咦咦咦,各位小可爱,我是你们的好伙伴——bug菌,今天又来给大家普及Java SE相关知识点了,别躲起来啊,听我讲干货还不快点赞,赞多了我就有动力讲得更嗨啦!所以呀,养成先点赞后阅读的好习惯,别被干货淹没了哦~
🏆本文收录于「滚雪球学Java」专栏,专业攻坚指数级提升,助你一臂之力,带你早日登顶🚀,欢迎大家关注&&收藏!持续更新中,up!up!up!!
环境说明:Windows 10 + IntelliJ IDEA 2021.3.2 + Jdk 1.8
文章目录
- 前言
- 摘要
- LinkedHashSet
- 概述
- 源代码解析
- 应用场景案例
- 优缺点分析
- 类代码方法介绍
- 测试用例
- 测试代码演示
- 测试结果
- 测试代码分析
- 全文小结
- 总结
- 附录源码
- ☀️建议/推荐你
- 📣关于我
前言
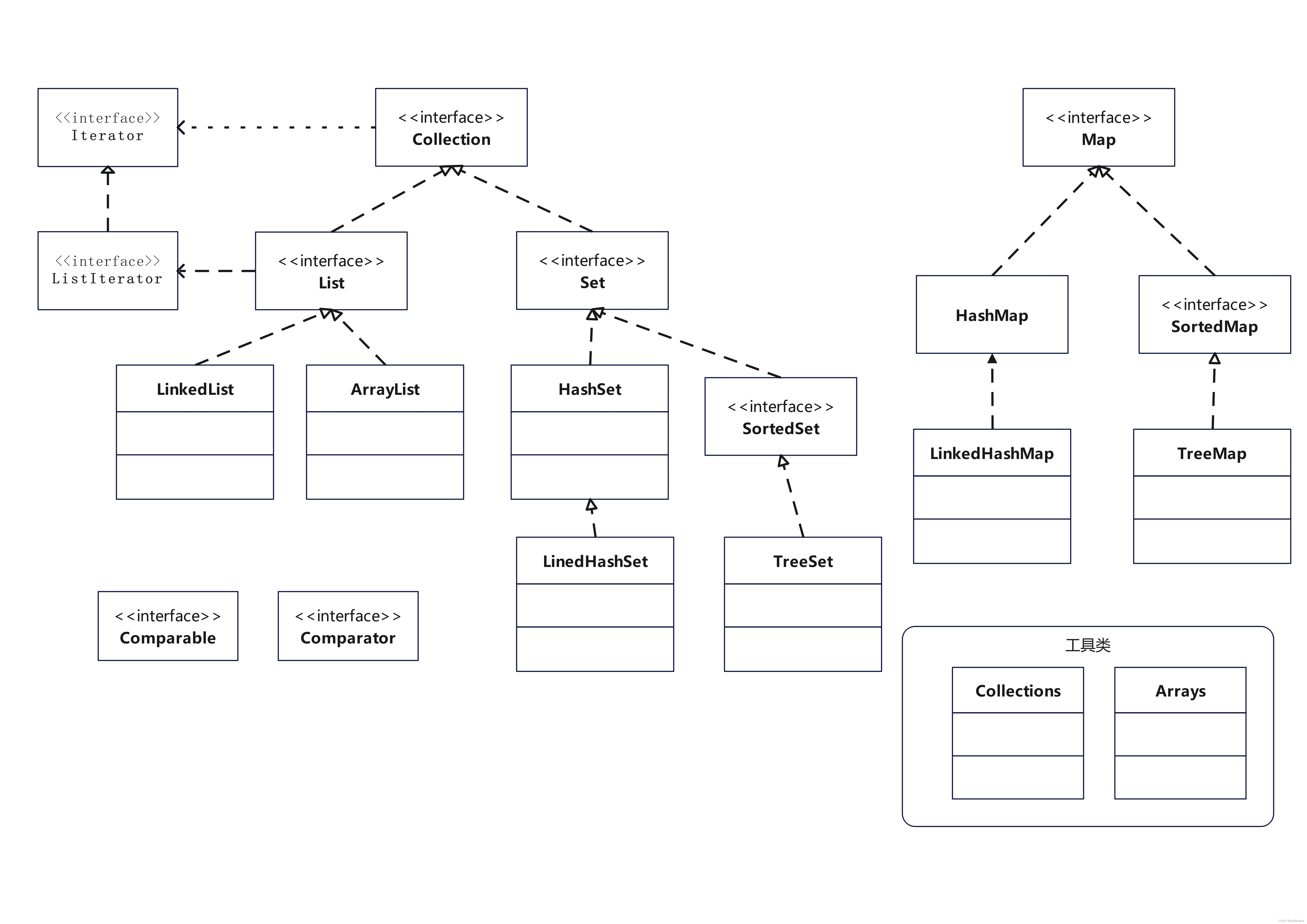
在Java开发中,使用集合类是必不可少的。其中,HashSet是最常用的集合类之一,但是HashSet在保证元素唯一性的同时,却不能保证插入顺序。因此,我们需要LinkedHashSet,在HashSet的基础上保证了元素插入的顺序。本文将对LinkedHashSet进行原理及实现的解析,帮助读者更好地理解LinkedHashSet。
摘要
LinkedHashSet是HashSet和LinkedHashMap的结合体,它具有HashSet的高效查找和LinkedHashMap的有序性。LinkedHashSet底层使用的是LinkedHashMap实现,数据结构是一个双链表和一个哈希表。本文将深入剖析LinkedHashSet的实现原理和应用场景,帮助读者更好地理解该类的使用。
LinkedHashSet
概述
LinkedHashSet是Java中的一个集合类,它实现了Set接口,继承了HashSet类,具有HashSet类的高效存储和检索元素的特点。同时,LinkedHashSet还对元素的插入顺序进行了维护,保证了元素的有序性,这是HashSet所不具备的。在实现上,LinkedHashSet底层使用的是LinkedHashMap,使用双向链表维护了元素的插入顺序。LinkedHashSet提供了以下构造方法:
public LinkedHashSet()
public LinkedHashSet(int initialCapacity)
public LinkedHashSet(int initialCapacity, float loadFactor)
public LinkedHashSet(Collection<? extends E> c)
