文章目录
- 前言
- 一、使用的工具
- 二、学习资源分享
- 三、libtorch环境配置
- 1.配置CUDA、nvcc、cudnn
- 2.下载libtorch
- 3.CLion配置libtorch
- 4.CMake Application指定Environment variables
- 5.测试libtorch
- 四、PyTorch CUDA CPP项目流程
- 1.使用`CLion`结合`torch extension`编写可以调用cuda的C++代码
- 2.编写`CU`设备代码,在代码中调用CUDA核函数使用GPU运算
- 3.创建header定义设备函数
- 4.编写`CPP`主机代码,在代码中使用`PYBIND`库连接pytorch和c++代码,使用主机函数调用设备函数
- 5.在`Pycharm`中创建`setup.py`脚本,将C++编写的cuda代码编译为python的一个package
- 6.使用`pip`安装自定义的cuda代码库
- 7.安装好自定义的cuda自定义库之后,编写python代码调用
- 五、总结
前言
这学期确定了研究方法,具体为三维重建相关,转而研究三维重建相关的知识。最近3D Gaussian Splatting方法效果十分的好,并且开源了源代码,因此十分值得对其源码进行研究,源码中对于可微光栅化的实现是基于CUDA实现的,因此想要后续对这块内容进行改进,则必须了解CUDA程序是如何编写的,作为一名DL农工,学习CUDA编程也有助于自己对于整个DL流程的理解,也能够进一步拓展自己的编程技术,因此无论出于什么目的,作为DL农工,我认为有必要掌握这项技术。
本教程仅作为Pytorch CUDA CPP开发的简易教程,我也是初学者。同时本教程的目的也是为了方便不熟悉CUDA项目结构的人快速了解一份新的程序的文件结构是怎样的。
一、使用的工具
Pytorch, libtorch, CUDA, C++, CLion, Pycharm
二、学习资源分享
如果想要详细了解整个CUDA程序的工作原理,可以观看这个详细教程:CUDA编程基础入门系列
如果想功利点的学习如何使用Pytorch调用CUDA程序,可以观看这个教程:Pytorch+cpp/cuda extension 教学
本简易教程也是基于第二个视频教程写的,这个教程讲了一种通用的Pytorch、CUDA程序编写范式,使用pytorch+cpp+cuda开发的几乎都遵循这套代码编写流程,因此学会怎么写,基本上就能看明白其他人的CUDA程序文件是如何组织的,尽管你还是有可能看不懂CUDA代码,但是你学完后一定能看明白CUDA程序是如何组织的。
自定义 C++ 和 CUDA 扩展
PYTORCH C++ API
三、libtorch环境配置
注意:我所有的操作都是在Windows上进行的,Linux上的操作应该也大差不差
libtorch环境配置的教程有很多,你可以参考其他人的博客进行配置,这里我仅贴我使用CLion配置libtorch的流程
1.配置CUDA、nvcc、cudnn
该项不进行说明,有许多攻略可供参考,这里贴一篇博客 Windows安装CUDA及cuDNN【保姆级教程】
注意安装的CUDA版本不要太新了,且要与libtorch提供的CUDA版本保持一致,目前官网提供的libtorch CUDA版本为11.8,因此你安装的CUDA最好也是11.8,否则会有许多奇怪的错误
你都来看CUDA编程了,不至于DL环境还不会配置吧🤣
2.下载libtorch
前往pytorch官网下载libtorch:Pytorch
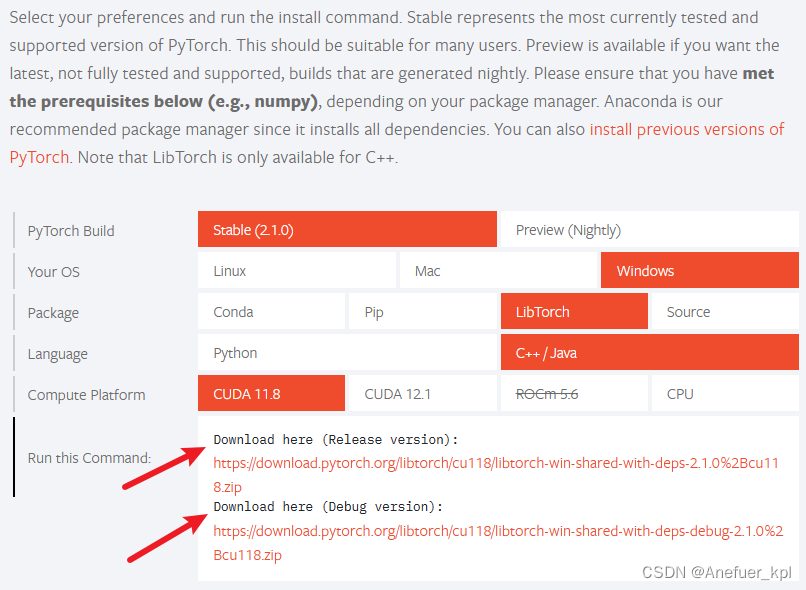
你可以选择CPU和CUDA版本,这就和Pytorch的CPU和CUDA版是一个意思,个人感觉对于Pytorch CUDA开发,CPU和CUDA版没有什么区别,libtorch就相当于一个C++版本的Pytorch,但是我们的目的仅仅是用C++版的torch调用CUDA程序,最后还是要用python代码调用C++代码,最后由C++调用CUDA程序。为了避免出现奇怪的bug,还是一开始就下载CUDA版的吧。
有release和debug两个版本可以选择,debug版支持debug操作,相应容量会大些;release版不能debug,容量会小很多。你自己选择,一般选debug版。
3.CLion配置libtorch
创建CLion项目,一定要创建 C++ Executable 项目,不要创建CUDA Executable,否则CMAKE时会不通过,出现奇怪的BUG我也不知道为啥。
在CMakeLists.txt中填入一下内容
