作者|李文,自如-质量中心
来源|自如技术公众号
![]()
背景
引用:根据2008年Aberdeen Group的研究报告,对于Web网站,1秒的页面加载延迟相当于少了11%的PV(page view),相当于降低了16%的顾客满意度。如果从金钱的角度计算,就意味着:如果一个网站每天挣10万元,那么一年下来,由于页面加载速度比竞争对手 慢1秒,可能导致总共损失25万元的销售额。
Compuware公司分析了超过150个网站和150万个浏览页面,发现页面响应时间从2秒增长到10秒,会导致38%的页面浏览放弃率。由此可见,网站性能与业务目标有着直接的关系,对网站进行性能测试非常重要。
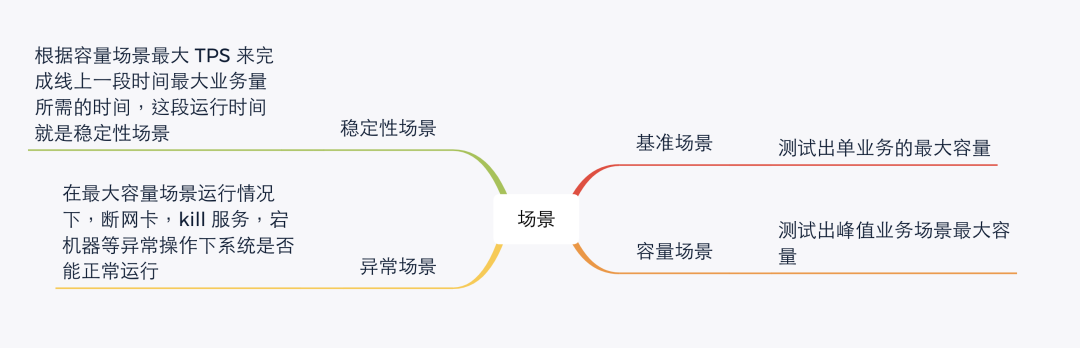
做性能测试的同学都知道性能执行中有很多场景,每个企业还会有自己定义的场景名词在这里就不列举,我做性能一般使用四个场景(基准场景、容量场景、稳定性场景、异常场景)来覆盖一个性能需求。下面聊一聊这四个场景怎么落地怎么覆盖性能需求。
![]()
实际落地
在聊四个场景之前我们先聊下性能测试一般流程,流程就是规则,在孟子-《离娄章句上》:"离娄之明,公输子之巧,不以规矩,不能成方圆"。有这个流程后遇到性能测试就不会乱手脚,就可以按这个流程开展工作。

关于每个动作需要做什么内容,做性能测试的人一看就知道需要做什么内容,在这里就不展开说明具体内容。我们做好前置条件后,就可以开展场景设计与执行,对于性能分析就不在这节课讲解,这里使用 Jmeter 压力工具、 TPS 是指 Jmeter 中Summary Report 组件中的 Throughput 值、后端接口不考虑前端页面js、css等页面元素加载时间,在具体做性能测试中也可以使用其他压力工具做,没有限制用什么压力工具,这里主要讲解场景怎么使用。
![]()
基准场景
基准场景就是单个接口进行压测,如果这样讲解谁都知道,那么我们应该怎么做基准场景呢?
-
环境准备
在互联网企业做性能测试一般都选择在线上进行压测,都知道搭建一套与线上一致的压测环境成本比较高如硬件成本、软件成本、人力成本、维护成本等等所以互联网企业选择线上做压测。 对于不是一线互联网企业或者传统行业一般都是在测试环境中做压测,我待过的银行保险就有自己的压测环境,他们的环境相对来说比较独立,做压测,做调优相对来说比较方便。
在测试环境中压测建议机器配置与线上机器配置一致,应用容器配置也得与线上环境一致,只有这样压测出来的结果才真实,说白了就是压测环境与线上环境需要一致,如果不能一致需要按一定比例做缩容。
-
数据准备
对于数据准备我们需要考虑压测环境中的铺垫数据量,一般铺垫数据来源脱敏后的真实生存库数据,在压测开始前需要把数据库备份,方便做问题排查,问题定位等等。如果数据量与线上数据量不一致,会导致压测结果不可信,大家可以思考下一个几百条数据库与线上百万,千万条数据库在性能上面根本不是一个级别的事情,所以在压测时候需要考虑压测环境中铺垫数据量。
-
参数准备
在做性能压测脚本时我们需要准备参数化数据,很多人觉得做性能测试几条数据就够,不需要大量数据做性能测试,这样就会导致压力与真实生存环境不一致,比如,几十条数据操作出千万级乃至亿级业务,这样压测出来的场景可信度就不好说。那么到底多少参数设置合理呢?
