一、Pandas概述
1、Pandas介绍
2008年WesMcKinney开发出的库,专门用于数据挖掘的开源python库
以Numpy为基础,借力Numpy模块在计算方面性能高的优势
基于matplotib,能够简便的画图
独特的数据结构
import pandas as pd
2、Pandas优势
- 便捷的数据处理能力
- 读取文件方便
- 封装了Matplotlib、Numpy的画图和计算
二、数据类型
1、DataFrame
1)结构
既有行索引、又有列索引的二维数组
- 行索引,表明不同行,横向索引,叫
index - 列索引,表明不同列,纵向索引,叫
columns
2)初识
import numpy as np
import pandas as pd
stock = np.random.normal(0, 1, (10,5))
hang = ["股票{}".format(i) for i in range(10)]
lie = pd.date_range(start="20180101", periods=5, freq="B")
df = pd.DataFrame(stock, index=hang, columns=lie)
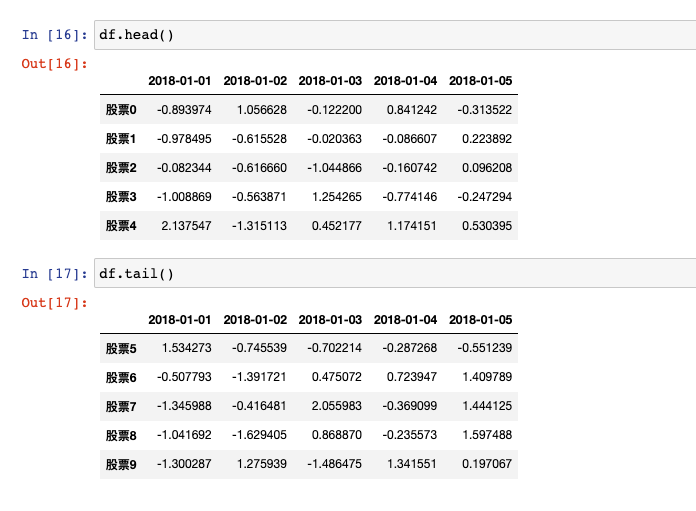
df.head()



3)属性
| 属性 | 属性名 |
|---|---|
| shape | 形状 |
| index | 行索引列表 |
| columns | 列索引列表 |
| values | 直接获取其中 array 的值 |
| T | 行列转置 |
4)方法
# 开头几行(默认5)
df.head(n)
# 最后几行
df.tail(n)
5)索引的设置
1. 修改行列索引值
不能单独修改索引
stock_ = ["股票_{}".format(i) for i in range(10)]
data.index = stock_

2. 重设索引
把原始索引删除(True)或当成普通列(False),重设索引
data.reset_index()
data.reset_index(drop=True) # drop=True把之前的索引删除

3. 设置新索引
df1 = pd.DataFrame({'month': [1, 4, 7, 10],
'year': [2012, 2014, 2013, 2014],
'sale':[55, 40, 84, 31]})
# 以月份设置新的索引
df1.set_index("month", drop=True)
# 设置多个索引,以年和月份
df1.set_index(["year", "month"])

2、MultiIndex
多级或分层索引对象
- names:levels 的名称
- levels:每个 level 的元组值
df2.index
df2.index.names
df2.index.levels

3、Panel
存储三维数组的容器
Panel 是 DataFrame 的容器 => 每个维度都是一个DataFrame
注:Pandas 从版本 0.20.0 开始弃用,推荐的用于表示 3D 数据的方法是 DataFrame 上的 MultiIndex 方法
4、Series
带索引的一维数组
DataFrame 是 Series 的容器
sr = data.iloc[1, :]
# 索引
sr.index
# 值
sr.values

三、数据操作
1、索引操作
# 直接索引 必须先列后行
data["open"]["2018-02-26"]
# 按名字索引
data.loc["2018-02-26"]["open"]
data.loc["2018-02-26", "open"]
# 数字索引
data.iloc[1, 0]
# 组合索引
data.loc[data.index[0:4], ['open', 'close', 'high', 'low']]

