✅作者简介:大家好,我是Leo,热爱Java后端开发者,一个想要与大家共同进步的男人😉😉
🍎个人主页:Leo的博客
💞当前专栏: Netty实战专栏
✨特色专栏: MySQL学习
🥭本文内容: Netty实战专栏 | NIO详解
🖥️个人小站 :个人博客,欢迎大家访问
📚个人知识库: Leo知识库,欢迎大家访问
✨✨ 粉丝福利订阅✨✨
Leo哥收集了一些关于面试以及其他学习资源,这里分享给大家,各位卷王快收下吧!!!

目录
- 1.前言
- 2.为什么会有NIO
- 2.1概念解释:
- 2.2IO模型的局限性
- 2.3NIO模型优势
- 3.NIO的由来
- 4.NIO和传统的IO有什么区别呢?
- 5.解读NIO
- 5.1流与块
- 5.2NIO的工作方式
- 5.3NIO的核心实现
- 5.4通道与缓冲区
- 1. 通道(Channel)
- FileChannel类
- SocketChannel类
- ServerSocketChannel类
- 2. 缓冲区(Buffer)
- 缓冲区数据类型
- 缓冲区核心方法
- 3.Selector(选择器)
- 5.5缓冲区的数据存取
- 1.缓冲区的类型
- 2.缓冲区存取数据的两个核心方法
- 3.缓冲区中的四个核心属性
- 6.NIO示例
- 7.参考文献
- 8.总结
学习参考 :
- 讲师:孙帅老师
- 课程:孙哥说netty
1.前言
大家好,我是Leo哥🫣🫣🫣,上一篇博客我们主要大致了解了一下Java中IO的演变历程,大体分为基础IO–>BIO–>NIO–>AIO这几个阶段,分部逐层递进。下面几个章节我们就要来聊聊这个变化。本节主要讨论关于NIO的知识。好了,话不多说让我们开始吧😎😎😎。
2.为什么会有NIO
NIO是为了弥补IO操作的不足而诞生的,NIO的一些新特性有:非阻塞I/O,选择器,缓冲以及管道。管道(Channel),缓冲(Buffer) ,选择器( Selector) 是其主要特征。
2.1概念解释:
Channel——管道实际上就像传统IO中的流,到任何目的地(或来自任何地方)的所有数据都必须通过一个 Channel 对象。一个 Buffer 实质上是一个容器对象。
Selector——选择器用于监听多个管道的事件,使用传统的阻塞IO时我们可以方便的知道什么时候可以进行读写,而使用非阻塞通道,我们需要一些方法来知道什么时候通道准备好了,选择器正是为这个需要而诞生的。
在Java编程中,IO和NIO是两种不同的输入/输出处理模型。IO,也被称为传统IO或者阻塞IO,而NIO则代表了新的输入/输出,也被称为非阻塞IO。尽管IO模型被广泛使用,但是由于其一些局限性,NIO应运而生,提供了更高的并发处理能力和更好的网络数据传输效率。
2.2IO模型的局限性
阻塞IO: 在传统IO模型中,当一个线程发起一个读或写请求时,它必须等待这个操作完成才能继续进行下一步。这种等待数据准备的过程是阻塞的,会导致CPU资源的浪费。
缺乏并发处理能力: 由于阻塞IO模型在数据处理过程中线程被阻塞,导致其无法同时处理多个客户端连接,极大地限制了系统的并发处理能力。
2.3NIO模型优势
非阻塞IO: NIO提供了非阻塞模式的网络IO操作。当线程发起一个读或写请求,它可以在等待数据准备的过程中执行其他任务,从而提高了线程的工作效率。
更高的并发处理能力: 利用NIO的选择器(Selector)机制,可以用一个线程处理多个客户端的连接请求,大大提高了系统的并发处理能力。
直接内存访问: NIO还提供了直接内存访问的能力,可以将数据直接写入到内存中,从而减少了在内核和用户空间之间复制数据的开销。
零拷贝: NIO引入了文件通道的概念,可以实现数据的零拷贝传输,进一步提高了数据传输的效率。
尽管NIO有许多优点,但并不是在所有场景下都适合使用。如果对并发处理能力要求不高,或者是数据量较小的场景,使用传统的IO模型可能会更加简单直接。
3.NIO的由来
NIO (New lO)也有人称之为java non-blocking lO是从Java 1.4版本开始引入的一个新的IO API,可以替代标准的Java lO API。NIO与原来的IO有同样的作用和目的,但是使用的方式完全不同,NIO支持面向缓冲区的、基于通道的IO操作。NIO将以更加高效的方式进行文件的读写操作。NIO可以理解为非阻塞IO,传统的IO的read和write只能阻塞执行,线程在读写IO期间不能干其他事情,比如调用socket.read()时,如果服务器一直没有数据传输过来,线程就一直阻塞,而NIO中可以配置socket为非阻塞模式。
- NIO相关类都被放在java.nio包及子包下,并且对原java.io包中的很多类进行改写。
- NIO有三大核心部分:Channel(通道),Buffer(缓冲区), Selector(选择器)
- Java NlO的非阻塞模式,使一个线程从某通道发送请求或者读取数据,但是它仅能得到目前可用的数据,如果目前没有数据可用时,就什么都不会获取,而不是保持线程阻塞,所以直至数据变的可以读取之前,该线程可以继续做其他的事情。非阻塞写也是如此,一个线程请求写入一些数据到某通道,但不需要等待它完全写入,这个线程同时可以去做别的事情。
- 通俗理解:NIO是可以做到用一个线程来处理多个操作的。假设有1000个请求过来,根据实际情况,可以分配20或者80个线程来处理。不像之前的阻塞IO那样,非得分配1000个。
4.NIO和传统的IO有什么区别呢?
