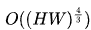一:Prometheus
1:介绍:
Prometheus是一个在SoundCloud上构建的开源系统监视和警报工具包
2:特点
- 多维度数据模型-由指标键值对标识的时间序列数据组成;
- PromQL,一种灵活的查询语言;
- 不依赖分布式存储; 单个服务器节点是自治的;
- 以HTTP方式,通过pull模型拉取时间序列数据;
- 支持通过中间网关推送时间序列数据;
- 通过服务发现或者静态配置,来发现目标服务对象;
- 支持多种多样的图表和界面展示。
3:docker部署Prometheus
(1)拉取Prometheus
docker pull prom/prometheus(2)配置Prometheus
新建一个prometheus.yml
global:
# 每15s获取一次数据指标
scrape_interval: 15s
# 获取数据超时时长 10s
scrape_timeout: 10s
# 规则评估评率,即计算指标是否有触发规则的计算频率
evaluation_interval: 15s
# 规则文件,从所有匹配的文件中读取规则和警报
rule_files:
- "alert_rules.yml"
# 采集配置列表
scrape_configs:
- job_name: prometheus
static_configs:
- targets: ['localhost:9090']
- job_name: 'node'
scrape_interval: 8s
static_configs:
- targets: ['node-exporter:9100']
- job_name: 'cadvisor'
static_configs:
- targets: ['cadvisor:8080']
新建一个规则文件alert_rules.yml
groups:
- name: targets
rules:
- alert: monitor_service_down
expr: up == 0
for: 30s
labels:
severity: critical
annotations:
summary: "Monitor service non-operational"
description: "Service {{ $labels.instance }} is down."
- name: host
rules:
- alert: high_cpu_load
expr: node_load1 > 1.5
for: 30s
labels:
severity: warning
annotations:
summary: "Server under high load"
description: "Docker host is under high load, the avg load 1m is at {{ $value}}. Reported by instance {{ $labels.instance }} of job {{ $labels.job }}."
- alert: high_memory_load
expr: (sum(node_memory_MemTotal_bytes) - sum(node_memory_MemFree_bytes + node_memory_Buffers_bytes + node_memory_Cached_bytes) ) / sum(node_memory_MemTotal_bytes) * 100 > 85
for: 30s
labels:
severity: warning
annotations:
summary: "Server memory is almost full"
description: "Docker host memory usage is {{ humanize $value}}%. Reported by instance {{ $labels.instance }} of job {{ $labels.job }}."
- alert: high_storage_load
expr: (node_filesystem_size_bytes{fstype="aufs"} - node_filesystem_free_bytes{fstype="aufs"}) / node_filesystem_size_bytes{fstype="aufs"} * 100 > 85
for: 30s
labels:
severity: warning
annotations:
summary: "Server storage is almost full"
description: "Docker host storage usage is {{ humanize $value}}%. Reported by instance {{ $labels.instance }} of job {{ $labels.job }}."