2、赋值操作
data.open = 100
data.iloc[1, 0] = 120

3、排序操作
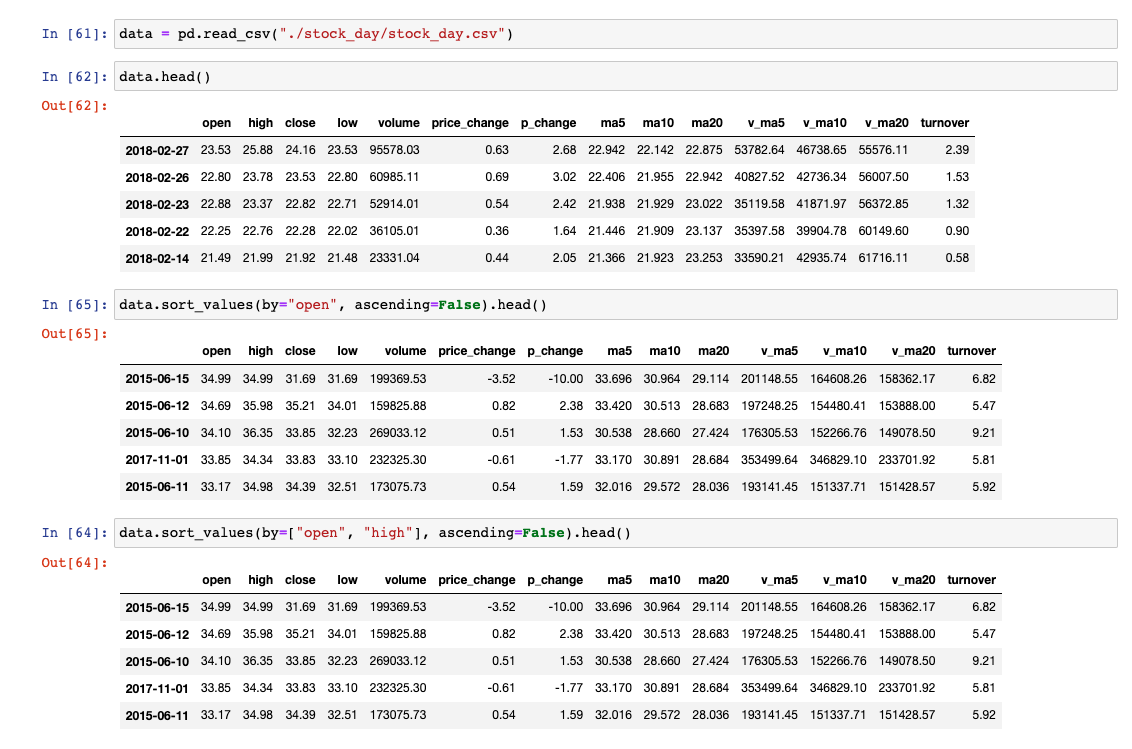
1)内容排序
# 单列内容排序
# ascending=False:降序、True:升序
data.sort_values(by="open", ascending=False)
# 多个列内容排序
data.sort_values(by=["open", "high"], ascending=False).head()
2)索引排序
data.sort_index()

四、DataFrame运算
1、算术运算
data["open"] + 3
data["open"].add(3)
data.sub(100)
data - 100
data["close"] - data["open"]
data["close"].sub(data["open"])
2、逻辑运算
data[data["p_change"] > 2]
data[(data["p_change"] > 2) & (data["low"] > 15)]
# query(expr) expr:查询字符串
data.query("p_change > 2 & low > 15")
# isin(values) 判断是否为 values
data[data["turnover"].isin([4.19, 2.39])]
3、统计运算
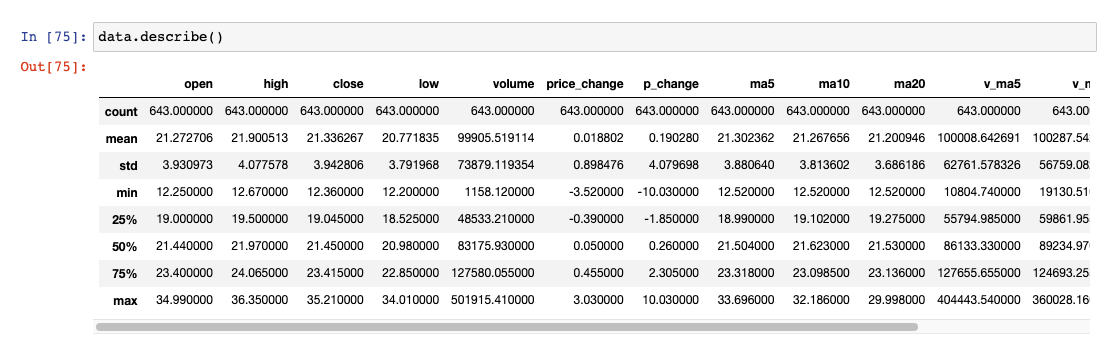
describe()综合分析:能够直接得出很多统计结果,count,mean,std,min,max 等
data.describe() # 综合分析
data.max() # 最大值
data.idxmax() # 最大值位置
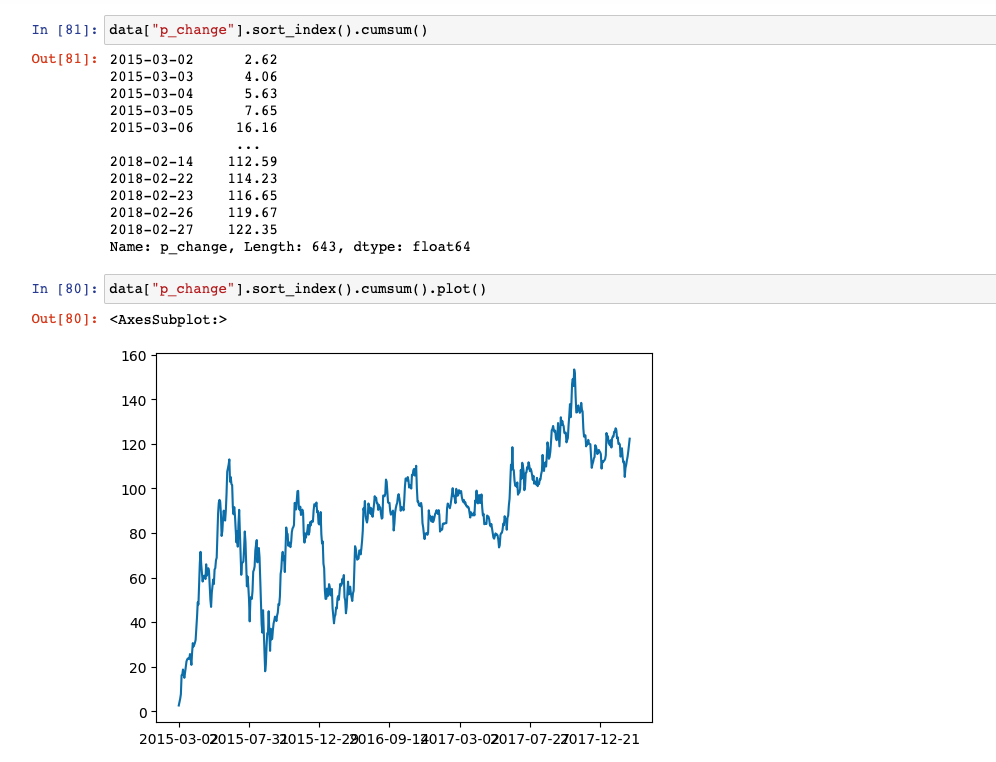
4、累计统计函数
cumsum计算前 1/2/3/…/n 个数的和cummax计算前 1/2/3/…/n 个数的最大值cummin计算前 1/2/3/…/n 个数的最小值cumprod计算前 1/2/3/…/n 个数的积
data["p_change"].sort_index().cumsum()
data["p_change"].sort_index().cumsum().plot()
5、自定义运算
apply(func, axis=0)
func:自定义函数axis=0:默认按列运算,axis=1:按行运算
data.apply(lambda x: x.max() - x.min())