| NIO | IO |
|---|---|
| 面向缓冲 | 面向流 |
| 同步非阻塞 | 同步阻塞 |
| 选择器(多路复用) | 无 |
- 传统 IO 流
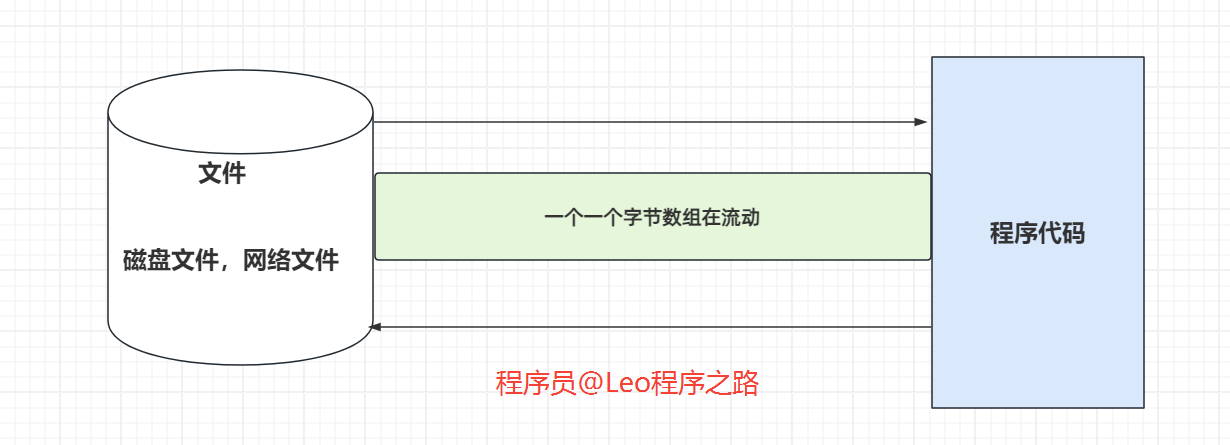
对上图说明一下:
- 我们需要把磁盘文件或者网络文件中的数据读取到程序中来,我们需要建立一个用于传输数据的管道,原来我们传输数据面对的直接就是管道里面一个个字节数据的流动(我们弄了一个 byte 数组,来回进行数据传递),所以说原来的 IO 它面对的就是管道里面的一个数据流动,所以我们说原来的 IO 是面向流的
- 我们说传统的 IO 还有一个特点就是,它是单向的。解释一下就是:如果说我们想把目标地点的数据读取到程序中来,我们需要建立一个管道,这个管道我们称为输入流。相应的,如果如果我们程序中有数据想要写到目标地点去,我们也得再建立一个管道,这个管道我们称为输出流。所以我们说传统的 IO 流是单向的
- NIO
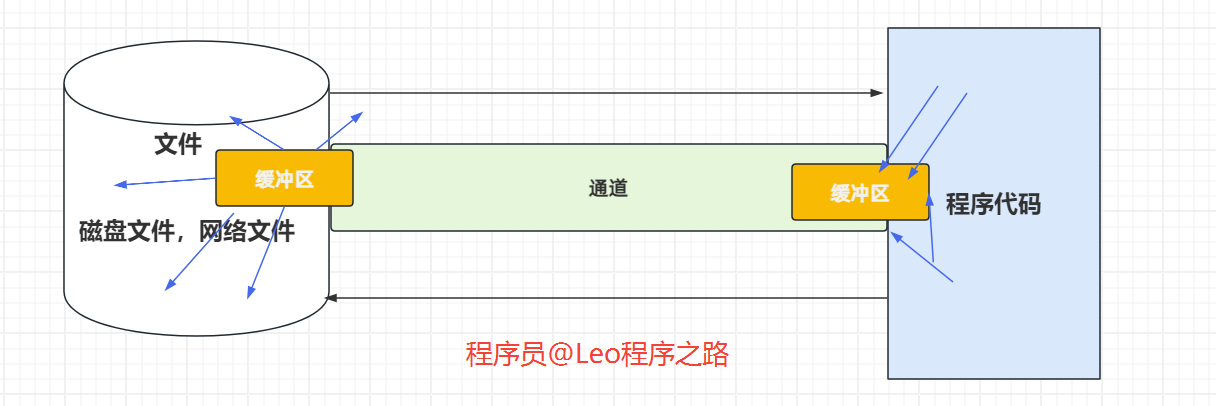
解释一下上图:
- 我们说只要是 IO ,那么就是为了完成数据传输的。
- 即便你用 NIO ,它也是为了数据传输,所以你要想完成数据传输,你也得建立一个用于传输数据的通道,这个通道你不能把它理解为之前的水流了,但是你可以把它理解为铁路,铁路本身是不能完成运输的,铁路要想完成运输它必须依赖火车,说白了这个通道就是为了连接目标地点和源地点。所以注意通道本身不能传输数据,要想传输数据必须要有缓冲区,这个缓冲区你就可以完全把它理解为火车,比如说你现在想把程序中的数据写到文件中,那么你就可以把数据都写到缓冲区,然后缓冲区通过通道进行传输,最后再把数据从缓冲区拿出来写到文件中,你想把文件中的数据传数到程序中,也是一个道理,把数据写到缓冲区,缓冲区通过通道进行传输,到程序中把数据拿出来。所以我们说原来的 IO 单向的现在的缓冲区是双向的,这种传输数据的方式也叫面向缓冲区。总结一下,就是通道只负责连接,缓冲区才负责存储数据。
- IO是面向流的,NIO是面向块(缓冲区)的。
IO面向流的操作一次一个字节地处理数据。一个输入流产生一个字节的数据,一个输出流消费一个字节的数据。,导致了数据的读取和写入效率不佳;
