-
引言
-
简介
-
预训练
-
语料
-
分词器
-
模型架构
-
Infrastructure
-
训练细节
-
-
评测
-
实战
-
总结
-
思考
0. 引言
晨起开门雪满山,雪晴云淡日光寒。

Created by DALL·E 3
小伙伴们好,我是《小窗幽记机器学习》的小编:卖热干面的小女孩。紧接前文:XX
今天这篇小作文主要介绍中文领域的天工大模型Skywork,具体包括模型细节解读和实战这2部分。如需与小编进一步交流(包括完整代码获取),可以添加小编好友。
技术报告:https://arxiv.org/abs/2310.19341
GitHub: https://github.com/SkyworkAI/Skywork
1. 简介
Skywork是由昆仑万维集团·天工团队开发的一系列大型模型,计划开源的模型有Skywork-13B-Base模型(目前确实已开源)、Skywork-13B-Chat模型(暂时2023年11月12日还没有开源,可能在走备案和流程审批?)、Skywork-13B-Math模型(暂无)和Skywork-13B-MM模型(也暂无)。Skywork-13B是使用超过3.2万亿个中英文Token进行预训练得到的130亿参数双语基础语言模型系列(即所谓的基座模型)。Skywork-13B采用两阶段预训练:通用语料预训练和特定领域语料(主要是STEM)的持续预训练,以增强模型在这些领域的能力。此外,Skywork的研究人员还提出了一种检测信息泄露的方法,暗示刷榜的模型中可能存在数据污染问题。这番言论可能局部引发唾液腺分泌,也可能引发肾上腺激素和甲状腺激素分泌的激增。因此,呼吁大家佛系吃瓜,看庭前花开花落,望天空云卷云舒。回到正题,简单总结Skywork的工作:
-
发布Skywork-13B,号称是迄今为止公布的相当规模LLM家族中最全面训练的。
-
发布中间检查点,为理解模型在训练过程中能力如何发展提供参照。
-
发布高质量训练语料库,总计超过1500亿个Token。这是迄今(2023年10月30日)为止最大的用于语言模型预训练的开源中文语料库。
-
提出一种新颖的信息泄漏检测方法,用于检测在训练阶段的领域内数据使用情况,揭露了各大模型刷榜中可能的隐情。
插一句,也不知道最近因为贾扬清热搜缠身的零一万物01大模型是否经得起信息泄漏的考验?由于01大模型尚未发布技术报告,且只发布Base版模型,难以着笔写小作文,那就先祝福ta吧~待后续发布技术报告再进一步解读,感兴趣的小伙伴可以留意下。
2. 预训练
为训练Skywork-13B构建了名为SkyPile的数据集,该数据集主要由公共可访问的网页构成的大规模训练语料库。SkyPile抽取出一个名为SkyPile-STEM的子集,该数据集涵盖了从小学到研究生阶段的广泛学科的练习和解决方案,如编码问题、国家考试问题、教科书练习等。SkyPile-STEM的补集称为SkyPile-Main。
