Flink 系列文章
1、Flink 部署、概念介绍、source、transformation、sink使用示例、四大基石介绍和示例等系列综合文章链接
13、Flink 的table api与sql的基本概念、通用api介绍及入门示例
14、Flink 的table api与sql之数据类型: 内置数据类型以及它们的属性
15、Flink 的table api与sql之流式概念-详解的介绍了动态表、时间属性配置(如何处理更新结果)、时态表、流上的join、流上的确定性以及查询配置
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及FileSystem示例(1)
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及Elasticsearch示例(2)
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及Apache Kafka示例(3)
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及JDBC示例(4)
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及Apache Hive示例(6)
17、Flink 之Table API: Table API 支持的操作(1)
17、Flink 之Table API: Table API 支持的操作(2)
18、Flink的SQL 支持的操作和语法
19、Flink 的Table API 和 SQL 中的内置函数及示例(1)
19、Flink 的Table API 和 SQL 中的自定义函数及示例(2)
19、Flink 的Table API 和 SQL 中的自定义函数及示例(3)
19、Flink 的Table API 和 SQL 中的自定义函数及示例(4)
20、Flink SQL之SQL Client: 不用编写代码就可以尝试 Flink SQL,可以直接提交 SQL 任务到集群上
21、Flink 的table API与DataStream API 集成(1)- 介绍及入门示例、集成说明
21、Flink 的table API与DataStream API 集成(2)- 批处理模式和inser-only流处理
21、Flink 的table API与DataStream API 集成(3)- changelog流处理、管道示例、类型转换和老版本转换示例
21、Flink 的table API与DataStream API 集成(完整版)
22、Flink 的table api与sql之创建表的DDL
24、Flink 的table api与sql之Catalogs(介绍、类型、java api和sql实现ddl、java api和sql操作catalog)-1
24、Flink 的table api与sql之Catalogs(java api操作数据库、表)-2
24、Flink 的table api与sql之Catalogs(java api操作视图)-3
24、Flink 的table api与sql之Catalogs(java api操作分区与函数)-4
25、Flink 的table api与sql之函数(自定义函数示例)
26、Flink 的SQL之概览与入门示例
27、Flink 的SQL之SELECT (select、where、distinct、order by、limit、集合操作和去重)介绍及详细示例(1)
27、Flink 的SQL之SELECT (SQL Hints 和 Joins)介绍及详细示例(2)
27、Flink 的SQL之SELECT (窗口函数)介绍及详细示例(3)
27、Flink 的SQL之SELECT (窗口聚合)介绍及详细示例(4)
27、Flink 的SQL之SELECT (Group Aggregation分组聚合、Over Aggregation Over聚合 和 Window Join 窗口关联)介绍及详细示例(5)
27、Flink 的SQL之SELECT (Top-N、Window Top-N 窗口 Top-N 和 Window Deduplication 窗口去重)介绍及详细示例(6)
27、Flink 的SQL之SELECT (Pattern Recognition 模式检测)介绍及详细示例(7)
28、Flink 的SQL之DROP 、ALTER 、INSERT 、ANALYZE 语句
29、Flink SQL之DESCRIBE、EXPLAIN、USE、SHOW、LOAD、UNLOAD、SET、RESET、JAR、JOB Statements、UPDATE、DELETE(1)
29、Flink SQL之DESCRIBE、EXPLAIN、USE、SHOW、LOAD、UNLOAD、SET、RESET、JAR、JOB Statements、UPDATE、DELETE(2)