NIO面向块的操作在一步中产生或者消费一个数据块。按块处理数据比按(流式的)字节处理数据要快得多,同时数据读取到一个它稍后处理的缓冲区,需要时可在缓冲区中前后移动。这就增加了处理过程中的灵活性。通俗来说,NIO采取了“预读”的方式,当你读取某一部分数据时,他就会猜测你下一步可能会读取的数据而预先缓冲下来。
2.IO是阻塞的,NIO是非阻塞的。
对于传统的IO,当一个线程调用read()或write()时,该线程被阻塞,直到有一些数据被读取,或数据完全写入。该线程在此期间不能再干任何事情了。
而对于NIO,使用一个线程发送读取数据请求,没有得到响应之前,线程是空闲的,此时线程可以去执行别的任务,而不是像IO中那样只能等待响应完成。
3.NIO和IO适用场景
NIO是为弥补传统IO的不足而诞生的,但是尺有所短寸有所长 ,NIO也有缺点,因为NIO是面向缓冲区的操作,每一次的数据处理都是对缓冲区进行的,那么就会有一个问题,在数据处理之前必须要判断缓冲区的数据是否完整或者已经读取完毕,如果没有,假设数据只读取了一部分,那么对不完整的数据处理没有任何意义。所以每次数据处理之前都要检测缓冲区数据。
5.解读NIO
5.1流与块
I/O 与 NIO 最重要的区别是数据打包和传输的方式,I/O 以流的方式处理数据,而 NIO 以块的方式处理数据。
面向流的 I/O 一次处理一个字节数据: 一个输入流产生一个字节数据,一个输出流消费一个字节数据。为流式数据创建过滤器非常容易,链接几个过滤器,以便每个过滤器只负责复杂处理机制的一部分。不利的一面是,面向流的 I/O 通常相当慢。
面向块的 I/O 一次处理一个数据块,按块处理数据比按流处理数据要快得多。但是面向块的 I/O 缺少一些面向流的 I/O 所具有的优雅性和简单性。
I/O 包和 NIO 已经很好地集成了,java.io.* 已经以 NIO 为基础重新实现了,所以现在它可以利用 NIO 的一些特性。例如,java.io.* 包中的一些类包含以块的形式读写数据的方法,这使得即使在面向流的系统中,处理速度也会更快
5.2NIO的工作方式
在上一节中,我们学习了关于BIO是如何运作的,今天我们来简单复习一下。
Java BIO:服务器实现模式为一个连接一个线程,即客户端有连接请求时服务器端就需要启动一个线程进行处理,如下图所示:
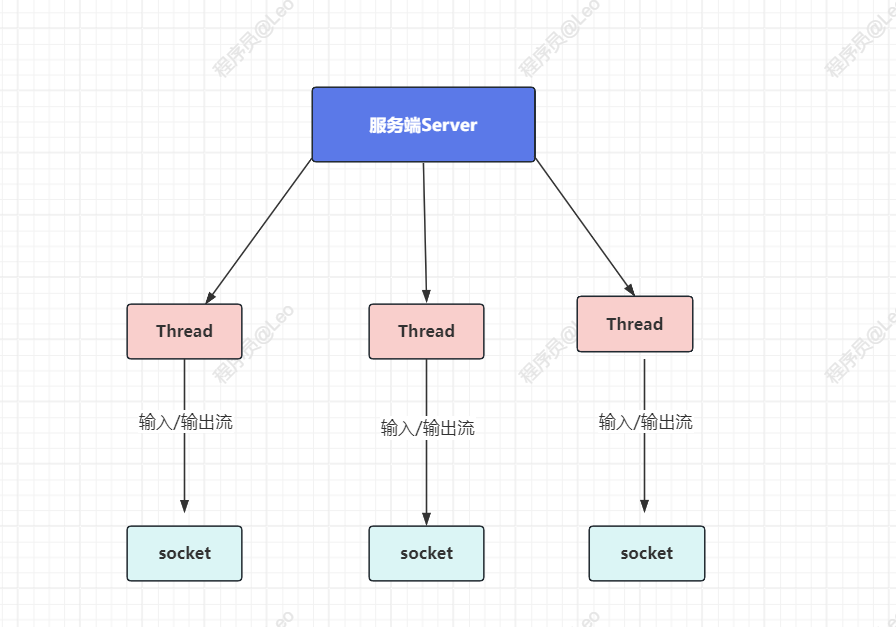
我们再来看NIO,
