Quartz-CSDN博客
上面是Quartz的一些基本知识,如果对quartz的基本API不是很了解的话,建议先看下上面的
和Linux Crontab对比
1.执行粒度:
Linux Crontab是进程级
quart是线程级
2.跨平台性:
Crontab只能在Linxu运行
quart是java实现,可以跨平台
3.调度集上
Crontab的最小执行单位是分钟
quartz毫秒级
4.任务监控
Crontab不能实现任务监控
quartz支持任务监控
5.高可用
Crontab是单机,单任务,任务挂了就挂了
quartz支持高可用
新建一个Maven工程,演示quartz,导入依赖
<dependencies>
<dependency>
<groupId>org.quartz-scheduler</groupId>
<artifactId>quartz</artifactId>
<version>2.2.1</version>
</dependency>
</dependencies>


执行

关于日志报错
引入依赖
<!--log4j-->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.12</version>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
在resource下 log4j.properties
# 设置日志级别为INFO
log4j.rootCategory=INFO, stdout
# 输出到控制台的appender配置
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss} %-5p %c{1}:%L - %m%n
# 输出到文件的appender配置
log4j.appender.file=org.apache.log4j.RollingFileAppender
#log4j.appender.file.File=/path/to/quartz.log
log4j.appender.file.File=F:/quartz.log
log4j.appender.file.MaxFileSize=10MB
log4j.appender.file.MaxBackupIndex=5
log4j.appender.file.layout=org.apache.log4j.PatternLayout
log4j.appender.file.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss} %-5p %c{1}:%L - %m%n
# 配置quartz的日志级别为INFO,并将日志输出到控制台和文件
log4j.logger.org.quartz=INFO, stdout, file
再次运行就好了
Quartz 框架中的 Trigger(触发器)有多种类型,用于在特定的时间条件下触发 Quartz 中定义的 Job(任务)。其中一些常见的 Trigger 类型包括:
SimpleTrigger(简单触发器):简单触发器可配置为在特定时间点执行一次任务,或者在指定时间间隔内重复执行任务。它允许指定开始执行时间、重复次数、间隔等属性。
CronTrigger(Cron 触发器):Cron 触发器基于 Cron 表达式来定义调度时间。Cron 表达式允许更复杂的时间表达式,例如每天的特定时间执行任务,或者每周、每月的特定日期等。
CalendarIntervalTrigger(日历间隔触发器):这个触发器基于日历间隔来定义执行时间。它允许指定日历间隔的时间段,比如每隔几天、几小时、几分钟执行一次任务。
DailyTimeIntervalTrigger(每日时间间隔触发器):允许定义每日执行的时间间隔,可以配置每天的特定时间段来执行任务。
这些 Trigger 类型允许开发者根据具体需求定义任务的触发时间和频率。不同的 Trigger 类型适用于不同的调度需求和时间规则。
下面演示上面这4个触发器 SimpleTrigger其实上面的例子就是
需求 15秒后执行 时间间隔5秒钟 执行500次

演示
DailyTimeIntervalTrigger(每日时间间隔触发器):允许定义每日执行的时间间隔,可以配置每天的特定时间段来执行任务。
需求,每天9点执行, 下午5点结束 每隔1小时执行一次 周一到周五执行

演示
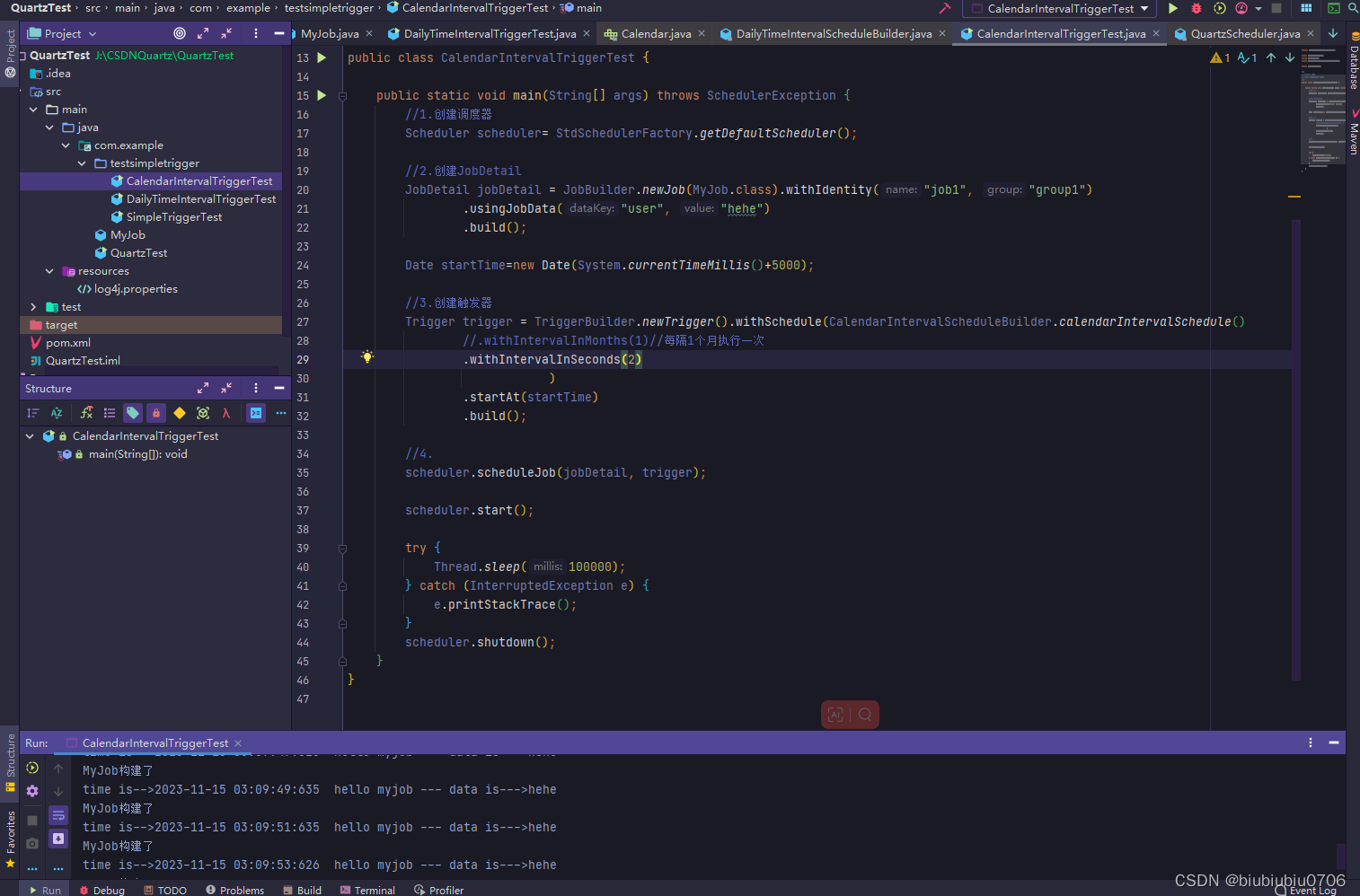
CalendarIntervalTrigger(日历间隔触发器):这个触发器基于日历间隔来定义执行时间。它允许指定日历间隔的时间段,比如每隔几天、几小时、几分钟执行一次任务。
需求 每月执行一次
CronTrigger(Cron 触发器):Cron 触发器基于 Cron 表达式来定义调度时间。Cron 表达式允许更复杂的时间表达式,例如每天的特定时间执行任务,或者每周、每月的特定日期等。

