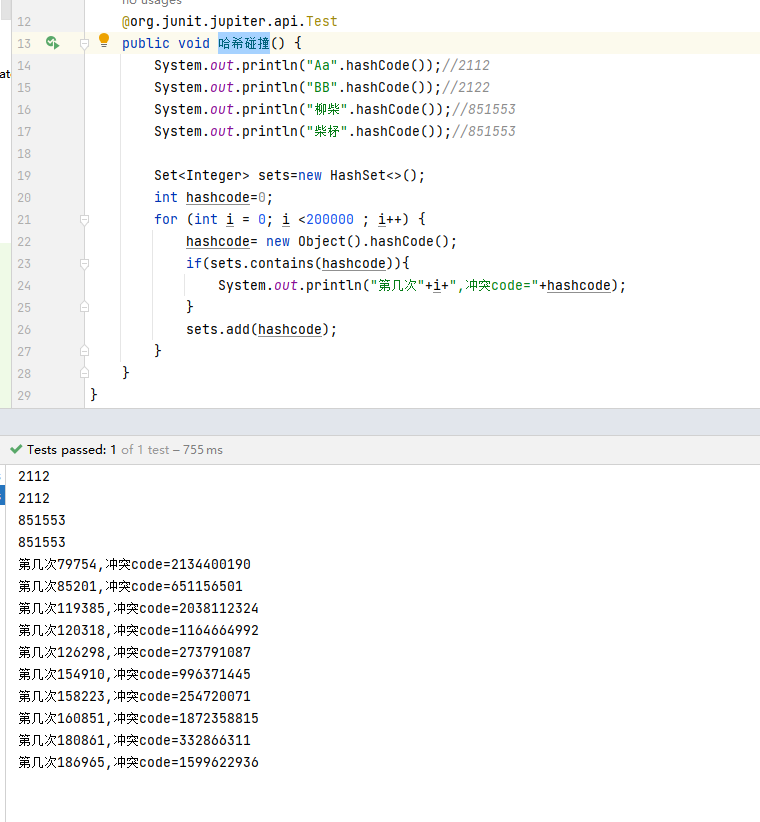
1 redis是单线程吗?
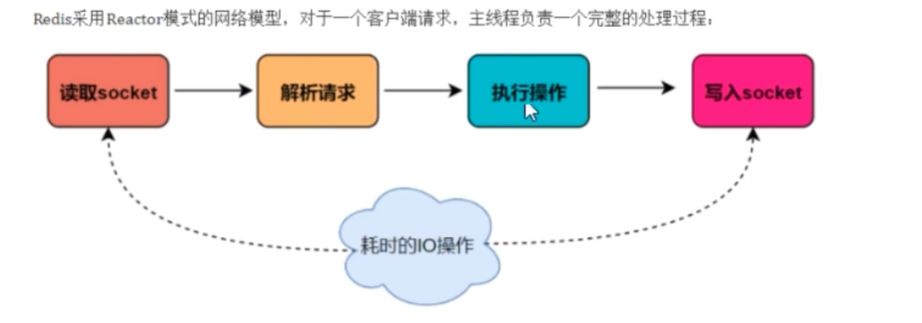
Redis是单线程
主要是指Redis的网络10和键值对读写是由一个线程来完成的,Redis在处理客户端的请求时包括获取(socket 读)、解析、执行、内容返回(socket 写) 等都由一个顺序串行的主线程处理,
但Redis的其他功能,比如持久化RDB、AOF、异步删除、集群数据同步等等,其实是由额外的线程执行的。Redis命令工作线程是单线程的,但是,整个Redis来说,是多线程的;
2 IO多路复用听说过吗?
什么叫IO?
input/output,针对文件的输入和输出。
Linux下的文件类型:
b(block块设备)
c(character字符设备)
d(directory目录)
-(普通文件)
l(line链接文件)
s(socket套接字文件)
p(pipe管道文件)
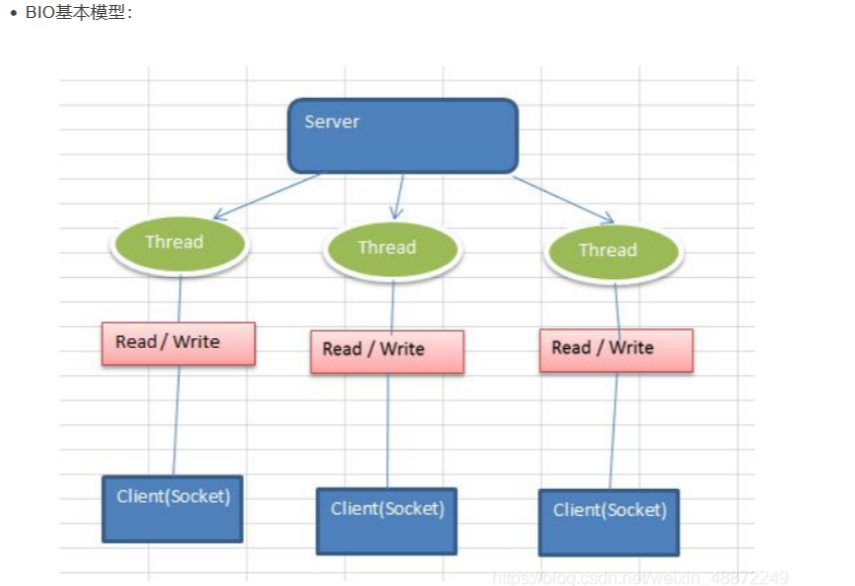
BIO:BIO(blocking I/O):同步阻塞,服务器实现模式为一个连接一个线程,即客户端有连接请求时服务器端就需要启动一个线程进行处理,如果这个连接不做任何事情会造成不必要的线程开销
BIO方式使用于连接数目比较小且固定的架构,这种服务方式对服务器资源要求比价高,并且局限于应用中,
package com.redis.redis01;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.PrintWriter;
import java.net.ServerSocket;
import java.net.Socket;
/**
* @version 1.0
* @Author zhaozhiqiang
* @Date 2023/11/10 9:08
* @Param
* @Description //TODO Socket(BIO,同步阻塞):BIO全称是Blocking IO,同步阻塞式IO,是JDK1.4之前的传统IO模型。
*/
public class SocketServer {
public static void main(String[] args) throws IOException {
ServerSocket serverSocket = new ServerSocket(8080);
while (true) {
Socket socket = serverSocket.accept(); // 阻塞等待客户端连接
new Thread(() -> {
try {
BufferedReader reader = new BufferedReader(new InputStreamReader(socket.getInputStream()));
String message = reader.readLine(); // 阻塞等待客户端数据
System.out.println("Received: " + message);
socket.close();
} catch (IOException e) {
e.printStackTrace();
}
}).start(); // 为每个客户端连接创建一个新线程处理,可能导致线程资源耗尽。
}
}
}
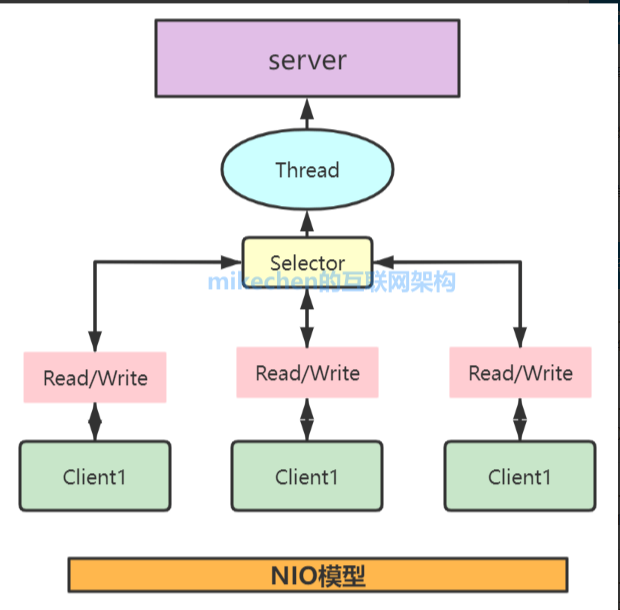
NIO:NIO全称 java non-blocking IO。从JDK 1.4开始,java提供了一些列改进的输入/输出(I/O)的新特性,被称为NIO,是同步非阻塞的
NIO三大核心部分:Channel(通道),Buffer(缓冲区),Selector(选择器)
package com.redis.redis01;
import java.io.IOException;
import java.net.InetSocketAddress;
import java.nio.ByteBuffer;
import java.nio.channels.SelectionKey;
import java.nio.channels.Selector;
import java.nio.channels.ServerSocketChannel;
import java.nio.channels.SocketChannel;
import java.util.Iterator;
/**
* @version 1.0
* @Author zhaozhiqiang
* @Date 2023/11/10 9:15
* @Param
* @Description //TODO NIO(同步非阻塞): Non-blocking,不单纯是 New,是解决高并发、I/O高性能的有效方式。
*/
public class NIOServer {
public static void main(String[] args) throws IOException {
ServerSocketChannel serverChannel = ServerSocketChannel.open();
//使SocketChannel工作在非阻塞模式
serverChannel.configureBlocking(false);
serverChannel.socket().bind(new InetSocketAddress(8080));
Selector selector = Selector.open();
serverChannel.register(selector, SelectionKey.OP_ACCEPT);
while (true) {
selector.select(); // 阻塞等待就绪Channel
Iterator<SelectionKey> iterator = selector.selectedKeys().iterator();
while (iterator.hasNext()) {
SelectionKey key = iterator.next();
iterator.remove();
if (key.isAcceptable()) {
ServerSocketChannel server = (ServerSocketChannel) key.channel();
SocketChannel client = server.accept();
client.configureBlocking(false);
client.register(selector, SelectionKey.OP_READ);
} else if (key.isReadable()) {
SocketChannel client = (SocketChannel) key.channel();
ByteBuffer buffer = ByteBuffer.allocate(1024);
int bytesRead = client.read(buffer);
if (bytesRead > 0) {
buffer.flip();
System.out.println("Received: " + new String(buffer.array(), 0, bytesRead));
client.close();
}
}
}
}
}
}
3 redis为啥那么快?