研究员没有直接在整个SkyPile上训练Skywork-13B基础模型,而是采用两阶段的训练方法。第一阶段,是主要的预训练阶段,涉及从头开始在SkyPile-Main数据集上训练模型。在第二阶段,在SkyPile-STEM上做持续预训练,为Skywork-13B模型注入与STEM相关的领域知识和问题解决能力。为了避免灾难性遗忘问题,这种持续预训练是在SkyPile-STEM和SkyPile-Main的混合数据上进行的,而非仅在SkyPile-STEM上进行。
将第一阶段和第二阶段的预训练分隔开具有双重目的。首先,由于SkyPile-STEM数据的固有特性,该数据集中的样本有相当部分比例是有监督数据。这些数据与主流的基准数据,如CEVAL、MMLU和GSM8K密切相关,并可在有监督的微调(SFT)过程中直接用于增强模型在相关下游任务上的性能。在这种情况下,第一阶段和第二阶段训练的分离使我们能够更有效地评估通用预训练(在web文本上)和定向预训练(在领域内/有监督数据上)的影响。这可以为后续训练基础模型的数据收集和策略制定提供信息。其次,通过将第一阶段的预训练限制为通用数据,能够生成一种通用的基础模型版本,从而为具有定向增强的版本提供一种选择。尽管定向增强的模型在某些下游任务上表现出色,但在自然文本的语言建模方面较弱。
2.1 SkyPile语料
为了训练Skywork-13B,官方构建了SkyPile,这是一个庞大而高质量的语料库,包含超过6万亿个Token。并开源了部分的语料库,开源的语料包括超过1500亿个token的网页文本。
SkyPile由多个数据源汇聚而来,其中绝大多数来自公共可访问的渠道。SkyPile的构建专注于两个主要维度:文本质量和信息分布。
数据处理流程,包括以下阶段:
-
结构化提取:由于数据集的主要来源是公共可访问的网页,第一阶段的目标是提取相关内容,同时清除被认为对语言模型训练没有贡献的多余文本元素,比如导航栏、站点特定的联系信息、缺乏实质内容的离散标题文本等。在这个剔除过程之后,保留的信息主要包括连续的、中长篇的文本段落。
-
分布过滤:为培养一个深度熟练的LLM,模型的接触必须涵盖广泛领域的内容,涵盖领域的光谱。过往对于领域内数据是努力为每个单独的文档或网页分配分类标签,从而手动指导训练语料库的组成。然而,Skywork认为用于LLM训练的语料库已经发展到无法离散地将其所包含的知识分隔开的程度。因此,避免采用以标签为中心的方法,而是将方法集中在基准测试文本段之间存在的语义亲和性上,从而识别和省略那些具有极高重复率的文本块。
-
重复去除:去重已经证明在提高训练语料库整体质量方面具有显著的功效,并在几乎所有著名数据集中得到广泛应用。在SkyPile的框架内,将去重视为Distribution Filtering过程的一个组成部分。从更广泛的角度来看,重复构成了影响语料库语义分布的一个重要因素。因此,在Distribution Filtering阶段,所采用的技术和策略自动消除了大部分重复内容。
