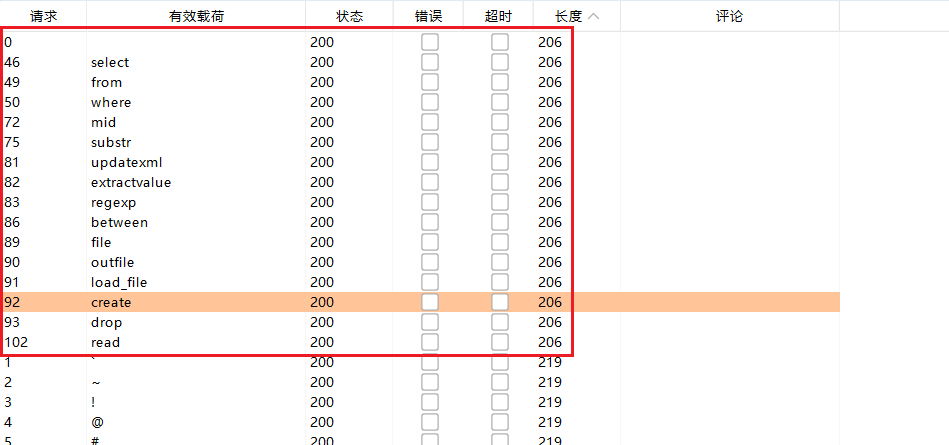
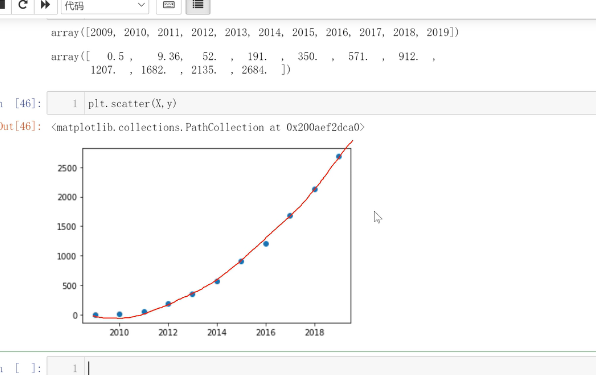
代码:https://github.com/neuralchen/SimSwap
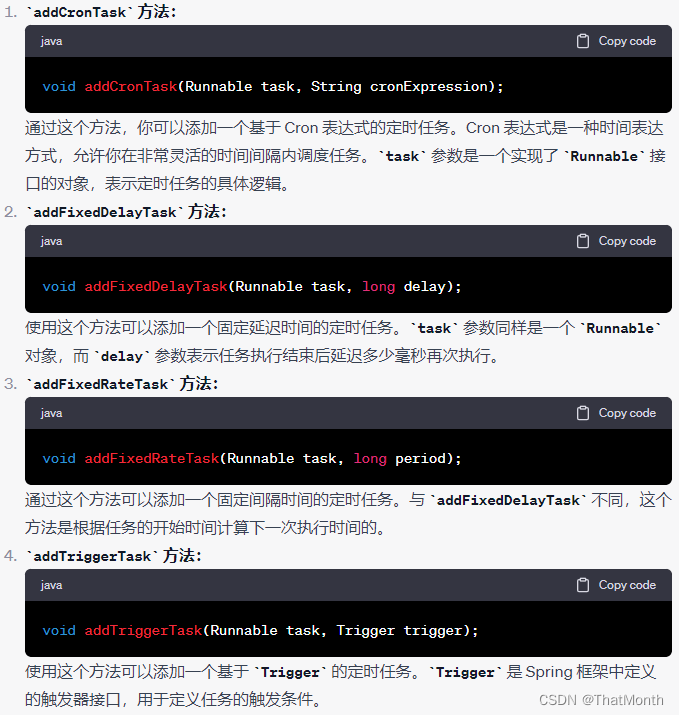
文章目录
- 摘要
- 介绍
- RELATED WORK
- 实验
- 结论
- 代码实操
- SimSwap是一个高保真度人脸交换的高效框架。
- 它将源脸的身份转移到目标脸上,同时保留目标脸的属性。
- 该框架包括ID注入模块(IIM),用于在特征级别上转移身份信息。
- 弱特征匹配损失用于隐式地保留属性。
- SimSwap在身份性能上具有竞争力,并且相比之前的方法更好地保留了属性。
- 该框架可以推广到任意身份,并通过广泛的实验进行了评估。
摘要
本文提出了一种高效的框架,称为Simple Swap(SimSwap),旨在实现通用且高保真度的人脸交换。与之前的方法相比,这种方法不仅能够适应任意身份,还能保留目标人脸的属性,如面部表情和注视方向。为了克服上述缺陷,本文采用了两种方法。首先,提出了ID注入模块(IIM),该模块可以在特征级别上将源人脸的身份信息转移到目标人脸上。通过使用该模块,将特定身份的人脸交换算法的架构扩展为任意人脸交换的框架。其次,提出了弱特征匹配损失,该损失以隐式方式帮助我们的框架保留面部属性。在野外人脸上进行的大量实验证明,SimSwap能够实现与先前最先进方法相媲美的身份性能,并且在属性保留方面表现更好。代码已经在GitHub上可用:https://github.com/neuralchen/SimSwap。
介绍
人脸交换是一项有前景的技术,它将源人脸的身份转移到目标人脸,同时保持目标人脸的属性(例如表情、姿势、光照等)不变。在电影业中,这项技术被广泛用于制作不存在的双胞胎。工业级人脸交换方法利用先进设备重建演员的面部模型并重新构建场景的光照条件,这超出了大多数人的能力范围。最近,无需高端设备进行人脸交换[2, 7, 20, 26]引起了研究人员的关注。
人脸交换的主要困难可以总结如下:1) 具有强大泛化能力的人脸交换框架应该适应任意人脸;2) 结果人脸的身份应与源人脸的身份接近;3) 结果人脸的属性(例如表情、姿势、光照等)应与目标人脸的属性一致。
主要有两种类型的人脸交换方法,包括在图像级别处理源人脸的源导向方法和在特征级别处理目标人脸的目标导向方法。源导向方法[3, 4, 26, 27]将目标人脸的属性(如表情和姿势)转移到源人脸,然后将源人脸混合到目标图像中。这些方法对源图像的姿势和光照敏感,不能准确复制目标的表情。目标导向方法[2, 7, 18, 20]直接修改目标图像的特征,并能很好地适应源人脸的变化([7] DeepFakes)。开源算法[7]DeepFakes能够生成两个特定身份之间的人脸交换结果,但缺乏泛化能力。基于GAN的工作[2]在特征级别上结合了源身份和目标属性,并将应用扩展到任意身份。 最近的工作[20]利用了一个两阶段框架,并取得了高度逼真的结果。然而,这些方法过于关注身份修改,对属性保留施加的约束较弱,往往在表情或姿势上出现不匹配。
