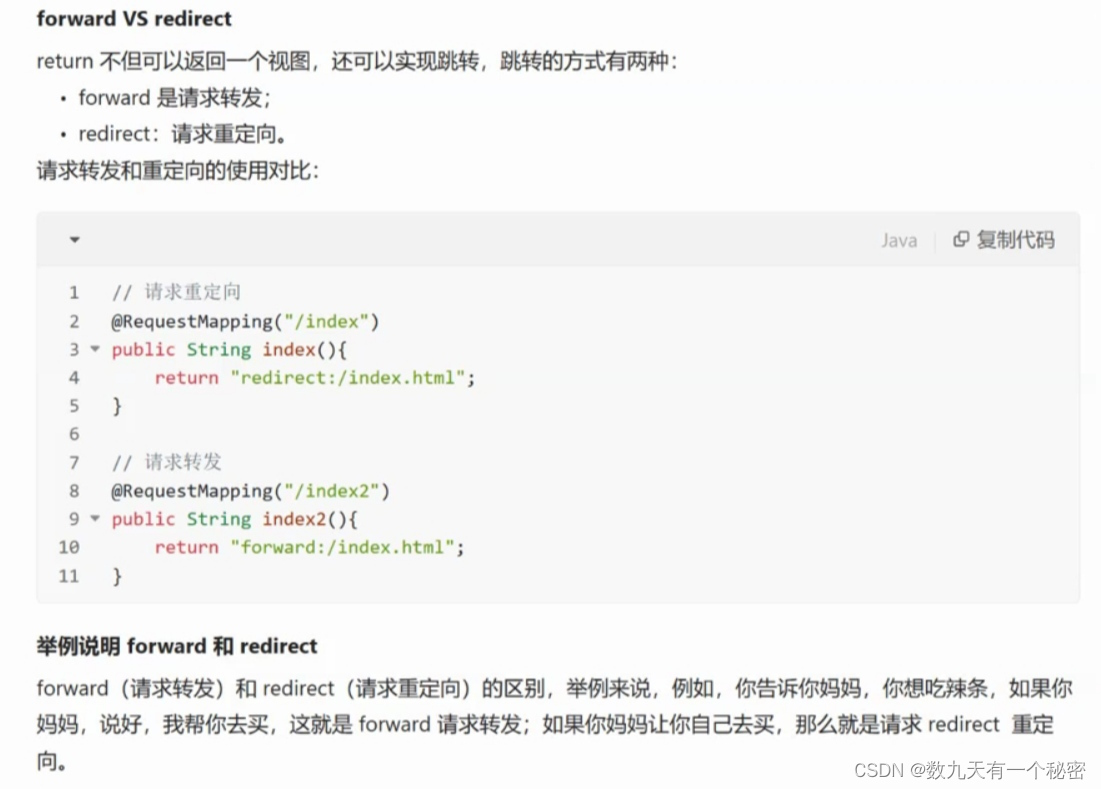
前言
你听说过GANs吗?还是你才刚刚开始学?GANs是2014年由蒙特利尔大学的学生 Ian Goodfellow 博士首次提出的。GANs最常见的例子是生成图像。有一个网站包含了不存在的人的面孔,便是一个常见的GANs应用示例。也是我们将要在本文中进行分享的。
生成对抗网络由两个神经网络组成,生成器和判别器相互竞争。我将在后面详细解释每个步骤。希望在本文结束时,你将能够从零开始训练和建立自己的生财之道对抗性网络。所以闲话少说,让我们开始吧。
目录
步骤0: 导入数据集
步骤1: 加载及预处理图像
步骤2: 定义判别器算法
步骤3: 定义生成器算法
步骤4: 编写训练算法
步骤5: 训练模型
步骤6: 测试模型
步骤0: 导入数据集
第一步是下载并将数据加载到内存中。我们将使用 CelebFaces Attributes Dataset (CelebA)来训练你的对抗性网络。主要分以下三个步骤:
1. 下载数据集:
https://s3.amazonaws.com/video.udacity-data.com/topher/2018/November/5be7eb6f_processed-celeba-small/processed-celeba-small.zip;
2. 解压缩数据集;
3. Clone 如下 GitHub地址:
https://github.com/Ahmad-shaikh575/Face-Generation-using-GANS
这样做之后,你可以在 colab 环境中打开它,或者你可以使用你自己的 pc 来训练模型。
导入必要的库
#import the neccessary libraries
import pickle as pkl
import matplotlib.pyplot as plt
import numpy as np
import torch.nn as nn
import torch.nn.functional as F
import torch
from torchvision import datasets
from torchvision import transforms
import torch
import torch.optim as optim步骤1: 加载及预处理图像
在这一步中,我们将预处理在前一节中下载的图像数据。
将采取以下步骤:
-
调整图片大小
-
转换成张量
-
加载到 PyTorch 数据集中
-
加载到 PyTorch DataLoader 中
# Define hyperparameters
batch_size = 32
img_size = 32
data_dir='processed_celeba_small/'
# Apply the transformations
transform = transforms.Compose([transforms.Resize(image_size)
,transforms.ToTensor()])
# Load the dataset
imagenet_data = datasets.ImageFolder(data_dir,transform= transform)
# Load the image data into dataloader
celeba_train_loader = torch.utils.data.DataLoader(imagenet_data,
batch_size,
shuffle=True)图像的大小应该足够小,这将有助于更快地训练模型。Tensors 基本上是 NumPy 数组,我们只是将图像转换为在 PyTorch 中所必需的 NumPy 数组。
然后我们加载这个转换成的 PyTorch 数据集。在那之后,我们将把我们的数据分成小批量。这个数据加载器将在每次迭代时向我们的模型训练过程提供图像数据。
随着数据的加载完成。现在,我们可以预处理图像。
图像的预处理
我们将在训练过程中使用 tanh 激活函数。该生成器的输出范围在 -1到1之间。我们还需要对这个范围内的图像进行缩放。代码如下所示:
def scale(img, feature_range=(-1, 1)):
'''
Scales the input image into given feature_range
'''
min,max = feature_range
img = img * (max-min) + min
return img这个函数将对所有输入图像缩放,我们将在后面的训练中使用这个函数。
现在我们已经完成了无聊的预处理步骤。
接下来是令人兴奋的部分,现在我们需要为我们的生成器和判别器神经网络编写代码。
步骤2: 定义判别器算法
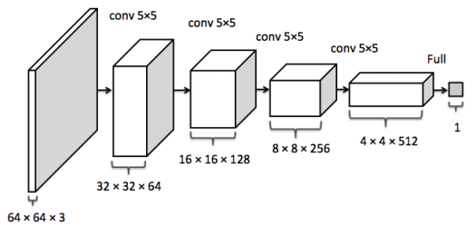
判别器是一个可以区分真假图像的神经网络。真实的图像和由生成器生成的图像都将提供给它。
我们将首先定义一个辅助函数,这个辅助函数在创建卷积网络层时非常方便。
# helper conv function
def conv(in_channels, out_channels, kernel_size, stride=2, padding=1, batch_norm=True):