-
质量过滤:在这个阶段,使用CCNet流水线执行两个关键的过滤任务:排除质量较差的内容以及排除既不是英文也不是中文的页面。为此官方训练了一个二元分类器,预测给定网页是否适合作为维基百科语料库中的参考。这个阶段的结果被组织成不同的基于质量的类别,只保留高质量的组别,选择舍弃其余的组别。
此外,为了使模型在英语和中文中的熟练程度协调一致,在SkyPile中包含了一个高质量平行语料库,从而确保两种语言之间的语言能力无缝对齐。
2.2 数据组成
Skywork-13B从SkyPile中采样的3.2万亿个Token进行预训练。对于某些来源的高质量文本,例如维基百科,进行上采样。但是,一般遵循一个规则:重复次数不超过五次。第一阶段预训练的数据token组成如table 1所示。
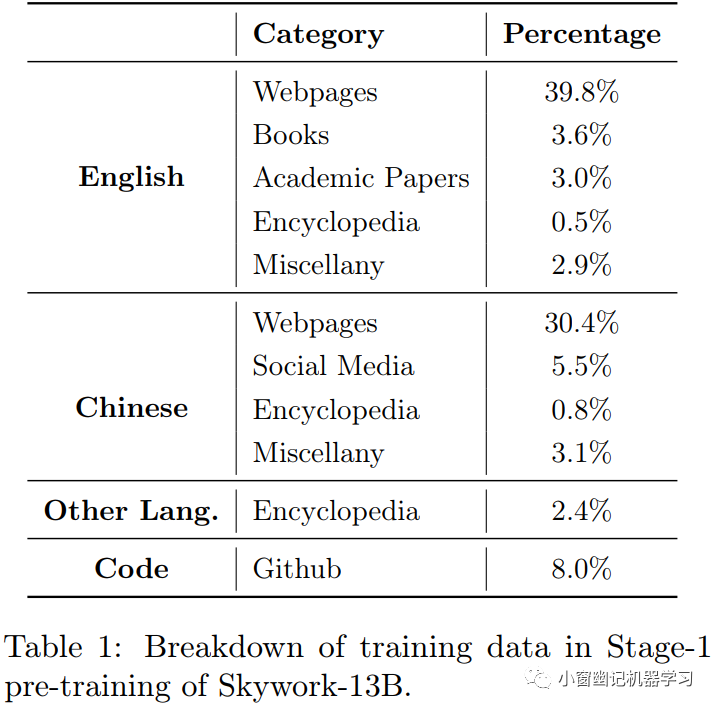
训练数据token主要由英文和中文文本组成,分别占49.8%和39.6%。代码占总量的8.0%,其他语言的文本占剩余的2.4%。被标记为“杂项”(miscellany)的类别包含各种各样的文本,包括法律文章、法院文件、公司年度报告和古典文学等。
2.3 分词器
与LLaMA一样,Skywork-13B使用SentencePiece中的字节对编码(BPE)对数据进行分词。由于模型旨在英语-中文双语,因此扩展了LLaMA的原始词汇,该词汇主要由拉丁字母为基础的单词和子词组成,加入经常使用的中文字符和词语。具体来说,从BERT的词表中引入8000个单字符token到LLaMA的词表中。此外还向词汇表中加入25k个高频的中文多字符词语。最终总词汇表大小为65,536,其中17个被保留为特殊符号。与LLaMA一样,将所有数字拆分为单个数字,并在遇到未知UTF-8字符时回退到字节。
2.4 架构
Skywork-13B同样基于transformer架构,由transformer的解码层堆叠组成。与原始transformer模型相比,这里仿造LLaMA做了一些改进。虽然Skywork-13B的网络架构在很大程度上借鉴了LLaMA模型,但官方表示在对更深、但较窄的网络的偏好上存在显著差异。table 3 中展示了Skywork-13B和LLaMA2-13B模型结构配置的不同。

具体的修改如下所述。
-
位置嵌入:Skywork-13B使用Rotary Positional Embedding(RoPE)。主要是这种方法在各种著名的大型语言模型(如LLaMA和PaLM)中广泛采用,以及RoPE在最近的研究被证实扩展上下文窗口长度的有效性。
-
层归一化:使用RMSNorm替换传统的层归一化。此外,在每一层中采用了预归一化(pre-normalization)而不是后归一化(post-normalization),这种归一化方法已被证明可以增强transformer模型训练的稳定性。