3.1 基于内存操作
所有Redis的数据都存在内存中,因此所有的运算都是内存级别的,所以他的性能高
3.2 数据结构简单
Redis的数据结构是专门设计的,这些简单的数据结构的查找和操作时间大部分复杂度都是O(1),性能高
3.3 多路复用和非阻塞IO
Redis使用I/O多路复用功能来监听多个socket连接客户端,这样可以使用一个线程来处理多个请求,减少线程切换带来额开销,同时也避免了I/O阻塞操作
3.4 避免上下文切换
因为是单线程模型,因此就避免了不必要的上下文切换和多线程竞争,这就省去了多线程切换带来的时间和性能上的消耗,而且单线程不会导致死锁问题的发生
4 redis读写能力咋样?
官网介绍
大数据量高性能(Redis一秒可以写8万次,读11万次,NoSQL的缓存记录级,是一种细粒度的缓存,性能会比较高)
WINDOWNS局域网本地测试

已用内存80%情况测试
package com.redis.redis01;
import org.junit.jupiter.api.Test;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.redis.core.RedisTemplate;
import javax.annotation.Resource;
import java.util.UUID;
@SpringBootTest
public class TestWR {
//注入模板 序列化
@Resource
private RedisTemplate<String, Object> redisTemplate;
volatile boolean stop = false;
/**
* redis写测试能力;简单字符平均大概在7000左右
* @throws InterruptedException
*/
@Test
void testWrite() throws InterruptedException {
Runnable runnable = new Runnable() {
public void run() {
int i=0;
while (!stop) {
//1 key和value都是UUID.randomUUID()+System.currentTimeMillis():每10秒683283个 每秒6833
//2 key和value都是UUID.randomUUID():每10秒67559个 每秒6755
//3 key和value都是从数字0开始递增:每10秒72562个 每秒72562
redisTemplate.opsForValue().set("" + i , "" + i);
i++;
}
}
};
new Thread(runnable).start();
Thread.sleep(10000);
new Thread(() -> {
stop = true;//调用shtdown方法stop为true
}).start();
}
/**
* redis读测试能力;简单字符平均大概在8000左右,比写快点
* @throws InterruptedException
*/
@Test
void testRead() throws InterruptedException {
Runnable runnable = new Runnable() {
public void run() {
int i=0;
while (!stop) {
redisTemplate.opsForValue().get("" + i );
i++;
}
System.out.println("读取到:"+i);//读取到:81374 大概每秒8134
}
};
new Thread(runnable).start();
Thread.sleep(10000);
new Thread(() -> {
stop = true;//调用shtdown方法stop为true
}).start();
}
}
结论:读能力大概81374/s,写能力大概72562/s,当前是redis3.2本地测试,是局域网,网络i/o影响不大,主要是内存当前没测试之前我的内存已经80%了;
内存剩余50%情况下测试
写7475/s,读8828/s
linux局域网测试
单机版本16G
内存已占用60

写1025/s,读1080/s
内存已经占用16

写1230/s,读1214
集群版本(一台16台机器装3主3从,和上面单机共用)
写1222/s,1312/s
redis7配置多线程后测试
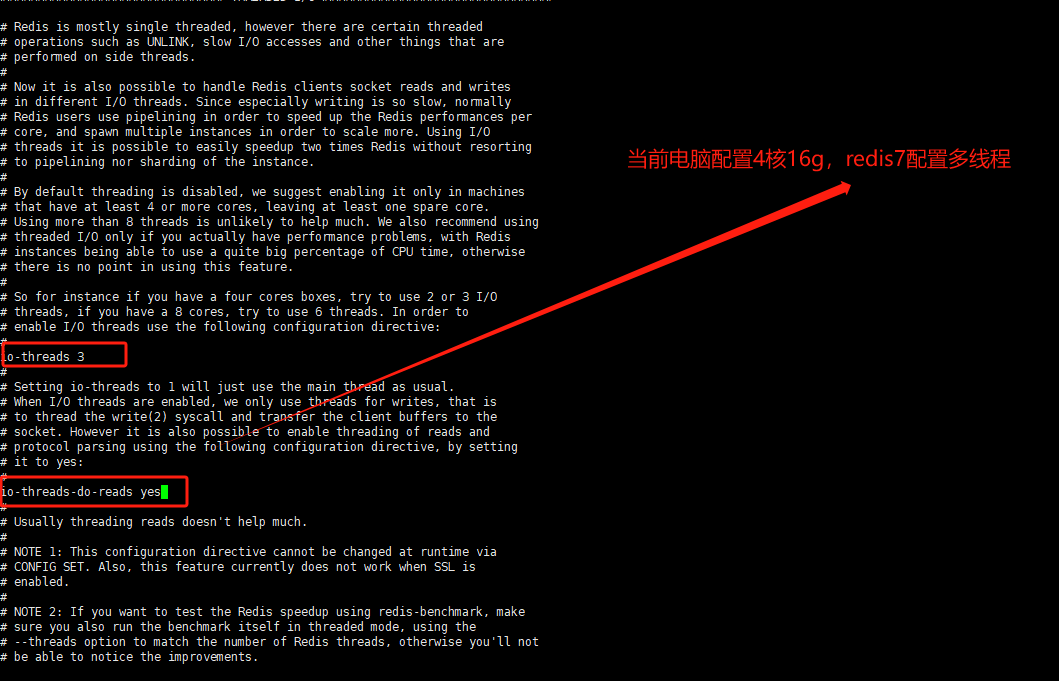
写1270/s,读1029
Jedis驱动测试
/**
* redis每秒读操作:
* 1 windows本地测试 13085/s
* 2 连接linux测试 1438/s
*
*/
@Test
public void redisTester2() throws InterruptedException {
// 1 connection 连接,通过指定ip和端口号
Jedis jedis = new Jedis("172.16.204.51", 6379);
// 2 指定访问服务器密码
jedis.auth("123456");
Runnable runnable = new Runnable() {
public void run() {
int i = 0;
try {
while (!stop) {
i++;
jedis.set("test" + i, i + "");
}
// 打印1秒内对Redis的操作次数
System.out.println("redis每秒操作:" + i + "次");
} finally {// 关闭连接
jedis.close();
}
}
};
new Thread(runnable).start();
Thread.sleep(1000);
new Thread(() -> {
stop = true;//调用shtdown方法stop为true
}).start();
}
1 jedis比lettuce快2倍左右,达到13085/s,(相同环境测试)
2 受网络带宽影响很大,连接linux测试慢了10倍
3 目前spingboot2.0之后集成lettuce连接redis,实际情况也就是5000左右,不会向jedis上万的
结论
1 上述16G配置在一般中小型公司算是比较高的配置了,当前测试都是局域网,带宽没限制比外网好太多,所以主要影响的就是内存了,redis官方理论写8万,读11万,应该是内存和网络io没限制的情况下最理想的情况下,当然内存2个T的肯定比16g测试出来的高太多,没条件测试
2 同一个机器下集群确实比单机redis读写能力更好,现在微服务大多数服务器配置2G,4G,8G,16G,32G的因该比较少,这种情况下redis读写能力在5000/s左右,集群的话可能达到1万左右,已经够用了,当前这是大概的说话,实际还要看情况
3 Jedis连接比lettuce确实快了很多将尽2倍数,RedisTemplate底层是lettuce线程安全的
5 redis7默认是否开启多线程?