Java NIO: 同步非阻塞,服务器实现模式为一个线程处理多个请求(连接),即客户端发送的连接请求都会注册到多路复用器上,多路复用器轮询到连接有I/O请求就进行处理。
一个线程中就可以调用多路复用接口(java中是select)阻塞同时监听来自多个客户端的IO请求,一旦有收到IO请求就调用对应函数处理,NIO擅长1个线程管理多条连接,节约系统资源。
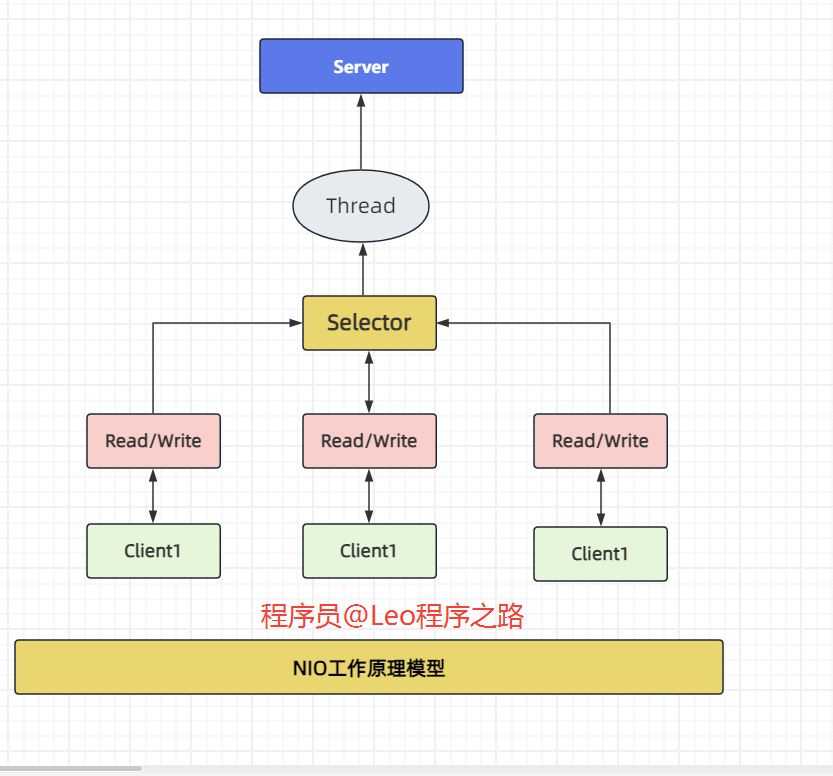
5.3NIO的核心实现
NIO 包含3个核心的组件:
- Channel(通道)
- Buffer(缓冲区)
- Selector(选择器)

关系图的说明:
- 每个 Channel 对应一个 Buffer。
- Selector 对应一个线程,一个线程对应多个 Channel。
- 该图反应了有三个 Channel 注册到该 Selector。
- 程序切换到那个 Channel 是由事件决定的(Event)。
- Selector 会根据不同的事件,在各个通道上切换。
- Buffer 就是一个内存块,底层是有一个数组。
- 数据的读取和写入是通过 Buffer,但是需要flip()切换读写模式,而 BIO 是单向的,要么输入流要么输出流。
5.4通道与缓冲区
1. 通道(Channel)
通道 Channel 是对原 I/O 包中的流的模拟,可以通过它读取和写入数据。
通道与流的不同之处在于,流只能在一个方向上移动(一个流必须是 InputStream 或者 OutputStream 的子类),而通道是双向的,可以用于读、写或者同时用于读写。
通道的主要实现类:
FileChannel类
本地文件IO通道,用于读取、写入、映射和操作文件的通道,使用文件通道操作文件的一般流程为:
1)获取通道
文件通道通过 FileChannel 的静态方法 open() 来获取,获取时需要指定文件路径和文件打开方式。
// 获取文件通道FileChannel.open(Paths.get(fileName), StandardOpenOption.READ);
2)创建字节缓冲区
文件相关的字节缓冲区有两种,一种是基于堆的 HeapByteBuffer,另一种是基于文件映射,放在堆外内存中的 MappedByteBuffer。
// 分配字节缓存ByteBuffer buf = ByteBuffer.allocate(10);
3)读写操作
读取数据