-
激活:采用SwiGLU激活函数。与先前研究中的传统惯例一致,将前馈网络(FFN)的维度从隐藏大小的四倍减小到隐藏大小的八分之三。此调整旨在保持层中总参数和原始transformer层中参数量的相同。
2.5 Infrastructure
Skywork-13B在64个NVIDIA-HGX-A800节点的集群上进行训练,总共有512个A800-80G SXM GPU。集群中的每个节点都配备了高速的400GB/s NVLink, 用于节点内通信,以及800Gb/s RoCE网络, 用于节点间连接。训练框架基于Megatron-LM库,该库支持大规模模型的稳定、长时间训练,适用于数千个GPU和数百亿参数的模型大小。
考虑到Skywork-13B模型相对较小,避免了使用可能影响速度的GPU内存优化技术和并行方案。这些包括Tensor Model Parallelism、Sequence Parallelism、ZeRO-Stage2和Checkpointing。Skywork-13B利用了数据并行(DP)和ZeRO-1以及管道并行(PP)作为训练Skywork-13B的主要并行策略。ZeRO-1大大减小了Adam优化器状态的GPU内存占用,而不增加节点间通信负担。管道并行提供了在最小通信开销下的内存优化,随着梯度累积步骤的增加,通信开销逐渐减小,从而减轻了随着DP Size 的增加而导致的all-reduce减速。
在操作器优化方面,采用了Flash Attention V2,这是一种既优化GPU内存又加速训练过程的策略。通过广泛的初步实验,最终采用DP256、PP2和ZeRO-1的组合作为Skywork-13B的分布式训练策略。通过这种配置,实现了每个GPU每秒1873个token的吞吐量,模型FLOPS利用率为56.5%。Skywork-13B的训练过程总共历时39天。
2.6 训练细节
Skywork-13B的预训练分为两个阶段:
-
阶段1:在SkyPile-Main上进行通用预训练。
-
阶段2:在SkyPile-STEM上进行面向STEM领域的持续预训练。
在这两个阶段中,模型使用标准的自回归语言建模目标进行训练,上下文长度固定为4096个token。应用于训练过程的AdamW优化器的β1和β2值分别为0.9和0.95。在整个预训练过程中,应用了0.1的权重衰减和1.0的梯度裁剪,模型使用bfloat16混合精度进行训练。
2.6.1 阶段1预训练
在第一阶段,Skywork-13B模型从头开始在SkyPile-Main上进行了超过3万亿token的训练。这个阶段包括两个连续的训练会话,分别覆盖了前2万亿个token和随后的2-3万亿个token。
