vite分享ppt,感兴趣的可以下载:
Vite分享、原理介绍ppt
什么是vite系列目录:
(一)什么是Vite——vite介绍与使用-CSDN博客
(二)什么是Vite——Vite 和 Webpack 区别(冷启动)-CSDN博客
(三)什么是Vite——Vite 主体流程(运行npm run dev后发生了什么?)-CSDN博客
(四)什么是Vite——冷启动时vite做了什么(源码、middlewares)-CSDN博客
(五)什么是Vite——冷启动时vite做了什么(依赖、预构建)-CSDN博客
未完待续。。。
Vite 和 Webpack 区别
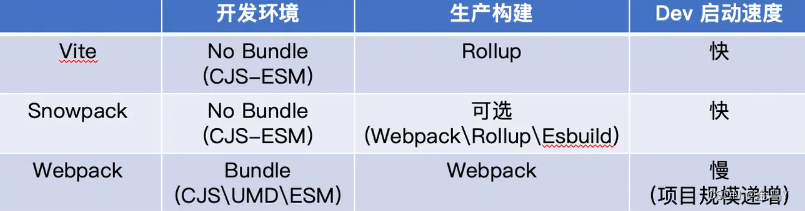
Webpack是近年来使用量最大,同时社区最完善的前端打包构建工具,新出的5.x版本对构建细节进行了优化,在部分场景下打包速度提升明显。Webpack在启动时,会先构建项目模块的依赖图,如果在项目中的某个地方改动了代码,Webpack则会对相关的依赖重新打包,随着项目的增大,其打包速度也会下降。
Vite相比于Webpack而言,没有打包的过程,而是直接启动了一个开发服务器devServer。Vite劫持浏览器的HTTP请求,在后端进行相应的处理将项目中使用的文件通过简单的分解与整合,然后再返回给浏览器(整个过程没有对文件进行打包编译)。所以编译速度很快。
Snowpack 首次提出利用浏览器原生ESM能力的打包工具,其理念就是减少或避免整个bundle的打包。默认在 dev 和 production 环境都使用 unbundle 的方式来部署应用。但是它的构建时却是交给用户自己选择,整体的打包体验显得有点支离破碎。
而 Vite 直接整合了 Rollup,为用户提供了完善、开箱即用的解决方案,并且由于这些集成,也方便扩展更多的高级功能。
两者较大的区别是在需要bundle打包的时候Vite 使用 Rollup 内置配置,而 Snowpack 通过其他插件将其委托给 Parcel/``webpack。
什么是 Webpack:
webpack是能把我们的开发文件打包成一个静态模块的工具,它将所有的模块打包成一个函数,并且会自动处理各种js模块之间的依赖关系,使用webpack打包项目,文件中必存在一个打包后的发布文件夹 dist ,和一个开发文件夹 src 。当 webpack 处理应用程序时,它会根据 命令行参数中 或 配置文件中 定义的模块列表开始处理。 从 入口 开始,webpack 会递归的构建一个 依赖关系图,这个依赖图包含着应用程序中所需的每个模块,然后将所有模块打包为少量的 bundle ( 通常只有一个)(可由浏览器加载)。
webpack核心思想
Webpack 最核心的功能:Webpack 核心原理