有#标识的表示需要修改成你自己的libtorch里对应的路径
cmake_minimum_required(VERSION 3.25)
project(xxx) # xxx为你自己的项目名称,这部分为CLion自动生成的
set(CMAKE_CXX_STANDARD 17)
set(Torch_DIR E:/CLion/libtorch/share/cmake/Torch) # your own path
find_package(Torch REQUIRED)
include_directories(E:/CLion/libtorch/include) # your own path
include_directories(E:/CLion/libtorch/include/torch/csrc/api/include) # your own path
add_executable(xxx main.cpp)
target_link_libraries(xxx ${TORCH_LIBRARIES})
set_property(TARGET xxx PROPERTY CXX_STANDARD 17)
4.CMake Application指定Environment variables
经过实测,如果不指定这个选项,会出现CMake时找不到xxx.dll,这些dll文件其实是存在的,但就是找不到位置,因此需要手动去指定,参考我的这篇博客:CLion配置libtorch找不到xxx.dll
5.测试libtorch
在main.cpp粘贴如下代码:
#include <iostream>
#include <torch/torch.h>
int main() {
torch::Tensor tensor = torch::rand({2, 3});
std::cout << tensor << std::endl;
std::cout << torch::cuda::is_available() << std::endl;
std::cout << "Hello, World!" << std::endl;
return 0;
}
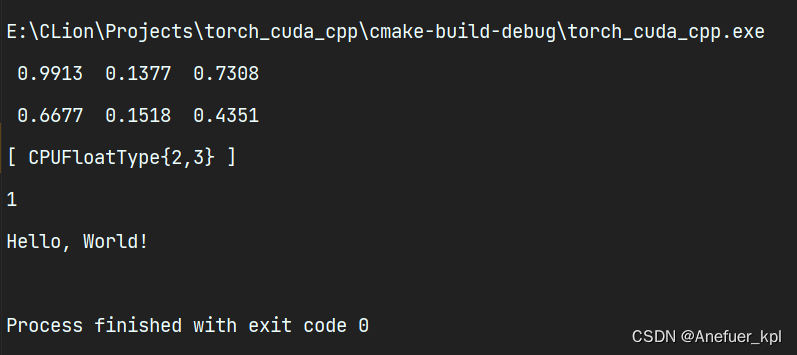
出现上面的输出,libtorch配置成功
如果在CMAKE时出现Unicode相关字样的报错,请参考我的这篇博客:warning C4819: 该文件包含不能在当前代码页(936)中表示的字符。请将该文件保存为 Unicode 格式以防止数据丢失
四、PyTorch CUDA CPP项目流程
可以把C++理解为沟通Pytorch代码和CUDA代码的桥梁
1.使用CLion结合torch extension编写可以调用cuda的C++代码
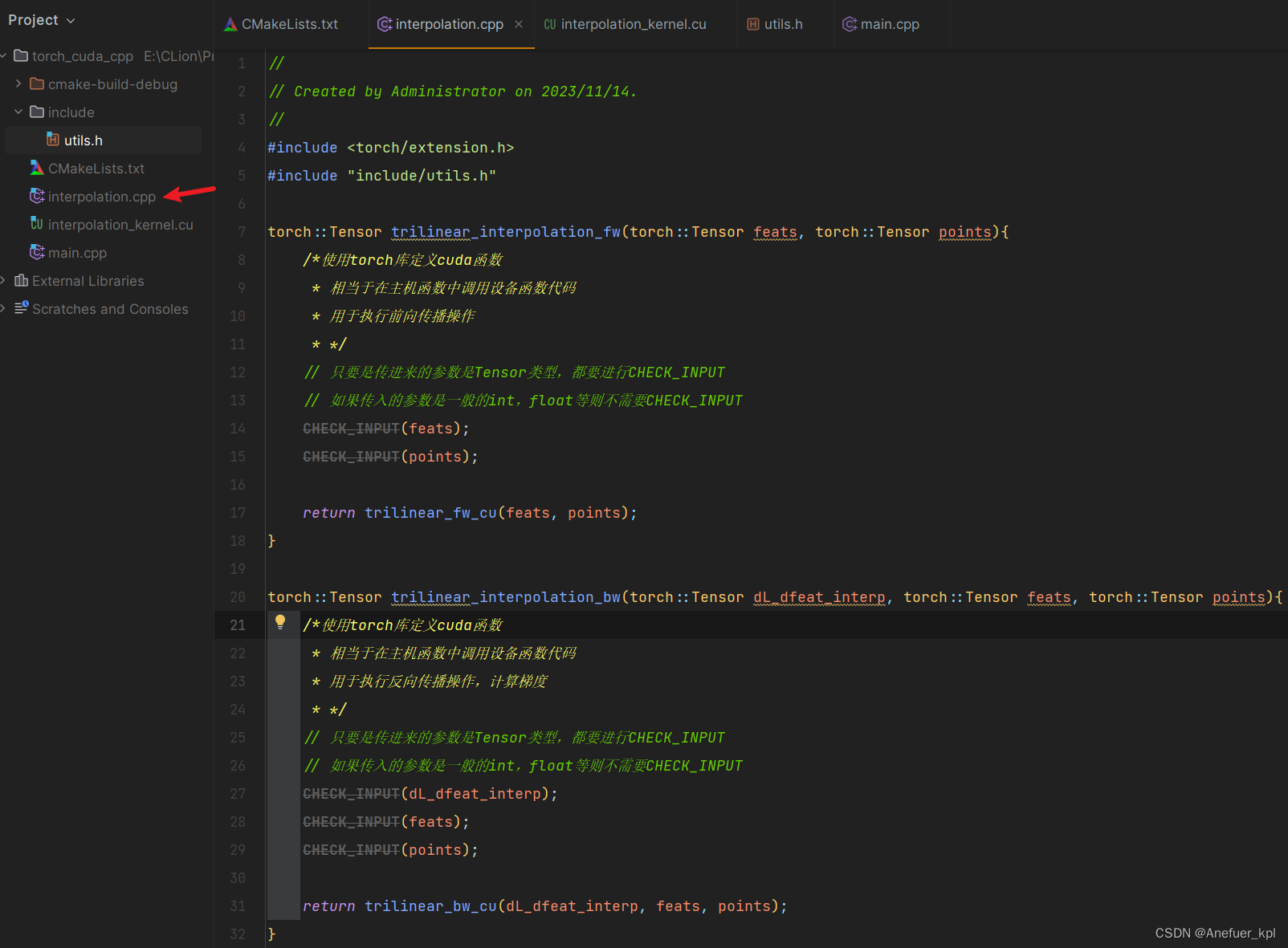
创建interpolation.cpp,你可以理解为该文件内存放着主机函数(即在CPU上执行的函数),用于调用设备函数(即在GPU上执行的函数)。
#include <torch/extension.h>
#include "include/utils.h" // 自定义的header
torch::Tensor trilinear_interpolation_fw(torch::Tensor feats, torch::Tensor points){
/*使用torch库定义cuda函数
* 相当于在主机函数中调用设备函数代码
* 用于执行前向传播操作
* */
// 只要是传进来的参数是Tensor类型,都要进行CHECK_INPUT
// 如果传入的参数是一般的int,float等则不需要CHECK_INPUT
CHECK_INPUT(feats);
CHECK_INPUT(points);
// trilinear_fw_cu() 为设备函数,
// 可以理解为主机函数作为设备函数的入口,这只是一种写法,你也可以有别的写法
return trilinear_fw_cu(feats, points);
}
torch::Tensor trilinear_interpolation_bw(torch::Tensor dL_dfeat_interp, torch::Tensor feats, torch::Tensor points){
/*使用torch库定义cuda函数
* 相当于在主机函数中调用设备函数代码
* 用于执行反向传播操作,计算梯度
* */
// 只要是传进来的参数是Tensor类型,都要进行CHECK_INPUT