30、Flink SQL之SQL 客户端(通过kafka和filesystem的例子介绍了配置文件使用-表、视图等)
32、Flink table api和SQL 之用户自定义 Sources & Sinks实现及详细示例
33、Flink 的Table API 和 SQL 中的时区
35、Flink 的 Formats 之CSV 和 JSON Format
41、Flink之Hive 方言介绍及详细示例
42、Flink 的table api与sql之Hive Catalog
43、Flink之Hive 读写及详细验证示例
44、Flink之module模块介绍及使用示例和Flink SQL使用hive内置函数及自定义函数详细示例–网上有些说法好像是错误的
文章目录
- Flink 系列文章
- 一、Flink 的 Formats
- 二、CSV Format
- 1、maven 依赖
- 2、Flink sql client 建表示例
- 3、table api建表示例
- 4、Format 参数
- 5、数据类型映射
- 三、JSON Format
- 1、maven 依赖
- 2、Flink sql client 建表示例
- 3、table api 建表示例
- 4、Format 参数
- 5、数据类型映射关系
本文介绍了Flink 支持的数据格式中的csv和json,并分别以sql和table api作为示例进行了说明。
本文依赖flink、kafka集群能正常使用。
本文分为3个部分,即概述、CSV和JSON Format。
本文的示例是在Flink 1.17版本(flink 集群和maven均是Flink 1.17)中运行。
一、Flink 的 Formats
Flink 提供了一套与表连接器(table connector)一起使用的表格式(table format)。表格式是一种存储格式,定义了如何把二进制数据映射到表的列上。
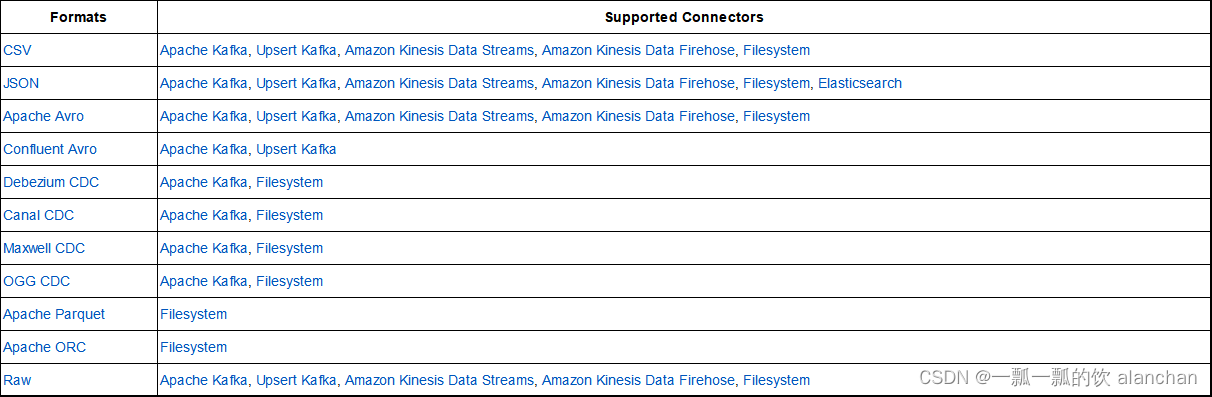
Flink 支持以下格式:
二、CSV Format
CSV Format 允许我们基于 CSV schema 进行解析和生成 CSV 数据。 目前 CSV schema 是基于 table schema 推断而来的。
1、maven 依赖
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-csv</artifactId>
<version>1.17.1</version>
</dependency>
2、Flink sql client 建表示例
以下是一个使用 Kafka 连接器和 CSV 格式创建表的示例。
CREATE TABLE Alan_KafkaTable (
`event_time` TIMESTAMP(3) METADATA FROM 'timestamp',
`partition` BIGINT METADATA VIRTUAL,
`offset` BIGINT METADATA VIRTUAL,
`user_id` BIGINT,
`item_id` BIGINT,
`behavior` STRING
) WITH (
'connector' = 'kafka',
'topic' = 'user_behavior',
'properties.bootstrap.servers' = '192.168.10.41:9092,192.168.10.42:9092,192.168.10.43:9092',
'properties.group.id' = 'testGroup',
'scan.startup.mode' = 'earliest-offset',
'format' = 'csv'
);
Flink SQL> CREATE TABLE Alan_KafkaTable (
> `event_time` TIMESTAMP(3) METADATA FROM 'timestamp',
> `partition` BIGINT METADATA VIRTUAL,
> `offset` BIGINT METADATA VIRTUAL,
> `user_id` BIGINT,
> `item_id` BIGINT,
> `behavior` STRING
> ) WITH (
> 'connector' = 'kafka',
> 'topic' = 'Alan_KafkaTable',
> 'properties.bootstrap.servers' = '192.168.10.41:9092,192.168.10.42:9092,192.168.10.43:9092',
> 'properties.group.id' = 'testGroup',
> 'scan.startup.mode' = 'earliest-offset',
> 'format' = 'csv'
> );
[INFO] Execute statement succeed.