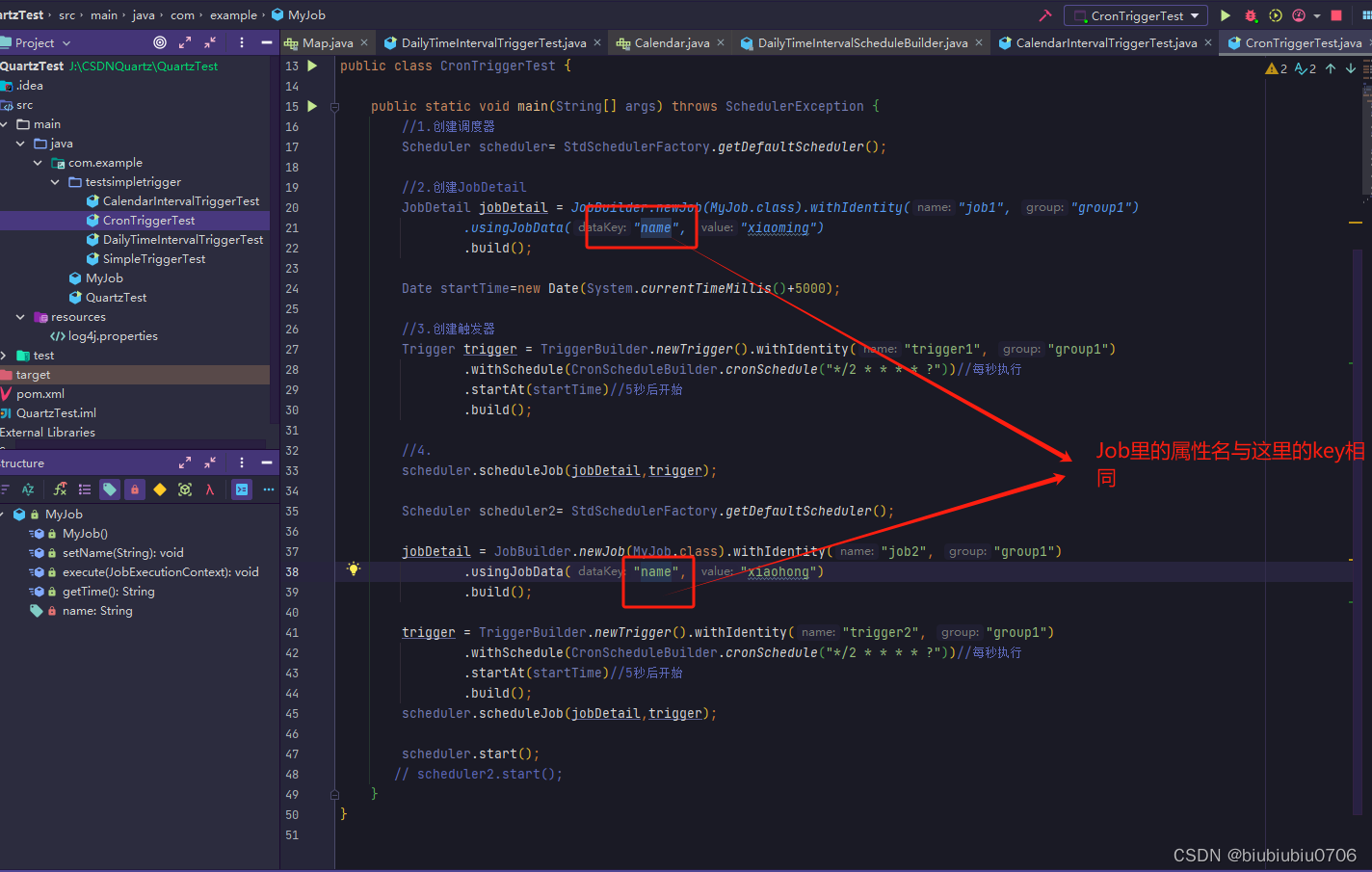
下面有个需求,我希望定时根据用户名字给对应的人发邮件
job1
job2

将Job改造一下

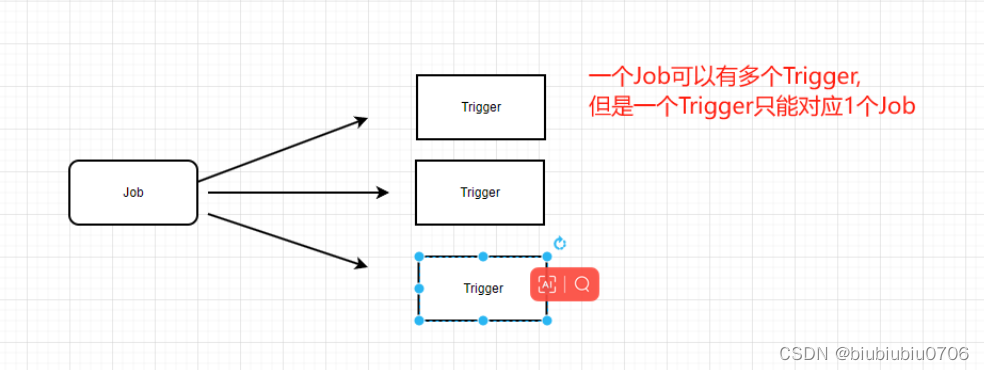
Job而言,一个Job可以对应多个Trigger,但是对于Trigger而言,一个Trigger智能对应一个Job,所以一个Trigger只能被指派给一个Job
执行结果

通过usingJobData之后 还可以在Job实现类中添加setter方法对应JobDataMap的键值,Quartz框架默认的JobFactory实现类在初始化Job实例对象时会自动调用这些setter方法
示例


那用对象行不行?