为了克服泛化和属性保留方面的缺陷,我们提出了一种高效的人脸交换框架,称为SimSwap。我们分析了一种特定身份的人脸交换算法[7]的架构,并发现泛化不足是由于将身份信息集成到解码器中,因此解码器只能应用于一个特定的身份。为了避免这种集成,我们提出了ID注入模块。我们的模块通过将源人脸的身份信息嵌入到目标图像的特征中进行修改,从而消除身份信息与解码器权重之间的相关性,使我们的架构能够适用于任意身份。此外,身份和属性信息在特征级别高度耦合。对整个特征进行直接修改会导致属性性能下降,我们需要使用训练损失来缓解这种影响。虽然明确约束结果图像的每个属性以匹配目标图像过于复杂,但我们提出了弱特征匹配损失。我们的弱特征匹配损失在高语义级别上将生成的结果与目标输入对齐,并隐含地帮助我们的架构保留目标的属性。通过使用这个术语,我们的SimSwap能够在具有竞争性身份性能的同时,具有比先前最先进的方法更好的属性保留能力。大量实验证明了我们算法的泛化性和有效性。
RELATED WORK
人脸交换已经被研究了很长时间。这些方法主要可以分为两类,包括在图像级别处理源人脸的源导向方法和在特征级别处理目标人脸的目标导向方法。
源导向方法:源导向方法将属性从目标人脸转移到源人脸,然后将源人脸混合到目标图像中。早期的方法[4]使用3D模型来转移姿势和光照,但需要手动干预。提出了一种自动方法[3],但只能与特定人脸库中的身份进行人脸交换。Nirkin等人[27]利用3D人脸数据集[29]来转移表情和姿势,然后使用Poisson Blending [30]将源人脸融合到目标图像中。然而,由于3D人脸数据集表达能力有限,依赖于3D模型的方法[4, 27]通常难以准确复制表情。最近,FSGAN [26]提出了一个两阶段的架构,首先使用人脸再现网络进行表情和姿势转移,然后使用另一个人脸修复网络将源人脸混合到目标图像中。源导向方法的一个普遍问题是它们对输入源图像敏感。源人脸的夸张表情或大幅度姿势将强烈影响人脸交换结果的性能。
目标导向方法:目标导向方法使用神经网络提取目标图像的特征,然后对这些特征进行修改,并将特征还原到输出的人脸交换图像中。Korshunova等人[18]训练了一个生成器,并能够与一个特定身份进行人脸交换。著名的算法DeepFakes [7]利用了一个编码器-解码器架构。一旦训练完成,它能够在两个特定身份之间进行人脸交换,但缺乏泛化能力。类似于[24, 25]的方法结合了源人脸区域和目标非人脸区域的潜在表示以生成结果,但未能保持目标的表情。IPGAN [2]从源图像中提取身份向量,从目标图像中提取属性向量,然后将它们发送到解码器。生成的输出在传递源人脸的身份方面表现良好,但通常未能保留目标人脸的表情或姿势。最近提出的方法FaceShifter [20]能够产生高度逼真的人脸交换结果。FaceShifter利用了一个复杂的两阶段框架,并取得了最先进的身份性能。然而,与以前的方法一样,FaceShifter对属性的约束太弱,因此它们的结果经常出现表情不匹配的问题。