五、Pandas画图
1、DataFrame
DataFrame.plot(x=None, y=None, kind='line')
- x: 标签或位置,默认为“无”
- y: 标签、位置或标签列表、位置。默认无标签
- 允许打印一列与另一列
- kind: str
- ‘line’: 折线图(default)
- ''bar": 条形图
- “barh”: 水平条形图
- “hist”: 直方图
- “pie”: 饼图
- “scatter”: 散点图
data.plot(x="volume", y="turnover", kind="scatter")

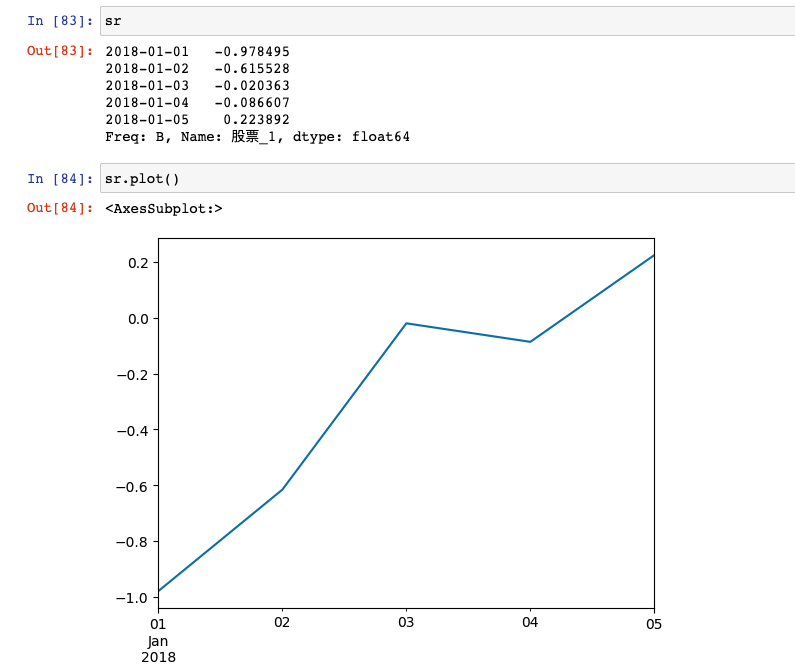
2、Series
sr.plot()
六、文件读取与存储
1、读取CSV
# 读取数据表,并指定读哪些列
data = pd.read_csv("./stock_day/stock_day.csv", usecols=["high", "low", "open", "close"])
# 如果数据表的列没有列名,用names传入列名
data = pd.read_csv("stock_day2.csv", names=["open", "high", "close"])
2、保存CSV
# 保存open列的数据
data[:10].to_csv("test.csv", columns=["open"])
# index=False不要行索引
# header=False不要列索引
# mode="a"追加模式|mode="w"重写
data[:10].to_csv("test.csv", columns=["open"], index=False, mode="a", header=False)