其中,第一个构造方法创建一个空的LinkedHashSet实例,第二个构造方法指定了初始化容量,第三个构造方法指定了初始化容量和加载因子,第四个构造方法使用指定集合来初始化LinkedHashSet。
源代码解析
LinkedHashSet底层使用的是LinkedHashMap,它是一个基于散列表的Map实现。它的数据结构是一个双链表和一个哈希表。双链表用来维护元素的插入顺序,哈希表用来实现高效的存储和查找。
LinkedHashSet类的源代码如下:
public class LinkedHashSet<E>
extends HashSet<E>
implements Set<E>, Cloneable, java.io.Serializable
{
private static final long serialVersionUID = -2851667679971038690L;
private final LinkedHashMap<E,Object> map;
// Dummy value to associate with an Object in the backing Map
private static final Object PRESENT = new Object();
public LinkedHashSet() {
map = new LinkedHashMap<>();
}
public LinkedHashSet(int initialCapacity) {
super(initialCapacity);
map = new LinkedHashMap<>(initialCapacity);
}
public LinkedHashSet(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor);
map = new LinkedHashMap<>(initialCapacity, loadFactor);
}
public LinkedHashSet(Collection<? extends E> c) {
map = new LinkedHashMap<>(Math.max((int) (c.size()/.75f) + 1, 16));
addAll(c);
}
public Iterator<E> iterator() {
return map.keySet().iterator();
}
public int size() {
return map.size();
}
public boolean isEmpty() {