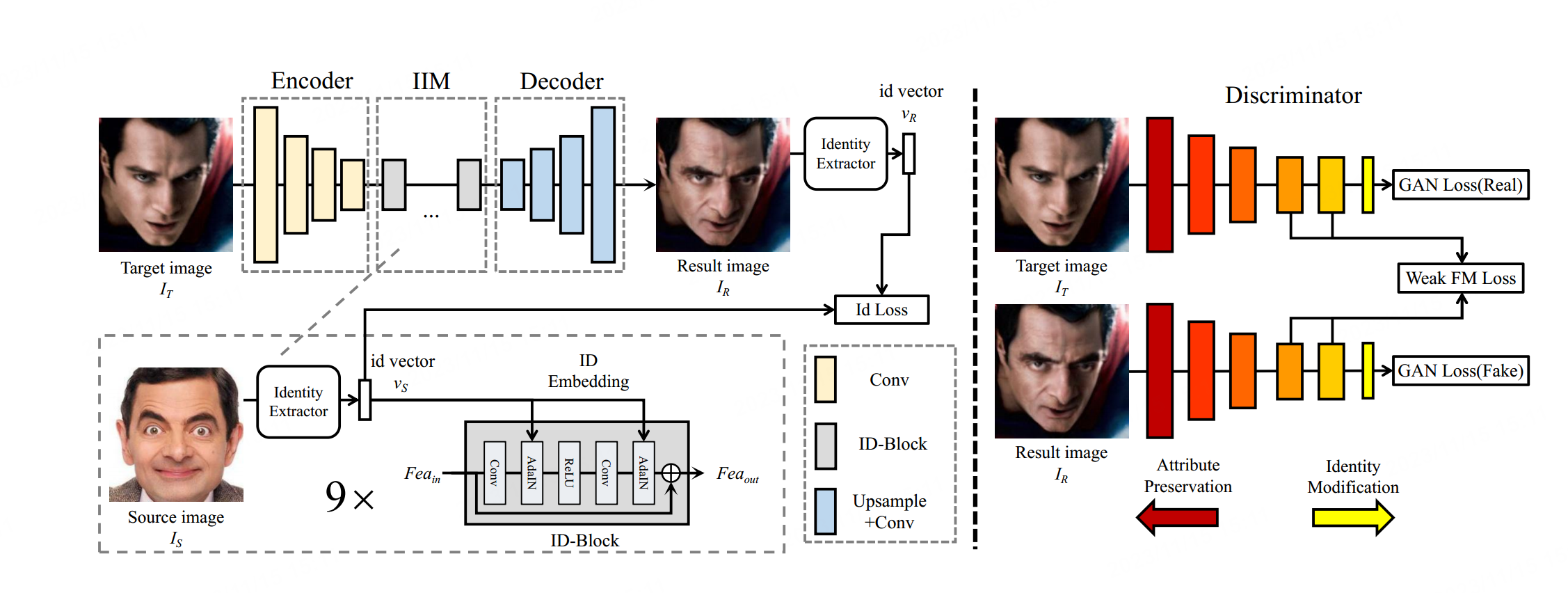
图2:SimSwap的框架我们的生成器包括三个部分,包括编码器部分、ID注入模块(IIM)和解码器部分。编码器从目标图像 𝐼𝑇 中提取特征 𝐹𝑒𝑎𝑇。ID注入模块将身份信息从𝐼𝑆传输到 𝐹𝑒𝑎𝑇。解码器将修改后的特征还原到结果图像中。我们使用身份损失来鼓励我们的网络生成与源人脸相似身份的结果。我们应用弱特征匹配损失来确保我们的网络在不过多影响身份修改性能的情况下保留目标人脸的属性。
3 方法
给定源图像和目标图像,我们提出了一个框架,将源人脸的身份转移到目标人脸,同时保持目标人脸的属性不变。我们的框架源于一种特定身份的人脸交换架构[7],可以适应任意身份。我们首先讨论原始架构的局限性(第3.1节)。我们展示如何将其扩展为适用于任意身份的框架(第3.2节)。然后,我们提出了弱特征匹配损失,有助于保留目标的属性(第3.3节)。最后,我们给出我们的损失函数(第3.4节)。
DeepFakes的架构包含两个部分,一个通用的编码器 𝐸𝑛𝑐 和两个特定身份的解码器 𝐷𝑒𝑐𝑆 , 𝐸𝑛𝑐𝑇。在训练阶段,𝐸𝑛𝑐-𝐷𝑒𝑐𝑆架构接收扭曲的源图像并将其恢复为原始的未扭曲的源图像。使用𝐸𝑛𝑐-𝐷𝑒𝑐𝑇架构对目标图像进行相同的过程。在测试阶段,目标图像将被发送到 𝐸𝑛𝑐-𝐷𝑒𝑐𝑆架构。该架构将错误地将其视为扭曲的源图像,并生成具有源身份和目标属性的图像。在此过程中,编码器 𝐸𝑛𝑐 提取了目标的特征,其中包含目标人脸的身份和属性信息。由于解码器 𝐷𝑒𝑐𝑆 设法将目标的特征转换为具有源身份的图像,源人脸的身份信息必须已经隐式地整合到 𝐷𝑒𝑐𝑆 的权重中,其中 𝐹𝑒𝑎𝑇 的哪一部分应该被改变,哪一部分应该被保留。
我们的ID注入模块致力于改变 𝐹𝑒𝑎𝑇 中的身份信息朝着源人脸的身份信息。该模块由两个部分组成,即身份提取部分和嵌入部分。在身份提取部分中,我们处理包含源人脸身份和属性信息的输入源图像 𝐼𝑆。由于我们只需要前者,我们使用人脸识别网络[8]从 𝐼𝑆 中提取身份向量 𝑣𝑆。在嵌入部分中,我们使用ID块将身份信息注入到特征中。我们的ID块是Residual Block [12]的修改版本,并使用自适应实例归一化(AdaIN) [13]替代原始的批次归一化[14]。我们任务中AdaIN的公式可以写成:
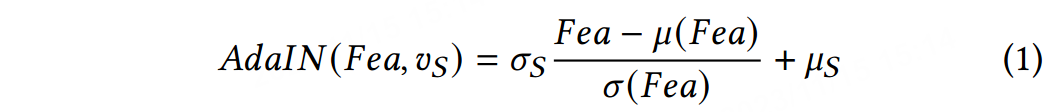
