1,Apache Hive概述
定义:
Hive是由Facebook开源用于解决海量结构化日志的数据统计,它是基于大数据生态圈Hadoop的一个数据仓库工具。
作用:
Hive可以用于将结构化的数据文件【映射】为一张表,并提供类SQL查询功能。
Hive的本质是将SQL转化成MapReduce程序。
使用场景:
主要用途:用来做离线数据分析,比直接MapReduce的开发效率更高。
总结作用:Hive可以简单理解为"SQL–MapReduce"框架的一个封装,可以将用户编写的SQL语句解析成对应的MapReduce程序,最终通过MapReduce运算框架形成运算结果,并提交给客户端Client。
1,Hive的优缺点
(1)优点
(a)操作接口采用类SQL语法,提供快速开发的能力;
(b)避免了直接去写MapReduce运算程序,减少开发人员的学习成本;
(c)Hive支持用户自定义函数,功能扩展很方便。
(2)缺点
(a)Hive的执行延迟比较高,因此Hive常用于数据分析,对实时性要求不高的场合;
(b)Hive优势在于处理大数据,对于处理小数据几乎没有优势,因为Hive的执行延迟比较高;
(c)直接使用MapReduce实现复杂查询逻辑开发难度太大,可以转而使用Hive完成。
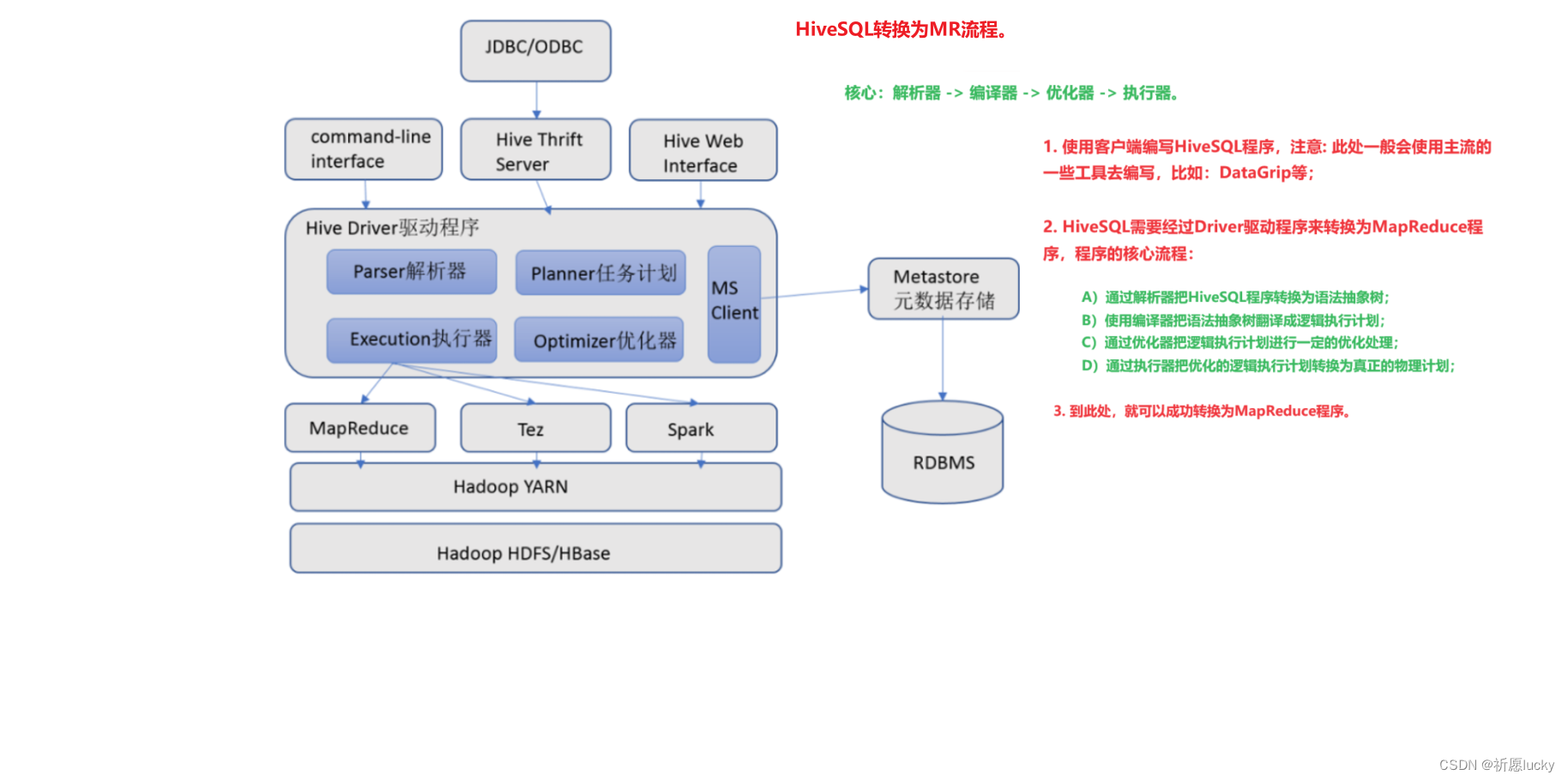
2,Hive基础架构
(1)用户接口
用户接口包括CLI、JDBC/ODBC、WebGUI。
a)CLI(command line interface)为shell命令行;
b)JDBC/ODBC是Hive的Java实现,与传统数据库JDBC类似;
c)WebGUI是通过浏览器访问Hive。
Hive提供了Hive Shell、ThriftServer等服务进程向用户提供操作接口。
(2)元数据存储
元数据包含: 用Hive创建的database、table、表的字段等元信息。
元数据存储: 存在关系型数据库中,如:hive内置的Derby数据库或者第三方MySQL数据库等。
在Hive中,元数据存储需要使用MetaStore。
(3)Driver驱动程序
Driver包括语法解析器、计划编译器、优化器、执行器,可以完成HQL查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。
生成的查询计划存储在HDFS中,并在随后由MapReduce调用执行。
这部分内容不是具体的服务进程,而是封装在Hive所依赖的Jar文件即Java代码中。
2,当使用Hive时,与传统数据库对比,特性有
(1)Hive用于海量数据的离线数据分析;
(2)Hive具有SQL数据库的外表,但应用场景完全不同,Hive只适合用来做批量数据统计分析。
2,Hive部署
1,MetaStore元数据存储流程
(1)客户端Client连接MetaStore服务;
(2)MetaStore再去连接MySQL等关系型数据库来存取元数据。
2,存在的作用
当有了MetaStore服务后,就可以有多个客户端同时连接,且这些客户端不需要知道MySQL等数据库的用户名和密码,只需要连接MetaStore服务即可
3,MetaStore提供存储服务时,有三种不同的模式:
(1)MetaStore服务是否需要单独配置、单独启动?
(2)Metadata元数据是存储在内置库Derby中,还是第三方库MySQL等数据库中。

(1)内嵌模式
当MetaStore元数据存储采用内嵌模式时:
(1)优点:解压Hive安装包到bin/hive后,启动Hive即可使用MetaStore;
(2)缺点:把Derby和MetaStore服务都嵌入在主Hive Server进程中,不适用于生产环境,原因:
a)一个服务只能被一个客户端连接(如果用两个客户端以上就非常浪费资源);
b)元数据不能共享。
(2)本地模式
当MetaStore元数据存储采用本地模式时:
(1)优点: 可以单独使用外部的数据库(MySQL), 元数据共享;
(2)缺点: 相对浪费资源, MetaStore嵌入到了Hive进程中,每启动一次Hive服务,都内置启动了一个MetaStore。
(3)远程模式
当MetaStore元数据存储采用远程模式时:
(1)优点: 可以单独使用外部库(mysql) ,还可以共享元数据。可以连接MetaStore服务,也可以连接hiveserver2服务;
(2)缺点: 需要注意如果想要启动hiveserver2服务,则先需要启动MetaStore服务。
4,启动MetaStore与HiveServer2
在hive安装的服务器上,首先启动MetaStore服务,然后启动hiveserver2服务。
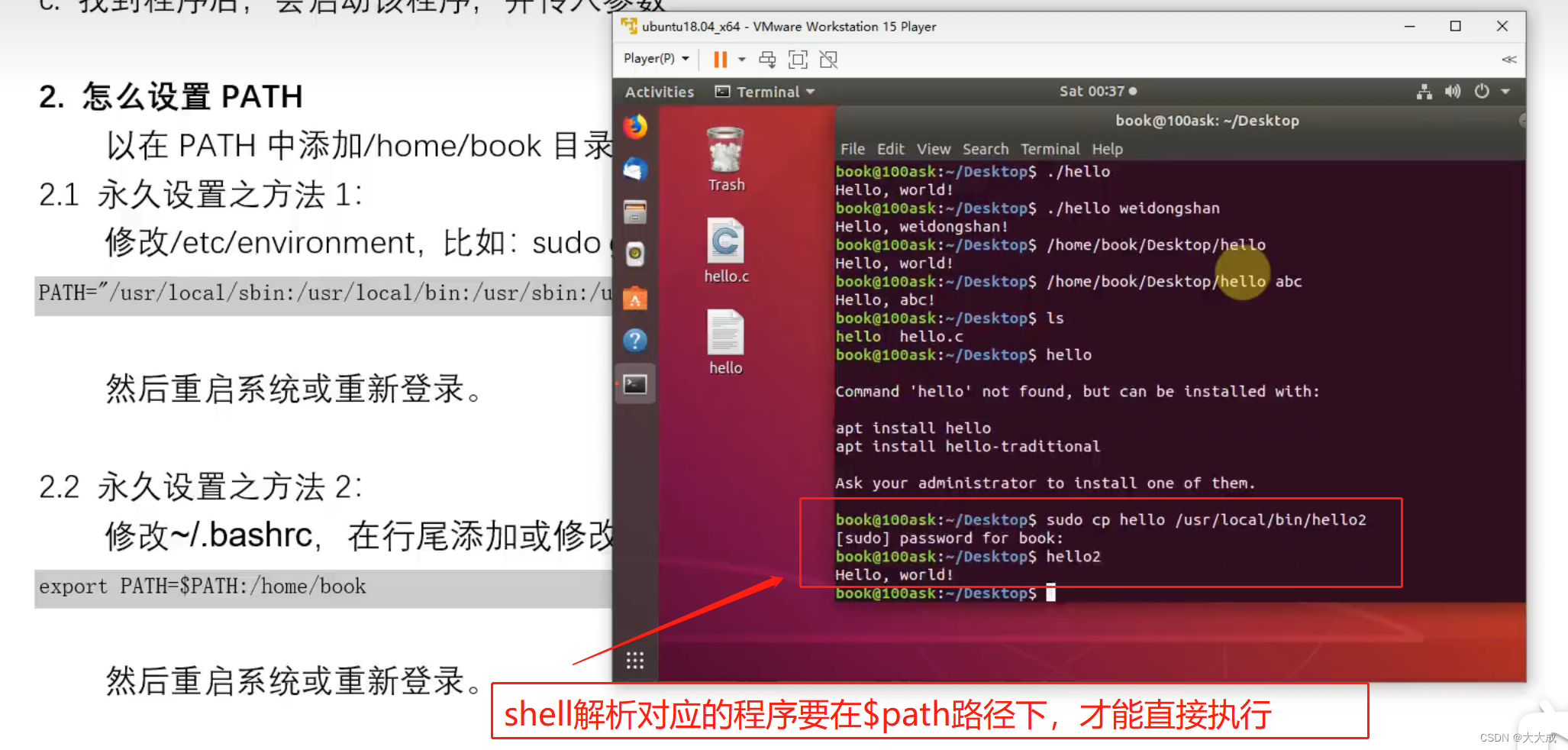
(1)进入/export/server/apache-hive-3.1.2-bin/bin目录后,启动MetaStore服务,命令:
[root@node1 apache-hive-3.1.2-bin]# [nohup] ./hive --service metastore &
#启动hiveserver2服务
[root@node1 apache-hive-3.1.2-bin]# [nohup] ./hive --service hiveserver2 &
(a)查看进程是否开启,命令:
# 可以使用lsof命令查看对应进程是否开启
[root@node1 apache-hive-3.1.2-bin]# lsof -i:10000
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
java 18804 root 520u IPv6 266172 0t0 TCP *:ndmp (LISTEN)
(b)杀死进程[关闭Hive服务]时,命令:
kill -9 进程号
2,当进程启动不成功时,需要杀死所有已经启动的runjar程序,然后再开始重新启动
5,HiveServer2服务
Beeline是JDBC的客户端,通过JDBC协议和Hiveserver2服务进行通信,协议的地址是:jdbc:hive2://node1:10000。
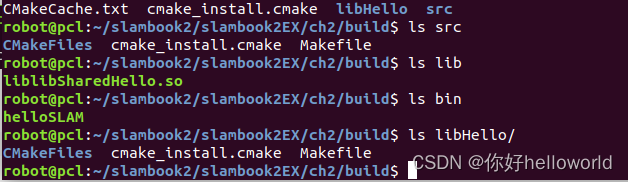
使用Beeline客户端连接Hive时,命令:
(1)启动Beeline,进入hive的bin目录后:
./beeline
(2)连接Hive
! connect jdbc:hive2://node1:10000