At its core, webpack is a static module bundler for modern JavaScript applications.
也就是将各种类型的资源,包括图片、css、js等,转译、组合、拼接、生成 JS 格式的 bundler 文件。官网首页 的动画很形象地表达了这一点:
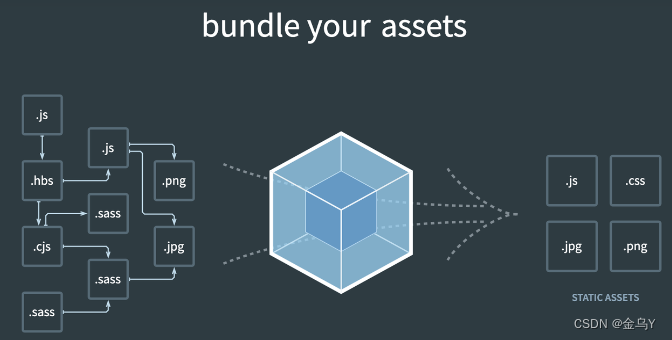
这个过程核心,完成了 内容转换 + 资源合并 两种功能,实现上包含以下三个阶段:
- 初始化阶段:
- 初始化参数:从配置文件、 配置对象、Shell 参数中读取,与默认配置结合得出最终的参数
- 创建编译器对象:用上一步得到的参数创建 Compiler 对象
- 初始化编译环境:包括注入内置插件、注册各种模块工厂、初始化 RuleSet 集合、加载配置的插件等
- 开始编译:执行 compiler 对象的 run 方法
- 确定入口:根据配置中的 entry 找出所有的入口文件,调用 compilition.addEntry 将入口文件转换为 dependence 对象
- 构建阶段:
- 编译模块(make):根据 entry 对应的 dependence 创建 module 对象,调用 loader 将模块转译为标准 JS 内容,调用 JS 解释器将内容转换为 AST 对象,从中找出该模块依赖的模块,再 递归 本步骤直到所有入口依赖的文件都经过了本步骤的处理
- 完成模块编译:上一步递归处理所有能触达到的模块后,得到了每个模块被翻译后的内容以及它们之间的 依赖关系图
- 生成阶段:
- 输出资源(seal):根据入口和模块之间的依赖关系,组装成一个个包含多个模块的 Chunk,再把每个 Chunk 转换成一个单独的文件加入到输出列表,这步是可以修改输出内容的最后机会
- 写入文件系统(emitAssets):在确定好输出内容后,根据配置确定输出的路径和文件名,把文件内容写入到文件系统
技术名词介绍:
- Entry:编译入口,webpack 编译的起点
- Compiler:编译管理器,webpack 启动后会创建 compiler 对象,该对象一直存活知道结束退出
- Compilation:单次编辑过程的管理器,比如 watch = true 时,运行过程中只有一个 compiler 但每次文件变更触发重新编译时,都会创建一个新的 compilation 对象
- Dependence:依赖对象,webpack 基于该类型记录模块间依赖关系
- Module:webpack 内部所有资源都会以“module”对象形式存在,所有关于资源的操作、转译、合并都是以 “module” 为基本单位进行的
- Chunk:编译完成准备输出时,webpack 会将 module 按特定的规则组织成一个一个的 chunk,这些 chunk 某种程度上跟最终输出一一对应