也可以 注意这里只是演示注入,没有考虑其他,代码往下执行会报错,因为get("user")是null.equals会报空指针

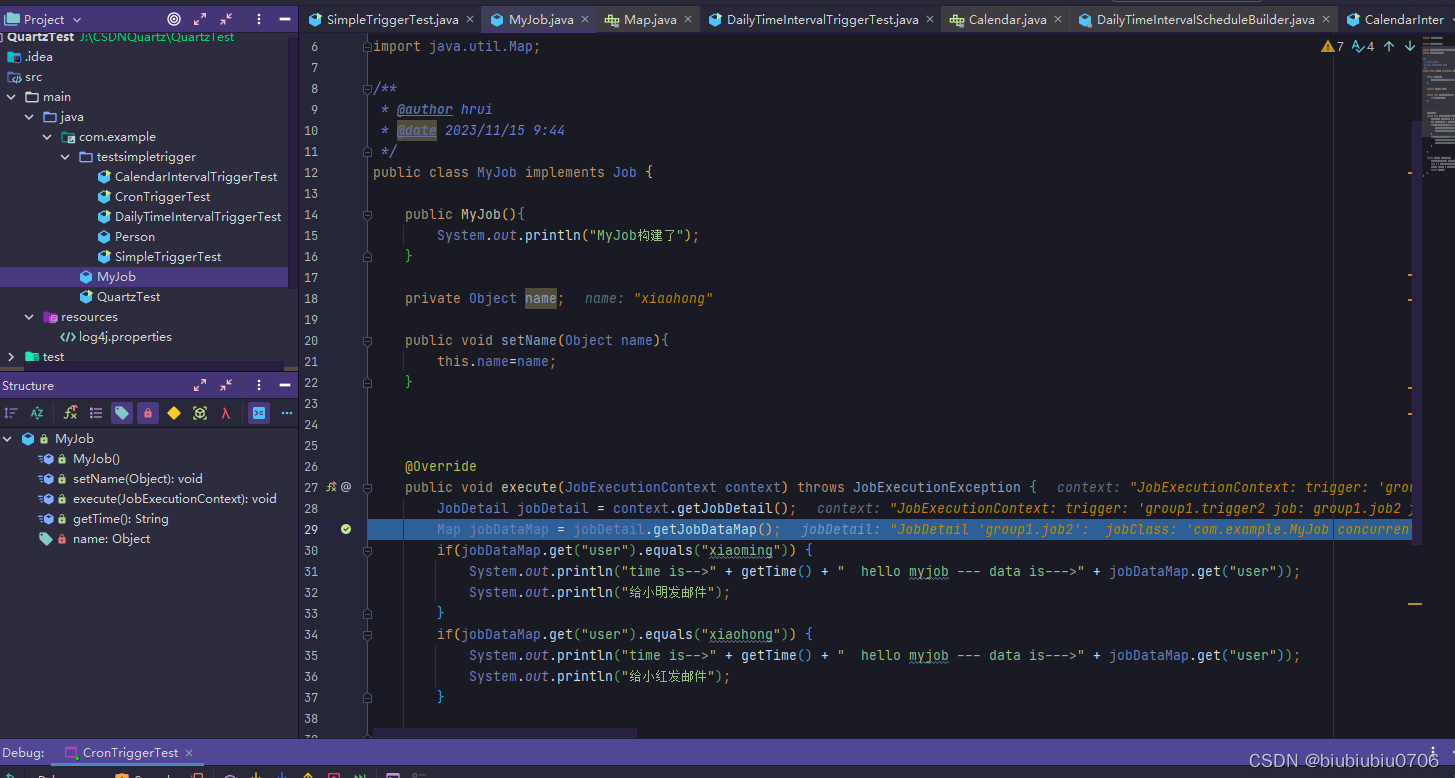
这里注意,如果遇到同名key(JobDataMap中有同名Key),Trigger中的usingJobData会覆盖JobDetail中的usingJobData
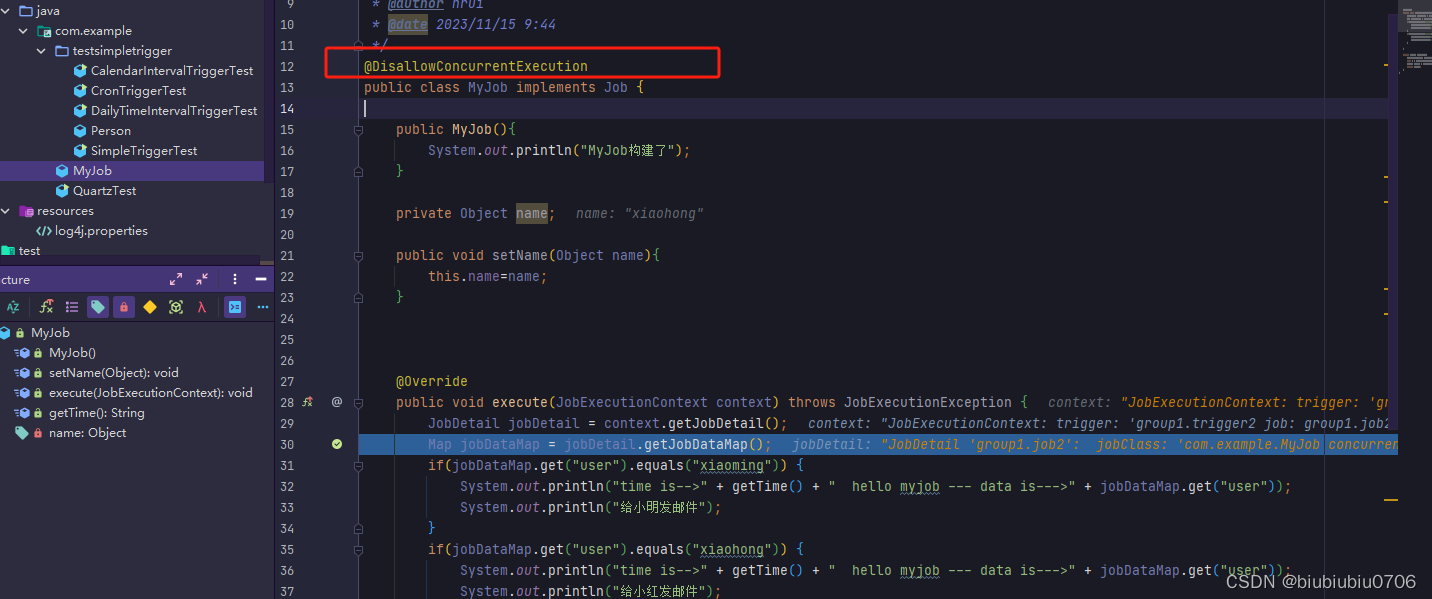
@DisallowConcurrentExecution 是 Quartz 调度框架中的一个注解,它用于确保同一个 JobDetail 不会并发执行。在一个 Quartz Scheduler 中,可能存在多个 Trigger 触发同一个 JobDetail,而且这些 Trigger 可能在同一时间点触发。
默认情况下,Quartz 允许同一个 JobDetail 被并发执行。这就意味着,如果一个 Job 正在执行,而此时又有一个 Trigger 触发了同一个 Job,那么新的 Job 实例会启动,可能会导致并发执行两个相同的 Job。
原因在于
@DisallowConcurrentExecution 主要是在一个 JobDetail 被多个 Trigger 触发时才会生效,防止同一个 Job形成抢的概念 实例并发执行
关于Scheduler
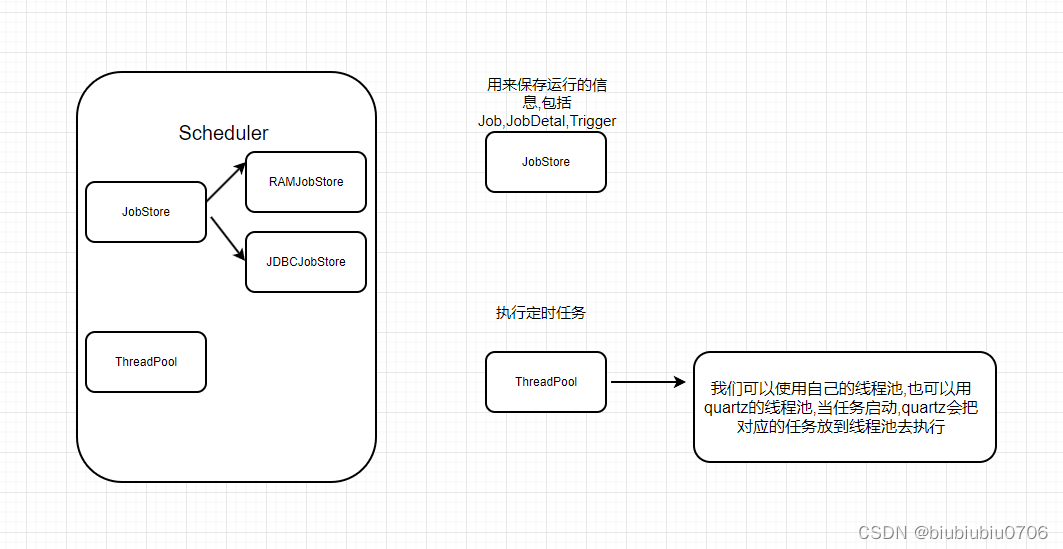
在Quartz调度框架中,JobStore 是一个用于存储和检索 JobDetail和 Trigger 数据的组件。JobStore 负责将这些信息持久化并管理调度器中的作业和触发器的状态。
Quartz支持不同类型的 JobStore,其中两个主要的实现是:
-
RAMJobStore: 这是 Quartz 的默认 JobStore 实现,它将调度器的状态存储在内存中。当应用程序关闭时,RAMJobStore 中的数据将丢失,不会被持久化。