layers = []
conv_layer = nn.Conv2d(in_channels, out_channels,
kernel_size, stride, padding, bias=False)
#Appending the layer
layers.append(conv_layer)
#Applying the batch normalization if it's given true
if batch_norm:
layers.append(nn.BatchNorm2d(out_channels))
# returning the sequential container
return nn.Sequential(*layers)这个辅助函数接收创建任何卷积层所需的参数,并返回一个序列化的容器。现在我们将使用这个辅助函数来创建我们自己的判别器网络。
class Discriminator(nn.Module):
def __init__(self, conv_dim):
super(Discriminator, self).__init__()
self.conv_dim = conv_dim
#32 x 32
self.cv1 = conv(3, self.conv_dim, 4, batch_norm=False)
#16 x 16
self.cv2 = conv(self.conv_dim, self.conv_dim*2, 4, batch_norm=True)
#4 x 4
self.cv3 = conv(self.conv_dim*2, self.conv_dim*4, 4, batch_norm=True)
#2 x 2
self.cv4 = conv(self.conv_dim*4, self.conv_dim*8, 4, batch_norm=True)
#Fully connected Layer
self.fc1 = nn.Linear(self.conv_dim*8*2*2,1)
def forward(self, x):
# After passing through each layer
# Applying leaky relu activation function
x = F.leaky_relu(self.cv1(x),0.2)
x = F.leaky_relu(self.cv2(x),0.2)
x = F.leaky_relu(self.cv3(x),0.2)
x = F.leaky_relu(self.cv4(x),0.2)
# To pass throught he fully connected layer
# We need to flatten the image first
x = x.view(-1,self.conv_dim*8*2*2)
# Now passing through fully-connected layer
x = self.fc1(x)
return x步骤3: 定义生成器算法
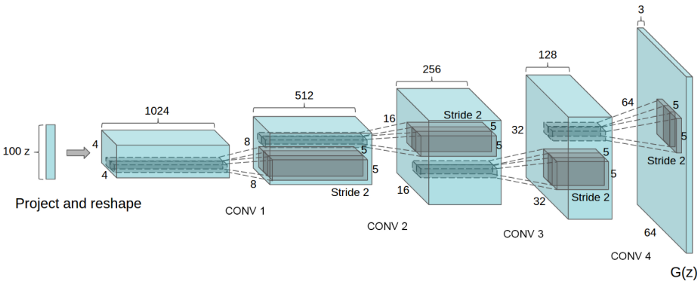
正如你们从图中看到的,我们给网络一个高斯矢量或者噪声矢量,它输出 s 中的值。图上的“ z”表示噪声,右边的 G (z)表示生成的样本。
与判别器一样,我们首先创建一个辅助函数来构建生成器网络,如下所示:
def deconv(in_channels, out_channels, kernel_size, stride=2, padding=1, batch_norm=True):
layers = []
convt_layer = nn.ConvTranspose2d(in_channels, out_channels,
kernel_size, stride, padding, bias=False)
# Appending the above conv layer
layers.append(convt_layer)
if batch_norm:
# Applying the batch normalization if True
layers.append(nn.BatchNorm2d(out_channels))
# Returning the sequential container
return nn.Sequential(*layers)现在,是时候构建生成器网络了! !
class Generator(nn.Module):
def __init__(self, z_size, conv_dim):
super(Generator, self).__init__()
self.z_size = z_size
self.conv_dim = conv_dim
#fully-connected-layer
self.fc = nn.Linear(z_size, self.conv_dim*8*2*2)
#2x2
self.dcv1 = deconv(self.conv_dim*8, self.conv_dim*4, 4, batch_norm=True)
#4x4
self.dcv2 = deconv(self.conv_dim*4, self.conv_dim*2, 4, batch_norm=True)
#8x8
