Python--快速入门四
1.Python函数

1.在括号中放入函数的参数。
2.可以通过return在函数作用域外获取函数作用域内的值。(默认的return值为None)
代码展示:BMI计算函数
def calculate_BMI(fuc_height,fuc_weight):
fuc_BMI = fuc_weight/(fuc_height**2)
return fuc_BMI
# input输入的值默认为字符串
height = float(input("请输入您的身高(/m):"))
weight = float(input("请输入您的体重(/kg):"))
# 调用函数
BMI = calculate_BMI(height,weight)
if BMI <= 18.5:
print("您的BMI为:" + str(BMI) + ", 偏廋")
elif 18.5 < BMI <= 25:
print("您的BMI为:" + str(BMI) + ", 正常")
elif 25 < BMI <= 30:
print("您的BMI为:" + str(BMI) + ", 偏胖")
elif BMI > 30:
print("您的BMI为:" + str(BMI) + ", 肥胖")

2.Python引入模块

1.import...语句引入模块:在使用模块中的函数时,需要 模块名.函数名( )进行调用。
2.from...import ...语句引入模块:指明模块中引入的函数,调用时可以直接使用,不需要再使用模块名进行调用。
3.form...import*语句引入模块:引入模块中的所有函数,调用时可以直接使用(一般不建议使用,引入不同的模块时可能会造成命名冲突)
4.若要安装外部模块,则需要先下载,再于终端输入:pip install 模块名(或者可以找到外部模块的相关文档,获取相应的安装方法),此后便可通过import语句引入外部模块了。
eg.安装akshare库
1).在下述网站上找到akshare库的下载连接和文档PyPI · The Python Package Index![]() https://pypi.org/
https://pypi.org/
2). 
在pycharm的终端完成akshare库的安装
3).通过import引入akshare库,在文档中查找该库的使用方法并进行使用测试

import akshare
print(akshare.get_cffex_daily())
3.Python创建类
 Python定义类名时习惯使用Pascal命名风格:通过首字母的大写来分隔单词
Python定义类名时习惯使用Pascal命名风格:通过首字母的大写来分隔单词
构造函数:__init__(self, ...)
class CuteCat:
def __init__(self,cat_name)
self.name = cat_name
# 创建类对象时,会自动调用相应的构造函数对类对象的属性赋值
cat1 = CuteCat("AFish")
构造函数的第一个参数默认为self(该参数不需要手动传入),代表对象本身。
定义方法:
class CuteCat:
def speak(self,...):
#方法的具体实现类方法的第一个参数默认也为self,可以调用类对象的属性,方法等。
代码实现:学生类
class StudentInfo:
def __init__(self, stu_name, stu_stn, stu_ch_grade, stu_math_grade, stu_eng_grade):
# 学生类属性的定义:
self.name = stu_name
self.stn = stu_stn
self.ch_grade = stu_ch_grade
self.math_grade = stu_math_grade
self.eng_grade = stu_eng_grade
# 打印单科成绩函数:
def print_single_grade(self, sub):
if sub == "math":
print(f"stu_name: {self.name} stu_stn: {self.stn} -- math_grade: {self.math_grade}")
elif sub == "chinese":
print(f"stu_name: {self.name} stu_stn: {self.stn} -- chinese_grade: {self.ch_grade}")
elif sub == "english":
print(f"stu_name: {self.name} stu_stn: {self.stn} -- english_grade: {self.eng_grade}")
# 打印所有成绩函数:
def print_all_grade(self):
print(
f"stu_name: {self.name} stu_stn: {self.stn} -- math_grade: {self.math_grade},chinese_grade: {self.ch_grade},english_grade:{self.eng_grade} ")
# 类对象的创建以及构造函数的调用
S1 = StudentInfo("AFish", "2021214455", "95", "88", "92")
# print_single_grade函数测试
subject = input("请输入您想查询成绩的科目(math/chinese/english):")
S1.print_single_grade(subject)
# print_all_grade函数测试
print("所有成绩如下:")
S1.print_all_grade()

