1 B树
Balanced 树,多路平衡搜索树
1.1 特征
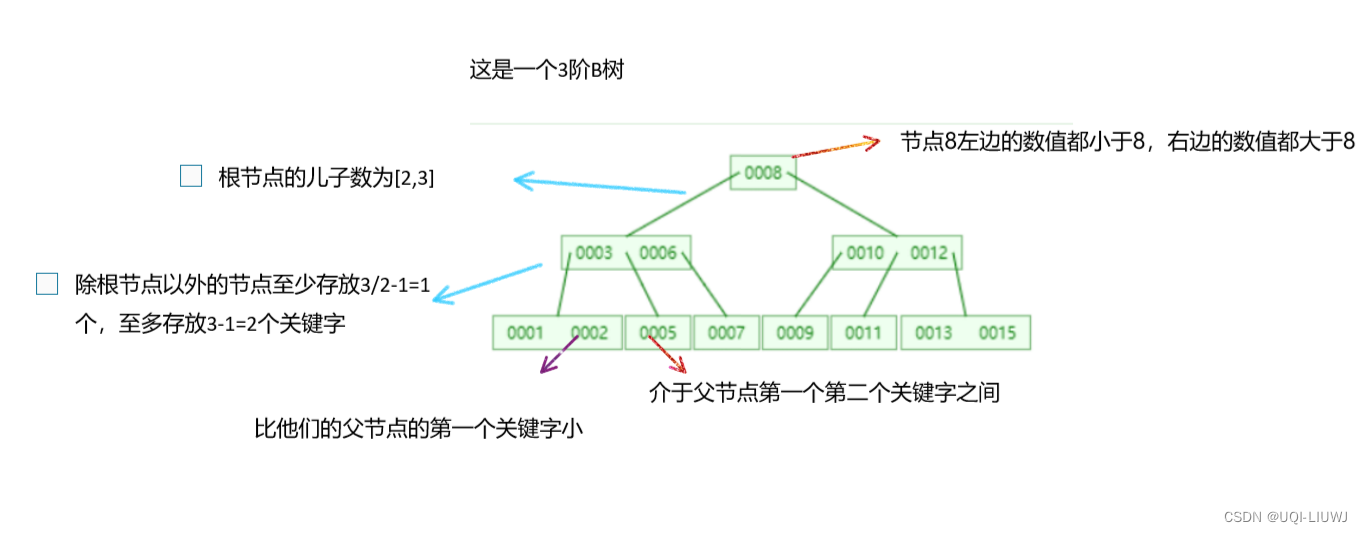
一个m阶的B树具有如下几个特征:
- 根结点的儿子数为[2, M];
- 除根结点以外的非叶子结点的儿子数为[M/2, M];(M/2向上取整)
- 每个结点存放至少M/2-1(M/2向上取整)和至多M-1个关键字;
- 非叶子结点的关键字个数=指向儿子的指针个数-1;
- 非叶子结点的关键字:K[1], K[2], …, K[M-1];且K[i] < K[i+1];
- 非叶子结点的指针:P[1], P[2], …, P[M];
- P[1]指向关键字小于K[1]的子树
- P[M]指向关键字大于K[M-1]的子树
- 其它P[i]指向关键字属于(K[i-1], K[i])的子树;
- 所有叶子结点位于同一层
上面这些特征可能看得云里雾里的,我们直接看一个例子:
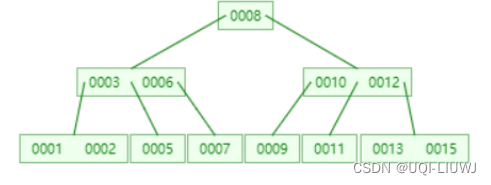
1.2 举例
1.3 查询
比如查询9:
从根节点开始,先跟8比较
大于8,所以找到8的右孩子,也就是(0010,0012)节点
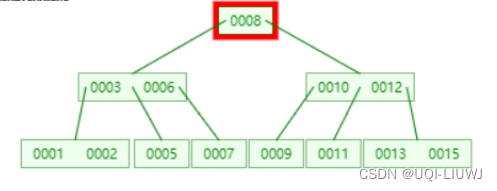
跟10比较,比10小,所以找到该节点的最左孩子9
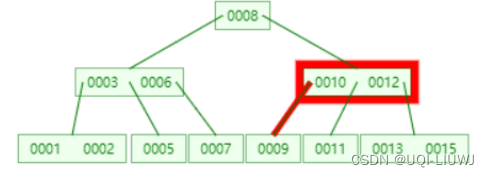
跟9比较,等于要查找的数值,返回

1.4 插入
首先查找,找到合适的位置,也就是(0013,0015)这个节点
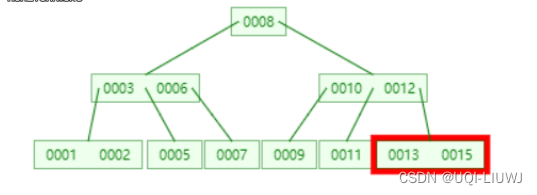
16插入该节点,变成(0013,0015,0016)
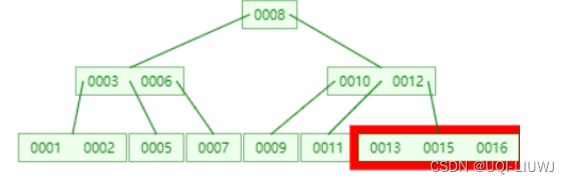
由于这是一个3阶B数,所有每个节点里面最多有3-1=2个关键词
为了符合B-树的特性,将会增加父节点的元素个数
向上传递元素,传递的原则就是中间值优先,所以传递元素为15
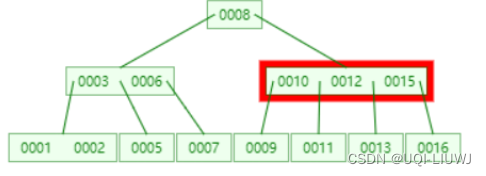
此时父节点不满足3阶B数特性了,所以再往上一级传递元素,传递元素为12
根节点,变成了(0008,0012),他需要有三个孩子,所以将根节点的右孩子,拆分成了两个
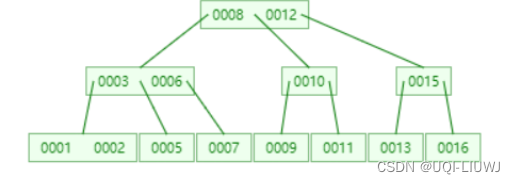