一般需要一个循环结构来读取数据,读取数据时需要注意切换 ByteBuffer 的读写模式。
while (channel.read(buf) != -1){ // 读取通道中的数据,并写入到 buf 中 buf.flip(); // 缓存区切换到读模式 while (buf.position() < buf.limit()){ // 读取 buf 中的数据 text.append((char)buf.get()); } buf.clear(); // 清空 buffer,缓存区切换到写模式}
写入数据
for (int i = 0; i < text.length(); i++) { buf.put((byte)text.charAt(i)); // 填充缓冲区,需要将 2 字节的 char 强转为 1 自己的 byte if (buf.position() == buf.limit() || i == text.length() - 1) { // 缓存区已满或者已经遍历到最后一个字符 buf.flip(); // 将缓冲区由写模式置为读模式 channel.write(buf); // 将缓冲区的数据写到通道 buf.clear(); // 清空缓存区,将缓冲区置为写模式,下次才能使用 }}
4)将数据刷出到物理磁盘,FileChannel 的 force(boolean metaData) 方法可以确保对文件的操作能够更新到磁盘。
channel.force(false);
5)关闭通道
channel.close();
SocketChannel类
网络套接字IO通道,TCP协议,针对面向流的连接套接字的可选择通道(一般用在客户端)。
TCP 客户端使用 SocketChannel 与服务端进行交互的流程为:
1)打开通道,连接到服务端。
SocketChannel channel = SocketChannel.open(); // 打开通道,此时还没有打开 TCP 连接channel.connect(new InetSocketAddress("localhost", 9090)); // 连接到服务端
2)分配缓冲区
ByteBuffer buf = ByteBuffer.allocate(10); // 分配一个 10 字节的缓冲区,不实用,容量太小
3)配置是否为阻塞方式。(默认为阻塞方式)