这里,[ \mu(\text{Fea}) ] 和 [ \sigma(\text{Fea}) ] 是特征 [ \text{Fea} ] 的按通道均值和标准差。[ \sigma_S ] 和 [ \mu_S ] 是使用全连接层从 [ \text{v}_S ] 生成的两个变量。为了保证足够的身份嵌入,我们使用了总共9个ID块。在注入身份信息后,我们将修改后的特征传递到解码器生成最终的结果 [ \text{I}_R ]。由于训练中涉及来自不同身份的源图像,解码器的权重不应与任何特定身份相关联。我们的解码器只专注于从特征中恢复图像,并将身份修改任务交给ID注入模块,因此我们可以将我们的架构应用于任意身份。在训练过程中,我们从生成的结果 [ \text{I}_R ] 中提取身份向量 [ \text{v}_R ],并使用身份损失最小化 [ \text{v}_R ] 与 [ \text{v}_S ] 之间的距离。然而,身份损失的最小化可能使网络过度拟合,并仅生成具有源身份的正面图像,同时失去了目标的所有属性。为避免这种现象,我们利用对抗训练的思想,并使用鉴别器来区分具有明显错误的结果。对抗损失在提高生成结果质量方面也发挥着重要作用。我们使用了鉴别器的patchGAN[15]版本。
该论文探讨了一种在进行人脸替换时保留目标人脸属性的方法。主要挑战包括仅修改目标人脸的身份部分,并保持属性(如表情、姿势、光照等)不变。所提出的方法涉及对整个人脸进行修改,包括身份和属性信息,但通过在深度层次上将结果图像与输入目标对齐,从而保持属性。引入了弱特征匹配损失,仅使用鉴别器的最后几层,以隐式学习如何保留目标人脸的属性。
总体损失函数包括五个组成部分:身份损失、重构损失、对抗性损失、梯度惩罚和弱特征匹配损失。身份损失确保真实和生成的人脸嵌入之间的相似性,同时防止属性不匹配。弱特征匹配损失受到pix2pixHD的启发,通过在多尺度设置中仅使用鉴别器的最后几层,以隐式方式约束属性,避免需要为每个属性训练单独的网络。
重构损失确保生成的结果在源脸和目标脸属于相同身份时与目标脸相匹配。采用Hinge版本的对抗性损失和梯度惩罚有助于在大姿势下提高性能。弱特征匹配损失使用所有鉴别器进行计算,构建了一个多尺度的设置。
论文解释了原始特征匹配损失和提出的弱特征匹配损失之间的差异。前者旨在稳定训练并关注多个层次的自然统计信息,而后者通过专注于深度特征来针对属性性能。
总体损失函数是各个损失的加权和,为每个组件分配了特定的权重。该方法旨在在人脸替换过程中平衡身份保持和属性一致性,提供了每个损失组件在总体函数中的实验参数。
实验
实施细节:由于我们致力于对任意身份进行面部交换,我们选择了一个大型的面部数据集VG-GFace2 [6]作为我们的训练集。为了提高我们的训练集的质量,我们删除了尺寸小于250 × 250的图像。我们将图像对齐和裁剪到大小为224 × 224的标准位置。至于ID注入模块中的人脸识别模型,我们使用在[9]上预先训练的Arcface [8]模型。我们使用Adam优化器[17]进行网络训练,其中𝛽1 = 0,𝛽2 = 0.999。我们对具有相同身份的图像对进行一批训练,然后对具有不同身份的图像对进行另一批训练,交替进行。我们对网络进行超过500个时期的训练。
4.1 定性面部交换结果