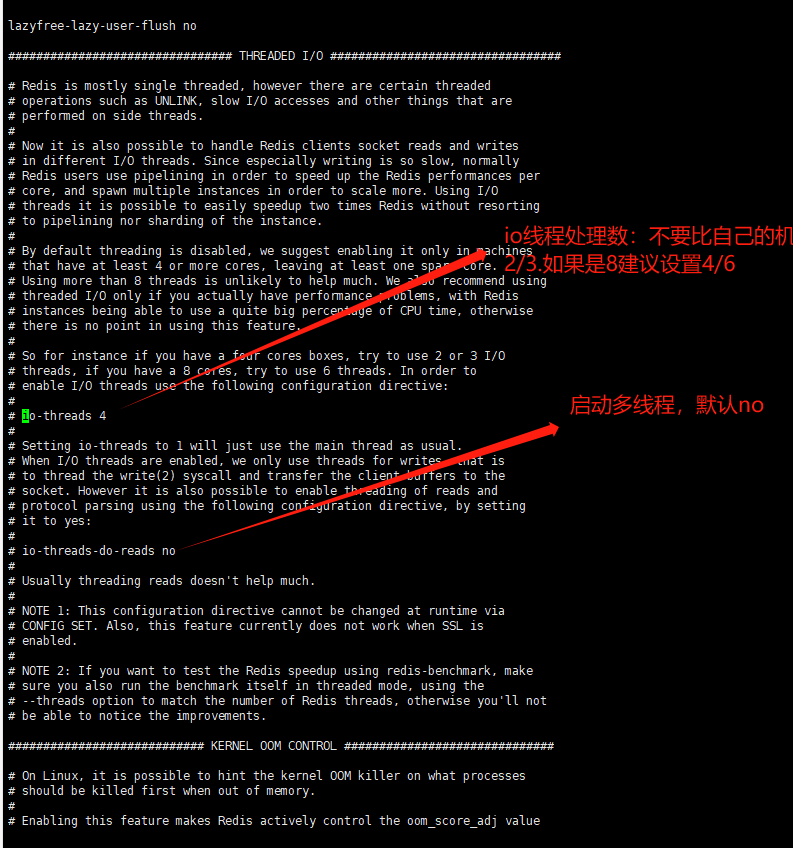
在单机模式下,可以开启多线程,但是在其他模式,最好不开启,Redis实例的 CPU开销不大但吞吐量却没有提升,可以考虑使用Redis7的多线程机制,加速网络处理,进而提升实例的吞吐量
6 redis是否支持多线程?
redis4之后才慢慢支持多线程,直到redis6/7稳定
7 redis是单线程的,如何利用多个cpu/内核?
CPU并不是您使用Redis的瓶颈,因为通常Redis要么受内存限制,要么受网络限制。例如,使用在平均Linux系统上运行的流水线Redis每秒可以发送一百万个请求,因此,如果您的应用程序主要使用0(N)或O(lg(N) )命令,则几乎不会使用过多的CPU。
但是,为了最大程度地利用CPU,您可以在同一中启动多个Redis实例,并将它们视为不同的服务器。在某个时候,单个盒子可能还不够,因此,如果您要使用多个CPU,则可以开始考虑更早地进行分片的某种方法。
8 Redis单线程为什么加了多线程特性?
8.1 因为单线程有单线程的问题,比如我要删除一个比较大的key,
del bigkey 会一直阻塞,等待删除完成,才能继续操作,会导致Redis主线程卡顿
所以引入了 惰性删除 可以有效避免Redis主线程卡顿
Redis 4.0 中就新增了多线程的模块,当然此版本中的多线程主要是为了解决删除数据效率比较低的问题的。
而lazy free的本质就是把某些cost(主要时间复制度,占用主线程cpu时间片)较高删除操作,从redis主线程剥离让BIO子线程来处理,极大地减少主线阻塞时间。从而减少删除导致性能和稳定性问题。
虽然引入了多个线程来实现数据的异步惰性删除等功能,但其处理读写请求的仍然只有一个线程,所以仍然算是狭义上的单线程
9 影响redis主要的性能瓶颈是内存/网络带宽/cpu?
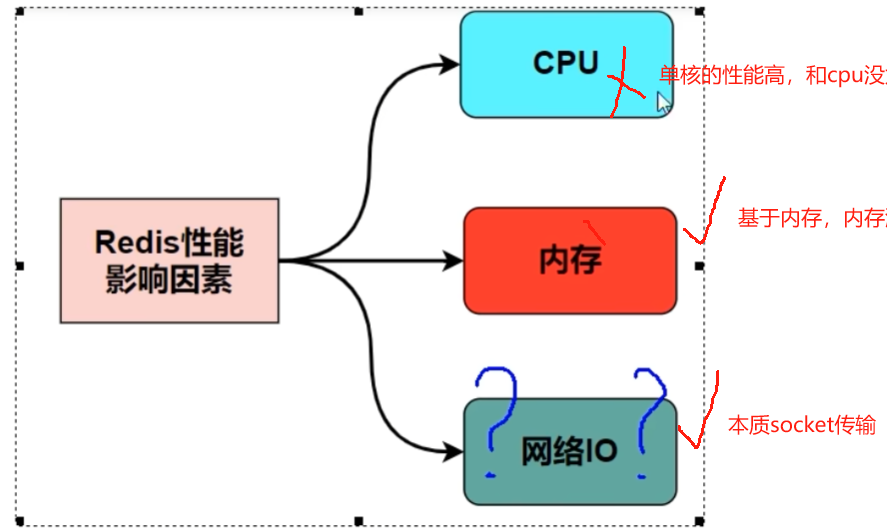
内存和带宽
10 redis大key如何处理?
准备数据阶段
1 造数据
for((i=1;i<=100*10000;i++)); do echo “set k i v i v ivi” >> /tmp/redisTest.txt ;done;
2 pipe管道命令执行
cat /tmp/redisTest.txt | /usr/local/install/redis-6.2.5/src/redis-cli -h localhost -p 6379 -a 123456 --pipe
:::info
linux redis6 100万数据, windows redis3.2 231万数据
:::
10.1 你如何生产上限制keys*、flushdb、flushall等危险命令以及防止误删误用?
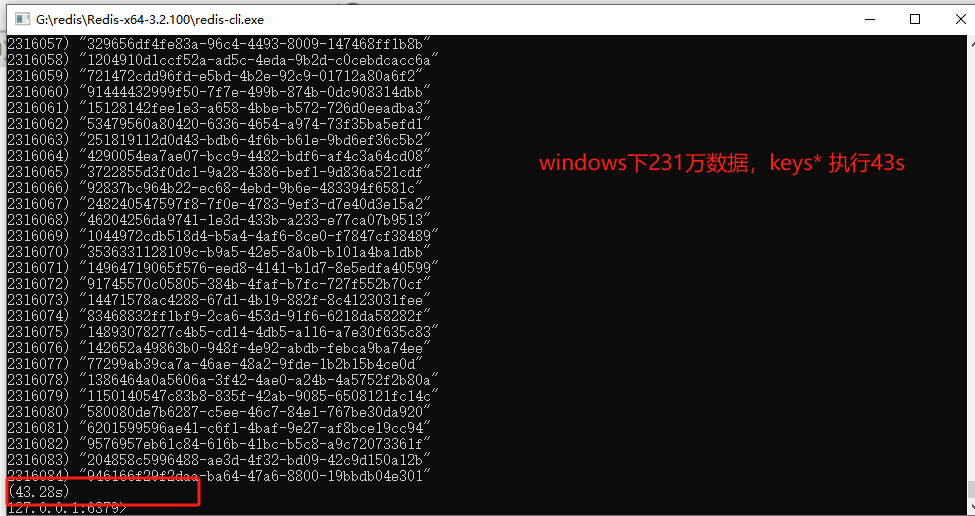

- keys * / flushall / flushdb 严禁 在线上使用
- keys * / flushall / flushdb 会造成阻塞,会导致Redis其他的读写都被延后甚至是超时报错,可能会引起缓存雪崩甚至数据库宕机
通过配置redis.conf禁用危险命令
rename-command keys ""
rename-command flushdb ""
rename-command flushall ""
重启禁用之后找不到命令

替代方案 scan类似与mysql limit,避免卡顿

@Test
void tesScan() throws InterruptedException {
long start = System.currentTimeMillis();
//需要匹配的key
String patternKey = "1*";
ScanOptions options = ScanOptions.scanOptions()
//这里指定每次扫描key的数量(很多博客瞎说要指定Integer.MAX_VALUE,这样的话跟 keys有什么区别?)
