一、介绍
EfficientNet 是深度学习领域的里程碑,代表了神经网络架构方法的范式转变。EfficientNet 由 Google Research 的 Mingxing Tan 和 Quoc V. Le 开发,在不影响性能的情况下满足了对计算高效模型不断增长的需求。本文深入探讨了 EfficientNet 背后的关键原理、其架构以及它对深度学习领域的影响。
EfficientNet:开创了模型效率时代,计算能力与优雅相结合,通过节省足迹将性能提升到新的高度,彻底改变深度学习。
二、背景
多年来,随着深度学习模型规模的增加,与训练和部署这些模型相关的计算成本也随之增加。计算需求的激增给资源利用、能源消耗以及处理能力有限的设备上的部署带来了重大挑战。为了应对这些挑战,EfficientNet 作为实现最佳模型效率的开创性解决方案应运而生。
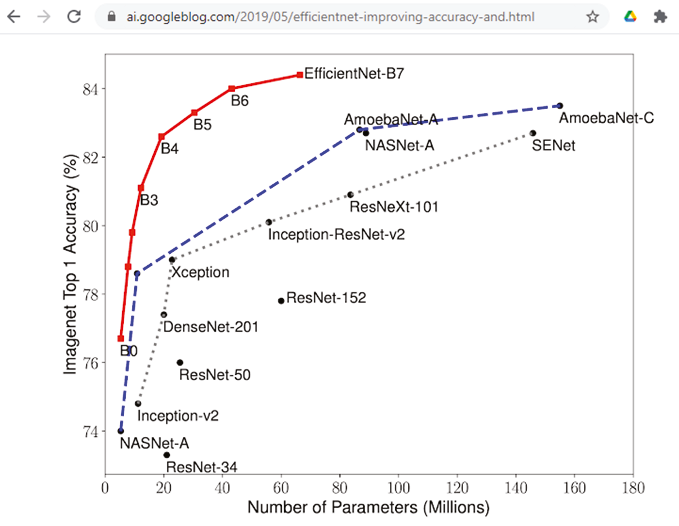
三、EfficientNet核心原理
EfficientNet 通过一种新颖的复合缩放方法来实现其效率,其中模型的深度、宽度和分辨率同时缩放。这种方法可确保模型在不同维度上变得更加高效,而不会牺牲性能。主要原则可概括如下:
- 复合缩放:EfficientNet 引入了一种复合缩放方法,可以统一缩放网络的深度、宽度和分辨率。这种方法可以实现资源的平衡分配,确保模型在各个计算方面都高效。通过联合优化这三个维度,EfficientNet 实现了比传统缩放方法更优越的性能。
- 神经架构搜索(NAS):EfficientNet的架构不仅仅是手工设计的结果,还涉及到神经架构搜索的使用。这个自动化过程探索可能架构的巨大搜索空间,以发现最有效的组合。NAS 有助于模型对不同任务和数据集的适应性。
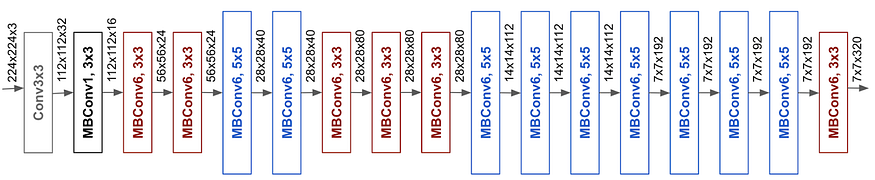
四、构筑
EfficientNet 的特点是称为 EfficientNet-B0 的基线架构。随后的模型(表示为 EfficientNet-B1 至 EfficientNet-B7)代表了基线的放大版本。系统地增加深度、宽度和分辨率,以保持效率,同时增强模型的容量。该架构包括反向瓶颈模块、挤压和激励模块以及其他优化技术,以进一步提高性能。
五、对深度学习的影响
EfficientNet 极大地影响了深度学习的格局,为资源受限的场景提供了一种不妥协的解决方案。它的影响可以在各个领域观察到:
- 资源效率: EfficientNet 为在计算资源有限的边缘设备上部署最先进的模型打开了大门,使得在资源效率至关重要的场景中可以进行深度学习。
- 迁移学习: EfficientNet 的效率使其成为迁移学习任务的热门选择。大型数据集上的预训练模型可以针对特定应用进行微调,从而在下游任务中实现更快的收敛和更好的性能。
- 可扩展性: EfficientNet 引入的复合扩展原理启发了其他领域高效模型的开发,促进了可扩展和高效神经网络架构的更广泛趋势。
六、代码
为 EfficientNet 创建完整的 Python 代码(包括数据集处理和绘图)将会非常广泛,并且可能会根据您想要的特定用例或数据集而有所不同。不过,我可以为您提供一个使用 TensorFlow 和 Keras 执行 CIFAR-10 数据集分类任务的简化示例。
请确保您已安装 TensorFlow:
pip install tensorflowimport tensorflow as tf
from tensorflow.keras import layers, models
from tensorflow.keras.datasets import cifar10
from tensorflow.keras.utils import to_categorical
import matplotlib.pyplot as plt
# Load and preprocess the CIFAR-10 dataset
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0 # Normalize pixel values to between 0 and 1
y_train, y_test = to_categorical(y_train), to_categorical(y_test)
# Define EfficientNet model using TensorFlow and Keras
def build_efficientnet():
base_model = tf.keras.applications.EfficientNetB0(include_top=False, input_shape=(32, 32, 3), weights='imagenet')
model = models.Sequential()
model.add(base_model)
model.add(layers.GlobalAveragePooling2D())
model.add(layers.Dense(10, activation='softmax')) # 10 classes for CIFAR-10
return model
# Compile the model
model = build_efficientnet()
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
# Train the model
history = model.fit(x_train, y_train, epochs=10, validation_data=(x_test, y_test))
# Plot training history
def plot_history(history):