// 如果传入的参数是一般的int,float等则不需要CHECK_INPUT
CHECK_INPUT(dL_dfeat_interp);
CHECK_INPUT(feats);
CHECK_INPUT(points);
return trilinear_bw_cu(dL_dfeat_interp, feats, points);
}
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
/*pybind库用于作为连接python和C++的桥梁
* name_: 表示python调用c++函数的名称(名称可一致也可以不一致),f:表示c++函数的地址*/
m.def("trilinear_interpolation_fw", &trilinear_interpolation_fw);
m.def("trilinear_interpolation_bw", &trilinear_interpolation_bw);
}
2.编写CU设备代码,在代码中调用CUDA核函数使用GPU运算
注意:设备函数卸载 .cu 文件中,只有这样在编译时nvcc才能识别
创建interpolation_kernel.cu编写设备函数
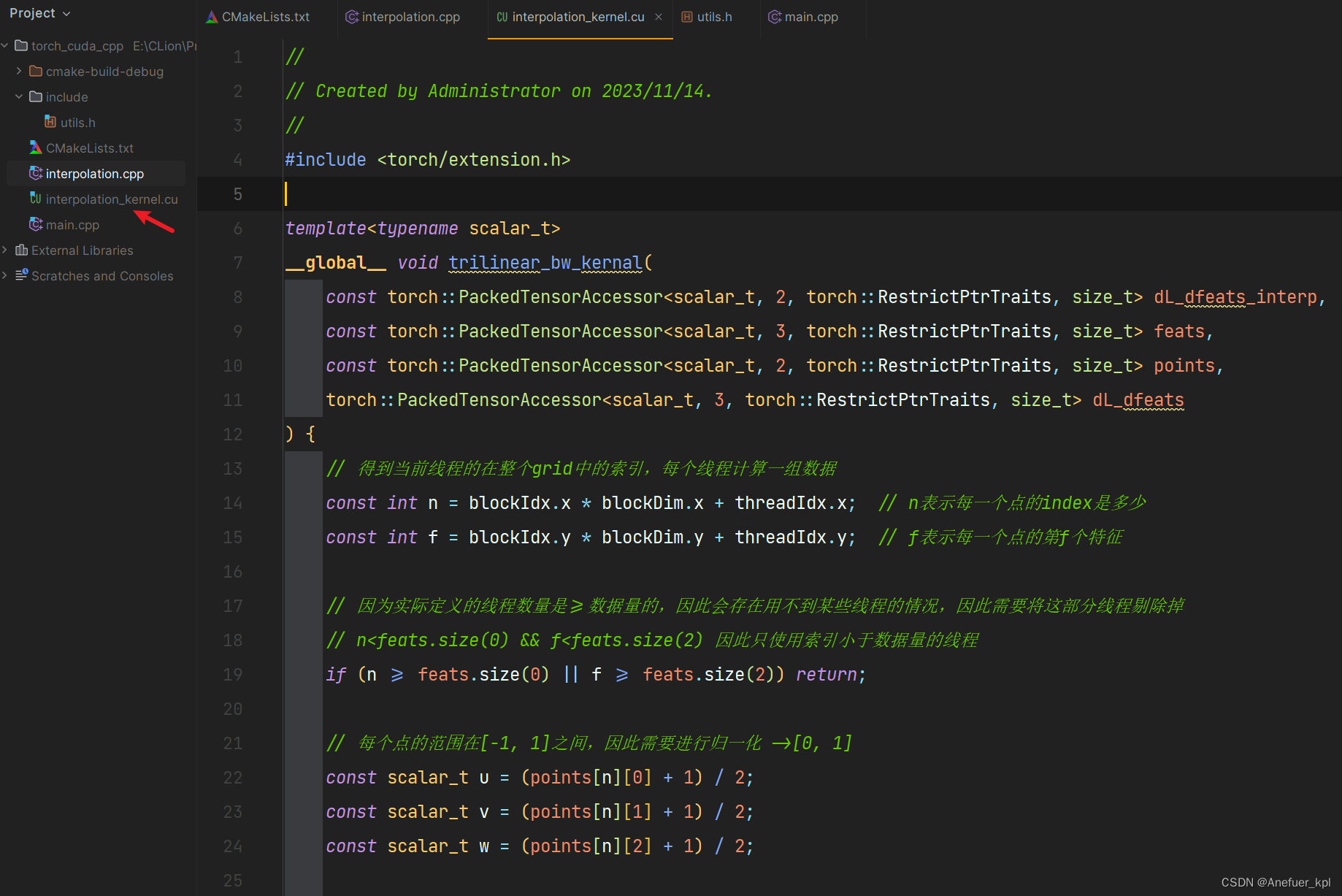
#include <torch/extension.h>
template<typename scalar_t>
__global__ void trilinear_bw_kernal(
const torch::PackedTensorAccessor<scalar_t, 2, torch::RestrictPtrTraits, size_t> dL_dfeats_interp,
const torch::PackedTensorAccessor<scalar_t, 3, torch::RestrictPtrTraits, size_t> feats,
const torch::PackedTensorAccessor<scalar_t, 2, torch::RestrictPtrTraits, size_t> points,
torch::PackedTensorAccessor<scalar_t, 3, torch::RestrictPtrTraits, size_t> dL_dfeats
) {
// 得到当前线程的在整个grid中的索引,每个线程计算一组数据
const int n = blockIdx.x * blockDim.x + threadIdx.x; // n表示每一个点的index是多少
const int f = blockIdx.y * blockDim.y + threadIdx.y; // f表示每一个点的第f个特征
// 因为实际定义的线程数量是>=数据量的,因此会存在用不到某些线程的情况,因此需要将这部分线程剔除掉
// n<feats.size(0) && f<feats.size(2) 因此只使用索引小于数据量的线程
if (n >= feats.size(0) || f >= feats.size(2)) return;
// 每个点的范围在[-1, 1]之间,因此需要进行归一化 ->[0, 1]
const scalar_t u = (points[n][0] + 1) / 2;
const scalar_t v = (points[n][1] + 1) / 2;
const scalar_t w = (points[n][2] + 1) / 2;
// 计算内插权重
// 三线性插值可以分解为两组双线性插值加一组单线性插值
// a b c d表示计算双线性插值时的4个顶点对应的插值权重
const scalar_t a = (1 - v) * (1 - w);
const scalar_t b = (1 - v) * w;
const scalar_t c = v * (1 - w);
const scalar_t d = 1 - a - b - c;
// 计算偏导数,我们需要实现根据公式计算出8个特征点的偏微分
dL_dfeats[n][0][f] = (1-u)*a*dL_dfeats_interp[n][f];
dL_dfeats[n][1][f] = (1-u)*b*dL_dfeats_interp[n][f];
dL_dfeats[n][2][f] = (1-u)*c*dL_dfeats_interp[n][f];
dL_dfeats[n][3][f] = (1-u)*d*dL_dfeats_interp[n][f];