.count(10000)
.match(patternKey).build();
RedisSerializer<String> redisSerializer = (RedisSerializer<String>) redisTemplate.getKeySerializer();
Cursor cursor = (Cursor) redisTemplate.executeWithStickyConnection(redisConnection -> new ConvertingCursor<>(redisConnection.scan(options), redisSerializer::deserialize));
List<String> result = new ArrayList<>();
while(cursor.hasNext()){
result.add(cursor.next().toString());
}
//切记这里一定要关闭,否则会耗尽连接数。报Cannot get Jedis connection; nested exception is redis.clients.jedis.exceptions.JedisException: Could not get a
cursor.close();
log.info("scan扫描共耗时:{} ms key数量:{}",System.currentTimeMillis()-start,result.size());
}
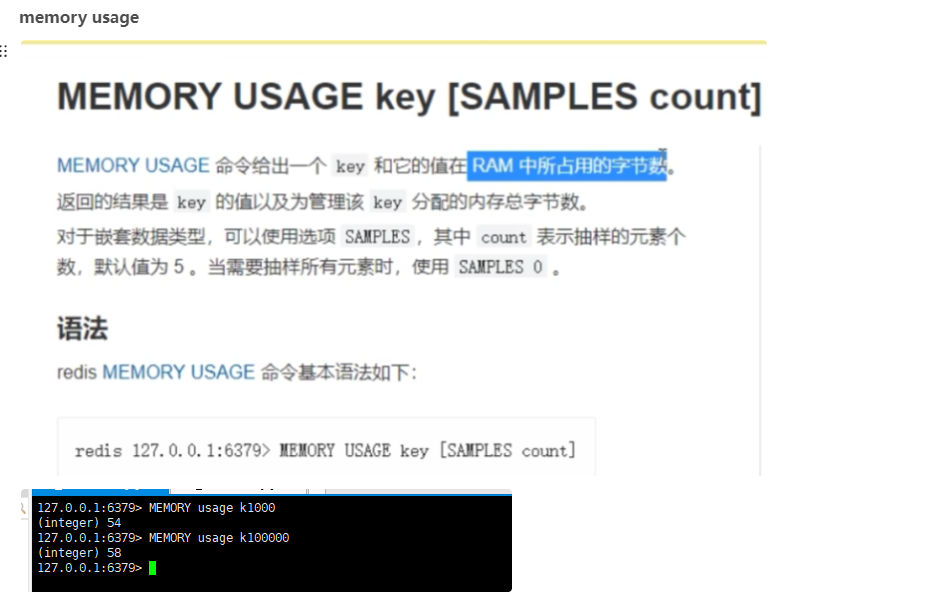
10.2 MEMORY USAGE命令你用过吗?
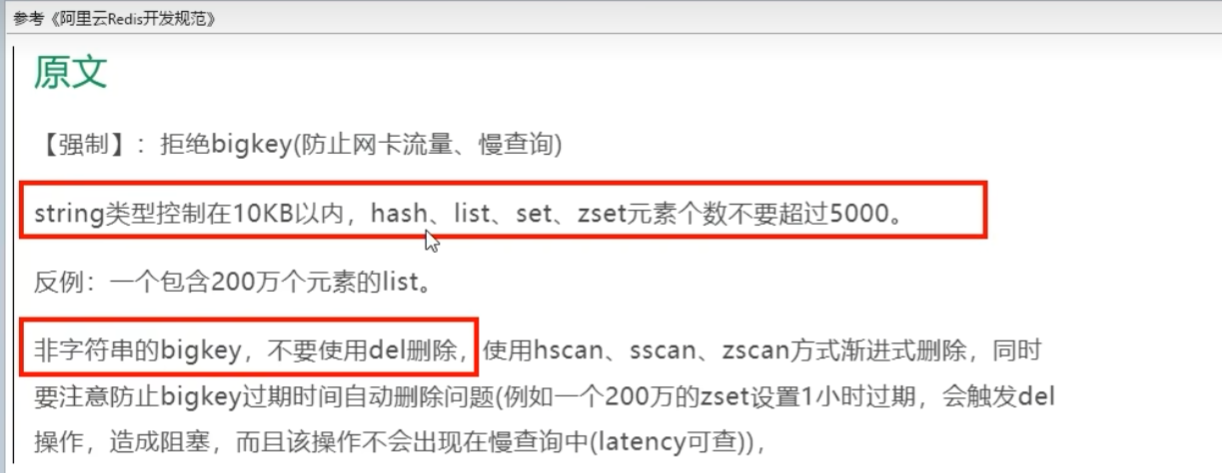
10.3 BigKey问题,多大算big?你如何发现?如何删除?如何处理?
多大算big
大的内容不是key本身,二十key对应的value

危害
- 内存不均,集群迁移困难
- 超时删除,大key导致阻塞
- 网络流量阻塞
如何产生、发现、删除
产生
- 社交类粉丝列表逐步递增
- 汇总统计某个报表,经年累月的积累
发现
redis-cli --bigkeys
redis-cli -h 127.0.0.1 -p 6379 -a 111111 --bigkeys
//每隔 100 条 scan 指令就会休眠 0.1s,ops 就不会剧烈抬升,但是扫描的时间会变长
redis-cli -h 127.0.0.1 -p 6379 –-bigkeys -i 0.1
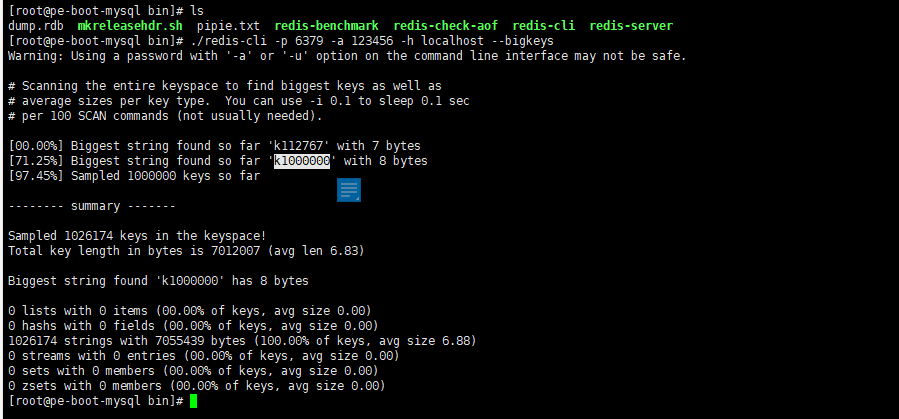
- 好处
- 给出每种数据结构Top 1 bigkey,同时给出每种数据类型的键值个数+平均大小
- 不足
- 想查询大于10kb的所有key,–bigkeys参数就无能为力了,需要用到memory usage来计算每个键值的字节数
memory usage

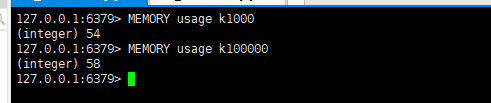
删除bigkey
- String
- 一般用del,过于庞大 unlink
- hash
- 使用hscan每次获取少量field-value,再使用hdel删除每个field
- 语法 hscan key cursor[match pattern] [count count]