plt.plot(history.history['accuracy'], label='accuracy')
plt.plot(history.history['val_accuracy'], label = 'val_accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.ylim([0, 1])
plt.legend(loc='lower right')
plt.show()
plot_history(history)Downloading data from https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz
170498071/170498071 [==============================] - 4s 0us/step
Downloading data from https://storage.googleapis.com/keras-applications/efficientnetb0_notop.h5
16705208/16705208 [==============================] - 0s 0us/step
Epoch 1/10
1563/1563 [==============================] - 504s 292ms/step - loss: 1.3704 - accuracy: 0.5261 - val_loss: 2.4905 - val_accuracy: 0.1014
Epoch 2/10
1563/1563 [==============================] - 420s 269ms/step - loss: 0.9050 - accuracy: 0.6939 - val_loss: 3.1378 - val_accuracy: 0.1823
Epoch 3/10
1563/1563 [==============================] - 417s 267ms/step - loss: 0.7452 - accuracy: 0.7534 - val_loss: 2.6976 - val_accuracy: 0.2337
Epoch 4/10
1563/1563 [==============================] - 423s 271ms/step - loss: 0.6388 - accuracy: 0.7845 - val_loss: 2.8459 - val_accuracy: 0.1197
Epoch 5/10
1563/1563 [==============================] - 423s 271ms/step - loss: 0.5644 - accuracy: 0.8112 - val_loss: 3.8598 - val_accuracy: 0.1005
Epoch 6/10
1563/1563 [==============================] - 418s 268ms/step - loss: 0.5156 - accuracy: 0.8244 - val_loss: 2.8828 - val_accuracy: 0.1068
Epoch 7/10
1563/1563 [==============================] - 420s 268ms/step - loss: 0.4453 - accuracy: 0.8498 - val_loss: 3.7792 - val_accuracy: 0.0870
Epoch 8/10
1563/1563 [==============================] - 425s 272ms/step - loss: 0.4123 - accuracy: 0.8608 - val_loss: 3.6623 - val_accuracy: 0.1248
Epoch 9/10
1563/1563 [==============================] - 424s 271ms/step - loss: 0.3715 - accuracy: 0.8746 - val_loss: 4.8576 - val_accuracy: 0.1023
Epoch 10/10
1563/1563 [==============================] - 426s 273ms/step - loss: 0.3379 - accuracy: 0.8853 - val_loss: 4.7601 - val_accuracy: 0.1156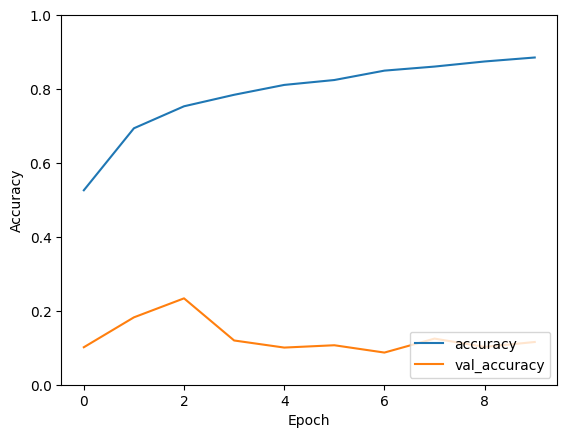
注意:这是一个简化的示例,在实际场景中,您可能需要根据您的具体要求调整代码,例如处理数据增强、微调等。此外,请确保安装任何所需的库并根据您的数据集和任务调整代码。
七、结论
EfficientNet 证明了深度学习模型不断进化以提高效率。通过解决计算成本和资源利用的挑战,EfficientNet 已成为开发模型的基石,这些模型不仅功能强大,而且适用于广泛的应用。它对该领域的影响引发了对高效神经网络架构的进一步研究,为深度学习更可持续和更容易的未来铺平了道路。



![C# 之 选择并调用文件[winform]](https://img-blog.csdnimg.cn/8b3a91c3cbe5410fab7fa4ddffaa4182.png)

![[C国演义] 第二十章](https://img-blog.csdnimg.cn/c46ade59f9e546c0b1432ab3c4e23044.png)