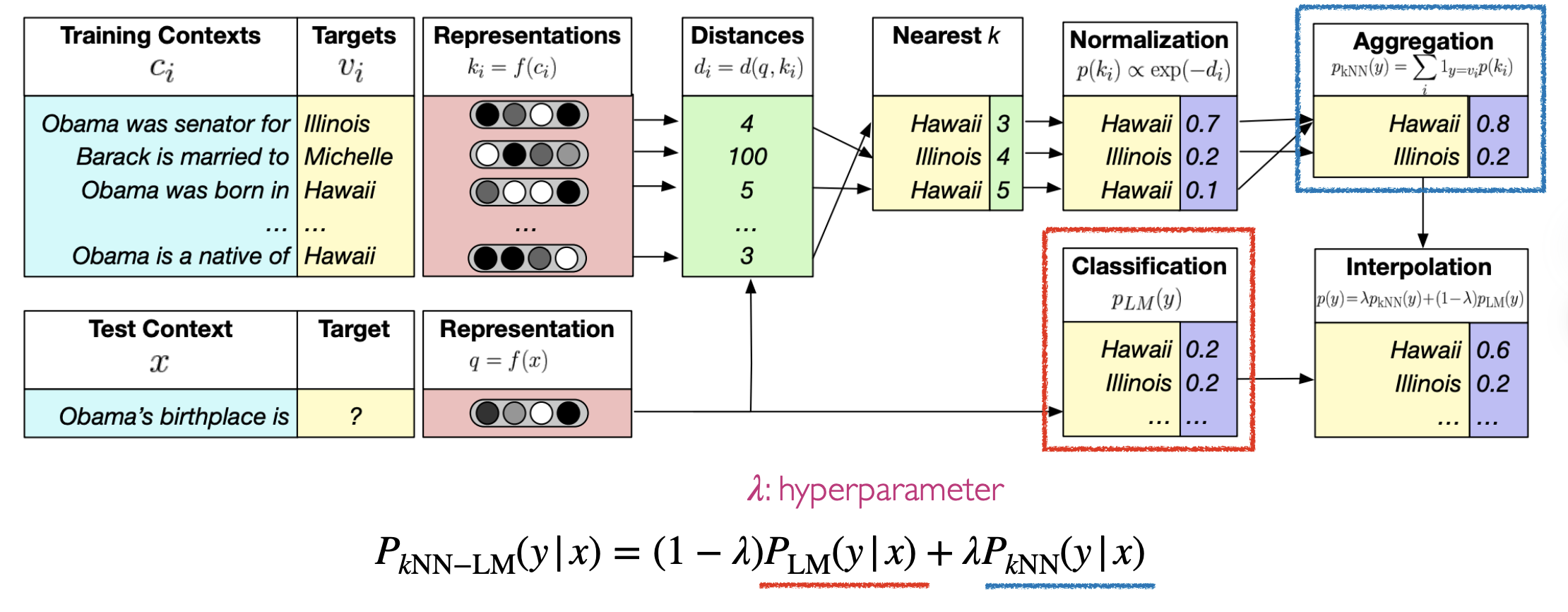
检索回的信息对LLM生成后的内容做控制约束
什么时候利用检索

有做过Motion plan的同学应该会很清楚,学院派的motion plan是分层前后端两部分,每个部分又是为了生成轨迹的质量做了很多的约束才能保证生成的轨迹符合实际需要。一样的如果把内容生成看成是知识点轨迹生成过程,那么什么时候对轨迹生成施加控制这件事就会变的很重要。
是在轨迹规划前输入约束(对应motion plan静态障碍物地图),还是可以在轨迹生成过程中走了一段计算一次约束(对应motion plan没有地图需要实时建图),还是需要每生成一个轨迹生成下一个轨迹点时候就需要加入约束(对应环境、机器人不确定性大的场景)。
这部分必须要有具体的例子才好说明,所以这部分会放在下一篇文章介绍。会尝试从最近提出的RAG论文角度来通过例子方式呈现约束时机的差异。
小结:
本文通过广告营销点击率预估的建模为例子介绍了如何对实际业务问题建模,提出了LLM是在对什么建模的假设。1.LLM具备知识表示能力
2.LLM具备知识抽取、存储组织能力
**
这三个能力其实在LLM里面并非是可以剥离开来的,而是全部的混在LLM参数里面,也就是说LLM具备知识存储、知识整理、知识检索、联想、组织、表达的能力,并且是一体的全部存在它巨大的参数里面。
介绍完LLM是对什么过程建模,然后介绍了现在流行的pretrain、sft、rlhf实际上是在做什么的更数学概念化介绍。齐次方程的求解包括了3种:齐次方程组通解、特解、约束解;其实pretrain过程对应的就是齐次方程的通解、sft过程对应的就是齐次方程的特解、RLHF过程对应的就是齐次方程的约束解。
介绍完LLM的训练流程,又介绍了RAG,提出了RAG其实就是在对LLM可控性生成。介绍了RAG对可控性的几个影响点:
1.RAG检索回什么,是chunk、token、信息的二阶标签还是内容的语义表示;这个其实代表的定义域空间的约束
2.检索如何控制LLM生成,是作为上下文、还是作为控制权柄对生成信息做过滤、还是把检索回来信息作为控制参数嵌入LLM控制生成
3.检索的触发时间是什么时候,LLM每生成一个词就检索一次、还是生成一段话再检索约束一次、还是检索一次一直约束到生成结尾