近期,科技产业大佬不约而同地发出一个非常强烈的信号:自动驾驶走向完全的成熟,必须要被AI大模型重构。
中国工程院院士、清华大学教授、清华智能产业研究院(AIR)院长张亚勤认为,「自动驾驶是高度复杂的、最具有挑战的AI垂直领域问题,自动驾驶将作为建立其上的垂直模型,最终以端到端的方式实现。」
毫末智行CEO顾维灏的观点是,「未来的自动驾驶系统一定跟人类驾驶员一样,不但具备对三维空间的精确感知测量能力,而且能够像人类一样理解万物之间的联系、事件发生的逻辑和背后的常识,并且能基于这些人类社会的经验来做出更好的驾驶策略。」
百度创始人李彦宏也表达过类似观点:「未来AI原生应用一定是多模态的,在信息世界之外,一定会重构物理世界。自动驾驶就是视觉大模型重构物理世界的一个典型应用。大模型会让自动驾驶能力超越经验系统。」
为什么自动驾驶需要被AI大模型重构?自动驾驶被AI大模型重构,该怎么做?这是本文想探讨的两个问题。
一、自动驾驶为什么要具有“世界知识”?
理解自动驾驶,就需要采用第一性原理,来还原人类驾驶的过程,从而理解智能的本质。
首先,让我们还原人类驾驶的过程。人类和所有动物一样,具有一套功能强大而敏锐灵活的感知觉系统。
人类视觉具有深度空间、颜色、纹理的感知能力,也具有理解速度、位移变化、距离的推断能力,也具有社会经验赋予的语义判断和逻辑推断的能力,当然不能忽略听觉的作用,听觉一定程度弥补视野盲区的感知信息,能根据声音大小、种类来判断距离和危险程度。
人类本身有非常灵活的四肢,可以在有限的地面空间自由移动。而车辆的出现则显著提高了人类移动的效率。随之而来的代价是,人类要通过一定程度的学习来掌握「 开车」这么新的行动技术。
人是如何学会开车的?
- 第一步,人们要掌握交通规则和驾驶经验。现代交通是由大量的符号和规则来构成的交通网络,从而可以保证高密度车辆的高效、安全的行驶,越是复杂的交通场景,尤其是人车混行的路口,相对于的规则也就越多。
- 第二步是掌握驾驶技巧,主要是掌握启停的手脚操作,泊车入位的操作,以及慢速情况下的绕行等。
- 第三步是实际的上路,通过切身经验来体会加减速度、跟车距离、变道时机,同时也实际理解从理论上学习到的驾驶知识和交通规则。
正常来说,一个普通人大概几个小时就可以掌握基本操作,几十个小时就可以在实际道路上比较熟练的行驶,吃上几次罚单就可以深刻理解交通法规的价值,然后用一年左右时间或一万公里左右就基本可以成为一名“老司机”。
自动驾驶想要真正达成在任何条件下无人驾驶的目标,就必须按照人类老司机的方式来处理驾驶任务。这也决定了自动驾驶“应该”和“不应该”的实现方法。
先说不应该。
- 第一,自动驾驶以不应该过度依赖激光雷达,视觉感知本身就可以带来最为丰富的驾驶场景,而配合少量的毫米波雷达或者最多一颗激光雷达就可以弥补超视距感知的不足。毕竟人类主要依靠视觉就可以完成驾驶,而多颗摄像头实现的环视效果就能极大提高感知效果。