dL_dfeats[n][4][f] = u*a*dL_dfeats_interp[n][f];
dL_dfeats[n][5][f] = u*b*dL_dfeats_interp[n][f];
dL_dfeats[n][6][f] = u*c*dL_dfeats_interp[n][f];
dL_dfeats[n][7][f] = u*d*dL_dfeats_interp[n][f];
}
// template <typename scalar_t> 表示告诉函数,函数输入参数的类型会根据scalar_t进行可变的对应
// 下面的参数的输入方法也是固定的,之后可以复制后并简单修改后使用
template<typename scalar_t>
__global__ void trilinear_fw_kernal(
const torch::PackedTensorAccessor<scalar_t, 3, torch::RestrictPtrTraits, size_t> feats,
const torch::PackedTensorAccessor<scalar_t, 2, torch::RestrictPtrTraits, size_t> points,
torch::PackedTensorAccessor<scalar_t, 2, torch::RestrictPtrTraits, size_t> feat_interp
) {
// 得到当前线程的在整个grid中的索引,每个线程计算一组数据
const int n = blockIdx.x * blockDim.x + threadIdx.x; // n表示每一个点的index是多少
const int f = blockIdx.y * blockDim.y + threadIdx.y; // f表示每一个点的第f个特征
// 因为实际定义的线程数量是>=数据量的,因此会存在用不到某些线程的情况,因此需要将这部分线程剔除掉
// n<feats.size(0) && f<feats.size(2) 因此只使用索引小于数据量的线程
if (n >= feats.size(0) || f >= feats.size(2)) return;
// 每个点的范围在[-1, 1]之间,因此需要进行归一化 ->[0, 1]
const scalar_t u = (points[n][0] + 1) / 2;
const scalar_t v = (points[n][1] + 1) / 2;
const scalar_t w = (points[n][2] + 1) / 2;
// 计算内插权重
// 三线性插值可以分解为两组双线性插值加一组单线性插值
// a b c d表示计算双线性插值时的4个顶点对应的插值权重
const scalar_t a = (1 - v) * (1 - w);
const scalar_t b = (1 - v) * w;
const scalar_t c = v * (1 - w);
const scalar_t d = 1 - a - b - c;
feat_interp[n][f] = (1 - u) * (a * feats[n][0][f] +
b * feats[n][1][f] +
c * feats[n][2][f] +
d * feats[n][3][f]) +
u * (a * feats[n][4][f] +
b * feats[n][5][f] +
c * feats[n][6][f] +
d * feats[n][7][f]);
}
/*如果想要在C++中回传多个值,那么可以直接回传一个vector类型,
* std::vector<torch::Tensor> trilinear_fw_cu(){
* return {a, b, c, ...}
* }
* */
torch::Tensor trilinear_fw_cu(torch::Tensor feats, torch::Tensor points) {
/*使用torch库定义cuda函数
* fw:表示前向传播 bw:表示反向传播 cu:表示这是一个cuda程序
* feats: [N, 8, F],表示N个元素,每个元素有8个顶点以及对应的特征
* points: [N, 3],表示N个元素,每个元素有3个顶点坐标
* */
const int N = feats.size(0), F = feats.size(2);
// 生成output变量,并指定变量的数据类型,并指定数据存放在哪个设备上
// 将运算结果存储在output变量中