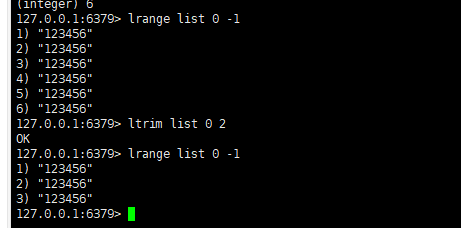
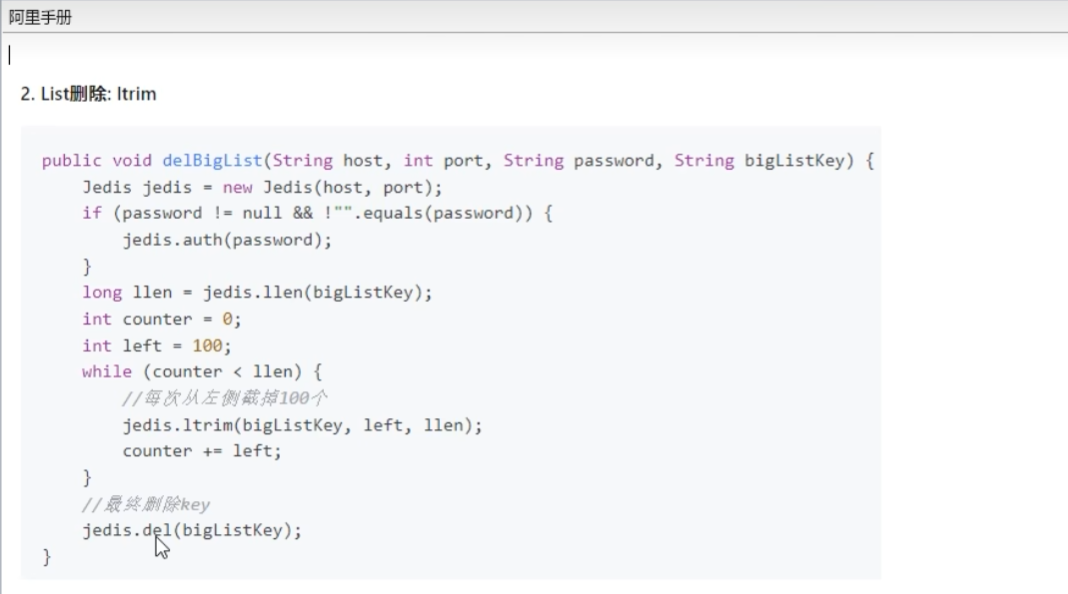
- ** list**
- 使用 ltrim 渐进式逐步删除,直到全部删除
- 命令 redis localhost:6379> ltrim key_name start stop
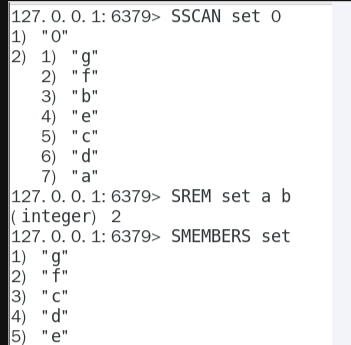
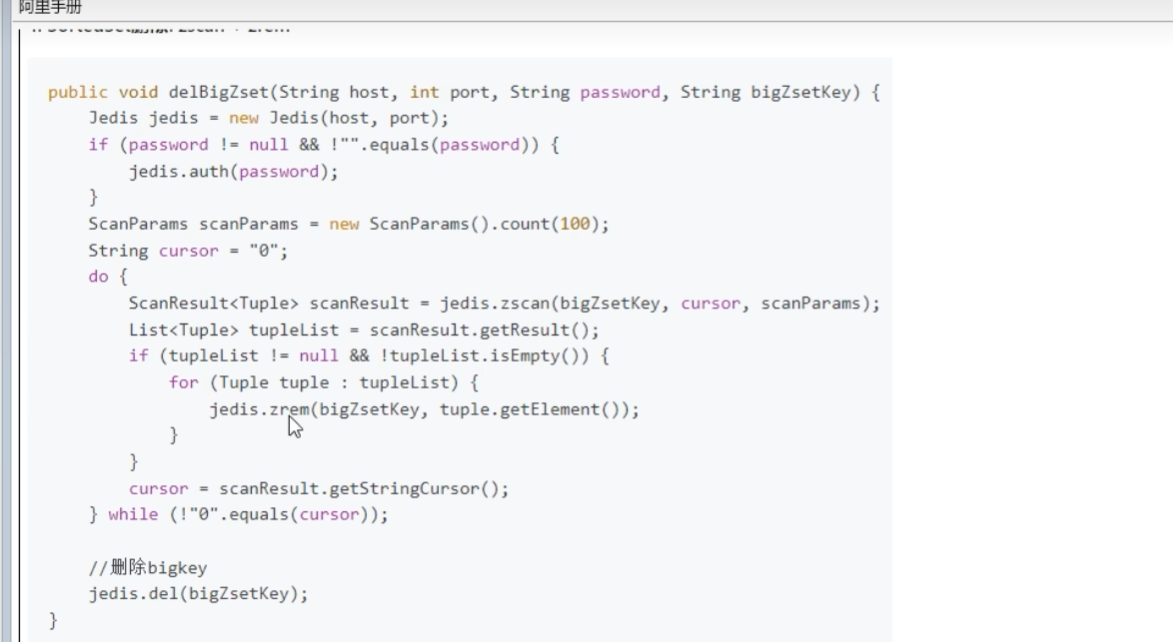
- set
- 使用sscan 每次获取部分元素,再使用 srem 命令删除每个元素
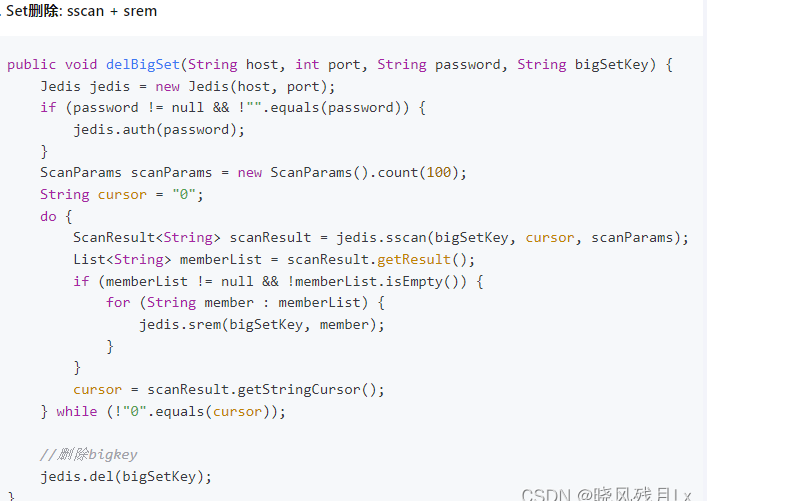
- zset
- 使用zscan每次获取部分元素,再使用ZREMRANGEBYRANK 命令删除每个元素
- 命令
10.4 BigKey你做过调优吗?惰性释放lazyfree了解吗?
- 阻塞和非阻塞删除命令
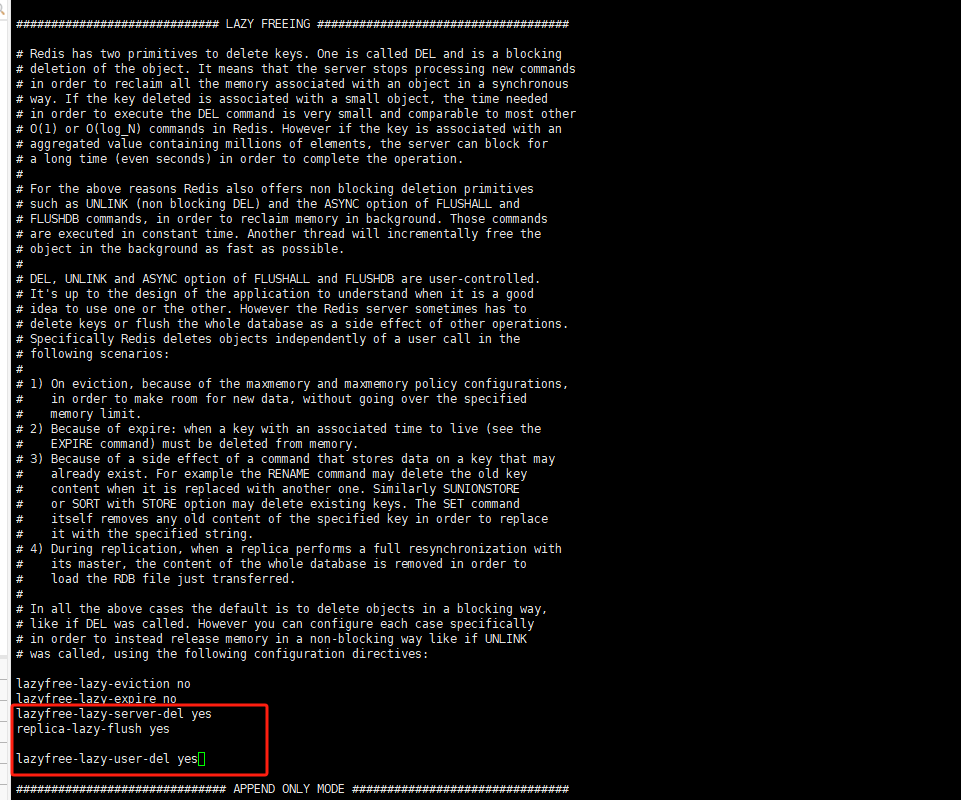
10.5 MoreKey问题,生产上redis数据库有1000w记录,你如何遍历?keys*可以吗?
1 scan 命令代替 keys ,避免卡顿