return map.isEmpty();
}
public boolean contains(Object o) {
return map.containsKey(o);
}
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
public boolean remove(Object o) {
return map.remove(o)==PRESENT;
}
public void clear() {
map.clear();
}
public Object clone() {
LinkedHashSet<E> clone = null;
try {
clone = (LinkedHashSet<E>) super.clone();
} catch (CloneNotSupportedException e) {
throw new InternalError();
}
clone.map = (LinkedHashMap<E,Object>) map.clone();
return clone;
}
private void writeObject(java.io.ObjectOutputStream s)
throws java.io.IOException {
s.defaultWriteObject();
s.writeInt(map.capacity());
s.writeFloat(map.loadFactor());
s.writeInt(map.size());
for (E e : map.keySet())
s.writeObject(e);
}
private void readObject(java.io.ObjectInputStream s)
throws java.io.IOException, ClassNotFoundException {
s.defaultReadObject();
int capacity = s.readInt();
float loadFactor = s.readFloat();
int size = s.readInt();
map = new LinkedHashMap<>(capacity, loadFactor);
for (int i=0; i<size; i++) {
E e = (E) s.readObject();
map.put(e, PRESENT);
}
}
}
可以看到,在LinkedHashSet的构造方法中,它使用LinkedHashMap来实现对元素插入顺序的维护。LinkedHashMap维护了一个双向链表,每次插入元素时,它会将新元素插入到链表的尾部,同时在哈希表中存储该元素的键值对,以便实现高效的存储和查找。LinkedHashSet中的add()方法就是通过调用LinkedHashMap中的put()方法实现插入新元素,而contains()方法则是直接调用LinkedHashMap的containsKey()方法实现对元素是否存在的判断。
如下是部分源码截图:
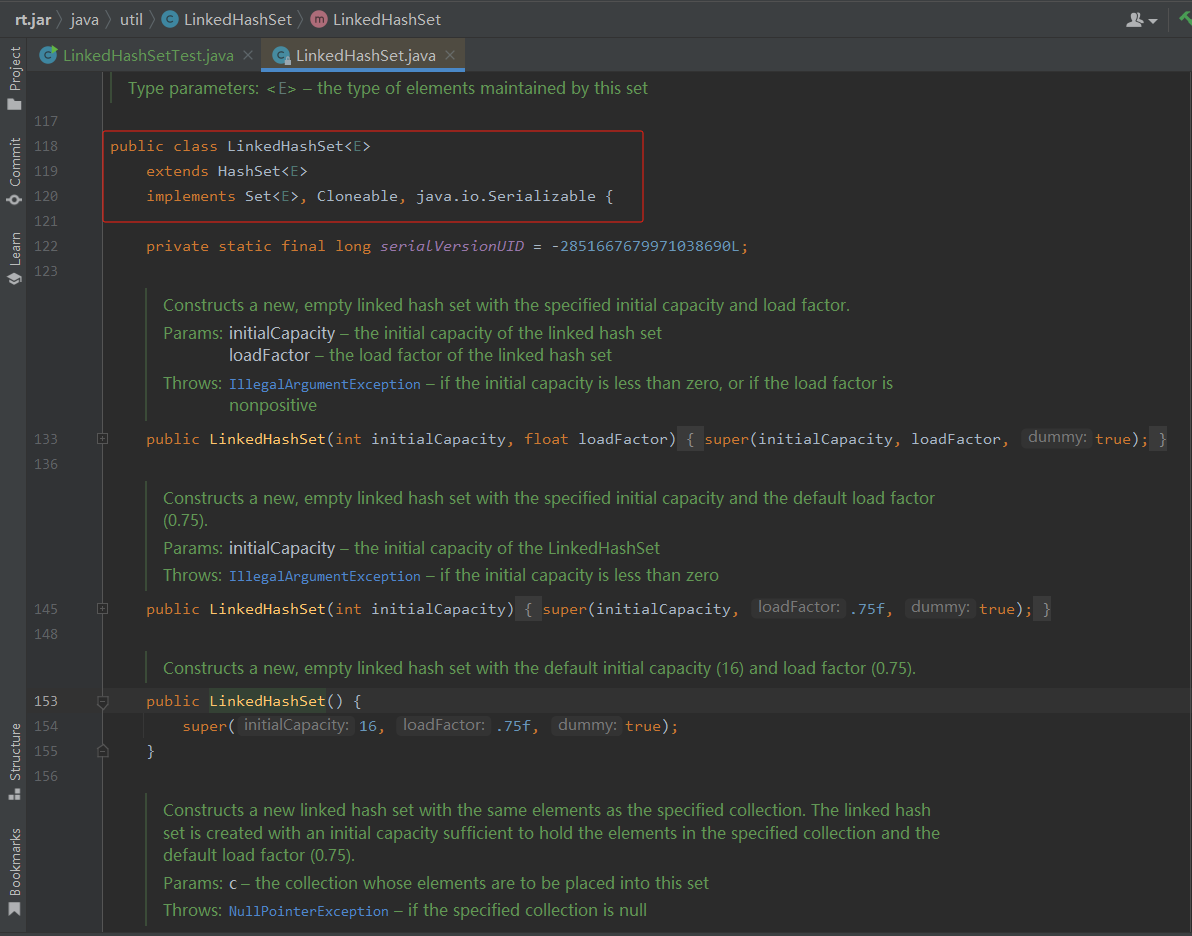
具体源码分析如下:
LinkedHashSet是一个继承自HashSet的类,实现了Set接口,支持元素按照插入顺序进行遍历。它内部通过使用一个LinkedHashMap来维护元素插入顺序,实际上LinkedHashSet就是在HashSet的基础上利用了LinkedHashMap的有序性。
LinkedHashSet提供了多个构造方法,可以仅传入初始容量、初始容量和负载因子等参数,也可以传入一个集合类对象进行初始化。
LinkedHashSet的主要方法和HashSet相同,例如:contains(),add(),remove()等。因为继承自HashSet,所以LinkedHashSet也是基于哈希表实现的。其迭代器返回元素的顺序与元素插入顺序一致。
LinkedHashSet的clone方法会创建一个新的LinkedHashSet对象,并将自身的LinkedHashMap进行浅复制。
LinkedHashSet还实现了Serializable接口,在序列化和反序列化时,会将其内部的LinkedHashMap也一并进行序列化和反序列化。
应用场景案例
LinkedHashSet在保证元素唯一性的同时,还保留了元素的插入顺序,因此,它在以下场景中得到了广泛应用:
-
缓存:当需要缓存一组数据时,如果希望缓存的数据按照插入顺序进行访问,就可以使用LinkedHashSet。
-
配置文件:当需要加载一组配置文件,并按照文件的出现顺序来访问它们的内容时,可以使用LinkedHashSet。
-
去重:当需要对一组数据进行去重,同时还需要保留它们的插入顺序时,可以使用LinkedHashSet。
优缺点分析
LinkedHashSet的优点在于它继承了HashSet的高效性和LinkedHashMap的有序性,同时支持高效的元素查找、插入和删除等操作。其缺点在于它需要维护一个双向链表,因此,在内存使用方面可能会略微占用一些空间。
类代码方法介绍
下面是LinkedHashSet类中的主要方法介绍:
-
add(E e):向集合中添加元素,并返回添加成功与否的结果。