[root@node1 ~]# /export/server/hive/bin/beeline
Beeline version 3.1.2 by Apache Hive
beeline> ! connect jdbc:hive2://node1:10000
Connecting to jdbc:hive2://node1:10000
Enter username for jdbc:hive2://node1:10000: root
Enter password for jdbc:hive2://node1:10000:
Connected to: Apache Hive (version 3.1.2)
Driver: Hive JDBC (version 3.1.2)
Transaction isolation: TRANSACTION_REPEATABLE_READ
0: jdbc:hive2://node1:10000>
6,Hive环境变量
1,Shell脚本执行方式有三种:
方式一:sh执行
格式: sh 脚本
注意: 需要进入脚本的所在工作目录,然后使用对应的sh命令来执行脚本,
这种执行方式,脚本文件不需要具有可执行权限。
2,相对路径执行
格式: ./脚本
注意: 需要先进入到脚本所在的目录,然后使用 ./脚本方式执行,
这种执行方式,必须保证脚本文件具有可执行权限。
3,方式三:绝对路径执行
格式: /绝对路径/脚本
注意: 需要使用脚本的绝对路径中执行,指的是直接
4,配置Hive的环境变量,命令:
echo 'export HIVE_HOME=/export/server/apache-hive-3.1.2-bin' >> /etc/profile
echo 'export PATH=$PATH:$HIVE_HOME/bin:$HIVE_HOME/sbin' >> /etc/profile
source /etc/profile
另外的,也可以把使用Vi把如下配置Hive环境变量的语句添加到/etc/profile结尾处:
# HIVE_HOME
export HIVE_HOME=/export/server/apache-hive-3.1.2-bin
export PATH=$PATH:$HIVE_HOME/bin:$HIVE_HOME/sbin
7,Hive使用
1,使用SQL操作Hive
(1)创建表
CREATE TABLE test(id INT, name STRING, gender STRING);
(2)插入数据
INSERT INTO test VALUES(1, '肖战', '男'), (2, '周杰伦', '男'), (3, '迪丽热巴', '女');
(3)查询数据
SELECT gender, COUNT(*) AS cnt FROM test GROUP BY gender;
(1)验证SQL语句启动的MapReduce程序
打开YARN的WEB UI页面查看任务情况:http://node1:8088
(2)验证Hive的数据存储
Hive的数据存储在HDFS的:/user/hive/warehouse中。
4,数据仓库和数据库
(1)数据库DataBase,简称为DB