我们展示一个面部矩阵,以展示我们的面部交换结果。我们从电影场景中选择了8张面部图像作为目标。DeepFakes的结果受到严重的光照和姿势不匹配的影响。FaceShifter成功产生了不错的面部交换结果,但结果面部的表情和凝视方向并不完全尊重目标面部的表情和凝视方向。我们的SimSwap生成了合理的面部交换结果,同时在属性保留方面表现更好。
与FaceShifter的额外比较:我们在图5中进一步比较了更多的结果与FaceShifter。如图所示,FaceShifter表现出强烈的身份修改能力,并且能够将结果面部的形状改变为源面部的形状。然而,它过于关注身份部分,经常在保持表情和凝视方向等属性方面失败。在图5的第2行中,目标面部正在眯起眼睛。SimSwap能够生成复制这种微妙表情的结果,而FaceShifter则失败。此外,尽管FaceShifter使用第二个网络将其面部交换结果与背景结合,但我们仍然设法产生了比FaceShifter稍好的光照条件(第3和4行)。
与FSGAN的比较:我们在图6中与FSGAN进行比较。FSGAN的结果未能复制目标面部的表情(第1行),凝视方向(第1和4行),并且它们的结果与目标图像之间在光照条件上存在明显差异。我们的SimSwap在属性保留方面表现更好。此外,FSGAN对输入源图像非常敏感。如第2行所示,目标面部有一个清晰的眼区域,但FSGAN引入了源面部的阴影。类似问题在第4行围绕鼻子区域也发生了。
图5:与FaceShifter [20]的更多比较结果。我们在表达和光照条件方面具有更好的属性性能。
此外,在鼻子区域周围的第4行也发生了类似的问题。SimSwap对输入源图像更加稳健,并产生更具说服力的结果。
4.3 SimSwap的分析
在本节中,我们将首先对我们的身份修改能力进行分析。然后,我们将进行多项消融测试,以展示在面部交换任务中如何在身份和属性性能之间保持平衡。
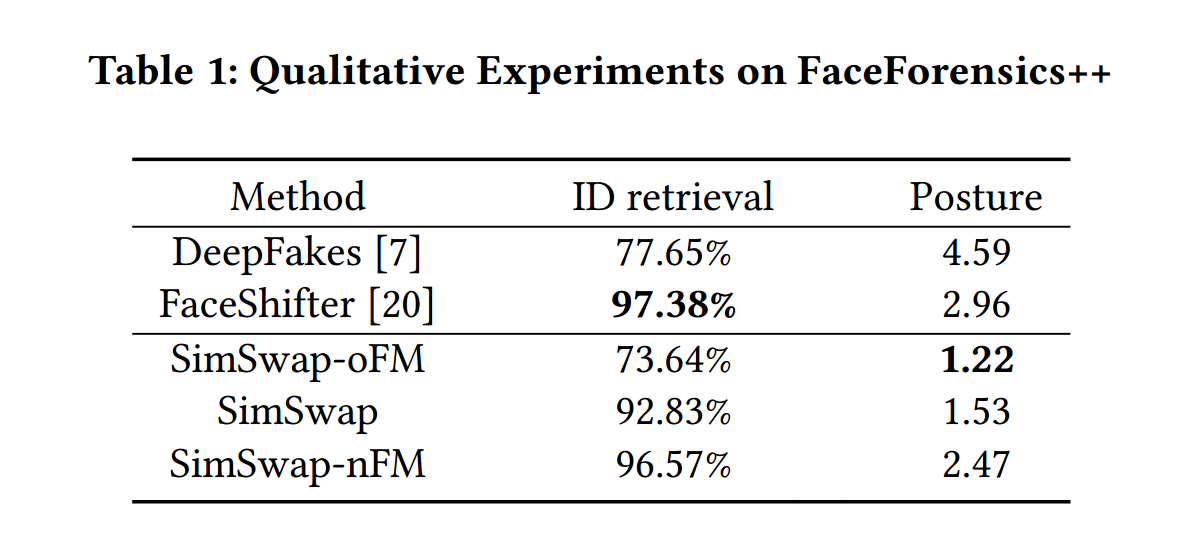
高效的ID嵌入:SimSwap的架构使用ID注入模块进行身份嵌入,以便我们可以将身份信息从解码器的权重中分离出来,并将我们的架构推广到任意身份。为了验证我们架构的有效性,我们使用FaceForensics++ [31]上由[20]提出的标准进行相同的定量实验。我们随机选择FaceForensics++中每个面部视频的10帧。我们使用SimSwap根据FaceForensics++中的相同源和目标对进行面部交换。我们使用另一个人脸识别网络[23, 33]提取生成的帧和原始帧的身份向量。对于每个生成的帧,我们搜索原始帧中最近的面部,并检查该面部是否来自正确的源视频。准确率被命名为ID检索,它作为该方法身份性能的代表。我们还使用姿势估计器[32]来估计生成的帧和原始帧中的姿势,并计算它们的平均L2距离。由于我们无法找到有效的复制,我们忽略了面部表情部分。