# kafka客户端命令行输入数据
[alanchan@server1 bin]$ kafka-console-producer.sh --broker-list server1:9092 --topic Alan_KafkaTable
>1,1001,login
>1,2001,p_read
>
# flink sql client 查询数据即可
Flink SQL> select * from Alan_KafkaTable;
+----+-------------------------+----------------------+----------------------+----------------------+----------------------+--------------------------------+
| op | event_time | partition | offset | user_id | item_id | behavior |
+----+-------------------------+----------------------+----------------------+----------------------+----------------------+--------------------------------+
| +I | 2023-11-15 15:53:17.925 | 0 | 0 | 1 | 1001 | login |
| +I | 2023-11-15 15:53:45.839 | 0 | 1 | 1 | 2001 | p_read |
3、table api建表示例
通过table api建表,参考文章:
17、Flink 之Table API: Table API 支持的操作(1)
17、Flink 之Table API: Table API 支持的操作(2)
import static org.apache.flink.table.api.Expressions.$;
import static org.apache.flink.table.api.Expressions.and;
import static org.apache.flink.table.api.Expressions.lit;
import static org.apache.flink.table.expressions.ApiExpressionUtils.unresolvedCall;
import java.sql.Timestamp;
import java.time.Duration;
import java.util.Arrays;
import java.util.Collections;
import java.util.HashMap;
import java.util.List;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.typeinfo.TypeHint;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.table.KafkaConnectorOptions;
import org.apache.flink.table.api.DataTypes;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.Over;
import org.apache.flink.table.api.Schema;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.TableDescriptor;
import org.apache.flink.table.api.TableEnvironment;
import org.apache.flink.table.api.Tumble;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.table.catalog.CatalogDatabaseImpl;
import org.apache.flink.table.catalog.CatalogView;
import org.apache.flink.table.catalog.Column;
import org.apache.flink.table.catalog.ObjectPath;
import org.apache.flink.table.catalog.ResolvedCatalogView;
import org.apache.flink.table.catalog.ResolvedSchema;
import org.apache.flink.table.catalog.hive.HiveCatalog;