-
JDBCJobStore: 这是一个基于数据库的 JobStore 实现,可以将调度器的状态存储在关系型数据库中。这样可以在应用程序关闭后保持数据,并且可以在多个应用程序实例之间共享数据。
选择使用哪个 JobStore 取决于你的应用程序的需求。如果你对数据的持久性没有严格的要求,而且你不需要在应用程序关闭后恢复之前的调度状态,那么使用默认的 RAMJobStore 就足够了。如果你需要数据持久性和可恢复性,或者要在多个应用程序实例之间共享调度状态,那么可以考虑使用 JDBCJobStore。
在 Quartz 的配置文件中,你可以通过配置属性来指定使用哪个 JobStore。例如,如果你使用 RAMJobStore,配置文件中可能包含以下配置:
org.quartz.jobStore.class = org.quartz.simpl.RAMJobStore
如果你使用 JDBCJobStore,你需要提供数据库相关的配置,例如:
org.quartz.jobStore.class = org.quartz.impl.jdbcjobstore.JobStoreTX org.quartz.jobStore.driverDelegateClass = org.quartz.impl.jdbcjobstore.StdJDBCDelegate org.quartz.jobStore.dataSource = yourDataSource org.quartz.jobStore.tablePrefix = QRTZ_
在 JDBCJobStore 的配置中,yourDataSource 是你事先配置好的数据源,QRTZ_ 是数据库表名的前缀。
JobStore的一些实现
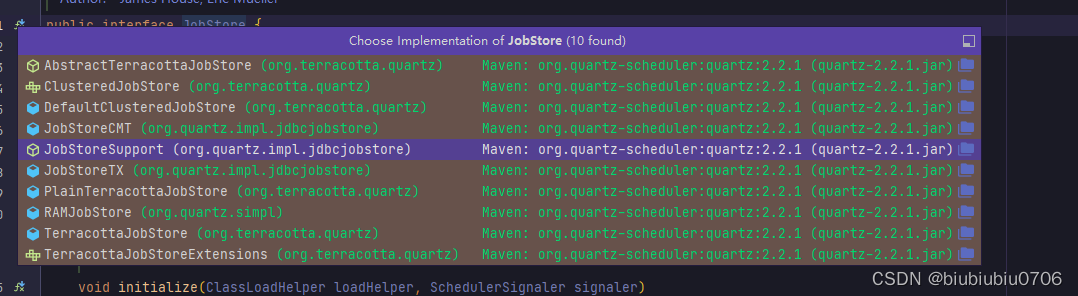
关于创建Scheduler SchdulerFactory有两个实例

