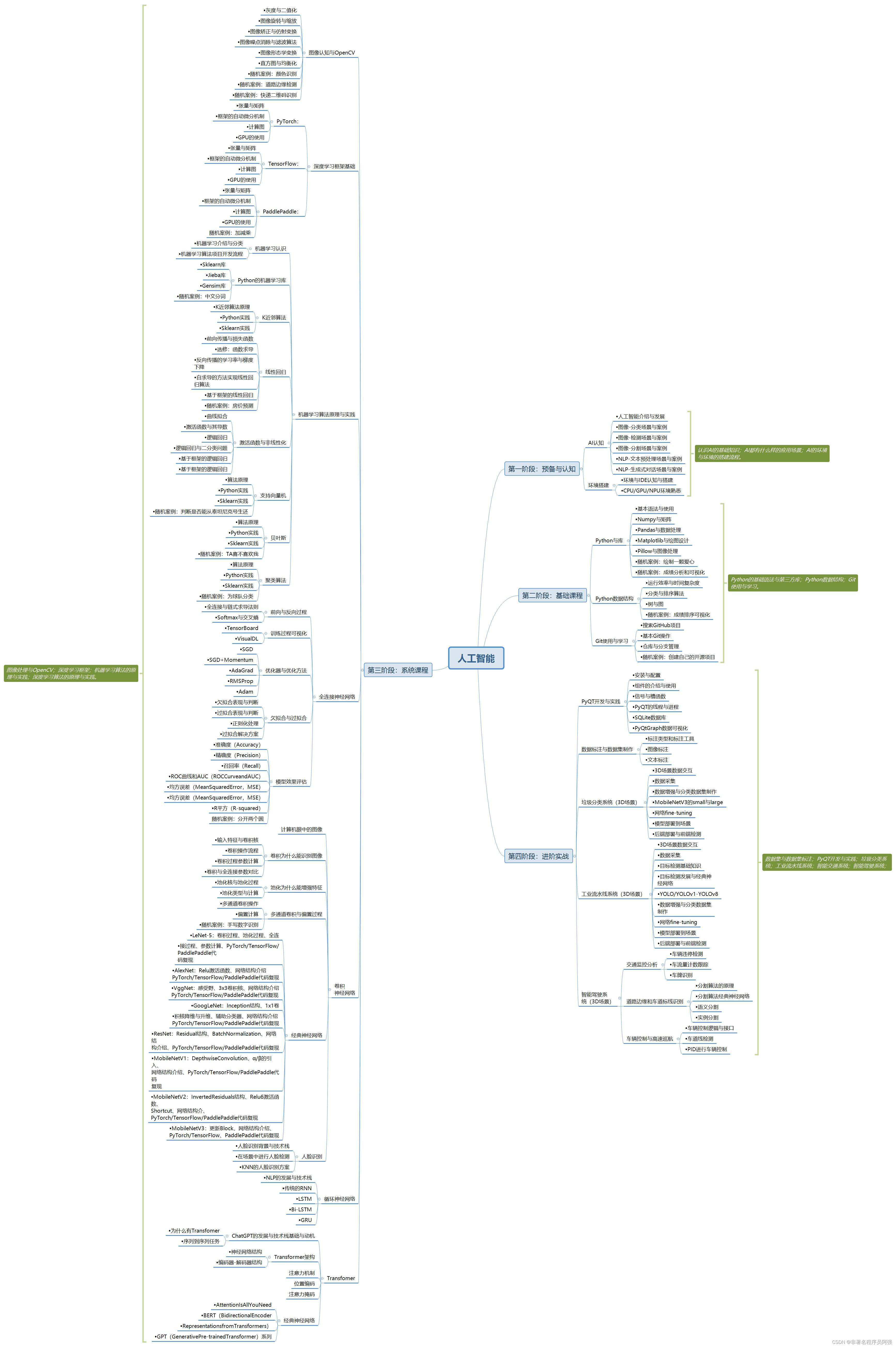
在深度学习领域,神经网络模型训练所需的计算量巨大,这就对计算资源提出了高要求。为了处理这一问题,图形处理器(GPU)被引入到深度学习中,其并行计算能力可以极大加速神经网络的训练过程。PyTorch作为一款出色的开源深度学习框架,为用户提供了简便灵活的GPU使用方式。本文将深入探讨PyTorch中GPU的使用,包括GPU加速的原理、GPU的配置和使用方法,以及GPU对深度学习的意义。
一、GPU加速的原理
传统的中央处理器(CPU)在深度学习任务中会面临计算能力的瓶颈,而GPU则具备大规模并行计算的能力,使得其在深度学习任务中能够发挥巨大的优势。GPU的加速原理在于其内部包含了大量的计算单元和高速内存,可以同时执行多个计算任务。
在深度学习框架中,如PyTorch,通过将计算任务并行分配到GPU上,可以同时处理更多的数据和计算,从而提高模型训练和推断的速度。PyTorch使用CUDA(计算统一设备架构)加速库实现与GPU的交互,使得用户可以方便地利用GPU进行深度学习任务的加速。

二、GPU的配置和使用
在使用PyTorch进行GPU加速前,首先需要确保正确配置GPU环境。用户需要安装正确版本的CUDA库和相应的GPU驱动程序,并且确保与PyTorch版本兼容。一旦GPU环境配置完成,用户可以通过简单的代码改动实现GPU的使用。
在PyTorch中,用户可以使用.to()方法将张量或模型迁移到指定的设备上,如GPU。例如,若要将一个张量迁移到GPU上,只需使用以下代码:
```
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
x = torch.tensor([1, 2, 3]).to(device)
```