import org.apache.flink.table.functions.BuiltInFunctionDefinitions;
import org.apache.flink.types.Row;
import com.google.common.collect.Lists;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
/**
* @author alanchan
*
*/
public class TestTableAPIDemo {
/**
* @param args
* @throws Exception
*/
public static void main(String[] args) throws Exception {
testCreateTableBySQLAndAPI();
}
static void testCreateTableBySQLAndAPI() throws Exception {
// EnvironmentSettings env = EnvironmentSettings.newInstance().inStreamingMode().build();
// TableEnvironment tenv = TableEnvironment.create(env);
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tenv = StreamTableEnvironment.create(env);
// SQL 创建输入表
// String sourceSql = "CREATE TABLE Alan_KafkaTable (\r\n" +
// " `event_time` TIMESTAMP(3) METADATA FROM 'timestamp',\r\n" +
// " `partition` BIGINT METADATA VIRTUAL,\r\n" +
// " `offset` BIGINT METADATA VIRTUAL,\r\n" +
// " `user_id` BIGINT,\r\n" +
// " `item_id` BIGINT,\r\n" +
// " `behavior` STRING\r\n" +
// ") WITH (\r\n" +
// " 'connector' = 'kafka',\r\n" +
// " 'topic' = 'user_behavior',\r\n" +
// " 'properties.bootstrap.servers' = '192.168.10.41:9092,192.168.10.42:9092,192.168.10.43:9092',\r\n" +
// " 'properties.group.id' = 'testGroup',\r\n" +
// " 'scan.startup.mode' = 'earliest-offset',\r\n" +
// " 'format' = 'csv'\r\n" +
// ");";
// tenv.executeSql(sourceSql);
//API创建表
Schema schema = Schema.newBuilder()
.columnByMetadata("event_time", DataTypes.TIME(3), "timestamp")
.columnByMetadata("partition", DataTypes.BIGINT(), true)
.columnByMetadata("offset", DataTypes.BIGINT(), true)
.column("user_id", DataTypes.BIGINT())
.column("item_id", DataTypes.BIGINT())
.column("behavior", DataTypes.STRING())
.build();
TableDescriptor kafkaDescriptor = TableDescriptor.forConnector("kafka")
.comment("kafka source table")
.schema(schema)
.option(KafkaConnectorOptions.TOPIC, Lists.newArrayList("user_behavior"))
.option(KafkaConnectorOptions.PROPS_BOOTSTRAP_SERVERS, "192.168.10.41:9092,192.168.10.42:9092,192.168.10.43:9092")
.option(KafkaConnectorOptions.PROPS_GROUP_ID, "testGroup")