前面示例中
还有一个是DirectSchedulerFactory
一般情况下,使用 StdSchedulerFactory 是更常见的方式,它提供了更灵活的配置选项,并且可以通过编程方式动态配置调度器。StdSchedulerFactory 会根据配置文件或配置属性创建 Scheduler 实例。
关于Job状态
有状态的Job和无状态的Job
有状态的Job可以理解为多次Job调用期间可以持有一些状态信息,这些状态信息存储在JobDataMap中,而默认的无状态Job每次调用时都会创建一个新的JobDataMap
默认都是无状态的
示例


执行结果

我在Job上加个@PersistJobDataAfterExecuption

下面做Spring与Quartz的整合
创建个Maven项目
引入依赖
<dependencies>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-core</artifactId>
<version>4.2.6.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context</artifactId>
<version>4.2.6.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-aop</artifactId>
<version>4.2.6.RELEASE</version>
</dependency>
<dependency>
<groupId>org.quartz-scheduler</groupId>
<artifactId>quartz</artifactId>
<version>2.2.1</version>
</dependency>
<dependency>
<groupId>org.quartz-scheduler</groupId>
<artifactId>quartz-jobs</artifactId>
<version>2.2.1</version>
</dependency>
<dependency>
<groupId>commons-logging</groupId>
<artifactId>commons-logging</artifactId>
<version>1.2</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-web</artifactId>
<version>4.2.6.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context-support</artifactId>
<version>4.2.6.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-tx</artifactId>
<version>4.2.6.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-jdbc</artifactId>
<version>4.2.6.RELEASE</version>
</dependency>
<dependency>
<groupId>javax.servlet</groupId>
<artifactId>servlet-api</artifactId>
<version>LATEST</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.33</version>
</dependency>
<dependency>
<groupId>commons-dbcp</groupId>
<artifactId>commons-dbcp</artifactId>
<version>1.4</version>
</dependency>
</dependencies>
在resource下新建 quartz.properties文件
#============================================================================ # Configure JobStore # Using Spring datasource in quartzJobsConfig.xml # Spring uses LocalDataSourceJobStore extension of JobStoreCMT #============================================================================ #表示 JobStore 的配置是否在配置文件中使用键值对的方式指定 org.quartz.jobStore.useProperties=true #设置数据库表名的前缀,所有的表将以 QRTZ_ 开头。 org.quartz.jobStore.tablePrefix = QRTZ_ #指示Quartz实例是否在集群模式下运行。设置为 true 表示Quartz将在集群环境中使用。 org.quartz.jobStore.isClustered = true #设置集群中节点相互检查的时间间隔(毫秒)。 org.quartz.jobStore.clusterCheckinInterval = 5000 # 设置作业(Job)的失火(misfire)阈值,即允许的最大延迟时间。 org.quartz.jobStore.misfireThreshold = 60000 #设置 JobStore 的事务隔离级别为 READ_COMMITTED。 org.quartz.jobStore.txIsolationLevelReadCommitted = true # Change this to match your DB vendor #指定 JobStore 的实现类为 JobStoreTX,这是一个适用于数据库的事务性 JobStore。 org.quartz.jobStore.class = org.quartz.impl.jdbcjobstore.JobStoreTX #指定用于委托JDBC调用的类。这里使用 StdJDBCDelegate,适用于标准的JDBC数据库。 org.quartz.jobStore.driverDelegateClass = org.quartz.impl.jdbcjobstore.StdJDBCDelegate #============================================================================ # Configure Main Scheduler Properties # Needed to manage cluster instances #============================================================================ #设置Quartz调度器的实例ID。设置为 "AUTO" 表示Quartz将自动生成唯一标识符。 org.quartz.scheduler.instanceId=AUTO #设置Quartz调度器实例的名称,在集群环境中用于标识不同的调度器实例。 org.quartz.scheduler.instanceName=MY_CLUSTERED_JOB_SCHEDULER #表示Quartz调度器是否应导出为远程方法调用(RMI)。这里设置为 false,表示禁用RMI导出。 org.quartz.scheduler.rmi.export = false #指定Quartz是否应使用RMI代理。设置为 false,表示不使用RMI代理。 org.quartz.scheduler.rmi.proxy = false #============================================================================ # Configure ThreadPool #============================================================================ #指定Quartz线程池的实现类为 SimpleThreadPool。 org.quartz.threadPool.class = org.quartz.simpl.SimpleThreadPool #设置Quartz线程池中的线程数为10。 org.quartz.threadPool.threadCount = 10 #设置Quartz线程池中线程的优先级为5。 org.quartz.threadPool.threadPriority = 5 #定线程池创建的线程是否应该继承初始化线程的上下文类加载器。 org.quartz.threadPool.threadsInheritContextClassLoaderOfInitializingThread = true
创建Spring.xml文件
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-4.0.xsd http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd">
<!--包扫描-->
<context:component-scan base-package="com.example.job"/>
<bean id="dataSource" class="org.apache.commons.dbcp.BasicDataSource">
<property name="driverClassName" value="com.mysql.cj.jdbc.Driver"></property>
<property name="url" value="jdbc:mysql://xxx/job"></property>
<property name="username" value="root"></property>
<property name="password" value="xxxx"></property>
</bean>
<!-- 分布式事务配置 start -->
<!-- 开启注解驱动的事务管理 -->
<!-- 配置线程池-->
<bean name="executor" class="org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor">
<property name="corePoolSize" value="15"/>
<property name="maxPoolSize" value="25"/>
<property name="queueCapacity" value="100"/>
</bean>
<bean name="transactionManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager">
<property name="dataSource" ref="dataSource"/>
</bean>
<!-- 配置调度任务-->
<bean name="quartzScheduler" class="org.springframework.scheduling.quartz.SchedulerFactoryBean">
<property name="configLocation" value="classpath:quartz.properties"/>
<property name="dataSource" ref="dataSource"/>
<property name="transactionManager" ref="transactionManager"/>
<!-- 任务唯一的名称,将会持久化到数据库-->
<property name="schedulerName" value="baseScheduler"/>
<!-- 每台集群机器部署应用的时候会更新触发器-->
<property name="overwriteExistingJobs" value="true"/>
<property name="applicationContextSchedulerContextKey" value="appli22"/>
<property name="jobFactory">
<bean class="com.example.config.AutowiringSpringBeanJobFactory"/>
</property>
<property name="triggers">
<list>
<ref bean="printCurrentTimeScheduler"/>
</list>
</property>
<property name="jobDetails">
<list>
<ref bean="printCurrentTimeJobs"/>
</list>
</property>
<property name="taskExecutor" ref="executor"/>
</bean>
<!-- 配置Job详情 -->
<bean name="printCurrentTimeJobs" class="org.springframework.scheduling.quartz.JobDetailFactoryBean">
<property name="jobClass" value="com.example.job.PrintCurrentTimeJobs"/>
<!--<property name="jobDataAsMap">
<map>
<entry key="clusterQuartz" value="com.aaron.framework.clusterquartz.job.PrintCurrentTimeJobs"/>
</map>
</property>-->
<property name="durability" value="true"/>
<property name="requestsRecovery" value="false"/>
</bean>
<!-- 配置触发时间 -->
<bean name="printCurrentTimeScheduler" class="org.springframework.scheduling.quartz.CronTriggerFactoryBean">
<property name="jobDetail" ref="printCurrentTimeJobs"/>
<property name="cronExpression">
<value>0/10 * * * * ?</value>
</property>
<property name="timeZone">
<value>GMT+8:00</value>
</property>
</bean>
<!-- 分布式事务配置 end -->
</beans>
出现这个