要回答这个问题需要确定参数化用在什么场景,因为场景不一样,参数化数据也不一样,假如不考虑场景情况下,100个线程,TPS 为800,系统运行1小时,数据类型、限制条件和数量计算方式如下:
假如把场景考虑进来我们就根据实际业务场景来分析用到什么样的数据,以便计算参数化数据量,这里的数据包括重复与不重复的数据,这里用我司统一登录做举例说明,对于登录业务需要两个参数一个是账号,一个是密码(这不考虑通过验证码登录)账号与密码必须可登录系统的否则不能完成后续业务操作,很显然不同人一定用不同账号登录。
➢ 场景一
我们在做脚本的时候,有多少线程就配置多少个用户,让每个线程用同一用户循环执行业务操作,但是这样的参数配置只能满足特定业务场景,比如早上登录后一直不退出,一直带着 token 操作业务,到下班退出系统,这样的场景我们有多少线程就需要准备多少用户数据。
➢ 场景二
对于一个电商系统按上面参数就不可取,因为一个账号不停购买商品这样的行为完全不符合真实场景,这时候我们应该怎么办呢?在这样的场景中,我们需要考虑TPS 和持续时间,用户数据计算方式参考:
➢ 场景三
假如一个线程可以循环使用固定参数,在这情况下我们需要根据实际业务判断,比如100 压力线程情况下,我们准备 1000 条数据,我们就可以让每个线程用不同的 10 条数据。这样的场景没固定条数限制,只能根据实践业务判断,但是在配置这个参数之前还需要考虑参数是什么类型,如果是可循环的数据,那么它在真实性能场景非常少,也就是说只使用一条或者几条测试数据真实场景基本没有。
-
参数化数据
知道参数用多少后,还需要解决参数化数据从什么地方获取,这一步目的是确保参数数据是有效的,一般我们参数化数据来源两个方向,一个是后台数据库存在的,一个是数据库不存在通过压力工具造出来的数据。
总之参数化数据来源需要确保数据的有效性,这些数据需要满足下面两个条件:
✓ 满足生产环境数据分布
✓ 满足性能场景中数据量的要求
对于一个系统来说,参数化数据是否合理,会直接影响压力测试结果是否有意义。如果压力工具使用的数据量少,那么那么应用服务器、缓存服务器、数据库服务器等都将使用少量的缓存来处理,导致不能把后端各类服务器的缓存占用到真实场景中应该有的大小,所以在这种状态之下是测试不出来真实场景下的压力。
对数据库连接的存储设备来说同样也有影响。如果数据量少,则相应的存储的 I/O 使用就少。参数取得过多,对系统的压力就会大;参数取得过少,不符合真实场景中的数据量,则无法测试出系统真实的压力。
如果参数来源于数据库,我们通常要检查一下数据库中的数据直方图。对于直接从生产上拿的数据来说,数据的分布更为精准。但是对于一些在测试环境中造的数据,则一定要在造数据之后,检查下数据分布是否与生产一致。有上面准备后,就可以开始做基准测试,我们在做基准测试需要注意两个点:

我们在实施中什么时候基准场景结束呢?或者到压到什么情况下就可以结束基准场景呢?一般压测过程中接口调用系统资源使用率到达90%或者完全把系统资源使用完毕就可以停止基准场景,注意遇到性能问题需要调优确保资源充足使用,以达到 TPS 还有响应时间是最合理。
![]()
容量场景
对于容量场景来说就是把之前基准场景所有接口按一定比例组合起来一起执行,还有做容量场景的目的是要回答“线上容量最大能达到多少”的问题。这里有个问题就是接口与接口间的比例怎么定?在压力工具中又怎么配置?如果不能解决这些问题我们就没法做容量场景设计,可能有些同学就说,直接把接口全部放到一个场景按1倍、2倍、3倍等倍数直接跑就行,没有必要考虑每个接口比例,直接跑个最大值就行,但是这样场景与实际场景有差距,跑出来的场景脱离真实性,那么我们应该怎么设计呢?还有一个问题就是容量场景什么时候停止?