用于把数据结果给外部各类程序使用,侧重于增删查改。
(2)数据仓库Data Warehouse,可简写为DW或DWH
用于分析历史数据而存在,为企业提供决策支持。
2,数据库和数据仓库的区别,就是说:OLTP与OLAP的区别。
(1)OLTP联机事务处理
操作型处理,叫联机事务处理OLTP(On-Line Transaction Processing,),也可以称面向交易的处理系统。
OLTP是针对具体业务在数据库联机的日常操作,通常对少数记录进行查询、修改。用户较为关心操作的响应时间、数据的安全性、完整性和并发支持的用户数等问题。
传统的数据库系统,常用于数据管理,比如对数据增删查改,属于操作型处理。
(2)OLAP联机分析处理
分析型处理,叫联机分析处理OLAP(On-Line Analytical Processing),一般针对某些主题的历史数据进行分析,支持管理决策。
3,值得注意的是,数据仓库的出现,并不是要取代数据库。
通常,数据仓库的主要特征有:
a)面向主题的(Subject-Oriented )
b)集成的(Integrated)
c)非易失的(Non-Volatile)[或(不可更新性)]
d)时变的(Time-Variant )
数据仓库是在数据库已经大量存在的情况下,为了进一步挖掘数据资源、为了决策需要而产生的。
4,主要区别如下:
A)数据库是面向事务的设计,数据仓库是面向主题设计的;
B)数据库一般存储业务数据,数据仓库存储的一般是历史数据;
C)数据库是为捕获数据而设计,数据仓库是为分析数据而设计
D)数据库设计是尽量避免冗余,一般针对某一业务应用进行设计,比如一张简单的User表,记录用户名、密码等简单数据即可,符合业务应用,但是不符合分析;而数据仓库在设计是有意引入冗余,依照分析需求,分析维度、分析指标进行设计
数仓的分层架构
存在意义:数据仓库出于对历史数据进行分析性报告、决策支持目的而创建的。目的是构建面向分析的集成化数据环境,为企业提供决策支持。
1,数据仓库中的数据源来自企业
(1)RDBMS关系型数据库—>业务数据
(2)log file----->日志文件数据
(3)爬虫数据
(4)其他数据
2,数据仓库的发展,大致经历了三个阶段:
a)简单报表阶段
解决一些日常的工作中业务人员需要的报表,以及生成一些简单的能够帮助领导进行决策所需要的汇总数据。这个阶段的大部分表现形式为数据库和前端报表工具。
b)数据集市阶段
根据某个业务部门的需要,进行一定的数据采集、整理,按照业务人员的需要,进行多维报表的展现,能够提供对特定业务指导的数据,并且能够提供特定的领导决策数据。
c)数据仓库阶段
按照一定的数据模型,对整个企业的数据进行采集、整理,并且能够按照各个业务部门的需要,提供跨部门的,完全一致的业务报表数据,能够通过数据仓库生成对对业务具有指导性的数据,同时,为领导决策提供全面的数据支持。
3,数据仓库的架构可分为三层
(1)源数据层(ODS):直接使用外部系统数据结构和数据,这是接口数据的临时存储区域,为后一步的数据处理做准备;
(2)数据仓库层(DW):也称为细节层,DW层的数据应该是一致的、准确的、干净的数据,即对源系统数据进行了清洗后的数据;