torch::Tensor feat_interp = torch::zeros({N, F}, torch::dtype(torch::kFloat32).device(feats.device()));
// 定义grid和block大小
// 根据要同时运算的数据维度的大小,建立相应大小的thread
const dim3 threads(16, 16); // 定义一个block的大小,一个block内有多少个线程,一般一个block定义为256个线程不会出错
const dim3
blocks((N + threads.x - 1) / threads.x, (N + threads.y - 1) / threads.y); // 定义一个grid的大小,一个grid内有多少个block
/*假设输入的大小为N=20,F=10;而一个block的大小为16*16,
* 因此需要额外的一个block才能包含整个输入数据,因此一个grid的大小应该为2*1
* 线程的数量应该>=数据量 */
// 启动一个kernel
// 下面的书写方法是固定的,以后复制粘贴使用即可
/* AT_DISPATCH_FLOATING_TYPES: 表示启动的这个kernel用于浮点数运算,包括float32和float64的运算
* AT_DISPATCH_FLOATING_TYPES_HALF: 表示可以进行16,32,64位的浮点数运算
* AT_DISPATCH_INTEGRAL_TYPES: 表示进行32和64位整数运算
* feats.type(): 表示feats的数据类型
* "trilinear_fw_cu": 表示启动的kernel的名字,建议kernel的名称与函数的名称一致,方便找错误
* trilinear_fw_cu<scalar_t><<<blocks, threads>>>: 丢出一个kernel,指定kernel的名称,用于在设备函数上进行相应的运算
* <scalar_t>: 表示相当于一个placeholder,因为不知道参数具体是什么类型,因此先占个位置;如果知道是什么类型,直接写上对应的类型即可,比如float
* <<<blocks, threads>>>: 表示启动的kernel的线程数,以及线程的block数
* feats.packed_accessor<scalar_t, 3, torch::RestrictPtrTraits, size_t>()
* feats.packed_accessor,points.packed_accessor,feat_interp.packed_accessor 表示这个kernel函数传入的三个值
* packed_accessor表示这个值是一个指针,指向一个内存地址,这个地址存储着数据,并且这个地址可以被grid和block访问,并且这个地址可以被cuda的线程访问
* 只有Tensor参数才需要进行packed_accessor处理,如果是一般的参数则直接写入参数列表即可
* 比如:trilinear_fw_cu<scalar_t><<<blocks, threads>>>(a, feats.packed_accessor<scalar_t, 3, torch::RestrictPtrTraits, size_t>(), ...)
* scalar_t: 表示参数类型
* 3: 表示参数维度,这里表示传入的参数维度为3
* torch::RestrictPtrTraits: 表示这个参数是restrict指针,表示这个参数不能被修改 (torch::RestrictPtrTraits和size_t这两个参数一般不用改)
* size_t: 表示这个参数这种类型占用的内存大小,用于访问内存
* */
AT_DISPATCH_FLOATING_TYPES(feats.type(), "trilinear_fw_cu",
([&] {
trilinear_fw_kernal<scalar_t><<<blocks, threads>>>(
feats.packed_accessor<scalar_t, 3, torch::RestrictPtrTraits, size_t>(),
points.packed_accessor<scalar_t, 2, torch::RestrictPtrTraits, size_t>(),
feat_interp.packed_accessor<scalar_t, 2, torch::RestrictPtrTraits, size_t>()
);
}));
return feat_interp;
