特征预处理采用的是特定的统计方法(数学方法)将数据转化为算法要求的数字
1. 数值型数据
归一化,将原始数据变换到[0,1]之间
标准化,数据转化到均值为0,方差为1的范围内
缺失值,缺失值处理成均值、中位数等
2. 类别型数据
降维,多指标转化为少数几个综合指标,去掉关联性不大的指标
PCA,降维的一种
3. 时间类别
时间的切分
1. 归一化
归一化是在特征(维度)非常多的时候,可以防止某一维或某几维对数据影响过大,也是为了把不同来源的数据统一到一个参考区间下,这样比较起来才有意义。其次可以让程序更快地运行。
例如,一个人的身高和体重两个特征,假如体重50kg,身高175cm,由于两个单位不一样,数值大小不一样。如果比较两个人的体型差距时,那么身高的影响结果会比较大,因此在做计算之前需要先进行归一化操作。
归一化的公式为:
式中,max 和 min 分别代表某列中的最大值和最小值;x 为归一化之前的值;x'' 为归一化后的结果;mx 和 mi 为要归一化的区间,默认是 [0,1],即mx=1,mi=0
在 sklearn 中的实现,导入方法: from sklearn.preprocessing import MinMaxScaler
归一化方法: scaler.fit_transform()
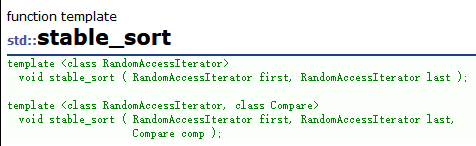
# 自定义数据
data = [[180,75,25],[175,80,19],[159,50,40],[160,60,32]]
# 导入归一化方法
from sklearn.preprocessing import MinMaxScaler
# 接收该方法
# scaler = MinMaxScaler(feature_range=(0,2)) #指定归一化区间
scaler = MinMaxScaler()
# 将数据传入归一化方法,产生返回值列表类型
result = scaler.fit_transform(data)
可以在归一化方法 MinMaxScaler() 中加入参数 feature_range=( , ) 来指定归一化范围,默认[0,1]。
归一化的优缺点:
归一化非常容易受到最大值和最小值的影响,因此,如果数据集中存在一些异常点,结果将发生很大改变,因此这种方法的鲁棒性(稳定性)很差。只适合数据量比较精确,比较小的情况。
2. 标准化
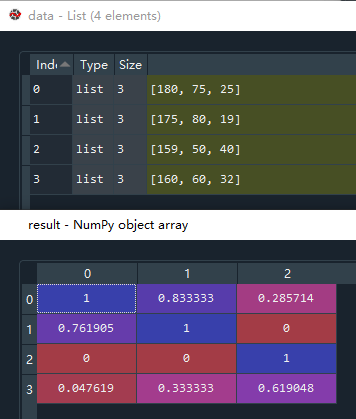
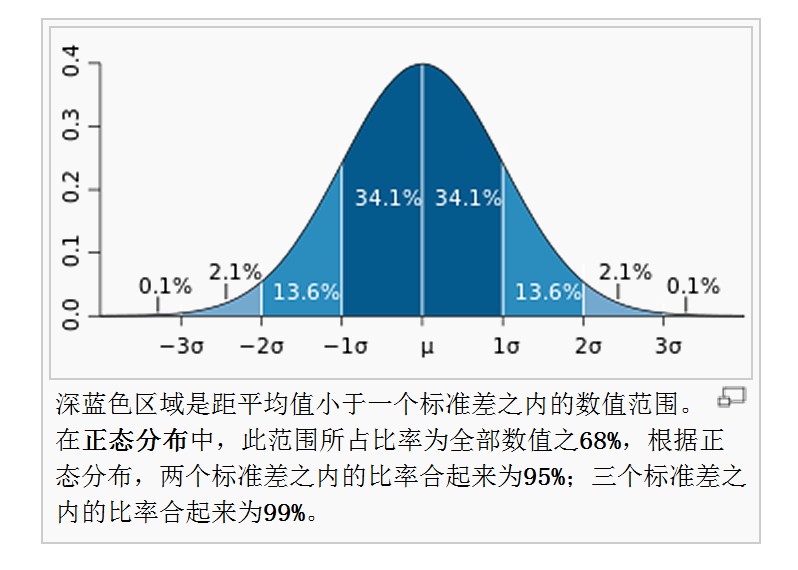
为了防止某一特征对结果影响太大,将每一个特征(每一列)都进行标准化处理,常用的方法是 z-score 标准化,处理后的数据均值为0,标准差为1,满足标准正态分布。标准正态分布图如下:
标准化公式:
其中, 是样本均值,
是样本标准差,它们可以通过现有的样本进行估计,在已有的样本足够多的情况下比较稳定,不受样本最大值和最小值的影响,适合嘈杂的数据场景。
标准差的求法是先求方差,方差 std 的求法如下,n为每个特征的样本数。
标准差为方差开根号
方差和标准差越趋近于0,则表示数据越集中;如果越大,表示数据越离散。
在 sklearn 中实现,导入方法: from sklearn.preprocessing import StandardScaler
标准化方法: scaler.fit_transform()
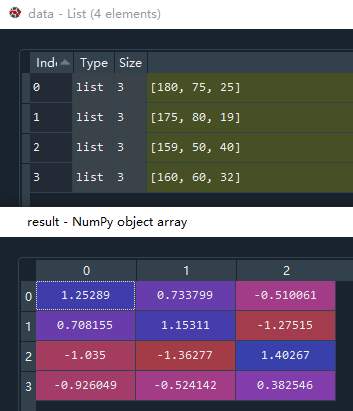
# 自定义数据
data = [[180,75,25],[175,80,19],[159,50,40],[160,60,32]]
# 导入标准化
from sklearn.preprocessing import StandardScaler
# 接收标准化
scaler = StandardScaler()
# 将数据传入标准化方法产生返回值是列表类型
result = scaler.fit_transform(data)
3. 缺失值处理
缺失值一般有两种处理方法,第一种是直接进行删除,第二种是进行替换。除非缺失值占总数据集的比例非常少,才推荐使用删除的方式,否则建议使用平均值、中位数的方式进行替换。
在sklearn中有专门的缺失值处理方式,from sklearn.impute import SimpleImputer
处理方法 SimpleImputer() 参数设置:
missing_values: 数据中的哪些值视为缺失值。默认missing_values=nan,把数据中的nan当作缺失值
strategy: 替换缺失值的策略,默认strategy='mean',使用平均值替换,可选'median'中位数,'most_frequent'众数,'constant'常数项。
注意:这里的均值众数等都是该缺失值所在特征列上的均值众数。
fill_value:只有当指定 strategy='constant' 时才使用,用于指定一个常数,默认fill_value=None
# 处理缺失值
# 自定义数据
import numpy as np
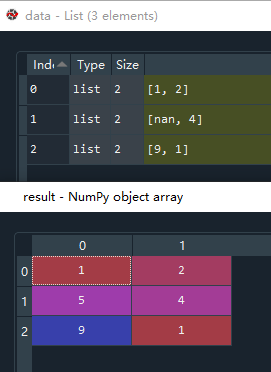
data = [[1,2],[np.nan,4],[9,1]]
# 导入缺失值处理方法
from sklearn.impute import SimpleImputer
# 接收方法
si = SimpleImputer()
# 传入原始数据
result = si.fit_transform(data)
使用默认值修改缺失值,用平均值替换nan