11 双写一致性
11.1 双写一致性,你先动缓存redis还是数据库mysql,why?
4中双写一致性更新策略
先更新数据库,再更新缓存
问题
- 回写redis失败,读到redis脏数据
- 多线程下/高并发下,回写redis延迟,redis更新的数据不是最终结果,导致督导redis脏数据,mysql和redis数据不一致

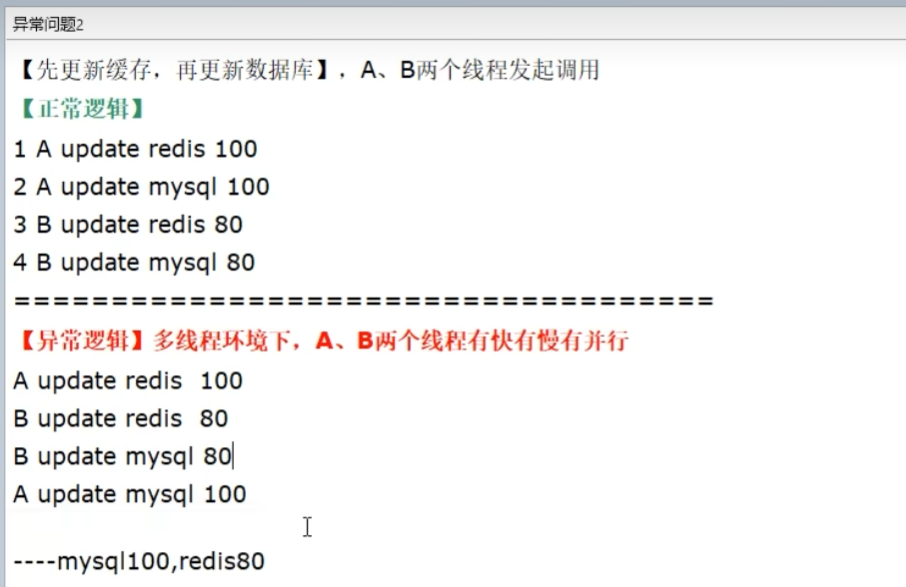
先更新缓存,再更新数据库
问题
- 一般把mysql写入作为准则,保证最后的解释,不推荐这样做
- 多线程高并发下,redis和mysql数据不一致
先删除缓存,再更新数据库
a线程删除redis,正在更新mysql还没commit,b线程读取mysql回写redis,a线程更新完成mysql发现redis 还是之前旧值
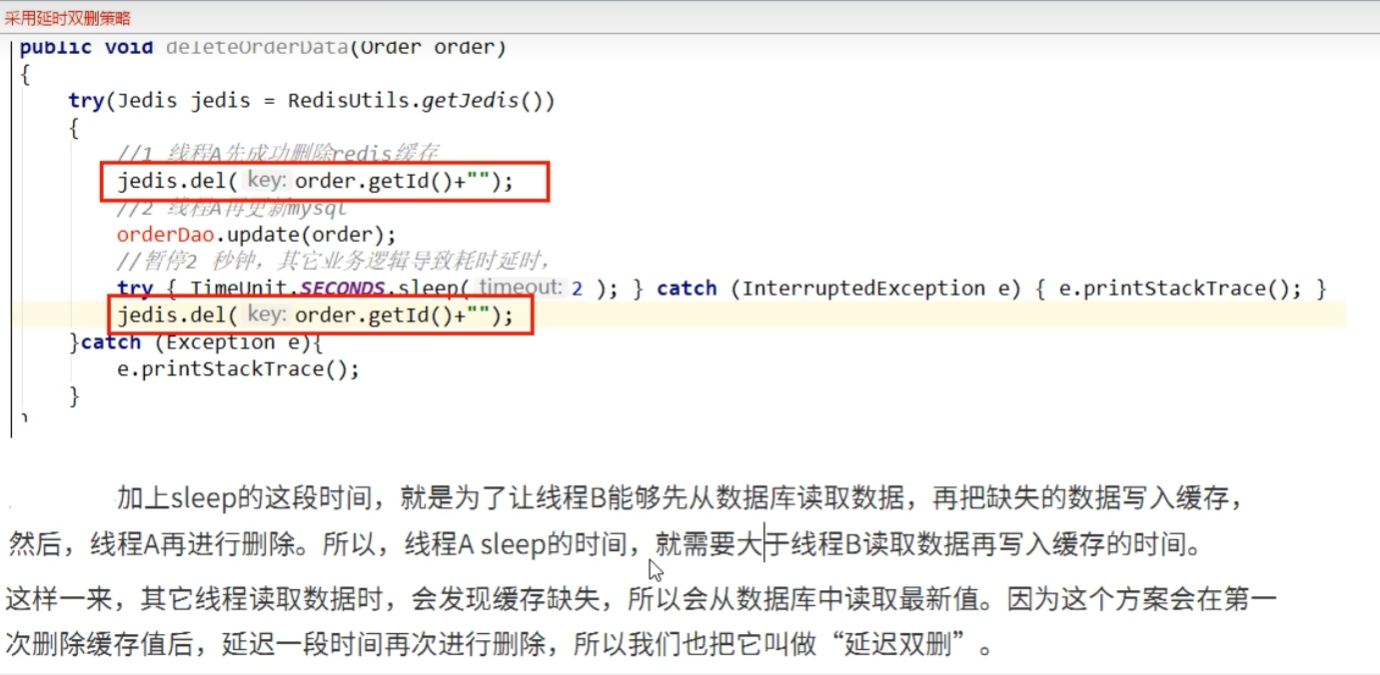
解决方案延时双删
延迟双删问题
这个删除该休眠多久呢?
- 统计线程读取和写入缓存的操作时间,自行评估项目中读业务数据耗时逻辑,进行估算,然后写数据的休眠时间再读取业务逻辑耗时的基础上增加百毫秒即可
- 新启动一个后台监控程序,watchDog监控程序会加时
这种同步淘汰策略,吞吐量降低咋么办?