}
/*反向传播,利用梯度更细参数的值 */
torch::Tensor trilinear_bw_cu(
torch::Tensor dL_dfeat_interp,
torch::Tensor feats,
torch::Tensor points) {
/* 用于反向传播计算特征的梯度
* dL_dfeat_interp: 表示根据损失值计算出来的特征关于损失的梯度
* */
const int N = feats.size(0), F = feats.size(2);
torch::Tensor dL_dfeats = torch::zeros({N, 8, F}, feats.options()); // 微分后的值的size和原来是一样大的,保存每个特征的偏微分值
const dim3 threads(16, 16);
const dim3 blocks((N + threads.x - 1) / threads.x, (F + threads.y - 1) / threads.y);
AT_DISPATCH_FLOATING_TYPES(feats.type(), "trilinear_bw_cu",
([&] {
trilinear_bw_kernal<scalar_t><<<blocks, threads>>>(
dL_dfeat_interp.packed_accessor<scalar_t, 2, torch::RestrictPtrTraits, size_t>(),
feats.packed_accessor<scalar_t, 3, torch::RestrictPtrTraits, size_t>(),
points.packed_accessor<scalar_t, 2, torch::RestrictPtrTraits, size_t>(),
dL_dfeats.packed_accessor<scalar_t, 3, torch::RestrictPtrTraits, size_t>()
);
}));
return dL_dfeats;
}
3.创建header定义设备函数
创建include/utils.h头文件,定义函数
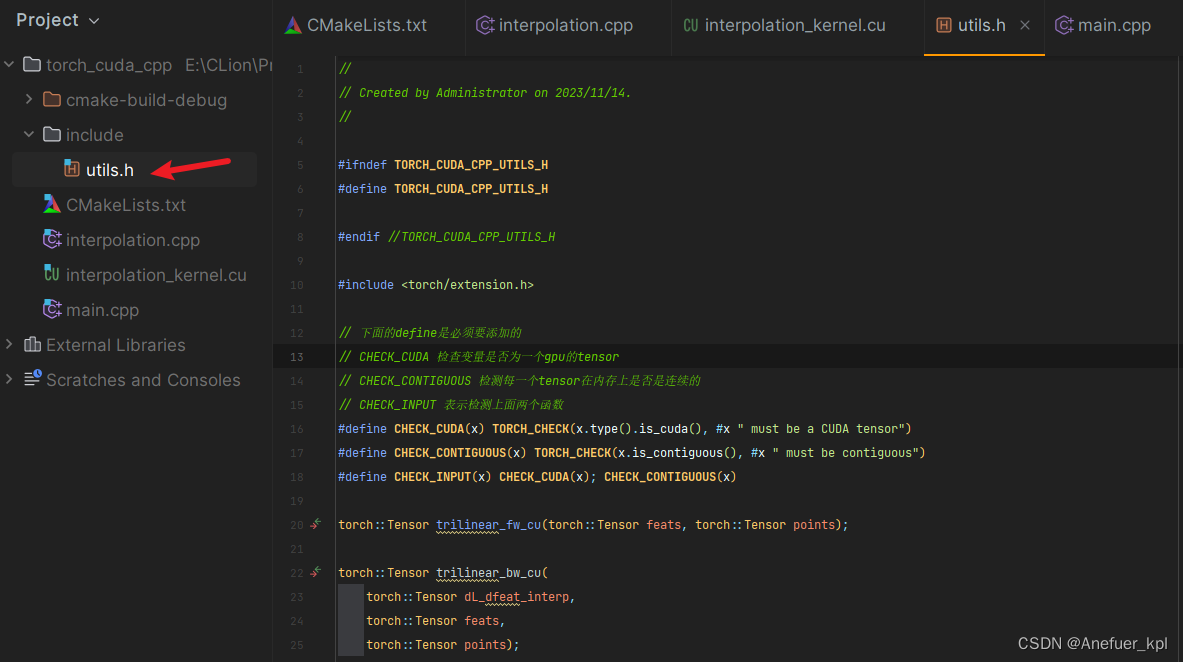
#ifndef TORCH_CUDA_CPP_UTILS_H
#define TORCH_CUDA_CPP_UTILS_H
#endif //TORCH_CUDA_CPP_UTILS_H
#include <torch/extension.h>
// 下面的define是必须要添加的,作用类似于python的assert
// CHECK_CUDA 检查变量是否为一个gpu的tensor
// CHECK_CONTIGUOUS 检测每一个tensor在内存上是否是连续的
// CHECK_INPUT 表示检测上面两个函数
#define CHECK_CUDA(x) TORCH_CHECK(x.type().is_cuda(), #x " must be a CUDA tensor")
#define CHECK_CONTIGUOUS(x) TORCH_CHECK(x.is_contiguous(), #x " must be contiguous")
#define CHECK_INPUT(x) CHECK_CUDA(x); CHECK_CONTIGUOUS(x)
torch::Tensor trilinear_fw_cu(torch::Tensor feats, torch::Tensor points);
torch::Tensor trilinear_bw_cu(
torch::Tensor dL_dfeat_interp,
torch::Tensor feats,
torch::Tensor points);
4.编写CPP主机代码,在代码中使用PYBIND库连接pytorch和c++代码,使用主机函数调用设备函数
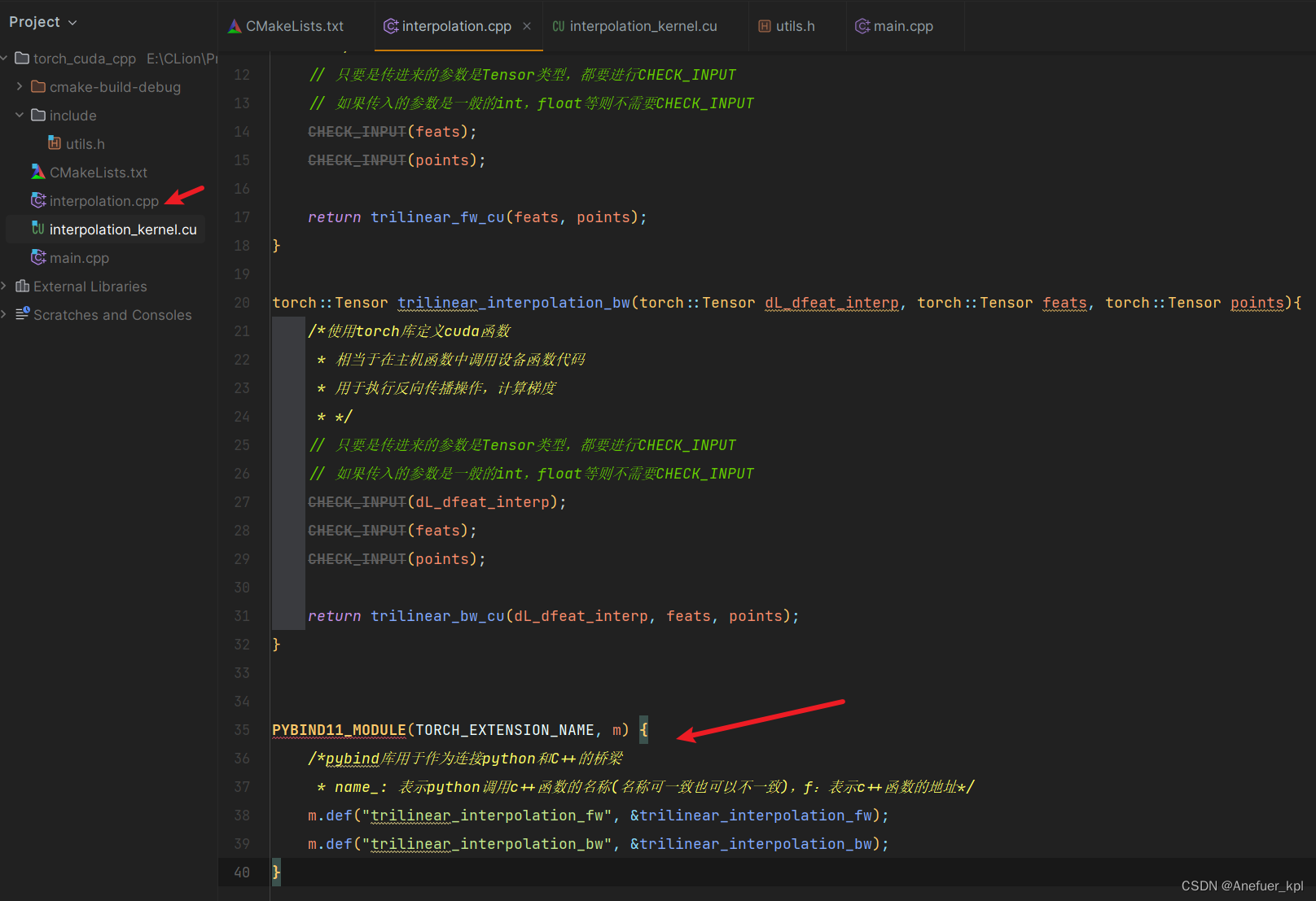
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
/*pybind库用于作为连接python和C++的桥梁
* name_: 表示python调用c++函数的名称(名称可一致也可以不一致),f:表示c++函数的地址*/
m.def("trilinear_interpolation_fw", &trilinear_interpolation_fw);