(3)数据应用层(DA或APP):前端应用直接读取的数据源,也是根据报表、专题分析需求而计算生成的数据。
4,ETL与ELT
数据仓库从各个数据源中,获取数据及在数据仓库内的数据转换和流动都可以认为是ETL(抽取Extract,转化Transform, 装载Load)的过程。
(1)ETL
先从数据源池中,抽取数据,并把数据保存在临时暂存数据库中(ODS)。
然后,执行转换操作,将数据结构化并转换为适合目标数据仓库(DW)系统的形式,然后将结构化数据加载到数据仓库中进行分析。
(2)ELT
使用ELT时,数据在从数据源中提取后立即加载。没有专门的临时数据库(ODS),这意味着数据会立即加载到单一的集中存储库中。
数据在数据仓库系统中进行转换,然后进行分析。大数据时代数仓这个特点很明显
5,数据库操作
1,HQL数据定义语言
数据定义语言 (Data Definition Language,DDL),指的是SQL语言集中对数据库内部的对象结构进行创建、删除、修改等操作。
其中,数据库对象包括有:数据库database(schema)、数据表table、视图view、索引index等。
核心语法:
(1)CREATE 创建
(2)ALTER 删除
(3)DROP 修改
2,创建数据库
create database [if not exists] 数据库名
[comment '解释说明']
[location '存储到HDFS路径名']
[with dbproperties (属性名='值', ...)];
指定文件夹下创建数据库
create database zuo location '/zuo';
3,查看数据库信息
desc database [extended] 数据库名;
(1)extended用于显示更多信息,比如位置路径等;
(2)查看数据库信息时,记得加上database。
查看正在使用哪个数据库
select current_database();
4,如果要查看创建数据库的语句时,命令:
show create database itcast;
5,删除库
DROP DATABASE语句用于删除数据库。语法:
drop database 数据库名 [restrict | cascade];
若要删除带有数据表的数据库zuo时,记得在语句结尾处添加cascade。
6,修改库
ALTER DATABASE语句可用于更改与Hive中的数据库关联的元数据信息。语法:
-- 修改数据库存储路径
alter database 数据库名 set location 存储路径名;
-- 修改或新增数据库配置属性
alter database 数据库名 set dbproperties (属性名=值, ...);
使用alter语法来修改数据库的属性
alter database zuo set dbproperties('create_time'='21:15');
desc database extended zuo;








![Mysql执行报错:[Err] 1292 - Truncated incorrect DOUBLE value:***](https://img-blog.csdnimg.cn/c5164e05f8ee4183a99b343dd95fb49d.png)