一、介绍
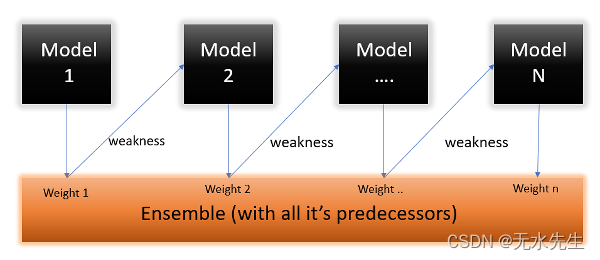
Boosting 是一种集成建模技术,由 Freund 和 Schapire 于 1997 年首次提出。从那时起,Boosting 就成为解决二元分类问题的流行技术。这些算法通过将大量弱学习器转换为强学习器来提高预测能力 。
Boosting 算法背后的原理是,我们首先在训练数据集上构建一个模型,然后构建第二个模型来纠正第一个模型中存在的错误。继续此过程,直到且除非错误被最小化并且数据集被正确预测。Boosting 算法以类似的方式工作,它结合多个模型(弱学习器)来达到最终输出(强学习器)。
学习目标
- 了解 AdaBoost 算法是什么及其工作原理。
- 了解什么是树桩。
- 了解增强算法如何帮助提高 ML 模型的准确性。
本文作为数据科学博客马拉松的一部分发表
目录
- 介绍
- 什么是 AdaBoost 算法?
- 了解 AdaBoost 算法的工作原理
- 第 1 步:分配权重
- 第 2 步:对样本进行分类
- 步骤 3:计算影响力
- 第 4 步:计算 TE 和性能
- 第 5 步:减少错误
- 第 6 步:新数据集
- 第 7 步:重复前面的步骤
- 结论
- 经常问的问题
二、什么是 AdaBoost 算法?
有许多机器学习算法可供选择用于您的问题陈述。其中一种用于预测建模的算法称为 AdaBoost。
AdaBoost 算法是 Adaptive Boosting 的缩写,是 一种在机器学习中用作集成方法的 Boosting 技术。它被称为自适应提升,因为权重被重新分配给每个实例,更高的权重分配给错误分类的实例。

该算法的作用是构建一个模型并为所有数据点赋予相同的权重。然后,它为错误分类的点分配更高的权重。现在,所有权重较高的点在下一个模型中都会变得更加重要。它将继续训练模型,直到收到较低的错误为止。
让我们举个例子来理解这一点,假设您在泰坦尼克号数据集上构建了一个决策树算法,并且从那里您获得了 80% 的准确率。之后,您应用不同的算法并检查准确性,结果显示 KNN 为 75%,线性回归为 70%。
当我们在同一数据集上构建不同的模型时,我们发现准确性有所不同。但是如果我们使用所有这些算法的组合来做出最终预测呢?通过取这些模型结果的平均值,我们将获得更准确的结果。我们可以通过这种方式来提高预测能力。
如果您想直观地理解这一点,我强烈建议您阅读这篇文章。
这里我们将更加关注数学直觉。
还有另一种集成学习算法称为梯度提升算法。在此算法中,我们尝试减少误差而不是权重,如 AdaBoost 中那样。但在本文中,我们将仅关注 AdaBoost 的数学直觉。
三、了解 AdaBoost 算法的工作原理
让我们通过以下教程了解该算法的原理和工作原理。
第 1 步:分配权重
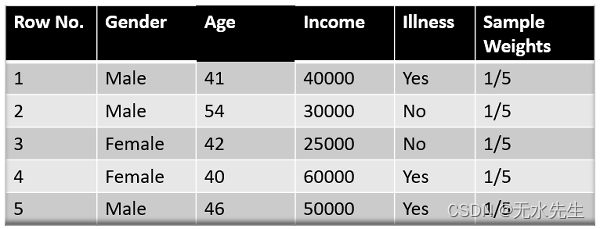
下面显示的图像是我们数据集的实际表示。由于目标列是二元的,因此这是一个分类问题。首先,这些数据点将被分配一些权重。最初,所有权重都是相等的。
样本权重的计算公式为:

其中 N 是数据点的总数
这里由于我们有 5 个数据点,因此分配的样本权重将为 1/5。