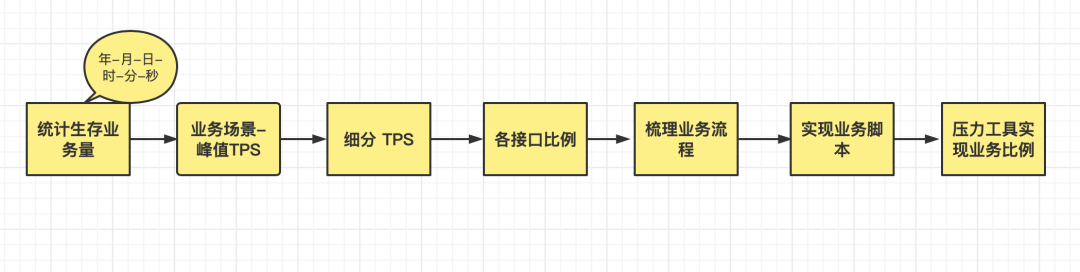
首先我们可以抽取生产日志,相信每个公司都有日志系统,如果没有日志系统可以使用 awk 命令去抽取日志,还可以使用 ELFK 来抽取日志,有上面数据后,就可以梳理业务逻辑。
我司可以通过 lambda 平台可以获取被压测日志,通过检索条件获取我们想要一段时间的接口数据:
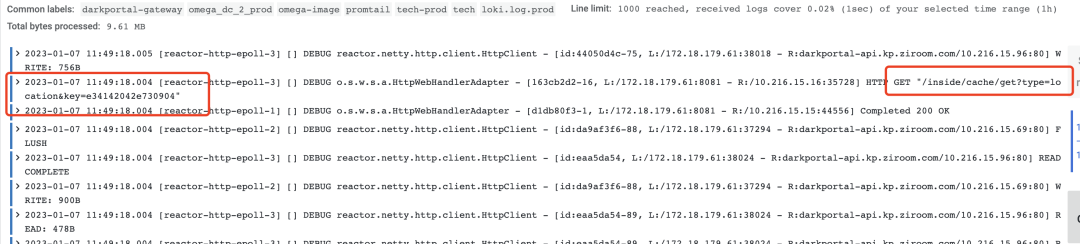
如果没有这样的系统我们可以在 Nginx 日志中获取相关数据, 可以通过写 python 脚本处理也可以使用 shell 命令获取我们想要的数据,我们需要数据格式为:
这样我们就可以知道,每个时间段内每个请求的数量,也就可以得到相应的业务比例了。
如果是 ELFK 抽出生存日志大家可以自己安装一个这样的环境配置后,设置相关条件抽出上面数据对应关系的数据类型。
注意:如果出现某个请求的高并发时间点和其他的请求不在同一时间点,就一定要做多个场景来模拟,因为场景中的业务模型会发生变化。
假设我们通过上面步骤就能得出被压测接口的调用量与请求比例,也就可以拿某请求的数量除以总请求数得出每个接口的比例,这里使用一个表格做说明(注意里面数据是假设出来):
这里总结下获取生产数据比例步骤:
请注意,上面的业务场景在实际的项目业务统计过程中可以有多个。这个思路可以解决任何性能场景和生产场景不一致的问题。有业务比例后接下来我们需要梳理业务场景,用场景覆盖业务比例,场景比例应该怎么设计呢,大家可以思考下,设计几个场景能覆盖上面接口业务比例,这里就不讲解,大家自己思考思考。
用 JMeter 里面,会用Throughput Timer来控制TPS。
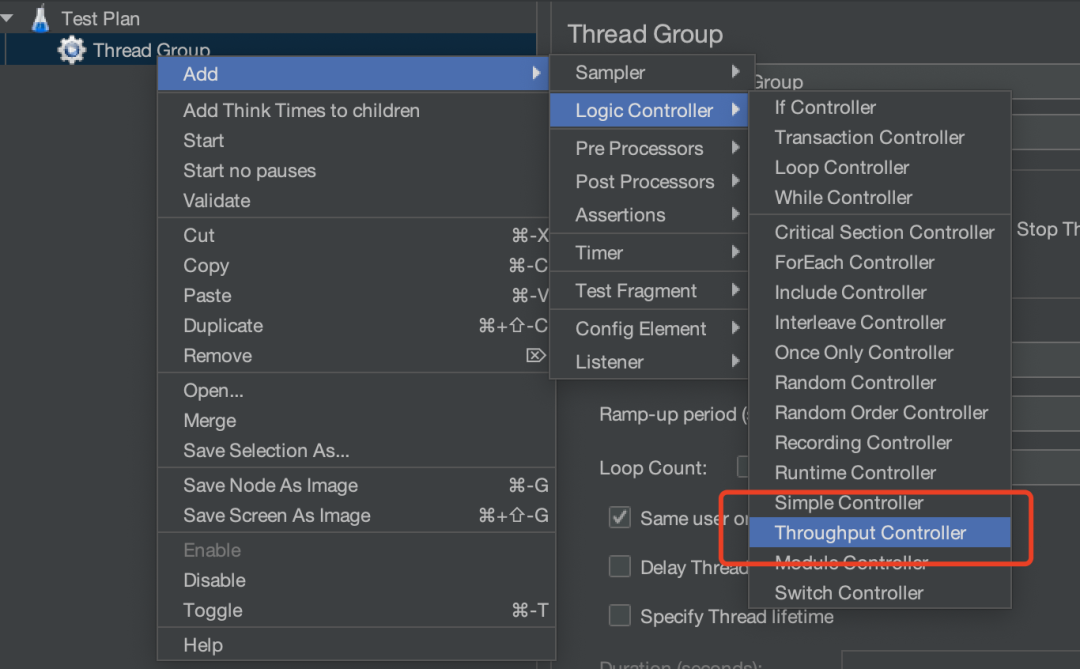
关于 Throughput Controller 控制器怎么场景比例,大家可以查询资料就能解决。
有上面业务比例后,我们可以思考下容量场景在什么情况下结束呢?我们在做容量场景时需要确定一个目标,否则就没有结束时间点。大家是否还记得我们在业务比例分配的时候是按一个数据总量分配给每一个接口做比例,这个总量就是我们容量测试的目标。
![]()
稳定性场景