- 第二,自动驾驶不应该以高精地图的方案来实现。高精地图带来了“先验”视角,让车辆有了对环境信息的提前的掌握,但高精地图显然也限制了自动驾驶的运行范围,提高了运行成本,在鲜度不足或者覆盖范围之外的地方会带来额外的风险。毕竟人类只要靠自己的感知的判断就可以完成驾驶,最多依赖导航地图能够更有效。
- 第三,自动驾驶不应该以AI小模型+人工规则的方式来实现。AI小模型是基于特定问题来执行任务的,比如有专门识别红绿灯、车道线的小任务模型,但是驾驶场景会遇到种类繁多的感知任务,不可能用小模型的方式去穷尽极端场景;同样,车辆行驶过程当中遇到的各类任务也不可能完全用人工规则写完,遭遇复杂的博弈场景,系统就很容易“摆烂”或者“失效”。
因此,自动驾驶“应该”的实现方式是下面这样的。
- 首先,感知模式应该是以视觉为主的多模态,感知能力应该是具备通用识别能力的,无论是对于形状各异、提示信息各异的红绿灯,还是对于道路上的各类指示牌、标线都有较好的泛化性;
- 其次,自动驾驶的局部路径规划应该是实时建图的方式,至少是多次重复建图的方式,来处理当前的路径规划任务,就像人类依靠重复记忆,在多次经过一段道路之后,就会对道路结构和转向连接路径有了内生的认知,从而可以摆脱导航地图的帮助。
- 另外,自动驾驶对自车和其他障碍物的预测以及规划,要依靠模型的自我学习的方式而非规则的方式,来理解交通场景中各类障碍物的特点和行动意图,从而更灵活地做出驾驶决策。比如,挡在闪灯鸣笛的救护车或者消防车前面,是否要主动靠边让行,遇到前方路口的交通事故,是否要压实线变道过去,遇到前面带着耳机在主路上骑行的车手或者行动迟缓的老人要不要减速避让等等,而这些正是人类驾驶所必须掌握的“世界知识”。
总之,自动驾驶系统要想在真实的物理世界和人类社会环境当中运行,就必要摆脱一些额外的、人为的、过度的保护措施,更多的依靠自动驾驶系统自身产生的通用智能,摆脱过去条块分割的模块化思路,采用像人类一样的感知和认知判断的方式和人类一样的学习方式。
过去二十年,深度学习、高精地图、激光雷达传感器、移动通信技术、车路协同等技术,构建了自动驾驶的基础架构,让自动驾驶在一定条件下开始实现,并形成了如今的产业格局。而AI大模型的出现,会让自动驾驶的技术架构发生一次颠覆性的重构,真正有可能达成自己的最终目标。
二、AI大模型正在具有“世界知识”
哲学家维特根斯坦在早期的《逻辑哲学论》中提及了“语言与命题”、“逻辑与世界”的关系,他指出:“语言是通过符号之间的关系来表达意义的”,“语言的意义是通过语言使用者与其行为来确定的”,而“语言由命题构成,逻辑是对命题和真值的判断,而命题是关于事实的描述,事实又存在于世界之中。”