为了进一步比较,我们训练了另外2个网络,分别称为SimSwap-oFM,其使用原始的特征匹配公式,以及SimSwap-nFM,其不使用特征匹配项。我们对这两个网络进行相同的定量实验。我们还在DeepFakes生成的帧上进行测试。比较结果显示在表1中。
正如我们所见,SimSwap-oFM具有最低的ID检索,因为它在浅层次上对齐了结果。与此同时,通过在所有级别上移除约束,SimSwap-nFM在身份性能上与Faceshifter相差无几。我们的SimSwap在身份上略逊于FaceShifter,但在属性保留方面表现相对较好。结合图4和5的结果,我们的SimSwap在身份检索,同时保持中等的重建损失,以在身份和属性性能之间保持良好的平衡。
为了进一步验证我们的弱特征匹配损失的有效性,不同网络生成的结果显示在图8中。我们注意到具有相同特征匹配项的结果(列3和4,列5和6)相对较小的差异,这表明增加𝜆𝐼𝑑对视觉效果的影响有限。当我们比较SimSwap(列5)和SimSwap-oFM(列3)之间的结果时,SimSwap呈现出更好的身份性能,同时没有失去太多属性。SimSwap-nFM的结果(列7)具有最佳的身份性能,并且结果面部的形状已经朝着源面部的形状进行了修改。然而,SimSwap-nFM明显失去了属性,因为凝视方向往往偏离目标面部的方向。
至于SimSwap和wFM-id+,它们在大多数情况下产生非常相似的视觉输出。然而,当比较图7中的wFM-id+和nFM的值以及图8中的结果时,我们注意到尽管wFM-id+具有较小的身份损失,但ID检索和视觉效果表明nFM确实实现了更好的身份性能。这表明wFM-id+已经过度拟合了身份损失。此外,wFM-id+更有可能从源面部引入头发(如图9所示)。这是不希望的,因为我们只是替换面部。因此,我们选择SimSwap以获得更稳定的结果。
结论
我们提出了SimSwap,这是一个旨在实现通用和高保真面部交换的高效框架。我们的ID注入模块在特征级别传递身份信息,并将特定于身份的面部交换扩展到任意面部交换。弱特征匹配损失有助于我们的框架具有良好的属性保留能力。广泛的结果表明,我们能够生成视觉上吸引人的结果,而且我们的方法能够比先前的方法更好地保留属性。
代码实操
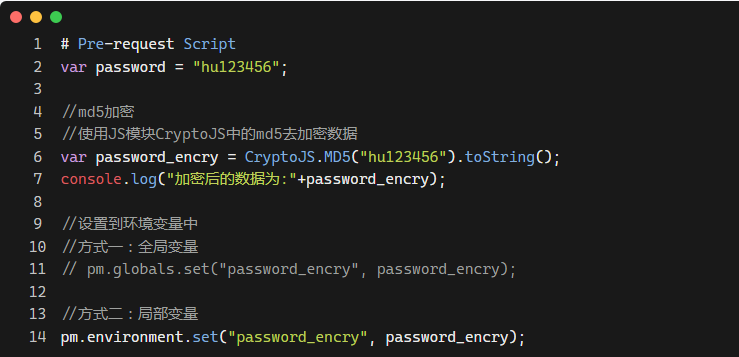
conda create -n simswap2 python=3.8 -y
conda activate simswap2
# 安装环境
sudo apt-get install python3-dev
pip install torch==1.8.0+cu111 torchvision==0.9.0+cu111 torchaudio==0.8.0 -f https://download.pytorch.org/whl/torch_stable.html
pip install --ignore-installed imageio
pip install cython insightface==0.7.3 onnx onnxruntime moviepy
文件目录:
.