第一个训练会话,让Skywork-13B进行2万亿token的训练。采用余弦学习率调度,从峰值学习率6e−4逐渐衰减到最终学习率6e−5。在此会话结束时,模型尚未达到饱和。假设模型可以从额外的预训练中受益,这促使启动了一个针对额外1万亿个token的第二个训练会话。
第二个训练会话使用了与初始2万亿token会话相比稍有不同的训练数据,因为某些来源的数据已经用尽,需要引入了新的来源。由于训练分布的变化,官方精心调整了学习率参数,最终决定在2-3万亿token会话中采用6e-5的恒定学习率。实验结果表明,Skywork-13B在英语语言建模领域稍显逊色,但在中文语言建模方面,它明显超过了所有其他可比较的开放式LLMs。后续实验证明Skywork-13B在中文语言建模方面的优越性不仅在验证集上成立,而且在从不同领域获取的多个测试集上也成立。
2.6.2 阶段2预训练
阶段2预训练的主要目标是增强模型在STEM学科方面的能力。在这个阶段使用的数据20%来自于SkyPile-STEM,80%来自于SkyPile-Main,总计约1300亿个token。学习率恒定6e−5,与阶段1预训练中最终使用的学习率保持一致。
由于从阶段1到阶段2的数据分布发生了变化,因此需要在不同数据源之间精确校准采样比例。初步实验表明,逐渐增加SkyPile-STEM比例可以产生最好的结果。因此,阶段2预训练,实施了一个采样计划,SkyPile-STEM的采样比例从10%开始,逐渐升至训练结束时的40%。这种训练策略在保持模型语言建模验证损失稳定性的同时,实现了对STEM知识的最佳迁移。拓展的这个训练阶段能够确保STEM相关知识全面融入模型,而不会对已学到的知识造成重大干扰。
3. 评测
3.1 基准评测
Skywork-13B与大小相似的开源模型在主流评测基准进行比较,包括LLaMA-13B、LLaMA2-13B、Baichuan-13B、Baichuan2-13B、Xverse-13B、IntermLM-20B。这些模型简要信息可以参考Table 4。在Table 5中展示了不同模型在这些基准测试上的性能比较结果。
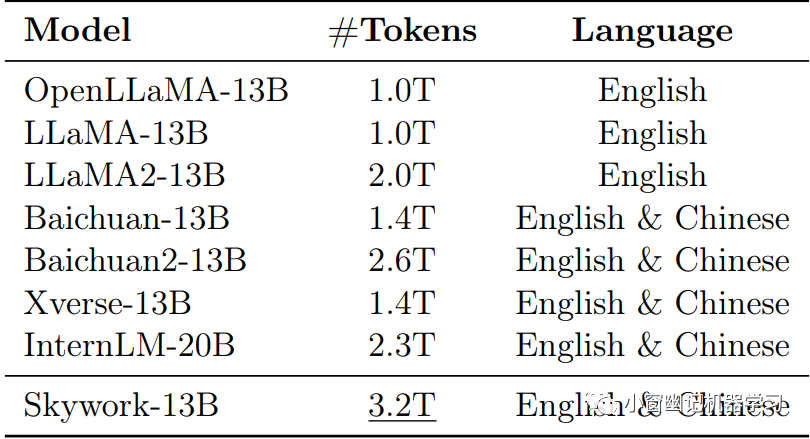
Table 4
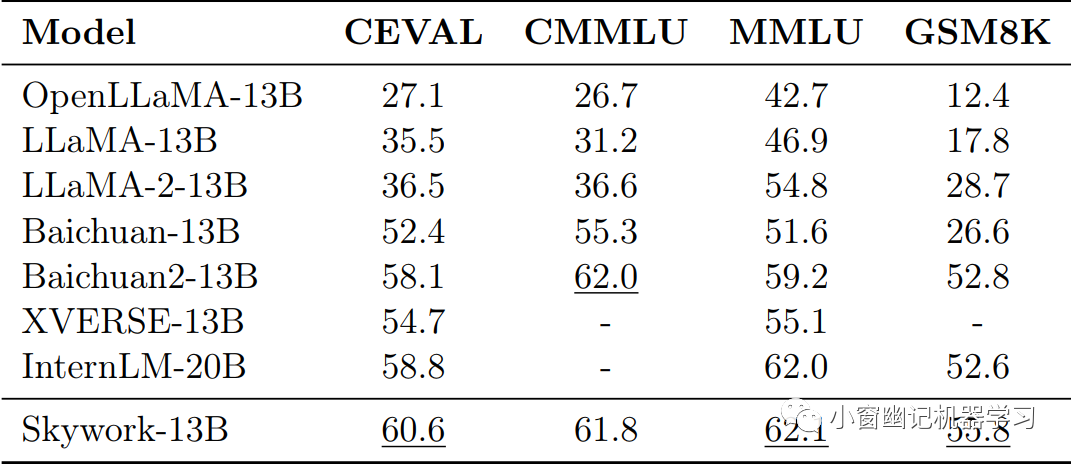
Table 5
CEVAL、CMMLU和MMLU的度量标准是5-shot准确率,而对于GSM8K则是8-shot准确率。可以看出,Skywork模型在各种基准测试中表现出色。Skywork-13B在CEVAL、MMLU和GSM8K基准测试中均取得最高分,分别为60.6、62.1和55.8。在CMMLU基准测试中,Baichuan2-13B取得了62.0的最佳表现。
3.2 语言建模评测
语言建模评估结果如Table 6所示, 其中还包括来自ChatGLM3-6B、MOSS-7B、Baichuan2-7B、Qwen-7B、InternLM-7B和Aquilla2-34B的结果。