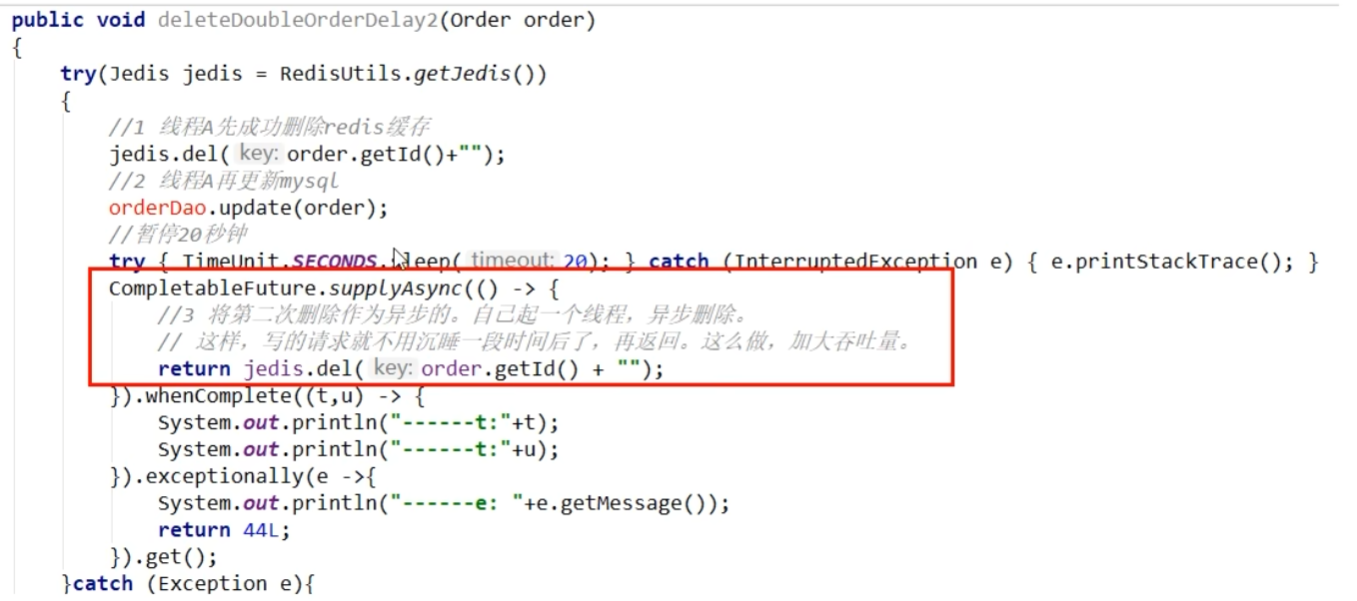
先更新数据库,再删除缓存
如果删除redis中的key不成功,如何解决
消息队列

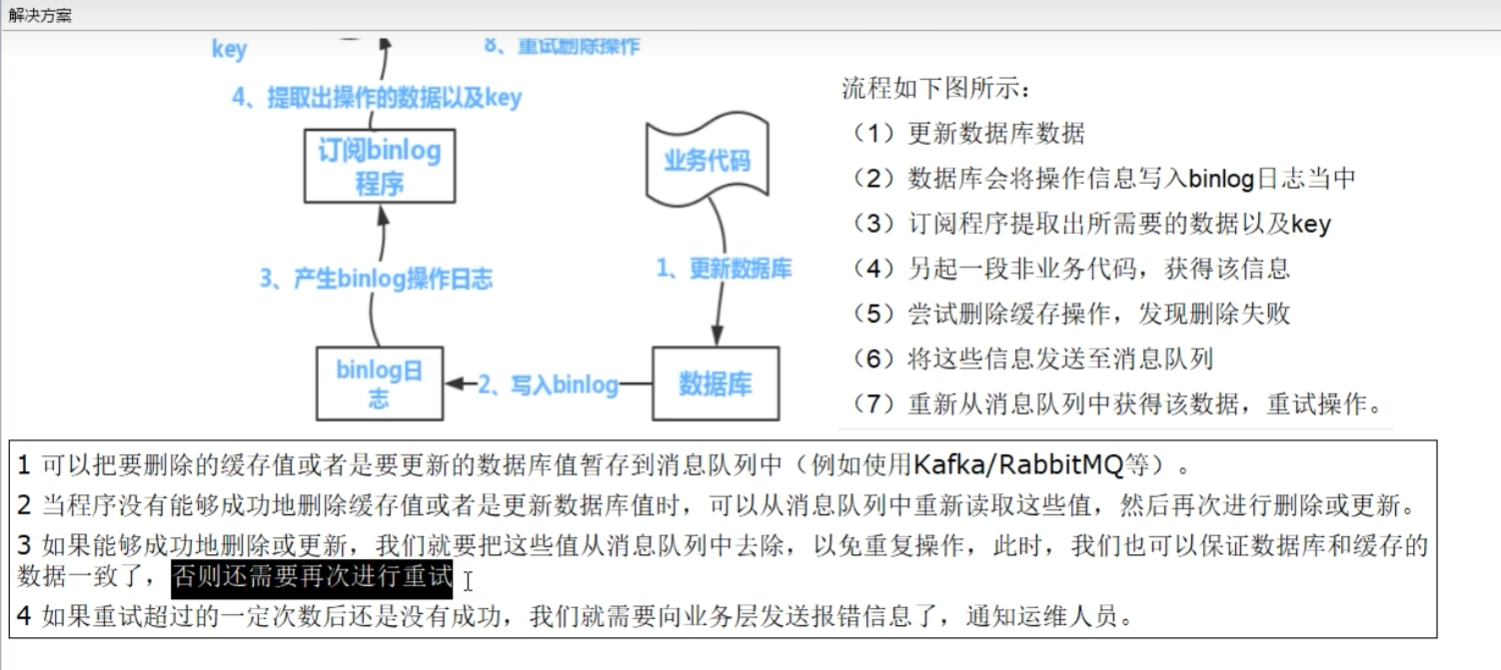
总结
先更新数据库,再删除缓存
如果业务层要求必须读取一致性的数据,那么我们就需要在更新数据库时,先在Redis缓存客户端暂停并发读请求,等数据库更新完、缓存值删除后,再读取数据,从而保证数据一致性,这是理论可以达到的效果,但实际,不推荐,因为真实生产环境中,分布式下很难做到实时一致性,一般都是最终一致性。
11.2 延迟双删你做过吗?会有哪些问题?
参照3.1 3.2
11.3 微服务查询redis无mysql有,为保证数据双写一致性回写redis需要注意仕么?
11.4 双加锁策略你了解吗?如何经量避免缓存击穿?
双锁策略定义
- 多个线程同时去查询数据库的这条数据,就在第一个查询数据的请求上使用一个互斥锁来锁住他。
- 其他线程获取不到锁就一直等待,等第一个线程查询到了数据,然后做了缓存
- 后面的线程进来发现已经有了缓存,就直接走缓存
避免缓存击穿
1 设置热点数据永不过期
2 加互斥锁,如下代码
/**
* 压力测试结果
* 1 id存在
* type=0,qps=1000,id存在 吞吐量 979.4/s 平均值 2
* type=0,qps=10000,id存在 吞吐量 1550.2/s 平均值 14
* type=1,qps=10000,id存在 吞吐量 4207.2/s 平均值 13
* 2 id不存在(null,失效,攻击能情况)
* type=0,qps=1000,id不存在 吞吐量 1541.3/s 平均值 42
* type=0,qps=10000,id不存在 吞吐量 1420.2/s 平均值 99
* type=1,qps=10000,id不存在 吞吐量 1582.7/s 平均值 89
*
* 结论:
* 1 重量级锁synchronized的吞吐量小于轻量级可重入锁ReentrantLock的吞吐量
* 2 重量级锁synchronized的平均响应时间大于轻量级锁ReentrantLock
* 3 双入保护机制能有效的保护系统的健壮性
*
* @param id
* @param type
* @param qps
* @return
*/
@RequestMapping(value = "findUserById")
public RedisBs findUserById(@RequestParam("id") Integer id, @RequestParam("type") int type, @RequestParam("qps")int qps) {
com.redis.redis01.bean.RedisBs userById = service.findUserById(id,type,qps);
return userById;
}
package com.redis.redis01.service;
import com.redis.redis01.bean.RedisBs;
import com.redis.redis01.mapper.RedisBsMapper;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
import javax.annotation.Resource;
import java.beans.Transient;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.locks.ReentrantLock;
@Slf4j
@Service
public class RedisBsService {
//定义key前缀/命名空间
public static final String CACHE_KEY_USER = "user:";
@Autowired
private RedisBsMapper mapper;
@Resource
private RedisTemplate<String, Object> redisTemplate;
private static ReentrantLock lock = new ReentrantLock();
/**
* 业务逻辑没有写错,对于中小长(qps<=1000)可以使用,但是大厂不行:大长需要采用双检加锁策略
*
* @param id
* @return
*/
@Transactional
public RedisBs findUserById(Integer id,int type,int qps) {
//qps<=1000
if(qps<=1000){
return qpsSmall1000(id);
}
//qps>1000
return qpsBig1000(id, type);
}
/**
* 加强补充,避免突然key失效了,或者不存在的key穿透redis打爆mysql,做一下预防,尽量不出现缓存击穿的情况,进行排队等候
* @param id
* @param type 0使用synchronized重锁,1ReentrantLock轻量锁
* @return
*/
private RedisBs qpsBig1000(Integer id, int type) {
RedisBs redisBs = null;
String key = CACHE_KEY_USER + id;
//1先从redis里面查询,如果有直接返回,没有再去查mysql
redisBs = (RedisBs) redisTemplate.opsForValue().get(key);
if (null == redisBs) {
switch (type) {
case 0:
//加锁,假设请求量很大,缓存过期,大厂用,对于高qps的优化,进行加锁保证一个请求操作,让外面的redis等待一下,避免击穿mysql
synchronized (RedisBsService.class) {
//第二次查询缓存目的防止加锁之前刚好被其他线程缓存了
redisBs = (RedisBs) redisTemplate.opsForValue().get(key);
if (null != redisBs) {
//查询到数据直接返回
return redisBs;
} else {
//数据缓存
//查询mysql,回写到redis中
redisBs = mapper.findUserById(id);
if (null == redisBs) {
// 3 redis+mysql都没有数据,防止多次穿透(redis为防弹衣,mysql为人,穿透直接伤人,就是直接访问mysql),优化:记录这个null值的key,列入黑名单或者记录或者异常
return new RedisBs(-1, "当前值已经列入黑名单");
}
//4 mysql有,回写保证数据一致性
//setifabsent
redisTemplate.opsForValue().setIfAbsent(key, redisBs,7l, TimeUnit.DAYS);