(3)运行Prometheus
docker run -d --name=prometheus -p 9090:9090 -v ./prometheus[创建的配置文件目录]:/etc/prometheus -v ./opt/data/prometheus[prometheus数据需要存储的地址]:/prometheus prom/prometheus(4)访问Prometheus
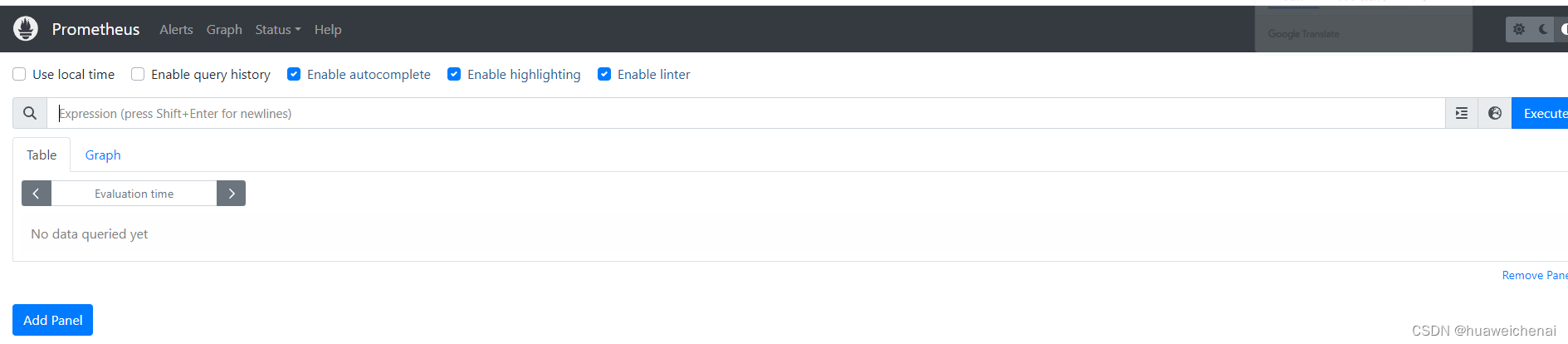
访问127.0.0.1:9090如下表示安装成功
二:Cadvisor
1:介绍
Cadvisor 是Google用来监测单节点资源信息的监控工具。 Cadvisor 提供了基础查询界面和http接口,方便其他组件如Grafana 、Prometheus等进行数据抓取。Cadvisor 可以对Docker主机上的资源及容器进行实时监控和性能数据采集,包括CPU使用情况、内存使用情况、网络吞吐量及文件系统使用情况等。Cadvisor 使用Go语言开发,利用Linux的Cgroups获取容器的资源使用信息。
2:特点
- 可以展示主机和容器两个层次的监控数据。
- 可以展示历史变化数据。
- 谷歌公司的开源产品。
- 监控指标齐全。
- 方便部署,有官方的docker镜像。
- 默认只在本地保存1分钟数据,可以集成InfluxDB等第三方存储使用。
3:docker部署Cadvisor
(1)拉取Cadvisor
docker pull google/cadvisor(2)运行Cadvisor
docker run -d --volume=/:/rootfs:ro --volume=/var/run:/var/run:ro --volume=/sys:/sys:ro --volume=/var/lib/docker/:/var/lib/docker:ro --volume=/dev/disk/:/dev/disk:ro --publish=8080:8080 --detach=true --name=cadvisor google/cadvisor:latest(3)访问Cadvisor
访问127.0.0.1:8080如下表示安装成功

三:Grafana
1:介绍
Grafana是一个可视化面板(Dashboard)工具,有着非常漂亮的图表和布局等展示功能,功能齐全的度量仪表盘和图形编辑器,支持Graphite、zabbix、InfluxDB、Prometheus和OpenTSDB等组件作为数据源。
2:特点
- 灵活丰富的图形化选项;
- 可以混合多种风格;
- 支持白天和夜间模式;
- 支持多个数据源;
3:docker部署Grafana
(1)拉取Grafana
docker pull grafana/grafana(2)运行Grafana
docker run -d --name=grafana -p 3000:3000 grafana/grafana(3)访问Grafana
访问127.0.0.1:3000如下表示安装成功(默认账号密码都为admin)
(4)Grafana配置
1.添加Prometheus数据源 Connections -> Data sources -> Add new data source -> 选择Prometheus 设置Prometheus server URL 为http://prometheus:9090然后保存
2.添加Dashboards仪表板 Dashboards -> import -> 导入仪表板 可用的仪表版模板:
Node Exporter Dashboard 220417 通用Job分组版
Docker monitoring with service selection
3.设置首页默认仪表板 Administration -> Default preferences -> 选择Home Dashboard
4.语言设置 用户头像 -> Profile -> 选择Language
四:dockers部署Prometheus+Cadvisor+Grafana
参考:https://download.csdn.net/download/huaweichenai/88537114