4.Python类继承
A is B -- A则可以是B的子类
子类会继承父类的属性和方法(优先调用子类的方法,如果子类没有该方法再向上调用父类对应的方法)
# 类继承
class DerivedClass(BasicClass):super()方法:该方法会返回当前类的父类
class DerivedClass(BasicClass):
super().__init__( )上述代码会直接访问父类的构造函数
代码实现:人力系统
# 父类:
class Employee:
def __init__(self, name, id):
self.name = name
self.id = id
def print_info(self):
print(f"name:{self.name},id:{self.id}")
# 全职员工子类:
class FullTimeEmployee(Employee):
def __init__(self, name, id, monthly_salary):
# 在此次需要调用基类的构造函数完成基类属性的定义,再完成派生类属性的定义
super().__init__(name, id)
self.monthly_salary = monthly_salary
def calculate_monthly_pay(self):
print(f"monthly_pay:{self.monthly_salary}")
# 兼职员工类:
class PartTimeEmployee(Employee):
def __init__(self, name, id, daily_salary, work_days):
super().__init__(name, id)
self.daily_salary = daily_salary
self.work_days = work_days
def calculate_monthly_pay(self):
print(f"monthly_pay:{self.daily_salary * self.work_days}")
F1 = FullTimeEmployee("AFish", "1122", 8000)
F1.print_info()
F1.calculate_monthly_pay()
P1 = PartTimeEmployee("GodFishhh","3344",200,22)
P1.print_info()
P1.calculate_monthly_pay()
5.Python文件操作
打开文件:open("文件的相对路径/绝对路径","r/w", encoding = "utf-8")
第二个参数是模式,有r--read只读模式和w--write写入模式,默认情况下为只读模式。
第三个参数为编码方式:其中常用 "uft-8"
UTF-8 是 Unicode 的编码系统。它可以将任何 Unicode 字符转换为匹配的唯一二进制字符串,还可以将二进制字符串转换回 Unicode字符。这就是"UTF"或"Unicode Transformation Format"的含义。
Unicode 是国际标准字符集,它将世界各种语言的每个字符定义一个唯一的编码,以满足跨语言、跨平台的文本信息转换。
# 相对路径
open("./data.txt","r",encoding = "utf-8")
# 绝对路径
open("/usr/demo/data.txt","w",encoding = "utf-8")5.1.读文件操作
read方法:

第一次read会读取到文件的末尾,程序会记录当前读取到的位置,所以第二次读取时会读取空字符串并打印。
如果文件中的字符串数量过多,读出来的内容过多时可以给read(n)方法传一个数字,表示会读到1-n个字节的文件内容。
print(f.read(10)) # 读1-10个字节的文件内容
print(f.read(10)) # 读11-20个字节的文件内容readline方法:

readline方法一般与while循环结合使用:读完文件内容后,会返回空字符串

readlines方法:
readlines方法一般与for循环结合使用: lines保存的是文件中以行分隔的字符串列表

关闭文件的两种方法:

第一种方法通过close()函数对文件手动关闭。
第二种方法则是当缩进中对文件的操作结束后,自动进行文件的关闭。
代码展示:
# f = open("./data.txt", "r",encoding="utf-8")
# content = f.read()
# print(content)
# f.close()
# 系统自动关闭close()
with open("./data.txt", "r",encoding='utf-8') as f:
# read方法
# content = f.read()
# print(content)
# readline方法
# 读取两行内容
# print(f.readline())
# print(f.readline())
# readlines方法,结合for循环使用
lines = f.readlines()
for line in lines:
print(line)
在PyCharm创建.txt文件,此时相对路径就是 ./data.txt(因为.py文件和.txt文件处于同一个文件夹,"."就代表当前文件夹,再加上分隔符" / "和文件名data.txt即可组成相对路径);也可以直接获得文件的绝对路径。
若open的第三个参数设置为encoding = " utf-8 "无法运行,有两种方法解决:
1.在代码开头加个默认:
# coding:utf-8
2.找到当前python文件,另存字符编码为"UTF-8"



5.2.写文件操作

写文件也需要通过open方法打开文件,此时第二个参数为"w"
注意点:
1.此时若地址所指向的地方没有该文件,则系统会自动创建一个文件并继续进行写操作。
2.如果地址所指向的地方存在文件,则系统会先把文件中的内容清空后再继续写操作。(可以将第二个参数换为"a"--追加模式,则不会清空文件中原有的内容,并在内容后完成写操作)
3.此时对文件不支持读操作。
open第二参数参考博客:
深入理解Python读写模式:‘r‘,‘w‘,‘a‘,‘r+‘,‘w+‘,‘a+‘_r模式python-CSDN博客
通过方法write()来进行对文件的写操作
f.write()代码实现:
# 1.对一个不存在的文件进行写操作
with open("./poem.txt", "w", encoding="utf-8") as f:
f.write("花间一壶酒,独酌无相亲。\n举杯邀明月,对影成三人。\n月既不解饮,影徒随我身。\n暂伴月将影,行乐须及春。\n")
# 2.对一个存在的文件进行写操作
with open("./poem.txt", "a", encoding="utf-8") as f:
f.write("我歌月徘徊,我舞影零乱。\n醒时相交欢,醉后各分散。\n永结无情游,相期邈云汉。\n")
6.Python异常处理