第 2 步:对样本进行分类
我们首先查看“性别”对样本进行分类的效果如何,然后查看变量(年龄、收入)如何对样本进行分类。
我们将为每个特征创建一个决策树桩,然后计算每棵树的基尼指数。基尼指数最低的树将是我们的第一个树桩。
在我们的数据集中,假设性别具有最低的基尼指数,因此它将是我们的第一个树桩。
第 3 步:计算影响力
现在,我们将使用以下公式计算该分类器在对数据点进行分类时的“发言量”或“重要性”或“影响力” :
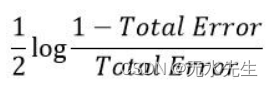
总误差只不过是错误分类的数据点的所有样本权重的总和。
在我们的数据集中,我们假设有 1 个错误的输出,因此我们的总误差将为 1/5,并且 alpha(树桩的性能)将为:
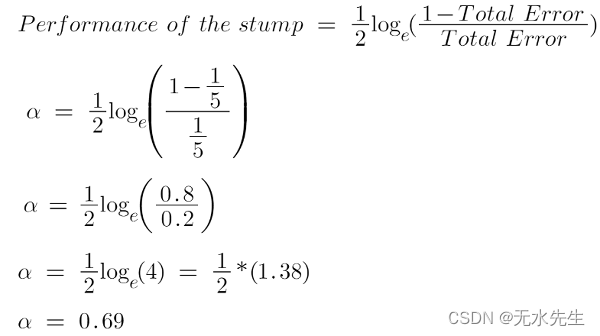
注意:总误差始终在 0 和 1 之间。
0 表示完美的树桩,1 表示糟糕的树桩。
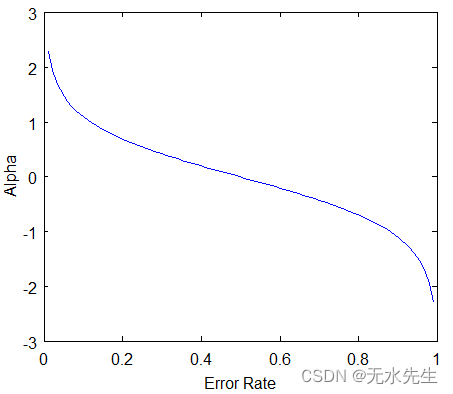
从上图中,我们可以看到,当没有错误分类时,我们就没有错误(Total Error = 0),因此“a amount of say (alpha)”将是一个很大的数字。
当分类器预测一半正确一半错误时,则总误差 = 0.5,并且分类器的重要性(可以说)将为 0。
如果所有样本都被错误分类,那么错误将非常高(大约为 1),因此我们的 alpha 值将是负整数。
第 4 步:计算 TE 和性能
您一定想知道为什么需要计算树桩的 TE 和性能。答案很简单,我们需要更新权重,因为如果将相同的权重应用于下一个模型,那么收到的输出将与第一个模型中收到的输出相同。
错误的预测将被赋予更高的权重,而正确的预测权重将被降低。现在,当我们在更新权重后构建下一个模型时,将更优先考虑权重较高的点。
在找到分类器的重要性和总误差后,我们最终需要更新权重,为此,我们使用以下公式:
![]()
当样本被正确分类时,例如(alpha)的数量将为负。
当样本被错误分类时,例如(alpha)的量将为正。
有 4 个正确分类的样本,1 个错误分类的样本。这里, 该数据点的样本权重是1/5,性别树桩的发言/表现 量是0.69。
正确分类样本的新权重为:
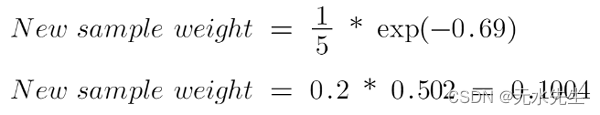
对于错误分类的样本,更新后的权重为:
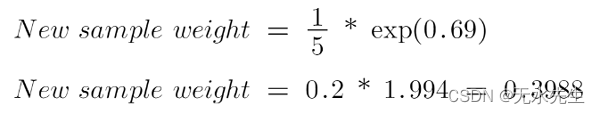
笔记
当我输入值时请查看 alpha 的符号,当数据点正确分类时alpha 为负,这会将样本权重从 0.2 降低到 0.1004。当存在错误分类时为正,这会将样本权重从 0.2 增加到 0.3988
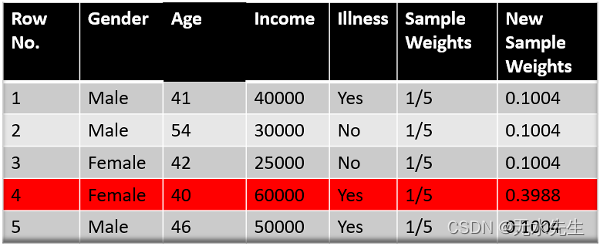
我们知道样本权重的总和必须等于 1,但是这里如果我们将所有新样本权重相加,我们将得到 0.8004。为了使这个总和等于 1,我们将所有权重除以更新权重的总和(即 0.8004)来标准化这些权重。因此,对样本权重进行归一化后,我们得到了这个数据集,现在总和等于 1。

第 5 步:减少错误