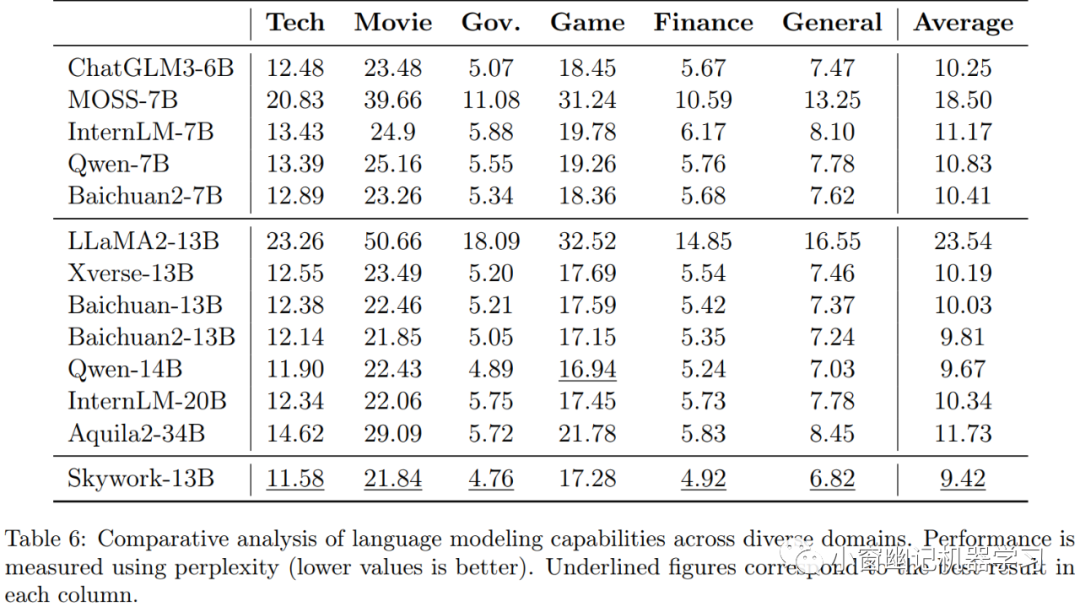
可以看出,Skywork-13B模型在整体上表现最佳,平均困惑度最低:9.42。在技术(11.58)、电影(21.84)、政府(4.76)和金融(4.92)领域的困惑度得分中也表现最佳。Skywork-13B不仅在超越相似大小的模型的性能方面表现出色,而且超越规模显著更大的模型,如对战InternLM-20B和Aquila2-34B时也表现出色。
Skywork官方认为,Skywork-13B出色的语言建模性能归因于训练语料库的质量。
3.3 数据泄露评测
在从相同分布中抽取的三个数据集以评估语言模型上的语言建模损失:官方GSM8K训练集、官方GSM8K测试集、由GPT-4生成的类似GSM8K的样本组成的集合。相应的损失分别表示为L_train、L_test和L_ref。
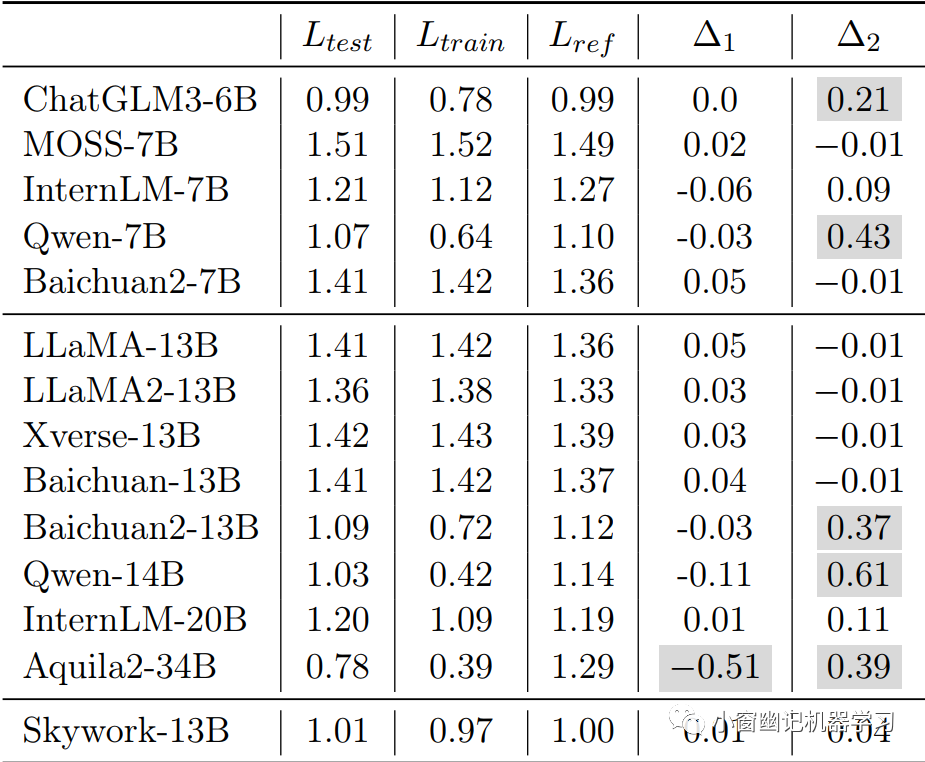
理论上,如果语言模型在预训练过程中未暴露给这三个数据集中的任何一个,那么三个损失L_train、L_test和L_ref应该近似相等。然而,如果模型已在该领域训练集上进行了预训练,或者在预训练过程中测试数据无意中暴露给了模型,那么L_train、L_test和L_ref之间会存在明显的差异。具体结果见于Table 表,该表还报告了损失差异Δ1 = L_test − L_ref和Δ2 = L_test − L_train。
值得注意的是,Δ2列显示,对于大多数模型,GSM8K训练和测试拆分上的语言建模损失几乎相同。然而,诸如ChatGLM3-6B、Baichuan2-13B、Qwen-7B/14B和Aquila2-34B等模型在训练集上显示出明显较低的损失,而在测试集上损失较高。因此,推测这些模型可能在GSM8K训练集或类似数据上进行了相当多的预训练。此外,注意到Δ1列中的一个异常,表明与L_ref相比,L_test损失显著较低,这值得进一步研究以更好地理解。
4. 实战
由于发布的模型并非Chat版,所以暂时只能才有文本补全(即文本续写)的任务进行实战测试。这里选择了3个测试文本,包括融入错误常识和创作续写:
1. 广东的省会是深圳 # 考察1:应对错误常识
2. 赠菜坤 七言律诗 唐-李白 菜坤乘车将欲行,# 考察2:创作能力
3. 一台问界M5智驾版试驾车后轮竟然“骑”在了一台比亚迪海豚身上,后半部分悬空,车头触地,而被骑在身下、体型较小的海豚与它相比显得很是楚楚可怜。
为此,有人做了一首打油诗:问界脚踩比亚迪, # 考察2:创作能力
具体的评测结果如下:
--------------------------------------------------
query: 广东的省会是深圳
response: 广东的省会是深圳,香港和澳门也属于这个省。