代码测试:
# Python异常捕捉
# FileNotFoundError LookupError
try:
with open("./test.txt", "r", encoding="uft-8") as f:
print("test")
except FileNotFoundError:
print("未找到该文件")
except LookupError:
print("没有找到此编码")
else:
print(f.read())
finally:
print("程序运行结束")
print("--------------------")
try:
with open("./data.txt", "r", encoding="uft-8") as f:
print("test")
except FileNotFoundError:
print("未找到该文件")
except LookupError:
print("没有找到此编码")
else:
print(f.read())
finally:
print("程序运行结束")
print("--------------------")
try:
with open("./data.txt", "r", encoding="utf-8") as f:
print(f.read())
except FileNotFoundError:
print("未找到该文件")
except LookupError:
print("没有找到此编码")
else:
print("文件可读")
finally:
print("程序运行结束")
7.Python测试
通过Python自带的测试库unitest进行测试:

1.测试代码一般和实现代码分开放在不同的文件中。
2.
测试代码所在的文件需要引入测试库:
import unittest还需要引入想要测试的功能:
测试文件和实现文件在同一个文件夹下:
from 文件名 import 函数名/类名3.创建的测试类需要继承于uniitest库中的TestCase类,可以使用TestCase的测试方法
4.测试用例的命名必须以 test_开头:unittest库会自动搜索以test_开头的方法,并只把test_开头的方法当作是测试用例。
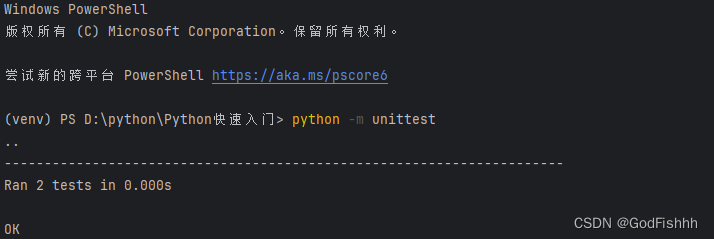
5. 写好测试用例后,在终端输入:python -m unittest,unittest就会调用所有集成了该库里TestCase类的子类,运行它们所有以test_开头的方法,并展示测试结果。
eg:
# Hello_Python.py
def calculate_add(x, y):
return x+y
# test.py
import unittest
from Hello_Python import calculate_add
class CalculateTest(unittest.TestCase):
def test_Add(self):
self.assertEqual(calculate_add(1,2),3)终端输入后结果:

其中横线上方的“ · ”代表通过了一个测试用例

" F " 则代表有一个测试用例未通过
unittest.TestCase类中的常见测试方法:

TestCase类中的setUp方法:

在运行各个test_测试用例之前,都会先调用setUp方法,可以在setUp方法中先创建好测试对象,再于各个测试用例中调用该对象的属性,减少代码的重复。
代码测试:
# Hello_Python.py
class ShoppingList:
def __init__(self, shopping_list):
self.shopping_list = shopping_list # shopping_list应当是一个字典
def get_item_count(self):
return len(self.shopping_list)
def get_total_price(self):
total_price = 0
for price in self.shopping_list.values():
total_price += price
return total_price
# test.py
import unittest
from Hello_Python import ShoppingList
class TestShoppingList(unittest.TestCase):
# setUp方法创建一个测试对象方面后续测试(test_测试用例调用前都会先调用setUp函数)
def setUp(self):
shop_dict = {"键盘": 700, "鼠标": 500, "显示器": 1500}
# 即为该测试类创建一个属性为shopping_list(创建方法类似与构造函数)
self.shopping_list = ShoppingList(shop_dict)
def test_get_item_count(self):
self.assertEqual(self.shopping_list.get_item_count(), 3)
def test_get_total_price(self):
self.assertEqual(self.shopping_list.get_total_price(),2700)