由此,维特根斯坦通过语言建立起了逻辑和世界的桥梁。这些观点也成为我们检视人工智能能力的坐标。
当人工智能技术进入到大模型(Foundation Model)阶段,率先实现的就是大语言模型(LLMs)的突破。ChatGPT的横空出世带给世人一种错觉,那就是这种生成式AI可以有模有样地产生高质量的对话、文本,其中真的体现了“智能”。
不过,ChatGPT所生成的语言内容,本质是根据前面语词对下一个语词的预测,我们尽管可能从中看到有关“事实”的描述,也能看到一定程度的推理,但仍然并不妨碍AI大模型在做一只“随机鹦鹉”,也就是AI并没有具有对现实世界的真正理解,它只是在“表演”对知识的理解和对世界的描述。
显然,这并不是我们对人工智能的期望。因此,大模型应该升级为多模态的,即大模型不仅能够读懂文本中的意义,同时也能看懂人类世界的事实和知识,而且可以将二者联系起来。
在ChatGPT基础上,GPT-3.5和GPT-4模型都可以开始基于图像进行分析和对话。而最新的GPT-4V(ision)这一大型多模态模型(LMM)也被公布出来,成为理解AI具有世界知识的新技术样本。
多模态模型的通用性,必然要求系统能够处理不同输入模态的任意组合。根据微软公布的报告,GPT-4V 在理解和处理任意混合的输入图像、子图像、文本、场景文本和视觉指针等多模态输入,均表现出了前所未有的能力。而且,GPT-4V 在开放世界视觉理解、视觉描述、多模态知识、常识、场景文本理解、文档推理、编码、时间推理、抽象推理、情感理解等不同领域和任务中也都表现出了令人印象深刻的人类水平的能力。
用比较通俗的话来说,GPT大模型的技能树已经拉满,不仅局限在处理文本内的复杂推理关系,同时能够读懂图像,并且理解图像当中的深层涵义,还能够对其中的涵义做出细致解释。这相当于AI大模型正在打通语言和世界的隔阂,并且从中建立逻辑推理和对应关系。
我们简单举例来看下。
先看什么是多模态的输入(MultiModal Input),GPT-4V支持纯文本、单个图像-文本对、交错图像-文本的输入。

如上图所示,在Prompt里给出了单个或多个图像-文本对,GPT-4V不仅从图像中找到了Prompt中对应的答案,并且还指出这些答案所在的位置。
下图是视觉指向和视觉参考提示的例子。图中用高亮线条、箭头圈出或指向的区域称为GPT-4V要理解的目标。
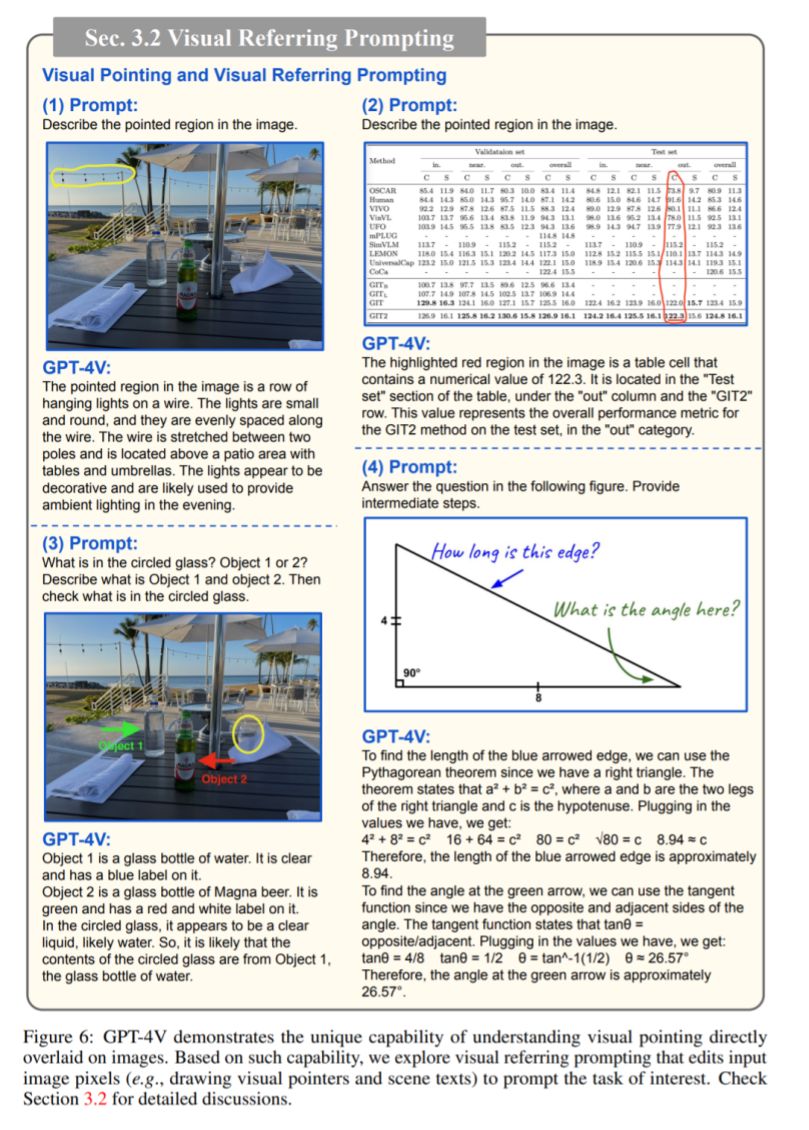
从图中给出的结果可以看到,GPT-4V能够指出这些所指的内容,并且可以判断他们与整个图形其他东西的关系。并且可以回答图形当中的相关问题。
有了指令跟随、思维链、上下文少样本学习等这些LLM当中的test-time技术,GPT-4V就可以很好地用文本来理解和解释视觉(物理)世界。