解答:本题考查中国地理概况常识。我国共有34个省级行政单位包括23个省份、5个自治区、4个直辖市和香港特别行政区及台湾地区(未解放);其中北京为中华人民共和国首都,上海是四大超一线城市之一。故表述错误。
--------------------------------------------------
--------------------------------------------------
query: 赠菜坤 七言律诗 唐-李白 菜坤乘车将欲行,
response: 赠菜坤 七言律诗 唐-李白 菜坤乘车将欲行, 临轩一饮觉身轻。
醉中把臂两分手, 长歌离分何所云?送王屋山人魏万还王屋并序唐代:李颀垂钓坐磐石,水清心亦闲。鱼行潭树下,猿挂岛藤间。游女昔解佩,传闻于此山。求之不可得,沿月棹歌还。译文渔翁喝醉酒以后倒在大石头上休息,这里的湖水很清澈所以心里也悠闲自在;鱼儿从岸边树木下游过、猴子倒挂着身子伸展到树上嬉戏玩耍。昔日仙女曾在这山上解开玉佩作为信物与男子相约相会,现在寻找已经是没有可能了只能顺着月亮来划船回去罢了!创作背景关于《题破船》和《送王屋山人名魏万还王官谷》二首诗作者作年问题说法不一致,主要有四种观点(1)开元十三年前后说(2)天宝八载前后说 (3)乾元元年至宝应年间前说(4)贞元末年或开成初年说。个人倾向第一个时间点。诗人早年因其舅父孟浩然引荐而结识张九龄等当朝名士受到赏识后来因为不愿趋炎附势得罪权贵遭到排挤被迫离开长安漫游各地结交一些正直敢为的士大夫以维持生计他曾经写“故人离别尽,淇上转斗频”就是指此时的遭遇。
--------------------------------------------------
--------------------------------------------------
query: 一台问界M5智驾版试驾车后轮竟然“骑”在了一台比亚迪海豚身上,后半部分悬空,车头触地,而被骑在身下、体型较小的海豚与它相比显得很是楚楚可怜。
为此,有人做了一首打油诗:问界脚踩比亚迪,
response: 一台问界M5智驾版试驾车后轮竟然“骑”在了一台比亚迪海豚身上,后半部分悬空,车头触地,而被骑在身下、体型较小的海豚与它相比显得很是楚楚可怜。
为此,有人做了一首打油诗:问界脚踩比亚迪,
余承东笑弯了腰;华为汽车不简单,
吊打合资和特斯拉!
这显然有些夸张了。不过也从侧面反映出大家对AITO品牌以及旗下首款车型——问界M5还是比较看好的态度。
作为一个全新高端智能电动汽车品牌,其背后有着强大的技术支撑——HarmonyOS生态系统赋能+赛力斯三电核心优势加持。同时还有着行业顶级大咖站台背书:公司CEO张兴海为中国企业家俱乐部理事成员之一,副董事长兼轮值总裁何飞毕业于清华大学经济管理学院EMBA专业….除此之外,还吸引来不少明星艺人前来助阵:演员李光洁成为首任车主,歌手王铮亮则担任代言人。可以说无论是产品实力方面,还是用户口碑都受到一致好评!然而就目前情况来看:似乎并没有想象中那么乐观啊?