m.def("trilinear_interpolation_bw", &trilinear_interpolation_bw);
}
trilinear_interpolation_fw表示你在python代码中调用cuda函数时,这个cuda函数的别名,这个别名进行和CUDA函数保持一致,报错了好找位置。trilinear_interpolation_bw同理
5.在Pycharm中创建setup.py脚本,将C++编写的cuda代码编译为python的一个package
一定是创建setup.py,不能是别的名称
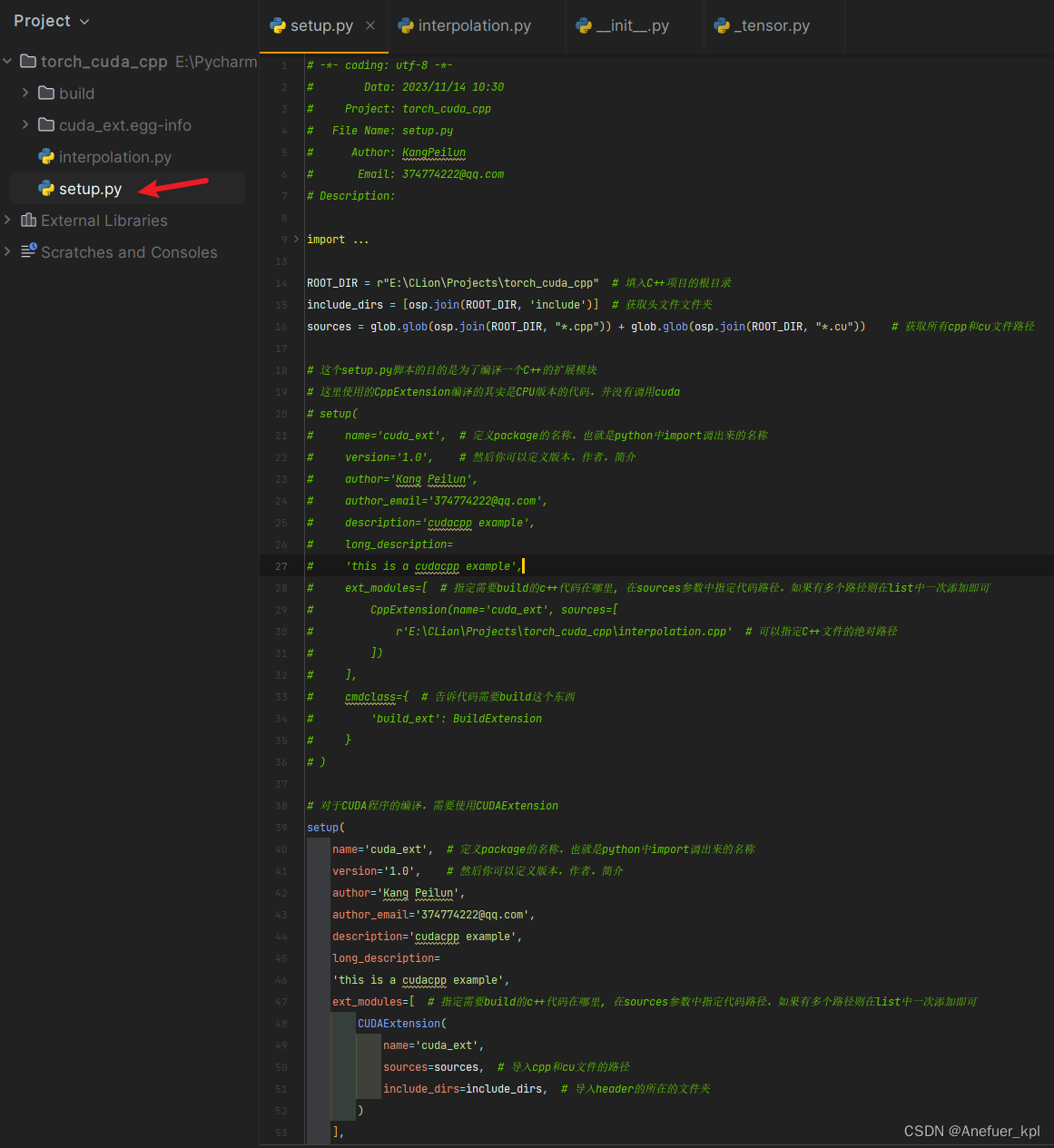
# -*- coding: utf-8 -*-
# Data: 2023/11/14 10:30
# Project: torch_cuda_cpp
# File Name: setup.py
# Author: KangPeilun
# Email: 374774222@qq.com
# Description:
import glob
import os.path as osp
from setuptools import setup
from torch.utils.cpp_extension import CppExtension, BuildExtension, CUDAExtension
ROOT_DIR = r"E:\CLion\Projects\torch_cuda_cpp" # 填入C++项目的根目录
include_dirs = [osp.join(ROOT_DIR, 'include')] # 获取头文件文件夹
sources = glob.glob(osp.join(ROOT_DIR, "*.cpp")) + glob.glob(osp.join(ROOT_DIR, "*.cu")) # 获取所有cpp和cu文件路径
# 这个setup.py脚本的目的是为了编译一个C++的扩展模块
# 这里使用的CppExtension编译的其实是CPU版本的代码,并没有调用cuda
# setup(
# name='cuda_ext', # 定义package的名称,也就是python中import调出来的名称
# version='1.0', # 然后你可以定义版本,作者,简介
# author='Kang Peilun',
# author_email='374774222@qq.com',
# description='cudacpp example',
# long_description=
# 'this is a cudacpp example',
# ext_modules=[ # 指定需要build的c++代码在哪里, 在sources参数中指定代码路径,如果有多个路径则在list中一次添加即可
# CppExtension(name='cuda_ext', sources=[
# r'E:\CLion\Projects\torch_cuda_cpp\interpolation.cpp' # 可以指定C++文件的绝对路径
# ])
# ],
# cmdclass={ # 告诉代码需要build这个东西
# 'build_ext': BuildExtension
# }
# )
# 对于CUDA程序的编译,需要使用CUDAExtension
setup(
name='cuda_ext', # 定义package的名称,也就是python中import调出来的名称
version='1.0', # 然后你可以定义版本,作者,简介
author='Kang Peilun',
author_email='374774222@qq.com',
description='cudacpp example',
long_description=
'this is a cudacpp example',
ext_modules=[ # 指定需要build的c++代码在哪里, 在sources参数中指定代码路径,如果有多个路径则在list中一次添加即可
CUDAExtension(
name='cuda_ext',
sources=sources, # 导入cpp和cu文件的路径
include_dirs=include_dirs, # 导入header的所在的文件夹
)
],
cmdclass={ # 告诉代码需要build这个东西
'build_ext': BuildExtension
}
)
6.使用pip安装自定义的cuda代码库
使用setup.py编译安装自定义的CUDA库
注意一定得是setup.py所在文件夹
pip install .