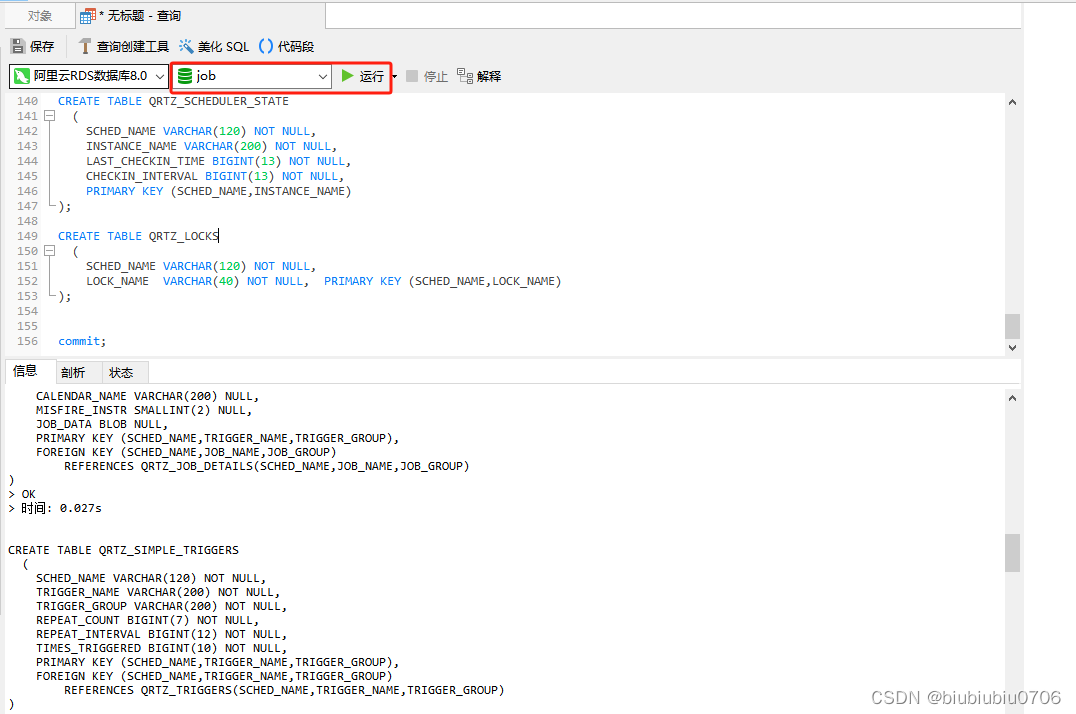
新建数据库

建表语句
#DROP TABLE IF EXISTS QRTZ_FIRED_TRIGGERS;
#DROP TABLE IF EXISTS QRTZ_PAUSED_TRIGGER_GRPS;
#DROP TABLE IF EXISTS QRTZ_SCHEDULER_STATE;
#DROP TABLE IF EXISTS QRTZ_LOCKS;
#DROP TABLE IF EXISTS QRTZ_SIMPLE_TRIGGERS;
#DROP TABLE IF EXISTS QRTZ_SIMPROP_TRIGGERS;
#DROP TABLE IF EXISTS QRTZ_CRON_TRIGGERS;
#DROP TABLE IF EXISTS QRTZ_BLOB_TRIGGERS;
#DROP TABLE IF EXISTS QRTZ_TRIGGERS;
#DROP TABLE IF EXISTS QRTZ_JOB_DETAILS;
#DROP TABLE IF EXISTS QRTZ_CALENDARS;
CREATE TABLE QRTZ_JOB_DETAILS
(
SCHED_NAME VARCHAR(120) NOT NULL,
JOB_NAME VARCHAR(200) NOT NULL,
JOB_GROUP VARCHAR(200) NOT NULL,
DESCRIPTION VARCHAR(250) NULL,
JOB_CLASS_NAME VARCHAR(250) NOT NULL,
IS_DURABLE VARCHAR(1) NOT NULL,
IS_NONCONCURRENT VARCHAR(1) NOT NULL,
IS_UPDATE_DATA VARCHAR(1) NOT NULL,
REQUESTS_RECOVERY VARCHAR(1) NOT NULL,
JOB_DATA BLOB NULL,
PRIMARY KEY (SCHED_NAME,JOB_NAME,JOB_GROUP)
);CREATE TABLE QRTZ_TRIGGERS
(
SCHED_NAME VARCHAR(120) NOT NULL,
TRIGGER_NAME VARCHAR(200) NOT NULL,
TRIGGER_GROUP VARCHAR(200) NOT NULL,
JOB_NAME VARCHAR(200) NOT NULL,
JOB_GROUP VARCHAR(200) NOT NULL,
DESCRIPTION VARCHAR(250) NULL,
NEXT_FIRE_TIME BIGINT(13) NULL,
PREV_FIRE_TIME BIGINT(13) NULL,
PRIORITY INTEGER NULL,
TRIGGER_STATE VARCHAR(16) NOT NULL,
TRIGGER_TYPE VARCHAR(8) NOT NULL,
START_TIME BIGINT(13) NOT NULL,
END_TIME BIGINT(13) NULL,
CALENDAR_NAME VARCHAR(200) NULL,
MISFIRE_INSTR SMALLINT(2) NULL,
JOB_DATA BLOB NULL,
PRIMARY KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP),
FOREIGN KEY (SCHED_NAME,JOB_NAME,JOB_GROUP)
REFERENCES QRTZ_JOB_DETAILS(SCHED_NAME,JOB_NAME,JOB_GROUP)
);CREATE TABLE QRTZ_SIMPLE_TRIGGERS
(
SCHED_NAME VARCHAR(120) NOT NULL,
TRIGGER_NAME VARCHAR(200) NOT NULL,
TRIGGER_GROUP VARCHAR(200) NOT NULL,
REPEAT_COUNT BIGINT(7) NOT NULL,
REPEAT_INTERVAL BIGINT(12) NOT NULL,
TIMES_TRIGGERED BIGINT(10) NOT NULL,
PRIMARY KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP),
FOREIGN KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP)
REFERENCES QRTZ_TRIGGERS(SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP)
);CREATE TABLE QRTZ_CRON_TRIGGERS
(SCHED_NAME VARCHAR(120) NOT NULL,
TRIGGER_NAME VARCHAR(200) NOT NULL,
TRIGGER_GROUP VARCHAR(200) NOT NULL,
CRON_EXPRESSION VARCHAR(200) NOT NULL,
TIME_ZONE_ID VARCHAR(80),
PRIMARY KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP),