self.dcv3 = deconv(self.conv_dim*2, self.conv_dim, 4, batch_norm=True)
#16x16
self.dcv4 = deconv(self.conv_dim, 3, 4, batch_norm=False)
#32 x 32
def forward(self, x):
# Passing through fully connected layer
x = self.fc(x)
# Changing the dimension
x = x.view(-1,self.conv_dim*8,2,2)
# Passing through deconv layers
# Applying the ReLu activation function
x = F.relu(self.dcv1(x))
x= F.relu(self.dcv2(x))
x= F.relu(self.dcv3(x))
x= F.tanh(self.dcv4(x))
#returning the modified image
return x为了使模型更快地收敛,我们将初始化线性和卷积层的权重。根据相关研究论文中的描述:所有的权重都是从0中心的正态分布初始化的,标准差为0.02。
我们将为此目的定义一个功能如下:
def weights_init_normal(m):
classname = m.__class__.__name__
# For the linear layers
if 'Linear' in classname:
torch.nn.init.normal_(m.weight,0.0,0.02)
m.bias.data.fill_(0.01)
# For the convolutional layers
if 'Conv' in classname or 'BatchNorm2d' in classname:
torch.nn.init.normal_(m.weight,0.0,0.02)现在我们将超参数和两个网络初始化如下:
# Defining the model hyperparamameters
d_conv_dim = 32
g_conv_dim = 32
z_size = 100 #Size of noise vector
D = Discriminator(d_conv_dim)
G = Generator(z_size=z_size, conv_dim=g_conv_dim)
# Applying the weight initialization
D.apply(weights_init_normal)
G.apply(weights_init_normal)
print(D)
print()
print(G)输出结果大致如下:
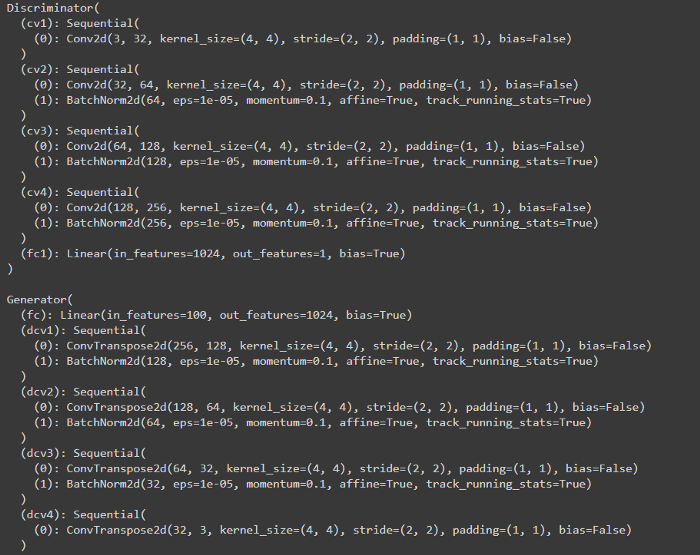
判别器损失:
根据 DCGAN Research Paper 论文中描述:
判别器总损失 = 真图像损失 + 假图像损失,即:d_loss = d_real_loss + d_fake_loss。
不过,我们希望鉴别器输出1表示真正的图像和0表示假图像,所以我们需要设置的损失来反映这一点。
我们将定义双损失函数。一个是真正的损失,另一个是假的损失,如下:
def real_loss(D_out,smooth=False):
batch_size = D_out.size(0)
if smooth:
labels = torch.ones(batch_size)*0.9
else:
labels = torch.ones(batch_size)
labels = labels.to(device)
criterion = nn.BCEWithLogitsLoss()
loss = criterion(D_out.squeeze(), labels)
return loss
def fake_loss(D_out):
batch_size = D_out.size(0)
labels = torch.zeros(batch_size)
labels = labels.to(device)
criterion = nn.BCEWithLogitsLoss()
loss = criterion(D_out.squeeze(), labels)
return loss生成器损失:
根据 DCGAN Research Paper 论文中描述:
生成器的目标是让判别器认为它生成的图像是真实的。
现在,是时候为我们的网络设置优化器了:
lr = 0.0005
beta1 = 0.3
beta2 = 0.999 # default value
# Optimizers
d_optimizer = optim.Adam(D.parameters(), lr, betas=(beta1, beta2))
g_optimizer = optim.Adam(G.parameters(), lr, betas=(beta1, beta2))我将为我们的训练使用 Adam 优化器。因为它目前被认为是对GANs最有效的。根据上述介绍论文中的研究成果,确定了超参数的取值范围。他们已经尝试了它,这些被证明是最好的!超参数设置如下:
步骤4: 编写训练算法