├── 512
│ └── 550000_net_G.pth
├── 512.zip
├── arcface_model
│ └── arcface_checkpoint.tar
├── archive
│ ├── data
│ ├── data.pkl
│ └── version
├── checkpoints
│ └── people
├── cog.yaml
├── crop_224
│ ├── 1_source.jpg
│ ├── 2.jpg
│ ├── 6.jpg
│ ├── cage.jpg
│ ├── dnl.jpg
│ ├── ds.jpg
│ ├── gdg.jpg
│ ├── gy.jpg
│ ├── hzc.jpg
│ ├── hzxc.jpg
│ ├── james.jpg
│ ├── jl.jpg
│ ├── lcw.jpg
│ ├── ljm2.jpg
│ ├── ljm3.jpg
│ ├── ljm.jpg
│ ├── mars2.jpg
│ ├── mouth_open.jpg
│ ├── mtdm.jpg
│ ├── trump.jpg
│ ├── wlh.jpg
│ ├── zjl.jpg
│ ├── zrf.jpg
│ └── zxy.jpg
├── data
│ └── data_loader_Swapping.py
├── demo_file
│ ├── Iron_man.jpg
│ ├── multi_people_1080p.mp4
│ ├── multi_people.jpg
│ ├── multispecific
│ ├── specific1.png
│ ├── specific2.png
│ └── specific3.png
├── Dockerfile
├── docs
│ ├── css
│ ├── favicon.ico
│ ├── fonts
│ ├── guidance
│ ├── img
│ ├── index.html
│ └── js
├── download-weights.sh
├── insightface_func
│ ├── antelope
│ ├── antelope.zip
│ ├── face_detect_crop_multi.py
│ ├── face_detect_crop_single.py
│ ├── __init__.py
│ └── utils
├── LICENSE
├── models
│ ├── arcface_models.py
│ ├── base_model.py
│ ├── config.py
│ ├── fs_model.py
│ ├── fs_networks_512.py
│ ├── fs_networks_fix.py
│ ├── fs_networks.py
│ ├── __init__.py
│ ├── models.py
│ ├── networks.py
│ ├── pix2pixHD_model.py
│ ├── projected_model.py
│ ├── projectionhead.py
│ ├── __pycache__
│ └── ui_model.py
├── MultiSpecific.ipynb
├── options
│ ├── base_options.py
│ ├── __pycache__
│ ├── test_options.py
│ └── train_options.py
├── output
│ └── result.jpg
├── parsing_model
│ ├── 79999_iter.pth
│ ├── model.py
│ ├── resnet.py
│ └── wget-log
├── pg_modules
│ ├── blocks.py