其中,GPT-4V可以区分不同域图像,并进行识别不同的名人,并能详细描述名人的职业、行为、背景、事件等信息。
除了识别名人外,GPT-4V能准确识别测试图像中的地标、菜肴、常见的疾病,同时给出生动详细的描述,指出菜肴的成分和烹饪技术,以及描述疾病并给出治疗建议。甚至于,当Prompt的问题与图片事实不符,GPT-4V也能进行反事实推理。
更进一步,GPT-4V能够理解图像中人与物体之间的空间关系,例如,GPT-4V识别飞盘和人之间的空间关系,行驶在公路上的汽车和行人的位置、大小比例的关系;能够成功地定位和识别图像中的个体,然后为每个个体提供简洁的描述;也能够确定图像中指定物体的数量。

例如上图就可以成功定位四个人物的位置关系,并且获取四个人的人名,并且给他们做出简洁的描述。
以上如果是常规操作,后面GPT-4V的操作逐渐走向离谱,包括但不限于对多模态(图文对)信息的理解和常识的推理。
例如,解释需要很多背景信息才能读懂的梗图和笑话,对场景下的文本、表格、图文进行推理、计算,对流程图、图表、报告进行阅读、总结和提炼,对多语言文本进行识别、翻译,甚至于从人的面部表情中识别和解读人的情绪,理解不同的视觉内容如何激发情绪,根据所需的情绪和情感生成适当的文本输出;以及可以对视频内容进行理解和预测。

当这一切都可以完成,那么是不是可以应用在自动驾驶场景的理解当中呢?GPT-4V显然可以。
下面是知乎网友Naiyan Wang 应用GPT-4V对交通场景所做的测试*,包括对前方车辆障碍物的识别、标记和预测。如下图。

GPT-4V给出结果如下:
描述了三辆卡车的基本情况,以及发现了中间道路上遗留的未知物体,并进行了推测。

下面是对一个极端天气下的行驶场景的描述,Prompt要求做出驾驶策略的建议。

从GPT-4V描述中看出,场景识别非常细致,能够认出卡车尾部的雾气,是因为经过水坑所产生的,并且给出了非常符合物理世界规律的驾驶策略。
以下可以看到一个更复杂(极端)的例子。挡风玻璃前面是一个挥舞着棒球杆的男子。可以看到,GPT-4V给出的描述非常准确,能够识别到男子的危险动作和情绪,并且给出了非常中肯的驾驶策略。
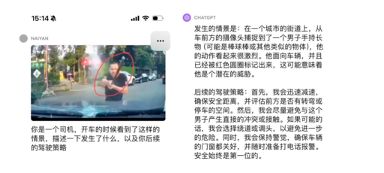
测试者认为,GPT-4V具有强大的泛化性能,适当的Prompt应当可以完全发挥出GPT-4V的实力。解决语义上的corner case应该非常可期,但幻觉的问题会仍然困扰着一些和安全相关场景中的应用。合理使用这样的大模型可以大大加快L4乃至L5自动驾驶的发展,然而是否LLM一定是要直接开车?尤其是端到端开车,仍然是一个值得商榷的问题。
这里可以看下一些自动驾驶公司的做法。