我们在前面提到,容量场景是为了看系统所能承受的最大容量,而稳定性场景主要看的是系统提供长时间服务时的性能稳定性,观察系统在长时间运行过程中出现的累积效应。因此,运行时长就是稳定性场景中非常重要的一个指标了。
这里需要明白稳定性运行时长不是固定的,它取决于业务系统的具体应用场景,那么应该怎么计算稳定性时间呢?这里提供一种计算执行时间计算方法。
假设你根据生产系统统计出,在之前的运维周期中,有6千万的业务容量,而在容量场景中得到的最大TPS有1000。那么,我们就可以通过下面这个公式来计算:
稳定性运行时长=6千万(业务累积量)÷1000(TPS)÷3600(秒)≈16(小时)。
不管是什么样的系统,要想运行稳定性场景,都得确定一个业务累积量(一时间业务总量),我们在执行的时候直接用最大TPS来运行,如果一个系统在最大TPS状态下正常运行,才能验证系统能否经得起考验。
![]()
异常场景
在异常场景设计中首先针对系统的架构,先分析异常场景中的需求点,再设计相应的案例来覆盖。为什么要分析系统架构呢?因为在一个应用中,我们把功能测试完一遍之后,异常问题通常有两大类:其一是架构级的异常;其二是容量引起的性能异常。而对于架构级的异常,我们只能站在架构的角度进行分析。
从性能技术的角度来说,基本上采用的是宕主机、断网络、宕应用等常用测试手段,现在市场上还有混沌工具,大家也可以采用混沌工具做异常测试,这提供一些通用手段帮助大家做操作:
✓ 主机:断电、reboot、shutdown 等;
✓ 网络:ifdown 命令关网卡、模拟抖动丢包延时重传等;
✓ 应用:kill、stop 等。
这里再谈下异常场景设计的逻辑,第一步把技术架构中的组件全部列出来,并分析可能产生异常的点,第二步根据分析异常点设计对应的场景。在很多时候都是根据感觉走,就会导致异常场景覆盖不全,这里建议参考 FMEA 失效模型来设计异常场景,因为有 FMEA 可以让我们有章可循,这里要注意的是对于任何方法论还有逻辑在实践落地时候都不要过度使用,而是要注意内容的合理性。
这里只是提供一种设计思路,大家在落地的时候把不符合自己公司的或者实践干活的可以去的,希望大家设计一套符合自己系统的异常场景模型。
TesterHome 学堂测开课:
从0到1实现UI自动化测试和框架设计 (Java技术栈)
Python+Appium移动端自动化项目实战
移动测试平台二次开发入门