channel.configureBlocking(false); // 配置通道为非阻塞模式
4)与服务端进行数据交互
5)关闭连接
channel.close(); // 关闭通道
ServerSocketChannel类
网络通信IO操作,TCP协议,针对面向流的监听套接字的可选择通道(一般用于服务端),流程如下:
1)打开一个 ServerSocketChannel 通道, 绑定端口。
ServerSocketChannel server = ServerSocketChannel.open(); // 打开通道
2)绑定端口
server.bind(new InetSocketAddress(9090)); // 绑定端口
3)阻塞等待连接到来,有新连接时会创建一个 SocketChannel 通道,服务端可以通过这个通道与连接过来的客户端进行通信。等待连接到来的代码一般放在一个循环结构中。
SocketChannel client = server.accept(); // 阻塞,直到有连接过来
4)通过 SocketChannel 与客户端进行数据交互
5)关闭 SocketChannel
client.close();
2. 缓冲区(Buffer)
发送给一个通道的所有数据都必须首先放到缓冲区中,同样地,从通道中读取的任何数据都要先读到缓冲区中。也就是说,不会直接对通道进行读写数据,而是要先经过缓冲区。
缓冲区实质上是一个数组,但它不仅仅是一个数组。缓冲区提供了对数据的结构化访问,而且还可以跟踪系统的读/写进程。
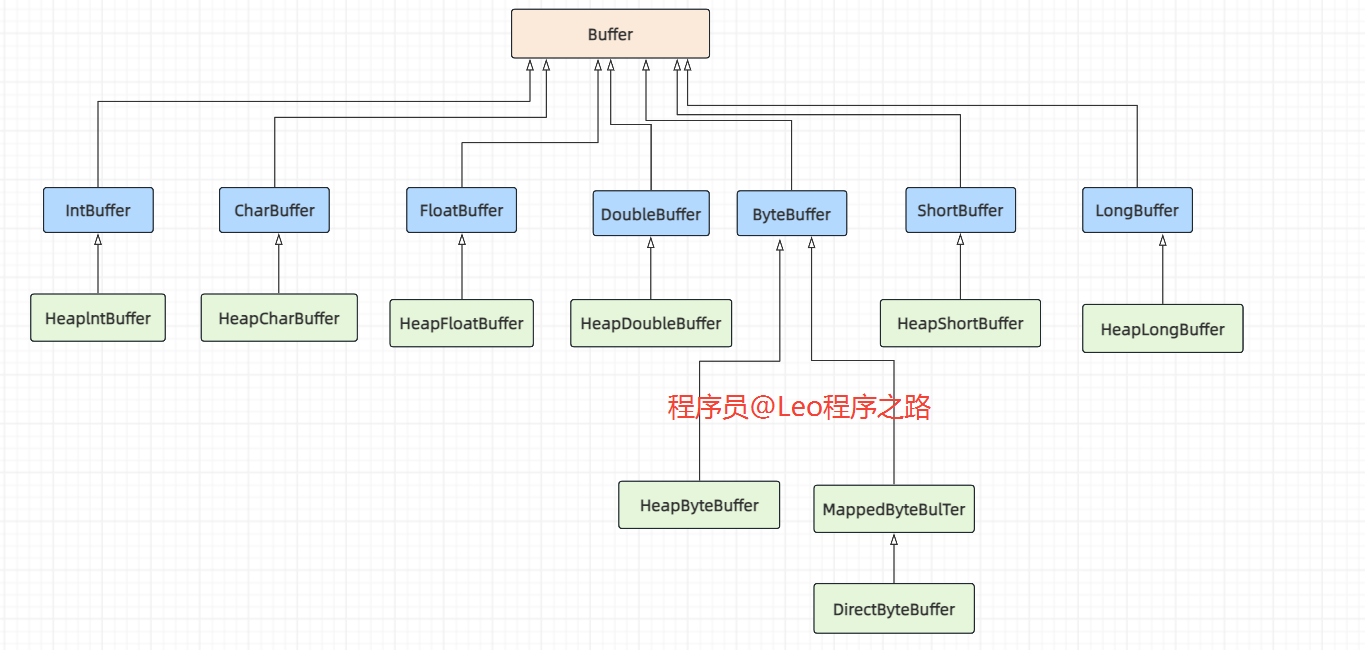
缓冲区数据类型
缓冲区核心方法
缓冲区存取数据的两个核心方法:
1)put():存入数据到缓冲区
- put(byte b):将给定单个字节写入缓冲区的当前位置
- put(byte[] src):将 src 中的字节写入缓冲区的当前位置
- put(int index, byte b):将指定字节写入缓冲区的索引位置(不会移动 position)
2)get():获取缓冲区的数据
- get() :读取单个字节
- get(byte[] dst):批量读取多个字节到 dst 中
- get(int index):读取指定索引位置的字节(不会移动 position)
3.Selector(选择器)
Selector类是NIO的核心类,Selector(选择器)选择器提供了选择已经就绪的任务的能力。