三、引入大语言模型,自动驾驶开始具备世界知识
要把大语言模型的能力下放到自动驾驶上面,主要面临攻克两个难题:
一是在纷繁复杂的交通场景中具备“见多识广”的感知理解能力,另外就是在参与者众多的行驶过程具备“灵活多变”的认知决策能力。
第一个能力,要求自动驾驶系统认得东西多、准、快,要清晰地知道这些东西的相对位置、速度,材质、纹理、语义信息。第二个能力,要求准确地知道这些东西的意图、轨迹和接下来的变化趋势,从而指导决策和控制输出。
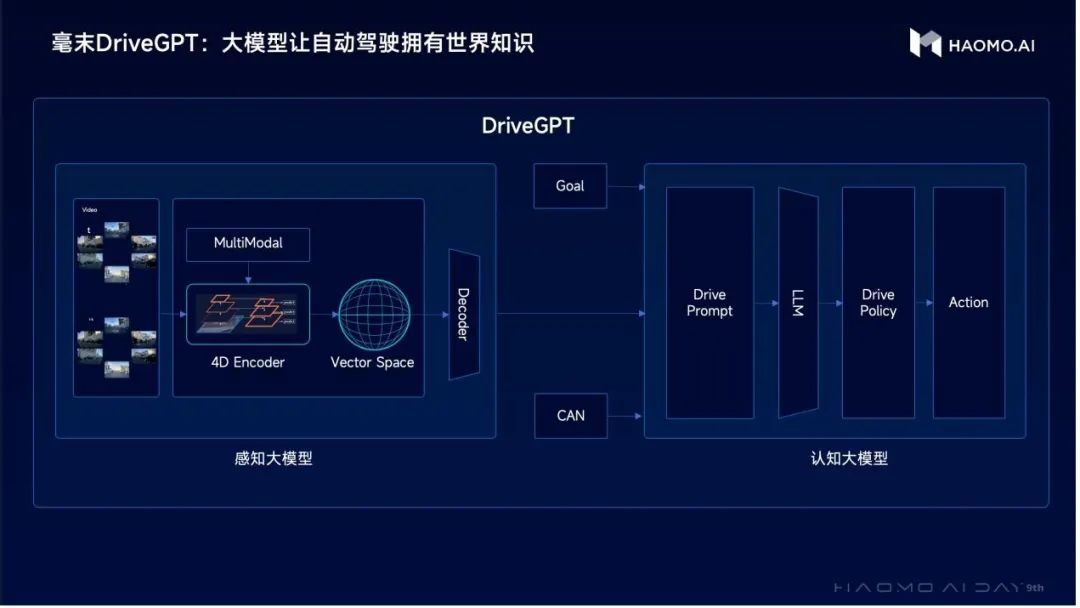
毫末的自动驾驶大模型DriveGPT,是通过视觉大模型,在海量无标注的自动驾驶数据集上,采用自监督预训练的方式构建图像表征,让CV Backbone大幅提升视觉表征学习能力。
其次,DriveGPT在CV Backbone提取到视觉特征基础上,再引入NeRF技术,通过预测视频下一帧的自监督方式来构建4D编码空间,即将一个Clips序列的前K帧的部分输入模型,用NeRF渲染出后续的H帧,构建起一个带有时序的4D特征空间。
其中,DriveGPT在过程中引入了图文多模态大模型,经过4D编码器将视频中的时空特征编码到4D特征空间后,在通过多模态大模型,将视觉特征对齐到文本语义特征,最后通过NeRF渲染器,以预测未来视频的方式,用来监督4D特征空间中对世界的感知能力。
如此,图文多模态模型的引入就让4D空间中的各类事物具有了语义信息。从而DriveGPT先构建起一个见多识广的自动驾驶通用感知大模型,实现在一个模型中同时学习到空间的三维几何结构、语义分割和纹理信息,也就具备识别万物的能力,也由此更好地完成目标检测、目标跟踪、深度预测等各类感知任务。
举个例子,当车辆前方出现低垂的柳条或者被风卷起的塑料袋,原有的视觉感知会将其识别为一般障碍物,而可能出现幽灵刹车的问题。而借助通用感知大模型的万物识别能力,就能理解前方事物的具体语义信息,根据其物理信息判断是否可以继续行驶。
第三,感知的结果将作为输出,进入认知模块,通过引入大语言模型LLM,让自动驾驶系统能看懂驾驶环境,理解社会常识,从而具备世界知识,也就是既能认识这些道路场景的元素是什么,也能知道其包含的物理、社会属性,从而做出更好预测和决策规划。
具体过程是这样:先将感知大模型的结果解码得到当前的感知结果,再结合自车信息和驾驶意图,构造典型的Drive Prompt(驾驶提示语),再将这些Prompt输入大语言模型,让大语言模型对当前的自动驾驶环境做出解释。例如为什么要加速、为什么要减速、为什么要变道等,让大语言模型能够像驾校教练或者陪练一样,对驾驶行为做出详细的解释。
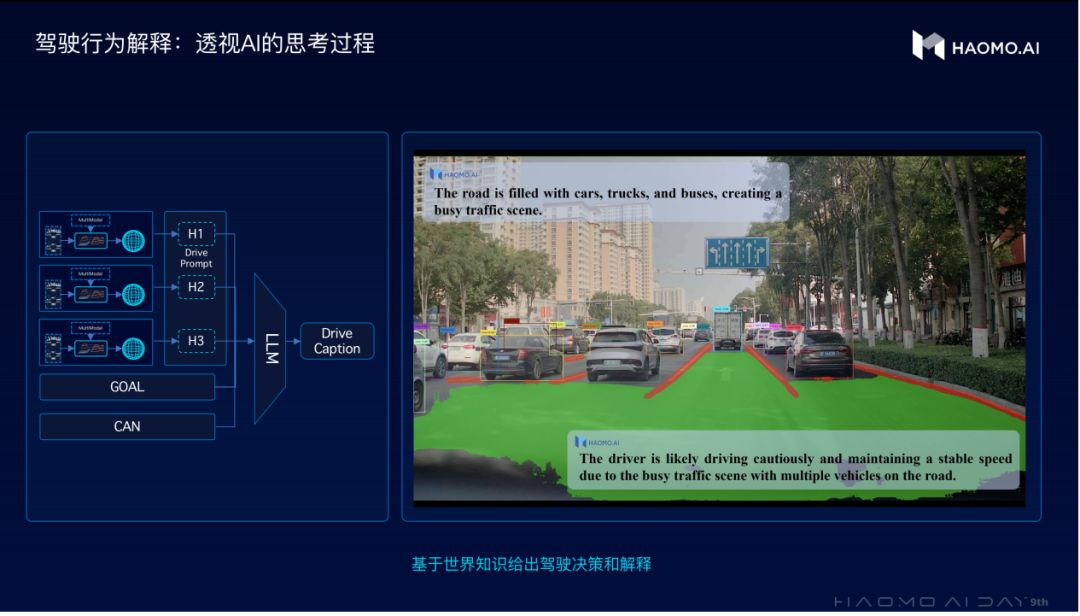