1.5 删减
首先还是要先找到目标值,即16这个结点

将其删除,此时15节点的子孩子只有一个,不符合3阶B树需要[3/2+1,3]个子孩子的限制
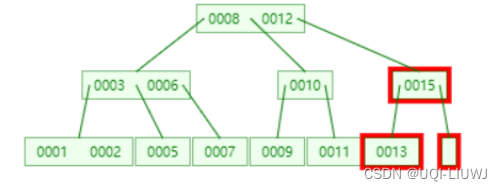
将16的父节点元素较大值15往下放
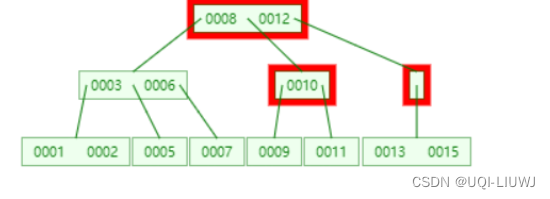
同时将15的父节点元素较大值12往下放
此时根节点只有一个元素8,只能有两个子节点
将10和12合并成(0010,0012)
2 B+树
B-树的变体,也是一种多路搜索树
2.1 B+树特征
一棵m阶的B+树和m阶的B-树的差异在于:
- 有n棵子树的节点中含有n个关键字(即每个关键字对应一棵子树);
- 叶子节点中包含了全部关键字的信息, 及指向含这些关键字记录的指针
- 叶子节点本身依关键字的大小自小而大顺序链接;
- 所有的非终端节点可以看成是索引部分,节点中仅含有其子树(根节点)中的最大(或最小)关键字哦(非叶子节点不含有任何信息)
- 除根节点外,其他所有节点中所含关键字的个数必须
>=⌈m/2⌉(比B树多一个)
2.2 举例
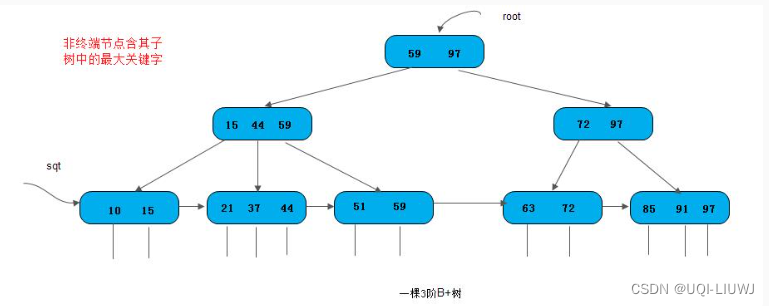
- 通常在
B+树上有两个指针头, 一个指向根节点,另一个指向关键字最小的叶子节点。 - 因此,可以对
B+树进行两种查找运算: 一种是从最小关键字起顺序查找,另一种是从根节点开始,进行随机查找
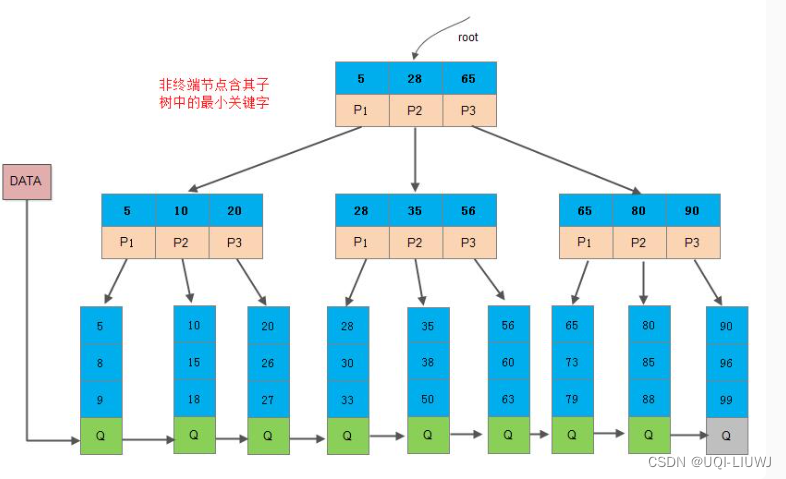
2.3 B+树相比于B树的优势
2.3.1 磁盘读写代价更低
- B+树的内部结点并没有指向关键字具体信息的指针,因此其内部结点占用内存相对B 树更小。
- 如果把所有同一内部结点的关键字存放在同一盘块中,那么盘块所能容纳的关键字数量也越多,一次性读入内存中的可以查找的关键字也就越多。
- ——》相对来说IO读写次数也就降低了;
2.3.2 查询效率更加稳定
- 由于非叶子结点并不是最终指向文件内容的结点,而只是叶子结点中关键字的索引。所以任何关键字的查找必须走一条从根结点到叶子结点的路。
- 所有关键字查询的路径长度相同,导致每一个数据的查询效率相当
2.3.3 便于范围查询
- 范围查找是数据库的常态
- B树虽然提高了IO性能,但是并没有解决元素遍历的效率低下