# . 表示setup.py所在的文件夹
# 当setup.py在别的文件夹中时,把.替换为setup.py所在文件夹路径即可,
# 注意一定得是setup.py所在文件夹
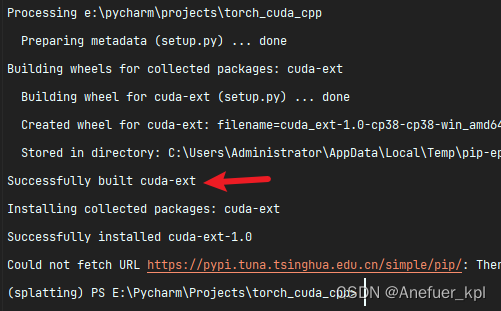
出现下方字样即代表,安装成功
7.安装好自定义的cuda自定义库之后,编写python代码调用
# -*- coding: utf-8 -*-
# Data: 2023/11/14 15:24
# Project: torch_cuda_cpp
# File Name: interpolation.py
# Author: KangPeilun
# Email: 374774222@qq.com
# Description:
import torch
import cuda_ext
from time import time
def trilinear_interpolation_py(feats, points):
"""
:param feats: [N, 8, F]
:param points: [N, 3]
:return:
"""
u = (points[:, 0:1]+1)/2
v = (points[:, 1:2]+1)/2
w = (points[:, 2:3]+1)/2
a = (1-v)*(1-w)
b = (1-v)*w
c = v*(1-w)
d = 1-a-b-c # <=> d = v*w
feats_interp = (1-u)*(a*feats[:, 0] + b*feats[:, 1] + c*feats[:, 2] + d*feats[:, 3]) +\
u*(a*feats[:, 4] + b*feats[:, 5] + c*feats[:, 6] + d*feats[:, 7])
return feats_interp
class Trilinear_interpolation_cuda(torch.autograd.Function):
'''使用torch.autograd.Function包装fw和bw处理
实现这个类,需要手动实现forward和backward两个函数,并且要用@staticmethod修饰
ctx: 负责存储反向传播用到的值,这个参数不能省略
forward的返回值的个数与backward输入参数的个数一致
backward的返回值个数与forward的输入参数个数一致,且返回计算过梯度的参数,如果某个参数不需要计算梯度,则对应返回None
'''
@staticmethod
def forward(ctx, feats, points):
feat_interp = cuda_ext.trilinear_interpolation_fw(feats, points)
ctx.save_for_backward(feats, points)
return feat_interp
@staticmethod
def backward(ctx, dL_dfeat_interp):
feats, points = ctx.saved_tensors
dL_feats = cuda_ext.trilinear_interpolation_bw(dL_dfeat_interp.contiguous(), feats, points)
return dL_feats, None
if __name__ == '__main__':
N = 65536
F = 256
# feats = torch.rand(N, 8, F, device='cuda').requires_grad_()
rand = torch.rand(N, 8, F, device='cuda')
feats1 = rand.clone().requires_grad_()
feats2 = rand.clone().requires_grad_()
points = torch.rand(N, 3, device='cuda')*2 - 1
t = time()
# 自定义的CUDA函数是没有办法自动计算梯度的,需要我们手动计算梯度
# 通过torch.autograd.grad自动保存计算后的梯度
# 使用 .apply 执行自定义的CUDA前向传播过程
out_cuda = Trilinear_interpolation_cuda.apply(feats1, points)
torch.cuda.synchronize()
print("\tCUDA time: ", time()-t, out_cuda)
# 1.使用Pytorch计算梯度
t = time()
out_py = trilinear_interpolation_py(feats2, points) # Pytorch可以自动计算梯度
torch.cuda.synchronize()
print("\tPytorch time: ", time()-t, out_py)
#
# print(torch.allclose(out_cuda, out_py)) # 判断两个tensor在误差范围内是否接近
loss2 = out_py.sum() # 简单的将他们的和作为loss,仅用于测试
loss2.backward() # 反向传播计算梯度
# 2.使用自定义CUDA函数计算梯度
loss1 = out_cuda.sum()
loss1.backward()
print("bw all close", torch.allclose(feats1.grad, feats2.grad))
五、总结
第四部分介绍了整个Pytorch CUDA CPP项目一般会包含哪些文件,所有代码都是基于教程:Pytorch+cpp/cuda extension 教学 编写,推荐有时间和能力的人把这个教程学完,会受益匪浅的。
总体来说Pytorch CUDA CPP项目一般同时会包含.py、.cpp、.cu、.h文件,cpp文件存放主机函数用于调用设备函数,cu文件存放设备函数用于调用kernel核函数在GPU上进行运算,setup.py文件用于将自定义的cuda程序构建为python的一个package,其他py文件调用package实现python调用C++代码,C++代码调用CUDA程序这一流程。