通过这种方式,用户可以灵活地将需要加速的张量或模型迁移到GPU上进行计算。同时,PyTorch还提供了.cuda()方法用于将模型的所有参数迁移到GPU上,实现整体的加速。
另外,PyTorch还提供了一些与GPU相关的优化技术,如半精度浮点数计算(FP16),可以进一步提高GPU的计算效率。用户可以通过修改模型和优化器的设置,启用这些技术来加速模型的训练和推断过程。
三、GPU对深度学习的意义
GPU的加速对于深度学习的发展具有重要意义。首先,GPU的并行计算能力可以大幅缩短神经网络模型训练的时间,加快模型的迭代速度。这对于研究者和开发者来说是非常宝贵的,因为他们可以更快地验证和改进模型,提高算法的效果。
其次,GPU的使用使得深度学习技术更易于普及和应用。在过去,只有大规模的计算机集群或昂贵的专用硬件才能满足深度学习的需求。而GPU的加入极大降低了硬件的门槛,使得普通用户也能够享受到深度学习技术的便利。这在对于加速深度学习应用和普及AI技术来说都具有重要意义。
最后,GPU的加速对于实时应用和大规模计算任务非常关键。在实时应用中,GPU的加速使得深度学习模型可以在几乎实时的速度下处理输入数据,满足了许多需要低延迟计算的场景需求。在大规模计算任务中,GPU的大内存和高速计算能力使得处理海量数据和复杂模型变得可行,推动了科学研究和技术创新的发展。

四、结语
总的来说,GPU的加速对于深度学习具有重要的意义,而PyTorch作为一款优秀的深度学习框架,为用户提供了便利灵活的GPU使用方式。通过正确配置GPU环境并利用PyTorch的GPU加速功能,用户可以推动深度学习模型的训练、推断速度以及效果的提升。
人工智能的学习之路非常漫长,不少人因为学习路线不对或者学习内容不够专业而举步难行。不过别担心,我为大家整理了一份600多G的学习资源,基本上涵盖了人工智能学习的所有内容。点击下方链接,0元进群领取学习资源,让你的学习之路更加顺畅!记得点赞、关注、收藏、转发哦!扫码进群领资料