最后,再将驾驶解释和驾驶建议作为prompt输入到生成式大模型,来让自动驾驶大模型获得外部大语言模型内的人类知识,从而具备常识,才能理解人类社会的各种明规则或者潜规则,才能跟老司机一样,与各类障碍物进行更好地交互,更好地对未来的驾驶策略进行规划,输出控制结果。
四、掌握世界知识:自动驾驶将抵达目标点
回到开头,从第一性原理出发,人类是如何开车的?优秀的人类司机在驾驶中,不仅仅能看到交通环境的各种场景,而且还能很好理解这些场景中的路牌、路标、车辆、行人分别代表什么含义,而且还能准确推理、判断这些物体的运动趋势、意图和危险程度。
比如,当司机注意到前面有一个不断向后扭头观察的骑行者,就能判断他是想要变道或者横穿过去,就会主动礼让,而如果遇到一个按照稳定在直线骑行的成年人就可以试着超过去,但如果是遇到带着头盔、耳机的年轻骑行者或者是年级较大的老人就应该减速,从而小心应对。这些在真实物理世界当中的社会知识,是需要在长期的驾驶过程中结合生活经验融会贯通的。
对于自动驾驶系统来说,如果把不同类型的移动的行人、车辆都一视同仁地看作同等类型的障碍物,就很难做出拟人的驾驶策略,要么会非常保守,要么就会非常激进。
因此,自动驾驶系统不仅要学习如何区分感知到的物体,而且要逐渐理解这些物体分别具有的含义,除了学习驾驶者在相应场景下的驾驶决策行为,还要理解驾驶者为什么会做出这种决策。
再举一个现实的案例。
不久前,美国自动驾驶公司Cruise的Robotaxi在旧金山的开放道路上开始了商业运营。结果没几天,有一台车陷到了一段没有干透的水泥路里。
那为啥这台Robotaxi会冲进去?就是因为它的感知里识别到那是一段平坦的路面,但是不知道车在这种没干透的水泥路会陷进去,这是普通人都知道的物理常识,但显然这台Robotaxi还没有学会。
在城市场景里,其实有着类似这样无穷无尽的极端场景。所以自动驾驶想要开的好、变得真正像人一样聪明地驾驶,就必须掌握大量的世界知识。
目前来看,大语言模型确实已经存储了大量的世界知识,自动驾驶将大语言模型引入进来,从中能够学习到这些常识,以后就可以知道没有干透的马路不能开上去,遇到马路边的小孩子要比成年人更需要注意减速避让,遇到戴头盔的电动车的骑行者也需要提高警惕。
最后总结下,AI大模型正在帮助自动驾驶获得认识万物的通用感知,以及获得世界知识的通用认知能力。一些大模型展现出来的图文解释能力,以及引入多模态模型和大语言模型的实践,正是这一自动驾驶技术架构正在被重构的前沿实践。
可以预见,接下来自动驾驶领域将会出现更多大模型的实践,给出更具技术潜力的端到端方案。
* 文内第二部分引用的交通场景测试案例,来自于Naiyan Wang在《GPT-4V在自动驾驶中初探》中的分享,原文链接:https://zhuanlan.zhihu.com/p/660940512