现在,我们需要创建一个新的数据集来查看错误是否减少。为此,我们将删除“样本权重”和“新样本权重”列,然后根据“新样本权重”将数据点划分为多个桶。
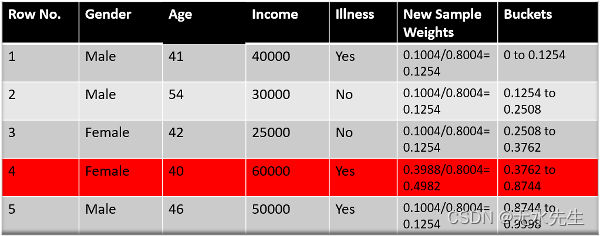
第 6 步:新数据集
我们快完成了。现在,该算法所做的是从 0-1 中选择随机数。由于错误分类的记录具有较高的样本权重,因此选择这些记录的概率非常高。
假设我们的算法采用的 5 个随机数是 0.38,0.26,0.98,0.40,0.55。
现在我们将看到这些随机数落在桶中的位置,并根据它,我们将制作如下所示的新数据集。
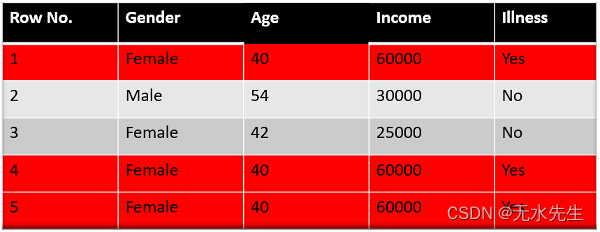
这是我们的新数据集,我们看到错误分类的数据点已被选择 3 次,因为它的权重较高。
第 7 步:重复前面的步骤
现在这作为我们的新数据集,我们需要重复上述所有步骤,即
- 为所有数据点 分配相同的权重。
- 通过查找基尼指数并选择基尼指数最低的树桩,找到对新样本集合进行分类的最佳树桩。
- 计算“Amount of Say”和“Total error”来更新之前的样本权重。
- 标准化新样本权重。
迭代这些步骤,直到达到较低的训练误差。
假设对于我们的数据集,我们按顺序构建了 3 个决策树(DT1、DT2、DT3) 。如果我们现在发送测试数据,它将通过所有决策树,最后,我们将看到哪个类占多数,并基于此,我们将对
测试数据集进行预测。
四、结论
如果你理解了本文的每一行,你就终于掌握了这个算法。
我们首先向您介绍什么是 Boosting 以及它的各种类型,以确保您了解 Adaboost 分类器以及 AdaBoost 的准确位置。然后我们应用简单的数学并了解公式的每个部分是如何工作的。
在下一篇文章中,我将解释梯度下降和极限梯度下降算法,它们是一些更重要的增强预测能力的Boosting技术。
如果您想从头开始了解 AdaBoost 机器学习模型初学者的 Python 实现,请访问Analytics vidhya 的完整指南。本文提到了bagging和boosting的区别,以及AdaBoost算法的优缺点。
点
- 在本文中,我们了解了 boosting 的工作原理。
- 我们了解 adaboost 背后的数学原理。
- 我们了解了如何使用弱学习器作为估计器来提高准确性。
五、常见的问题
答:Adaboost 属于机器学习的监督学习分支。这意味着训练数据必须有一个目标变量。使用adaboost学习技术,我们可以解决分类和回归问题。
答:需要较少的预处理,因为您不需要缩放自变量。AdaBoost 算法中的每次迭代都使用决策树桩作为单独的模型,因此所需的预处理与决策树相同。AdaBoost 也不太容易出现过度拟合。除了增强弱学习器之外,我们还可以微调这些集成技术中的超参数(例如learning_rate)以获得更好的准确性。
答:与随机森林、决策树、逻辑回归和支持向量机分类器非常相似,AdaBoost 也要求训练数据具有目标变量。该目标变量可以是分类变量或连续变量。scikit-learn 库包含 Adaboost 分类器和回归器;因此我们可以使用Python中的sklearn来创建adaboost模型。