Selector会不断的轮询注册在上面的所有channel,如果某个channel为读写等事件做好准备,那么就处于就绪状态,通过Selector可以不断轮询发现出就绪的channel,进行后续的IO操作。
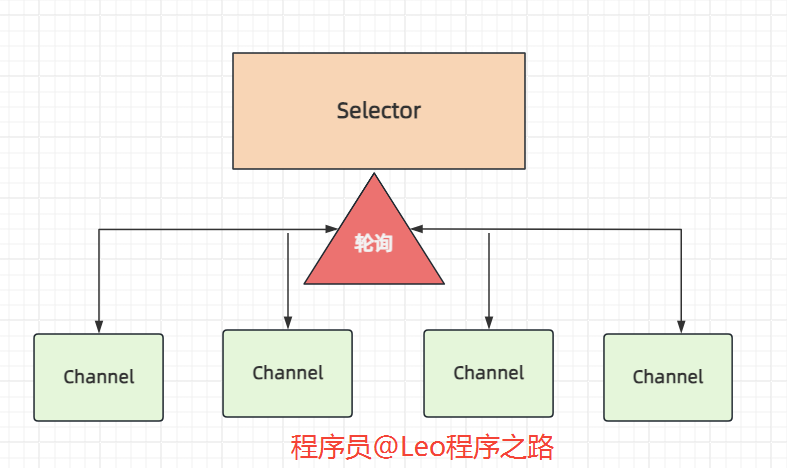
一个Selector能够同时轮询多个channel,这样,一个单独的线程就可以管理多个channel,从而管理多个网络连接,这样就不用为每一个连接都创建一个线程,同时也避免了多线程之间上下文切换导致的开销。
5.5缓冲区的数据存取
**缓冲区(Buffer):**一个用于特定基本数据类型的容器。由 java.nio 包定义的,所有缓冲区都是 Buffer 抽象类的子类。
1.缓冲区的类型
缓冲区(Buffer):在 Java NIO 中负责数据的存取。缓冲区就是数组。用于存储不同类型的数据。根据数据类型的不同(boolean 除外),提供了相应类型的缓冲区:
ByteBuffer
CharBuffer
ShortBuffer
IntBuffer
LongBuffer
FloatBuffer
DoubleBuffer
上述缓冲区管理方式几乎一致,都是通过 allocate() 来获取缓冲区
2.缓冲区存取数据的两个核心方法
put():存入数据到缓冲区中get():获取缓冲区中的数据
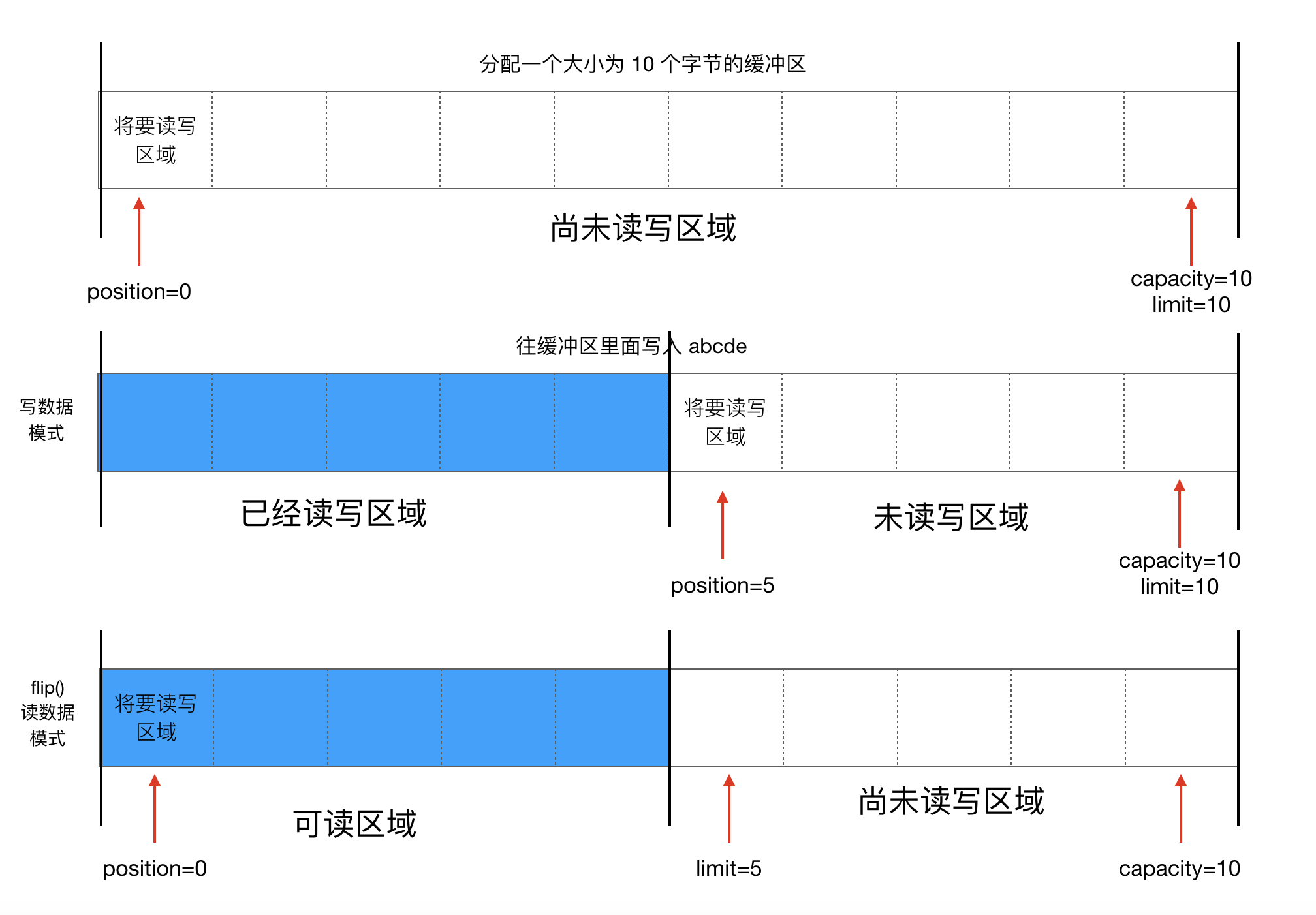
3.缓冲区中的四个核心属性
capacity: 容量,表示缓冲区中最大存储数据的容量。一旦声明不能更改。limit: 界限,表示缓冲区中可以操作数据的大小。(limit 后的数据不能进行读写)position: 位置,表示缓冲区中正在操作数据的位置。mark: 标记,表示记录当前 position 的位置。可以通过reset()恢复到mark的位置。
注:
0 <= mark <= position <= limit <= capacity
代码示例:

6.NIO示例
public static void fastCopy(String src, String dist) throws IOException {
/* 获得源文件的输入字节流 */
FileInputStream fin = new FileInputStream(src);