}
}
break;
case 1:
//加锁,大厂用,对于高qps的优化,进行加锁保证一个请求操作,让外面的redis等待一下,避免击穿mysql
lock.lock();
try {
//第二次查询缓存目的防止加锁之前刚好被其他线程缓存了
redisBs = (RedisBs) redisTemplate.opsForValue().get(key);
if (null != redisBs) {
//查询到数据直接返回
return redisBs;
} else {
//数据缓存
//查询mysql,回写到redis中
redisBs = mapper.findUserById(id);
if (null == redisBs) {
// 3 redis+mysql都没有数据,防止多次穿透(redis为防弹衣,mysql为人,穿透直接伤人,就是直接访问mysql),优化:记录这个null值的key,列入黑名单或者记录或者异常
return new RedisBs(-1, "当前值已经列入黑名单");
}
//4 mysql有,回写保证数据一致性
redisTemplate.opsForValue().set(key, redisBs);
}
} catch (Exception e) {
e.printStackTrace();
} finally {
//解锁
lock.unlock();
}
}
}
return redisBs;
}
private RedisBs qpsSmall1000(Integer id) {
RedisBs redisBs = null;
String key = CACHE_KEY_USER + id;
//1先从redis里面查询,如果有直接返回,没有再去查mysql
redisBs = (RedisBs) redisTemplate.opsForValue().get(key);
if (null == redisBs) {
//2查询mysql,回写到redis中
redisBs = mapper.findUserById(id);
if (null == redisBs) {
// 3 redis+mysql都没有数据,防止多次穿透(redis为防弹衣,mysql为人,穿透直接伤人,就是直接访问mysql),优化:记录这个null值的key,列入黑名单或者记录或者异常
return new RedisBs(-1, "当前值已经列入黑名单");
}
//4 mysql有,回写保证数据一致性
redisTemplate.opsForValue().set(key, redisBs);
}
return redisBs;
}
}
11.5 redis和mysql双写100%会处纰漏,做不到强一直性,你如何保证最终一致性?
以mysql写入数据为准,对缓存操作做最大努力即可,也就是说,写入mysql成功,缓存更新失败,那么只要达到过期时间,后面请求自然会从数据库中读取新值然后回填缓存,达到最终一致性
12 mysql有记录改动了,立刻同步反应到redis?该如何做?
canal 监听mysql回写redis
https://github.com/alibaba/canal
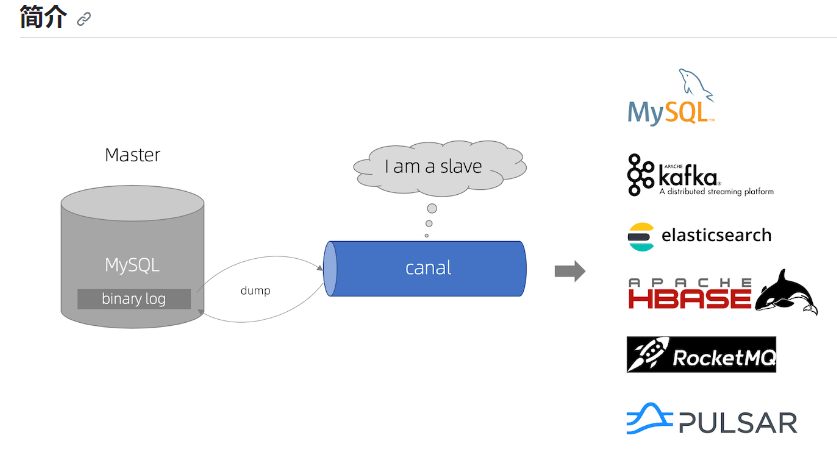 canal [kə’næl],译意为水道/管道/沟渠,主要用途是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费
canal [kə’næl],译意为水道/管道/沟渠,主要用途是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费
早期阿里巴巴因为杭州和美国双机房部署,存在跨机房同步的业务需求,实现方式主要是基于业务 trigger 获取增量变更。从 2010 年开始,业务逐步尝试数据库日志解析获取增量变更进行同步,由此衍生出了大量的数据库增量订阅和消费业务。
基于日志增量订阅和消费的业务包括
- 数据库镜像
- 数据库实时备份
- 索引构建和实时维护(拆分异构索引、倒排索引等)
- 业务 cache 刷新
- 带业务逻辑的增量数据处理
当前的 canal 支持源端 MySQL 版本包括 5.1.x , 5.5.x , 5.6.x , 5.7.x , 8.0.x
13 对于亿级数据的收集、清洗、统计、展现,需要用仕么技术实现?介绍一下pv、uv、pau?仕么是基数统计?
UV: Unique Visitor ,独立访客数,是指在一个统计周期内,访问网站的人数之和。一般理解客户ip,需要去重
PV : Page View,浏览量,是指在一个统计周期内,浏览页面的数之和。不需要去重
DAU: Daily Active User 日活跃用户数量;去重
DNU:Daily New User,日新增用户数
MAU:Monthly New User,月活跃用户;去重
需要使用redis hyperloglog基数统计数据结构来实现
基数统计:数据集中不重复的元素的个数
HyperLogLog 的优点是,在输入元素的数量或者体积非常非常大时,计算基数所需的内存空间总是固定的、并且是很小的。因为 HyperLogLog 只会根据输入元素来计算基数,而不会储存输入元素本身;
HyperLogLog 优势在于只需要花费 12 KB 内存,就可以计算接近 2^64 个元素的基数,和元素越多就越耗费内存的 Set 和 Hash 类型相比,HyperLogLog 就非常节省空间。所以,非常适合统计百万级以计网站的独立访客数场景。
14 布隆过滤器了解过吗?
由一个初值都为零的bit数组和多个哈希函数构成,用来快速判断集合中是否存在某个元素
目的
减少内存占用
方式
不保存数据信息,只是在内存中做一个是否存在的标记flag
本质
判断具体数据是否村在于一个大的集合中
布隆过滤器是一种类似 set 的数据结构,只是统计结果在巨量数据下有点小瑕疵,不够完美
- 它实际上是一个很长的二进制数组(00000000)+一系列随机hash算法映射函数,主要用于判断一个元素是否在集合中。
- 通常我们会遇到很多要判断一个元素是否在某个集合中的业务场景,一般想到的是将集合中所有元素保存起来,然后通过比较确定。
- 链表、树、哈希表等等数据结构都是这种思路。但是随着集合中元素的增加,我们需要的存储空间也会呈现线性增长,最终达到瓶颈。同时检索速度也越来越慢,上述三种结构的检索时间复杂度分别为O(n),O(logn),O(1)。这个时候,布隆过滤器(Bloom Filter)就应运而生
能干嘛
- 高效地插入和查询,占用空间少,返回地结果是不确定性 + 不完美性
- 一个元素如果判断结果:存在时,元素不一定存在,不存在时,元素一定不存在
- 布隆过滤器可以添加元素,但是不能删除元素
- 涉及到hashcode判断依据,删掉元素会导致误判率增加
- 为什么不能删掉?
- 因为他是有多个 hash 函数,对一个值进行多次 hash 运算,将获得的每个值,在对应位置存 1 ,容易导致这个 1 也代表别的值,一旦删除,另一个值也无法通过