│ ├── diffaug.py
│ ├── projected_discriminator.py
│ └── projector.py
├── predict.py
├── README.md
├── SimSwap colab.ipynb
├── simswaplogo
│ ├── simswaplogo.png
│ └── socialbook_logo.2020.357eed90add7705e54a8.svg
├── test
│ ├── checkpoints.zip
│ └── people
├── test_one_image.py
├── test_video_swapmulti.py
├── test_video_swap_multispecific.py
├── test_video_swapsingle.py
├── test_video_swapspecific.py
├── test_wholeimage_swapmulti.py
├── test_wholeimage_swap_multispecific.py
├── test_wholeimage_swapsingle.py
├── test_wholeimage_swapspecific.py
├── train.ipynb
├── train.py
└── util
├── add_watermark.py
├── html.py
├── image_pool.py
├── json_config.py
├── logo_class.py
├── norm.py
├── plot.py
├── __pycache__
├── reverse2original.py
├── save_heatmap.py
├── util.py
├── videoswap_multispecific.py
├── videoswap.py
├── videoswap_specific.py
└── visualizer.py
31 directories, 104 files
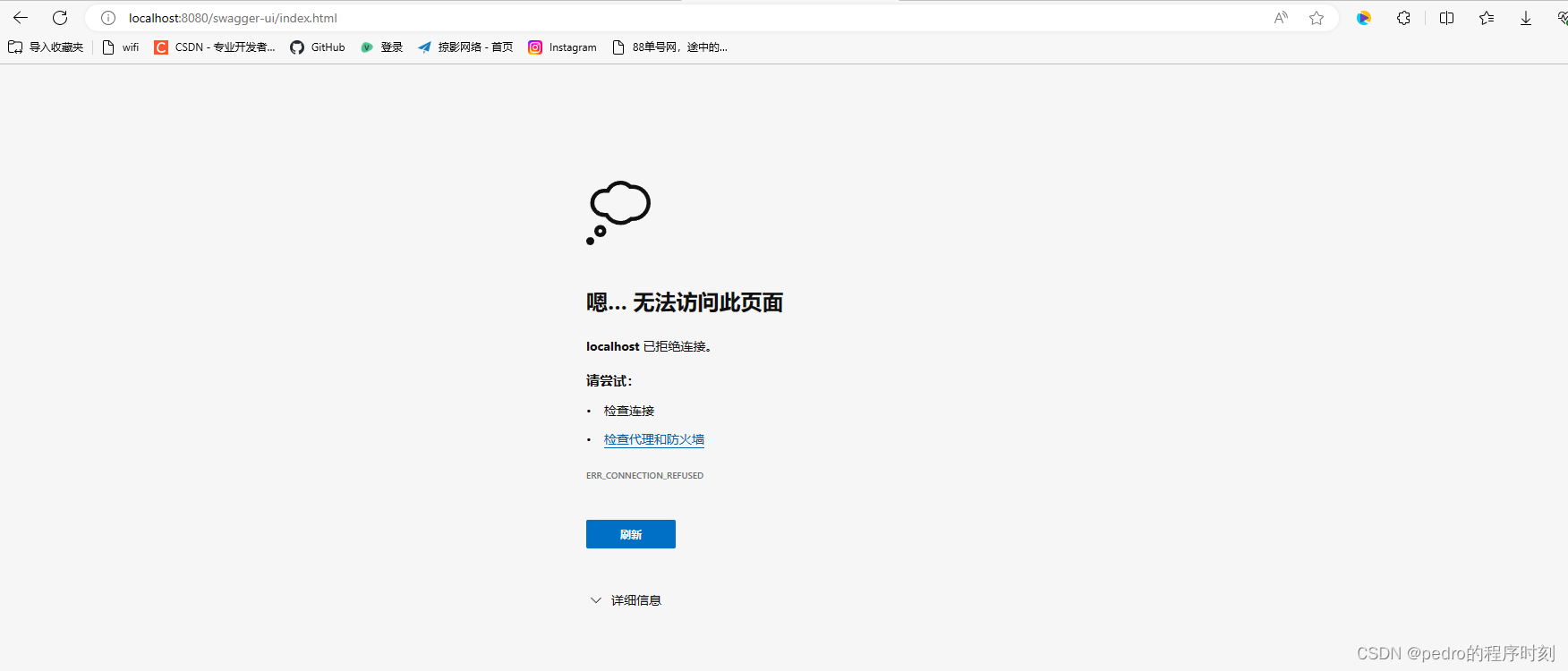
执行这个:
python test_one_image.py --name people --Arc_path arcface_model/arcface_checkpoint.tar --pic_a_path crop_224/6.jpg --pic_b_path crop_224/ds.jpg --output_path output/
报了个错:
-------------- End ----------------
Pretrained network G has fewer layers; The following are not initialized:
['down0', 'first_layer', 'last_layer', 'up0']
/home/xiedong/xiedong/miniconda3/envs/simswap2/lib/python3.8/site-packages/torch/nn/functional.py:3451: UserWarning: Default upsampling behavior when mode=bilinear is changed to align_corners=False since 0.4.0. Please specify align_corners=True if the old behavior is desired. See the documentation of nn.Upsample for details.
warnings.warn(
真难玩,不玩了,换个项目玩,比如faceshifter。