.option("scan.startup.mode", "earliest-offset")
.format("csv")
.build();
tenv.createTemporaryTable("Alan_KafkaTable", kafkaDescriptor);
//查询
String sql = "select * from Alan_KafkaTable ";
Table resultQuery = tenv.sqlQuery(sql);
DataStream<Tuple2<Boolean, Row>> resultDS = tenv.toRetractStream(resultQuery, Row.class);
// 6、sink
resultDS.print();
// 7、执行
env.execute();
//kafka中输入测试数据
// 1,1001,login
// 1,2001,p_read
//程序运行控制台输入如下
// 11> (true,+I[16:32:19.923, 0, 0, 1, 1001, login])
// 11> (true,+I[16:32:32.258, 0, 1, 1, 2001, p_read])
}
@Data
@NoArgsConstructor
@AllArgsConstructor
public static class User {
private long id;
private String name;
private int age;
private Long rowtime;
}
}
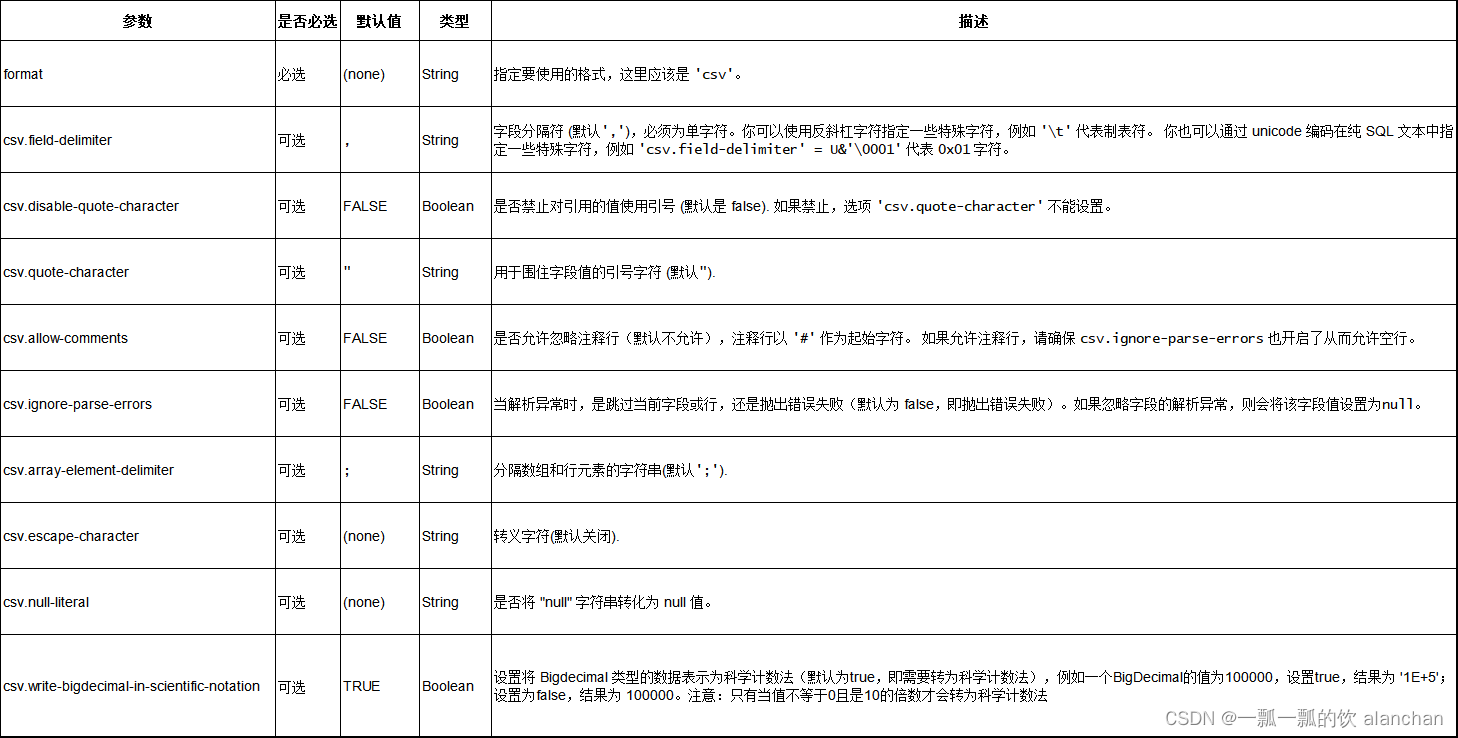
4、Format 参数
5、数据类型映射
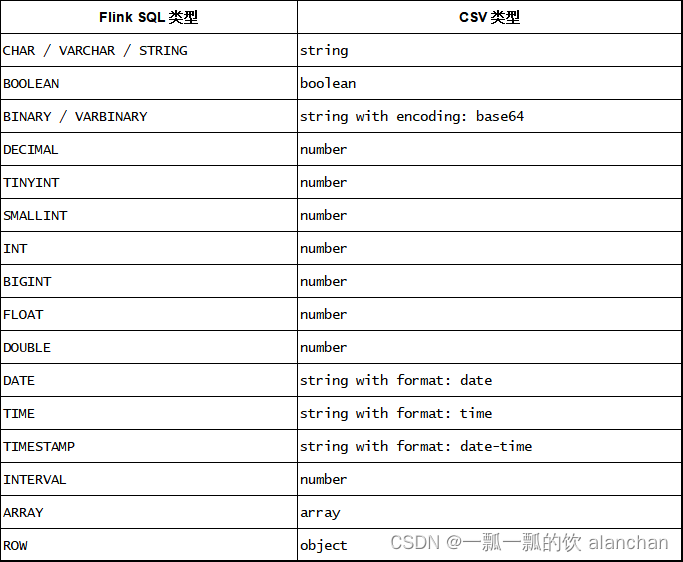
目前 CSV 的 schema 都是从 table schema 推断而来的。显式地定义 CSV schema 暂不支持。 Flink 的 CSV Format 数据使用 jackson databind API 去解析 CSV 字符串。
下面的表格列出了flink数据和CSV数据的对应关系。
三、JSON Format
JSON Format 能读写 JSON 格式的数据。当前,JSON schema 是从 table schema 中自动推导而得的。
1、maven 依赖
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-json</artifactId>
<version>1.17.1</version>
</dependency>
2、Flink sql client 建表示例
以下是一个利用 Kafka 以及 JSON Format 构建表的例子。
CREATE TABLE Alan_KafkaTable_json (
`id` INT,
name string,
age BIGINT,
t_insert_time TIMESTAMP(3) METADATA FROM 'timestamp',
WATERMARK FOR t_insert_time as t_insert_time - INTERVAL '5' SECOND
) WITH (
'connector' = 'kafka',
'topic' = 'Alan_KafkaTable_json',
'scan.startup.mode' = 'earliest-offset',
'properties.bootstrap.servers' = '192.168.10.41:9092,192.168.10.42:9092,192.168.10.43:9092',
'format' = 'json'
);
Flink SQL> CREATE TABLE Alan_KafkaTable_json (
> `id` INT,
> name string,
> age BIGINT,
> t_insert_time TIMESTAMP(3) METADATA FROM 'timestamp',
> WATERMARK FOR t_insert_time as t_insert_time - INTERVAL '5' SECOND
> ) WITH (
> 'connector' = 'kafka',
> 'topic' = 'Alan_KafkaTable_json',
> 'scan.startup.mode' = 'earliest-offset',
> 'properties.bootstrap.servers' = '192.168.10.41:9092,192.168.10.42:9092,192.168.10.43:9092',
> 'format' = 'json'
> );
[INFO] Execute statement succeed.