/* 获取输入字节流的文件通道 */
FileChannel fcin = fin.getChannel();
/* 获取目标文件的输出字节流 */
FileOutputStream fout = new FileOutputStream(dist);
/* 获取输出字节流的通道 */
FileChannel fcout = fout.getChannel();
/* 为缓冲区分配 1024 个字节 */
ByteBuffer buffer = ByteBuffer.allocateDirect(1024);
while (true) {
/* 从输入通道中读取数据到缓冲区中 */
int r = fcin.read(buffer);
/* read() 返回 -1 表示 EOF */
if (r == -1) {
break;
}
/* 切换读写 */
buffer.flip();
/* 把缓冲区的内容写入输出文件中 */
fcout.write(buffer);
/* 清空缓冲区 */
buffer.clear();
}
}
7.参考文献
- https://pdai.tech/md/java/io/java-io-nio.html#%e7%bc%93%e5%86%b2%e5%8c%ba%e7%8a%b6%e6%80%81%e5%8f%98%e9%87%8f
- https://blog.csdn.net/yewandemty/article/details/106824335
- https://www.jianshu.com/p/5442b04ccff8
8.总结
以上便是本文的全部内容,本人才疏学浅,文章有什么错误的地方,欢迎大佬们批评指正!我是Leo,一个在互联网行业的小白,立志成为更好的自己。
如果你想了解更多关于Leo,可以关注公众号-程序员Leo,后面文章会首先同步至公众号。


![[读论文]DiT Scalable Diffusion Models with Transformers](https://img-blog.csdnimg.cn/ddeca94c35dc4e979c3abe293e791dc3.png)




![[C++]:8.C++ STL引入+string(介绍)](https://img-blog.csdnimg.cn/b94bff53ffaa42a584f6e3c27aa22ea6.png)