概述
在选择一款数据库产品时,对数据库上下游生态组件的打通是大数据开发工程师需要面对的一致难题。
MatrixOne提出了“One Size Fits Most”理念,旨在用全新HSTAP技术架构打破数据孤岛,其中,与各生态组件的“无缝衔接”也是MatrixOne“一栈式”愿景中的重要一环。
MatrixOne高度兼容MySQL协议,在1.0正式版发布前,MatrixOne收集整理了社区反馈较多的上下游组件并进行了更为完整的适配。本轮适配主要围绕:数据集成工具、BI工具和数据计算引擎这三类生态工具。
Part 1 数据集成工具
数据集成工具可以将来自不同数据源的数据整合为统一的数据集,通常具备从不同数据源中收集数据、对数据进行清洗、转换、重构和整合的能力,以便能够在一个统一的数据仓库或数据湖中进行存储和管理。
与数据集成工具的适配可帮助数据开发工程师更丝滑高效的进行初期存量数据的迁移和后续日常的ETL作业,极大的保障工作效率和业务的稳定性。
MatrixOne在征集社区建议后,本轮优先对DataX与SeaTunnel进行了适配。得益于对MySQL协议的高度兼容,经过本轮适配,我们在DataX或SeaTunnel中可以直接使用MySQL所对应的Writer或Driver来对MatrixOne进行连接访问。
在DataX官方版本中,mysqlwriter默认使用版本较老的mysql-connector-java-5.1.47.jar驱动,为保证拥有更好的性能和兼容性,在适配了mysqlwriter的基础上,MatrixOne社区还基于mysqlwriter改造出使用mysql-connector-j-8.0.33.jar驱动的matrixonewriter,作业json示例如下,欢迎社区同学下载使用:
{
"job": {
"setting": {
"speed": {
"channel": 1
}
},
"content": [
{
"reader": {
"name": "streamreader",
"parameter": {
"column" : [
{
"value": 20210106,
"type": "long"
},
{
"value": "matrixone",
"type": "string"
}
],
"sliceRecordCount": 1000
}
},
"writer": {
"name": "matrixonewriter",
"parameter": {
"writeMode": "insert",
"username": "root",
"password": "111",
"column": [
"M_ID",
"M_NAME"
],
"preSql": [
"delete from m_user"
],
"connection": [
{
"jdbcUrl": "jdbc:mysql://127.0.0.1:6001/mo_demo",
"table": [
"m_user"
]
}
]
}
}
}
]
}
}Part 2 BI工具
BI即指商业智能(Business Intelligence),指用现代数据仓库技术、线上分析处理技术、数据挖掘和数据展现技术进行数据分析以实现商业价值。例如数据分析师会使用BI工具,基于海量的散乱数据进行数据分析,最终产出清晰的、可用于支持决策的数据报表。
BI工具所用的数据通常存储在数据库中,由于不同数据库之间语法存在不同程度的差异,BI厂商通常会与数据库厂商进行兼容性互认并针对性的开发出对应的连接器。
MatrixOne本次针对Superset、FineBI和永洪BI进行了首轮的适配,当我们在使用上述BI工具连接MatrixOne时,可以直接选择MySQL连接器,将MatrixOne视为MySQL进行连接访问,来对用户的数据可视化场景提供有效支撑。下图为永洪BI使用MySQL数据源连接示例:
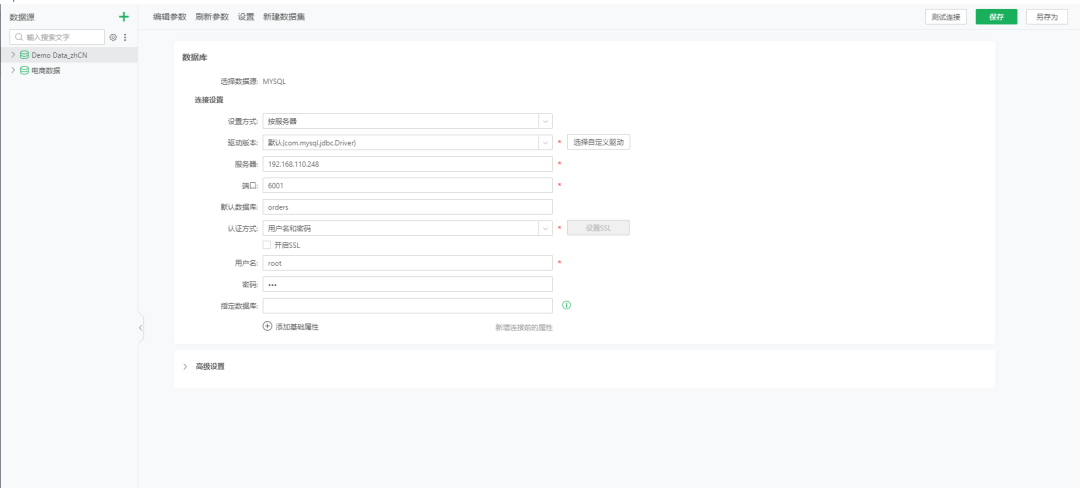
BI的适配工作无法做到“一步到位”,MatrixOne当前先基于MySQL语法兼容性来实现与BI的高度兼容,随着MatrixOne新版本个性化能力的不断扩展,我们也会积极推进和BI厂商的互认,来协同开发出兼容性更优的专用连接器。
Part 3 数据计算引擎
大数据计算引擎主要用于对数据的加工、清洗、计算或迁移导入,常用的计算引擎例如:MapReduce、Storm、Spark、Flink等。其中,Spark和Flink作为目前主流的批量/流式计算引擎,MatrixOne进行了细节的测试和适配。
MatrixOne规划中的“流引擎”能力在持续完善中,在适配Spark/Flink引擎后,开发者可以直接使用通用JDBC驱动,在Spark或Flink中通过外部算力进行大数据量级的数据清洗,再或着,通过Flink实现更灵活的“流式数据源”的数据接入。例如,MatrixOne 1.0版本原生实现了与Kafka中数据源的连接:
CREATE SOURCE | SINK CONNECTOR [IF NOT EXISTS] connector_name CONNECTOR_TYPE WITH(property_name = expression [, ...]);通过本轮适配Flink引擎,MatrixOne即可扩展支持包括Kafka、Pulsar、RocketMQ等更广泛的消息队列产品。以使用Flink Table API为例:
--定义Kafka源表
CREATE TABLE kafka_source (
`user_id` BIGINT,
`item_id` BIGINT,
`behavior` STRING
) WITH (
'connector' = 'kafka',
'topic' = 'user_behavior',
'properties.bootstrap.servers' = 'localhost:9092',
'properties.group.id' = 'testGroup',
'scan.startup.mode' = 'earliest-offset',
'format' = 'csv'
)
--定义MatrixOne目标表,驱动使用mysql驱动
CREATE TABLE matrixone_kafka_sink (
`user_id` BIGINT,
`item_id` BIGINT,
`behavior` STRING,
PRIMARY KEY(user_id) NOT ENFORCED
) WITH (
'connector' = 'mysql',
'hostname' = '<yourHostname>',
'port' = '6001',
'username' = '<yourUsername>',
'password' = '<yourPassword>',
'database-name' = '<yourDatabaseName>',
'table-name' = '<yourTableName>'
);
--同步Kafka流式数据到MatrixOne
INSERT INTO matrixone_sink SELECT * FROM kafka_source;此外,借助Flink CDC,MatrixOne也可支持对传统TP类数据库的数据同步,这项能力的补齐可帮助企业在不改变原业务上游框架的基础上扩展加入MatrixOne,然后使用MatrixOne统一下游业务所需的数据分析场景,真正实现“Single Source of Truth”。仍以Flink Table API为例:
--定义MySQL CDC流式数据源
CREATE TABLE mysql_cdc_orders (
`user_id` BIGINT,
`item_id` BIGINT,
`behavior` STRING,
PRIMARY KEY(user_id) NOT ENFORCED
) WITH (
'connector' = 'mysql-cdc',
'hostname' = 'localhost',
'port' = '3306',
'username' = 'flinkuser',
'password' = 'flinkpw',
'database-name' = 'mydb',
'table-name' = 'orders'
);
--定义MatrixOne目标表,驱动使用mysql驱动
CREATE TABLE matrixone_cdc_sink (
`user_id` BIGINT,
`item_id` BIGINT,
`behavior` STRING,
PRIMARY KEY(user_id) NOT ENFORCED
) WITH (
'connector' = 'mysql',
'hostname' = '<yourHostname>',
'port' = '6001',
'username' = '<yourUsername>',
'password' = '<yourPassword>',
'database-name' = '<yourDatabaseName>',
'table-name' = '<yourTableName>'
);
--同步MySQL binlog流式数据到MatrixOne
INSERT INTO matrixone_cdc_sink SELECT * FROM mysql_cdc_orders;随着MatrixOne 1.0正式版发版脚步渐近,越来越多的小伙伴开始在更多的业务中测试和使用MatrixOne,也为社区提出了非常多的宝贵建议。MatrixOne社区将响应社区开发者的呼声,持续适配主流的生态组件,不断提升产品的易用性和友好性。欢迎大家反馈在使用过程中发现的兼容性问题,您的每一个issue我们都无比珍视,社区开发者将会第一时间进行排期修复。
MatrixOne社区介绍
MatrixOne是一款面向未来的超融合异构云原生数据库管理系统。通过全新设计和研发的统一分布式数据库引擎,能够同时灵活支持OLTP、OLAP、 Streaming等不同工作负载的数据管理和应用,用户可以在公有云、自建数据中心和边缘节点上无缝部署和运行。
MatrixOrigin 官网:新一代超融合异构开源数据库-矩阵起源(深圳)信息科技有限公司 MatrixOne
Github 仓库:GitHub - matrixorigin/matrixone: Hyperconverged cloud-edge native database