# kafka 客户端命令输入数据
[alanchan@server1 bin]$ kafka-console-producer.sh --broker-list server1:9092 --topic Alan_KafkaTable_json
>{ "id":"1" ,"name":"alan","age":"12" }
>{ "id":"2" ,"name":"alanchan","age":"22" }
>{ "id":"3" ,"name":"alanchanchan","age":"32" }
>{ "id":"4" ,"name":"alan_chan","age":"42" }
>{ "id":"5" ,"name":"alan_chan_chn","age":"52" }
>
# flink sql client查询数据
Flink SQL> select * from Alan_KafkaTable_json;
+----+-------------+--------------------------------+----------------------+-------------------------+
| op | id | name | age | t_insert_time |
+----+-------------+--------------------------------+----------------------+-------------------------+
| +I | 1 | alan | 12 | 2023-11-15 16:03:49.805 |
| +I | 2 | alanchan | 22 | 2023-11-15 16:04:02.632 |
| +I | 3 | alanchanchan | 32 | 2023-11-15 16:04:08.810 |
| +I | 4 | alan_chan | 42 | 2023-11-15 16:04:15.132 |
| +I | 5 | alan_chan_chn | 52 | 2023-11-15 16:04:21.146 |
3、table api 建表示例
通过table api建表,参考文章:
17、Flink 之Table API: Table API 支持的操作(1)
17、Flink 之Table API: Table API 支持的操作(2)
参考上文中关于CSV Format的table api 建表示例,变化的是json的格式参数。
4、Format 参数

5、数据类型映射关系
当前,JSON schema 将会自动从 table schema 之中自动推导得到。不支持显式地定义 JSON schema。
在 Flink 中,JSON Format 使用 jackson databind API 去解析和生成 JSON。
下表列出了 Flink 中的数据类型与 JSON 中的数据类型的映射关系。
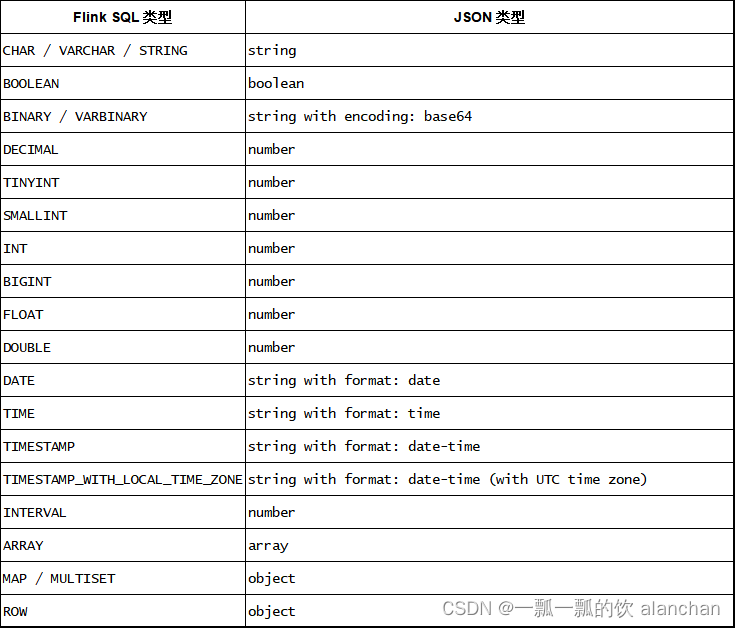
以上,介绍了Flink 支持的数据格式中的csv和json,并分别以sql和table api作为示例进行了说明。