- Loader:资源内容转换器,其实就是实现从内容 A 转换 B 的转换器
- Plugin:webpack构建过程中,会在特定的时机广播对应的事件,插件监听这些事件,在特定时间点介入编译过程
Webpack 知识图谱分享: Webpack 知识图谱 和 Webpack 5 知识体系

冷启动时webpack做了什么:#
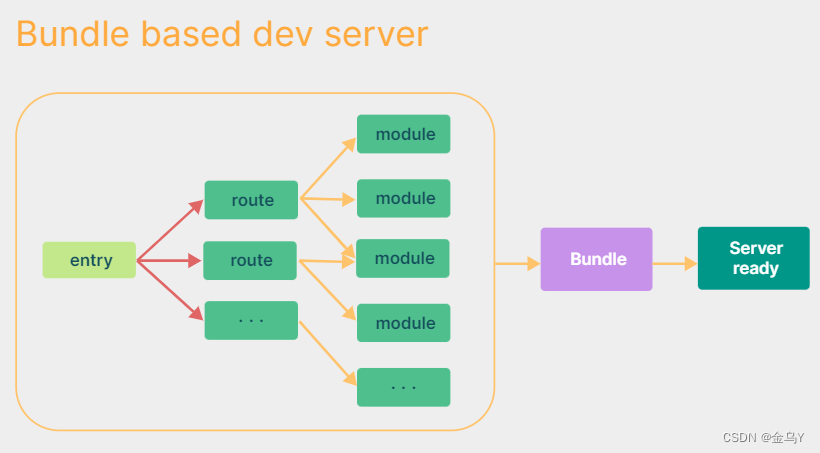
在 Vite出来之前,传统的打包工具如 Webpack 在服务器启动之前,需要从入口文件完整解析构建整个应用:先解析依赖、打包构建再启动开发服务器,Dev Server 必须等待所有模块构建完成,当我们修改了 bundle 模块中的一个子模块, 整个 bundle 文件都会重新打包然后输出。项目应用越大,启动时间越长。因此,有大量的时间都花在了依赖生成,构建编译上。
打包过程如下:
- 通过配置文件,找到入口entry;
- 从入口文件开始递归识别模块依赖,也就是遇到类似于require、import时,webpack都会对其分析,从而拿到对应的代码依赖;
- 对拿到的代码进行分析、转换、编译,最后输出浏览器可以识别的代码。整个过程大概如下图(来自vite官网):
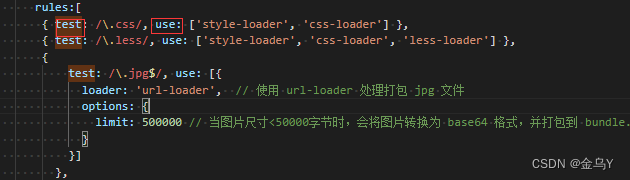
webpack作为代码编译工具,有入口、出口、loader、和插件plugin:
入口起点(entry point)指示 webpack 应该使用哪个模块,来作为构建其内部依赖图的开始。进入入口起点后,webpack 会找出有哪些模块和库是入口起点(直接和间接)依赖的。
output 属性告诉 webpack 在哪里输出它所创建的 bundles,以及如何命名这些文件,默认值为 ./dist。基本上,整个应用程序结构,都会被编译到你指定的输出路径的文件夹中。可以通过在配置中指定一个 output 字段,来配置这些处理过程。
loader 让 webpack 能够去处理那些非 JavaScript 文件(webpack 自身只理解 JavaScript)。loader 可以将所有类型的文件转换为 webpack 能够处理的有效模块,然后你就可以利用 webpack 的打包能力,对它们进行处理。
插件 plugin 是 webpack 的支柱功能。Webpack 自身也是构建于在 webpack 配置中用到的相同的插件系统之上。插件目的在于解决 loader 无法实现的其他事。Webpack 提供很多开箱即用的 插件。

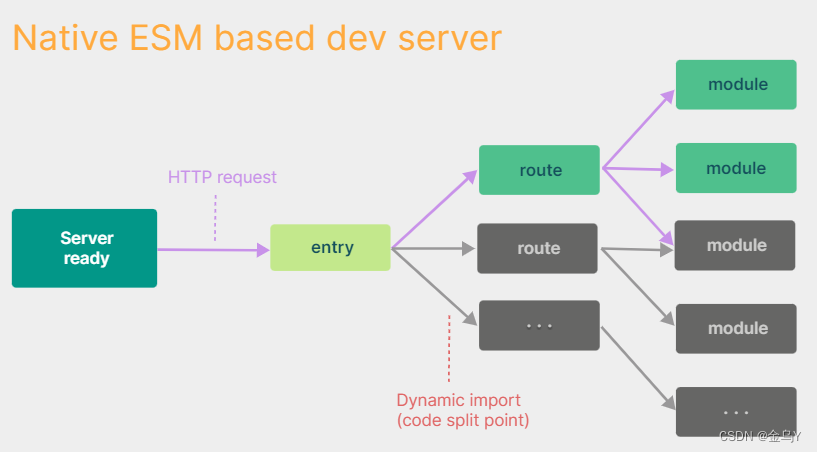
冷启动时vite做了什么
Vite利用浏览器对 ESM的支持,当 import 模块时,浏览器就会下载被导入的模块。先启动开发服务器,当代码执行到模块加载时再请求对应模块的文件,本质上实现了动态加载。灰色部分是暂时没有用到的路由,所有这部分不会参与构建过程。随着项目里的应用越来越多,增加 route,也不会影响其构建速度。