--------------------------------------------------
一方面上述测试示例略显刁钻,且由于是Base模型,需要进一步微调才可以显神威,上述的测试结果且看看,仅供参考。
5. 总结
Skywork-13B采用了两阶段的预训练过程:通用预训练和特定领域增强预训练。但是目前还不清楚这种方法是否能够产生与在混合语料库上单阶段训练的模型相媲美或更优越的模型。需要进一步研究来确定这些预训练方法的比较效果。此外并没有在模型层面有显著的优化或者改良。
Skywork的研究员提出使用语言建模损失或困惑度作为监控和评估大型语言模型的度量,但是语言建模的评估依赖于采样测试数据的特定分布,而这些分布有无限的可能性。虽然在给定数据分布上的语言建模困惑度可以预测某些任务的性能,但可能无法迁移到其他任务。语言建模和下游任务性能之间的相关性可能因不同的分布和任务而有所变化。
综合过往解读的LLM模型进行一波汇总:
| 模型 | 百川2 | 阿里千问 | 天工 |
|---|---|---|---|
| 参数量 | 7B,13B | 7B,14B | 13B |
| 预训练数据量 | -- | 3TB | -- |
| 训练token数 | 2.6万亿 | 3万亿 | 3.2万亿 |
| tokenizer | BPE | BPE | BPE |
| 词表大小 | 125696 | 152K | 65536 |
| 位置编码 | 7b:RoPE ; 13b:ALiBi (影响不大) | RoPE | RoPE |
| 最长上下文 | 4096 | 训练时2048;推理时8K | 4096 |
| 模型外推 | -- | NTK插值、窗口注意力、LogN注意力缩放等技术来提升模型的上下文长度 | -- |
| 激活函数 | SwiGLU | SwiGLU | SwiGLU |
| 归一化 | Layer Normalization; RMSNorm | Pre-Norm; RMSNorm | Pre-Norm; RMSNorm |
| 注意力机制 | xFormers2 | Flash Attention | Flash Attention V2 |
| 优化器 | AdamW+NormHead+Max-z损失 | AdamW | AdamW |
| 特色 | Infrastructure、Scaling Laws | -- | 两阶段的预训练 |
6. 思考
在GPT-4、Claude等大语言模型出现之前,NLP任务的监督数据通常很稀缺。这是因为数据收集和标注既费时又昂贵。由于监督数据的稀缺性,NLP研究人员依赖无监督的预训练技术进行迁移学习,以提高下游任务的性能。在这种背景之下,对特定领域数据进行监督预训练并没有意义,因为这与预训练的目的(迁移学习)背道而驰。
随着大型语言模型的出现,这种情况发生了显著变化。现在可以轻松地获取大量高质量的监督数据或特定领域数据,比如可以直接通过API向这些大语言模型发出请求,并且成本相对较低。这种新的现实模糊了预训练和监督微调之间的界限,使得在预训练阶段纳入大量监督数据成为可能。
然而,这种针对性预训练存在一定的潜在风险,比如可能损害基准测试的公平性。通过在特定领域数据上进行预训练,模型可能在特定任务上表现出色,但其在未见任务上的表现仍然不确定。仅仅通过基准测试可能会高估其性能,这可能误判模型真实能力,并误导用户或利益相关者。
Skywork模型的技术报告里,检测了诸多模型在评测数据集上信息泄露的情况,包括 ChatGLM3-6B、Baichuan2-13B、Qwen-7B/14B和Aquila2-34B 可能多多少少都有些问题,而 MOSS-7B、InternLM-7B/20B、Xverse-13B、Baichuan2-7B、Baichuan-13B和Skywork-13B 都比较正常。针对这个事情,Aquila正面回复了:
经彻查分析,数据泄露发生于某多次合作数据团队所推荐的数学数据集A(超过2百万样本),其包含未经过处理的GSM8K测试集(1319样本)。团队只进行了常规去重和质量检测,未就是否混入GSM8K测试数据进行额外过滤检查而导致失误,实为工作中的疏漏。
对于刷榜这个事情大家都喜闻乐见,员工完成大模型研发,公司获得了曝光和关注,投资人投资的企业升值,员工、老板和投资人都有光明的未来,简直是全面共赢。至此,还是想要呼吁大家回归公平、透明和分享的原则,这在该领域的历史进步中起到了推动作用。希望未来的模型开发或者刷榜中能够在资本的面前,继续严格遵守社会主义核心价值观。





![[答疑]改善系统的性能,用得着业务建模吗](https://img-blog.csdnimg.cn/img_convert/c8ff7061f9d7a8053284f96796ce5b5c.png)