我们必须为我们的两个神经网络编写训练算法。首先,我们需要初始化噪声向量,并在整个训练过程中保持一致。
# Initializing arrays to store losses and samples
samples = []
losses = []
# We need to initilialize fixed data for sampling
# This would help us to evaluate model's performance
sample_size=16
fixed_z = np.random.uniform(-1, 1, size=(sample_size, z_size))
fixed_z = torch.from_numpy(fixed_z).float()对于判别器:
我们首先将真实的图像输入判别器网络,然后计算它的实际损失。然后生成伪造图像并输入判别器网络以计算虚假损失。
在计算了真实和虚假损失之后,我们对其进行求和,并采取优化步骤进行训练。
# setting optimizer parameters to zero
# to remove previous training data residue
d_optimizer.zero_grad()
# move real images to gpu memory
real_images = real_images.to(device)
# Pass through discriminator network
dreal = D(real_images)
# Calculate the real loss
dreal_loss = real_loss(dreal)
# For fake images
# Generating the fake images
z = np.random.uniform(-1, 1, size=(batch_size, z_size))
z = torch.from_numpy(z).float()
# move z to the GPU memory
z = z.to(device)
# Generating fake images by passing it to generator
fake_images = G(z)
# Passing fake images from the disc network
dfake = D(fake_images)
# Calculating the fake loss
dfake_loss = fake_loss(dfake)
#Adding both lossess
d_loss = dreal_loss + dfake_loss
# Taking the backpropogation step
d_loss.backward()
d_optimizer.step()对于生成器:
对于生成器网络的训练,我们也会这样做。刚才在通过判别器网络输入假图像之后,我们将计算它的真实损失。然后优化我们的生成器网络。
## Training the generator for adversarial loss
#setting gradients to zero
g_optimizer.zero_grad()
# Generate fake images
z = np.random.uniform(-1, 1, size=(batch_size, z_size))
z = torch.from_numpy(z).float()
# moving to GPU's memory
z = z.to(device)
# Generating Fake images
fake_images = G(z)
# Calculating the generator loss on fake images
# Just flipping the labels for our real loss function
D_fake = D(fake_images)
g_loss = real_loss(D_fake, True)
# Taking the backpropogation step
g_loss.backward()
g_optimizer.step()步骤5: 训练模型
现在我们将开始100个epoch的训练: D
经过训练,损失的图表看起来大概是这样的:
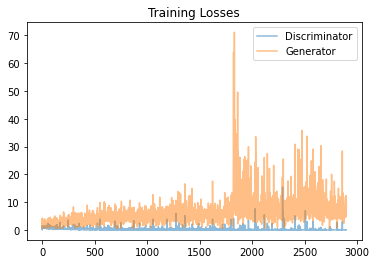
我们可以看到,判别器 Loss 是相当平滑的,甚至在100个epoch之后收敛到某个特定值。而生成器的Loss则飙升。
我们可以从下面步骤6中的结果看出,60个时代之后生成的图像是扭曲的。由此可以得出结论,60个epoch是一个最佳的训练节点。
步骤6: 测试模型
10个epoch之后:

20个epoch之后:

30个epoch之后:

40个epoch之后:

50个epoch之后:

60个epoch之后:

70个epoch之后:

80个epoch之后:

90个epoch之后:

100个epoch之后:

总结
我们可以看到,训练一个生成对抗性网络并不意味着它一定会产生好的图像。
从结果中我们可以看出,训练40-60个 epoch 的生成器生成的图像相对比其他更好。
您可以尝试更改优化器、学习速率和其他超参数,以使其生成更好的图像!