FOREIGN KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP)
REFERENCES QRTZ_TRIGGERS(SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP)
);CREATE TABLE QRTZ_SIMPROP_TRIGGERS
(
SCHED_NAME VARCHAR(120) NOT NULL,
TRIGGER_NAME VARCHAR(200) NOT NULL,
TRIGGER_GROUP VARCHAR(200) NOT NULL,
STR_PROP_1 VARCHAR(512) NULL,
STR_PROP_2 VARCHAR(512) NULL,
STR_PROP_3 VARCHAR(512) NULL,
INT_PROP_1 INT NULL,
INT_PROP_2 INT NULL,
LONG_PROP_1 BIGINT NULL,
LONG_PROP_2 BIGINT NULL,
DEC_PROP_1 NUMERIC(13,4) NULL,
DEC_PROP_2 NUMERIC(13,4) NULL,
BOOL_PROP_1 VARCHAR(1) NULL,
BOOL_PROP_2 VARCHAR(1) NULL,
PRIMARY KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP),
FOREIGN KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP)
REFERENCES QRTZ_TRIGGERS(SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP)
);CREATE TABLE QRTZ_BLOB_TRIGGERS
(
SCHED_NAME VARCHAR(120) NOT NULL,
TRIGGER_NAME VARCHAR(200) NOT NULL,
TRIGGER_GROUP VARCHAR(200) NOT NULL,
BLOB_DATA BLOB NULL,
PRIMARY KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP),
FOREIGN KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP)
REFERENCES QRTZ_TRIGGERS(SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP)
);CREATE TABLE QRTZ_CALENDARS
(SCHED_NAME VARCHAR(120) NOT NULL,
CALENDAR_NAME VARCHAR(200) NOT NULL,
CALENDAR BLOB NOT NULL,
PRIMARY KEY (SCHED_NAME,CALENDAR_NAME)
);CREATE TABLE QRTZ_PAUSED_TRIGGER_GRPS
(
SCHED_NAME VARCHAR(120) NOT NULL,
TRIGGER_GROUP VARCHAR(200) NOT NULL,
PRIMARY KEY (SCHED_NAME,TRIGGER_GROUP)
);CREATE TABLE QRTZ_FIRED_TRIGGERS
(
SCHED_NAME VARCHAR(120) NOT NULL,
ENTRY_ID VARCHAR(95) NOT NULL,
TRIGGER_NAME VARCHAR(200) NOT NULL,
TRIGGER_GROUP VARCHAR(200) NOT NULL,
INSTANCE_NAME VARCHAR(200) NOT NULL,
FIRED_TIME BIGINT(13) NOT NULL,
SCHED_TIME BIGINT(13) NOT NULL,
PRIORITY INTEGER NOT NULL,
STATE VARCHAR(16) NOT NULL,
JOB_NAME VARCHAR(200) NULL,
JOB_GROUP VARCHAR(200) NULL,
IS_NONCONCURRENT VARCHAR(1) NULL,
REQUESTS_RECOVERY VARCHAR(1) NULL,
PRIMARY KEY (SCHED_NAME,ENTRY_ID)
);CREATE TABLE QRTZ_SCHEDULER_STATE
(
SCHED_NAME VARCHAR(120) NOT NULL,
INSTANCE_NAME VARCHAR(200) NOT NULL,
LAST_CHECKIN_TIME BIGINT(13) NOT NULL,
CHECKIN_INTERVAL BIGINT(13) NOT NULL,
PRIMARY KEY (SCHED_NAME,INSTANCE_NAME)
);CREATE TABLE QRTZ_LOCKS
(
SCHED_NAME VARCHAR(120) NOT NULL,
LOCK_NAME VARCHAR(40) NOT NULL, PRIMARY KEY (SCHED_NAME,LOCK_NAME)
);
commit;