vite serve 开启一个用于开发的Web服务器,启动时 Web 服务器时不需要编译所有的代码文件,启动速度非常快,不需要打包,直接开启web服务器。
Vite利用现代浏览器支持 ES Modules 的模块化的特性,省略了打包,对需要编译的组件,例如单文件组件,Vite采用了另一种模式,即时编译,请求某个文件的时候才会编译某个文件,及时编译的好处:按需编译,速度会很快。

对比 vue-cli-service-serve Webpack打包所有模块-bundle内存-打开web服务器 提前编译,打包到bundle里面,文件越多越慢。
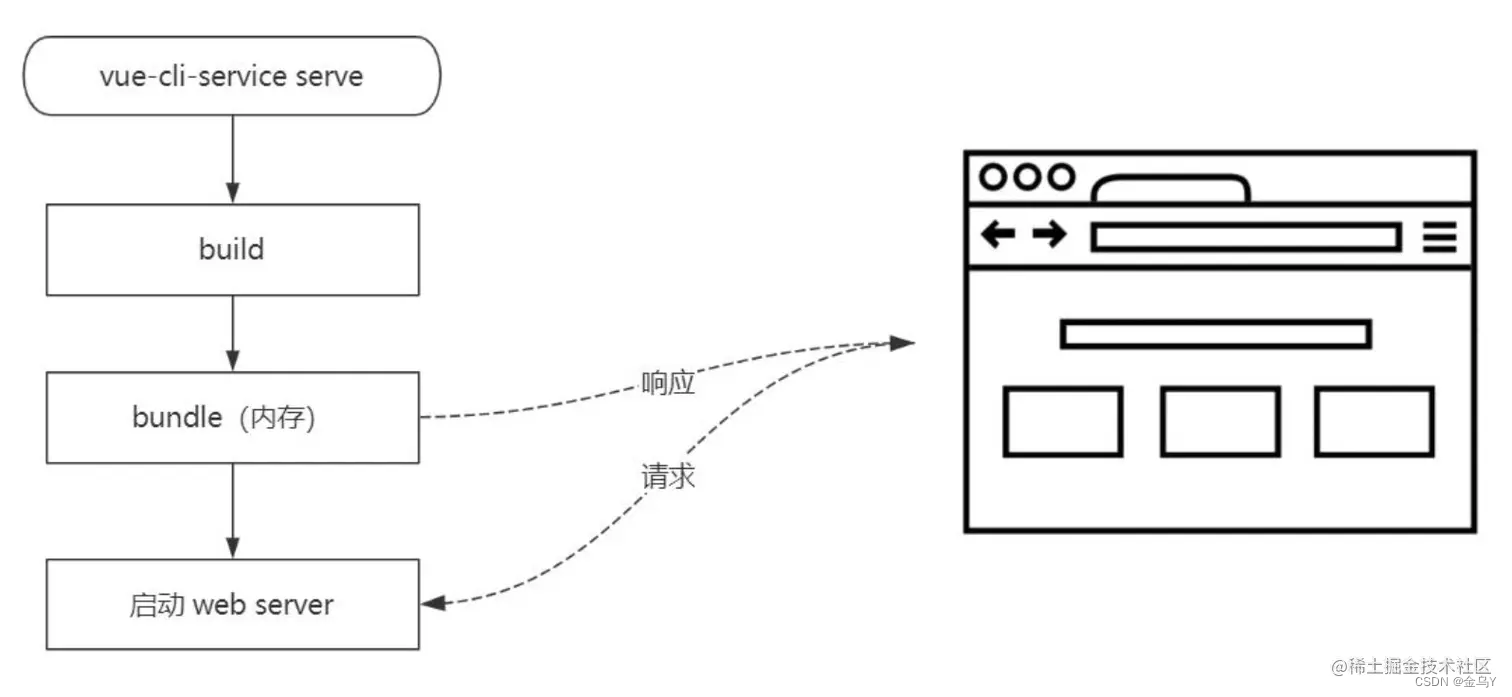
vite build 省略了对模块的打包,使用即时编译,按需编译速度更快。
小结:
| Webpack | Vite |
| 先打包生成bundle,再启动开发服务器 | 先启动开发服务器,利用新一代浏览器的ESM能力,无需打包,直接请求所需模块并实时编译 |
| HMR时需要把改动模块及相关依赖全部编译 | HMR时只需让浏览器重新请求该模块,同时利用浏览器的缓存(源码模块协商缓存,依赖模块强缓存)来优化请求 |
| 内存高效利用 | - |
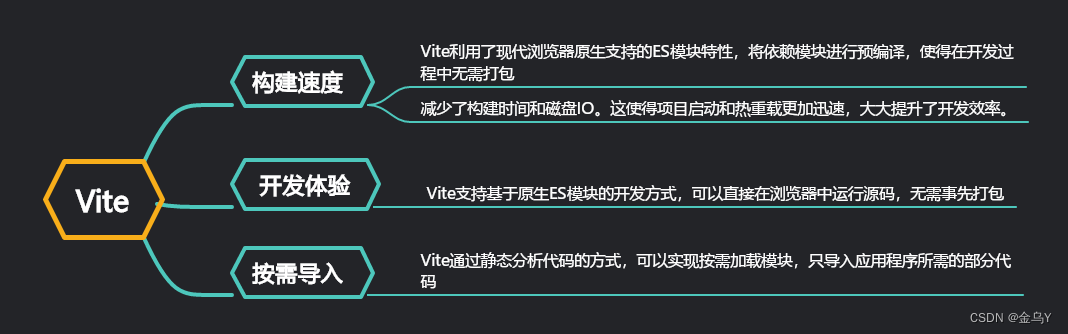
vite 的特性
- 去掉打包步骤
打包是开发者利用打包工具将应用各个模块集合在一起形成 bundle,以一定规则读取模块的代码,以便在不支持模块化的浏览器里使用,并且可以减少 http 请求的数量。但其实在本地开发过程中打包反而增加了我们排查问题的难度,增加了响应时长,Vite 在本地开发命令中去除了打包步骤,从而缩短构建时长。
- 按需加载
为了减少 bundle 大小,一般会想要按需加载,主要有两种方式:
- 使用动态引入 import() 的方式异步的加载模块,被引入模块依然需要提前编译打包;
- 使用 tree shaking 等方式尽力的去掉未引用的模块;(TreeShaking)
而 Vite 的方式更为直接,它只在某个模块被 import 的时候动态的加载它,实现了真正的按需加载,减少了加载文件的体积,缩短了时长;


![[云原生2.] Kurbernetes资源管理 ---- (陈述式资源管理方式)](https://img-blog.csdnimg.cn/598038617e5c42e9ad263920e52ceebc.png)



![[nlp] 损失缩放(Loss Scaling)loss sacle](https://img-blog.csdnimg.cn/7a1a6f1924374a3eb4c0b1ce649bab0b.png)