包结构
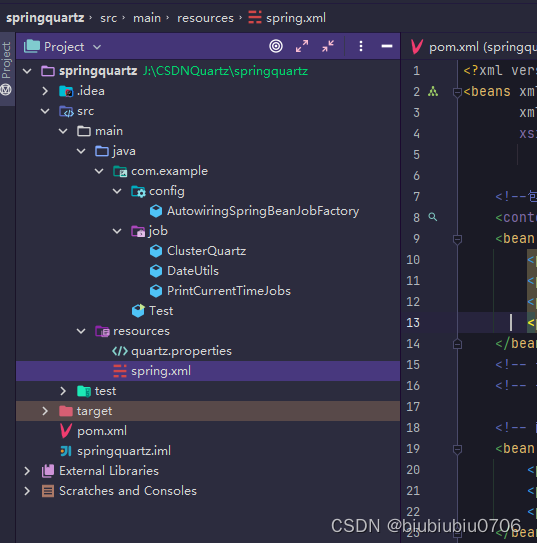
package com.example.config;
import org.quartz.spi.TriggerFiredBundle;
import org.springframework.beans.BeansException;
import org.springframework.beans.factory.config.AutowireCapableBeanFactory;
import org.springframework.context.ApplicationContext;
import org.springframework.context.ApplicationContextAware;
import org.springframework.scheduling.quartz.SpringBeanJobFactory;
/**
* 使job类支持spring的自动注入
* @author hrui
* @date 2023/11/16 12:55
*/
public class AutowiringSpringBeanJobFactory extends SpringBeanJobFactory implements ApplicationContextAware {
private transient AutowireCapableBeanFactory beanFactory;
public void setApplicationContext(ApplicationContext applicationContext) throws BeansException {
beanFactory = applicationContext.getAutowireCapableBeanFactory();
}
@Override
protected Object createJobInstance(TriggerFiredBundle bundle) throws Exception {
Object job = super.createJobInstance(bundle);
beanFactory.autowireBean(job);
return job;
}
}
package com.example.job;
import org.springframework.stereotype.Controller;
import java.util.Date;
@Controller
public class ClusterQuartz {
public void printUserInfo() {
System.out.println("*** start " + DateUtils.dateToString(new Date(), "yyyy-MM-dd HH:mm:ss:SSS") + " *************");
System.out.println("*");
System.out.println("* current username is " + System.getProperty("user.name"));
System.out.println("* current os name is " + System.getProperty("os.name"));
System.out.println("*");
System.out.println("*********current user information end******************");
}
}
package com.example.job;
import org.springframework.stereotype.Controller;
import java.util.Date;
@Controller
public class ClusterQuartz {
public void printUserInfo() {
System.out.println("*** start " + DateUtils.dateToString(new Date(), "yyyy-MM-dd HH:mm:ss:SSS") + " *************");
System.out.println("*");
System.out.println("* current username is " + System.getProperty("user.name"));
System.out.println("* current os name is " + System.getProperty("os.name"));
System.out.println("*");
System.out.println("*********current user information end******************");
}
}
package com.example.job;
import java.util.Date;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import org.quartz.JobExecutionContext;
import org.quartz.JobExecutionException;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.scheduling.quartz.QuartzJobBean;
public class PrintCurrentTimeJobs extends QuartzJobBean {
public PrintCurrentTimeJobs(){
System.out.println("job构建了");
}
private static final Log LOG_RECORD = LogFactory.getLog(PrintCurrentTimeJobs.class);
@Autowired
private ClusterQuartz clusterQuartz;
protected void executeInternal(JobExecutionContext jobExecutionContext) throws JobExecutionException {
LOG_RECORD.info("begin to execute task," + DateUtils.dateToString(new Date()));
clusterQuartz.printUserInfo();
LOG_RECORD.info("end to execute task," + DateUtils.dateToString(new Date()));
}
}