-
remove(Object o):从集合中删除指定的元素,并返回删除结果。
-
contains(Object o):判断集合中是否包含指定元素,如果包含则返回true,否则返回false。
-
iterator():返回一个迭代器,用于遍历集合中的元素。
-
size():返回集合中元素的数量。
-
isEmpty():判断集合是否为空,如果为空则返回true,否则返回false。
测试用例
下面是使用LinkedHashSet的一个简单测试用例:
测试代码演示
package com.demo.javase.day64;
import java.util.LinkedHashSet;
/**
* @Author bug菌
* @Date 2023-11-06 11:36
*/
public class LinkedHashSetTest {
public static void main(String[] args) {
LinkedHashSet<String> linkedHashSet = new LinkedHashSet<>();
// 向集合中添加元素
linkedHashSet.add("A");
linkedHashSet.add("B");
linkedHashSet.add("C");
linkedHashSet.add("D");
linkedHashSet.add("E");
// 遍历集合中的元素,并输出它们的顺序
for (String str : linkedHashSet) {
System.out.print(str + " ");
}
System.out.println();
// 删除集合中的元素
linkedHashSet.remove("C");
// 再次遍历集合中的元素,并输出它们的顺序
for (String str : linkedHashSet) {
System.out.print(str + " ");
}
System.out.println();
// 判断集合中是否包含指定元素
System.out.println("集合中是否包含\"A\":" + linkedHashSet.contains("A"));
System.out.println("集合中是否包含\"C\":" + linkedHashSet.contains("C"));
}
}
测试结果
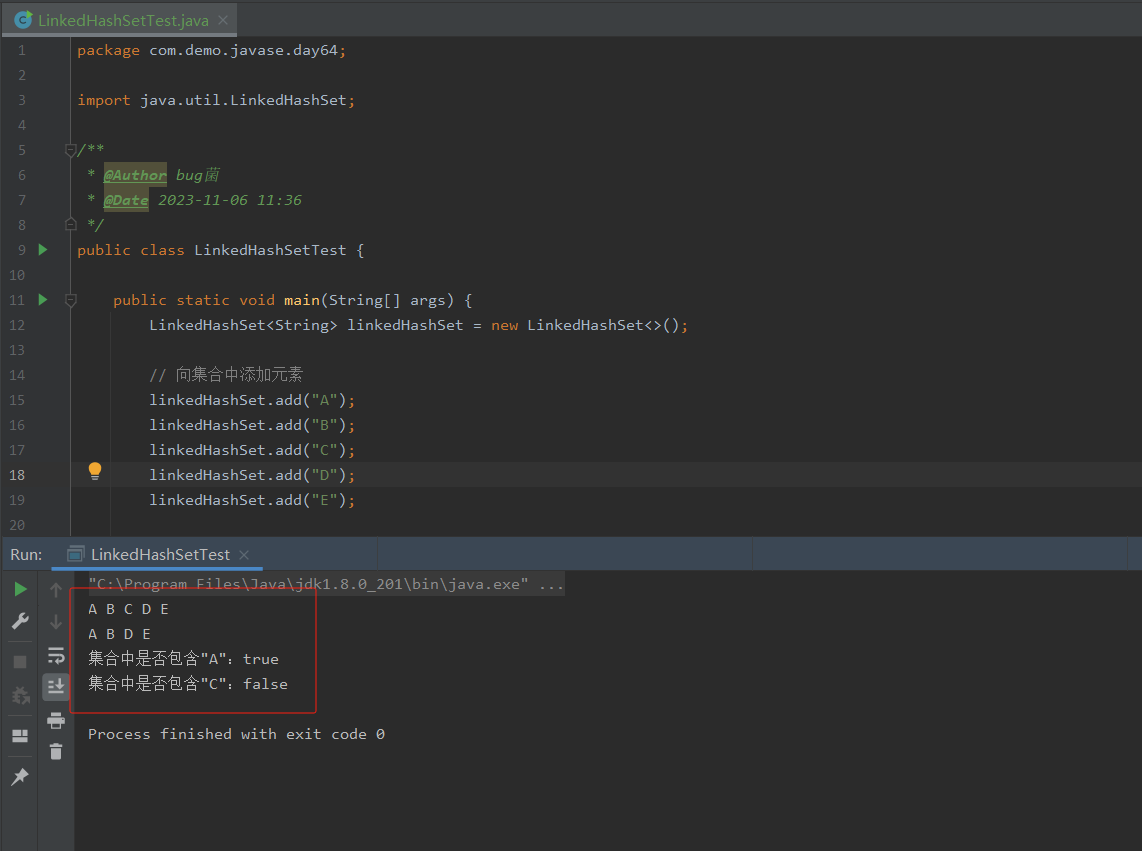
根据如上测试用例,本地测试结果如下,仅供参考,你们也可以自行修改测试用例或者添加更多的测试数据或测试方法,进行熟练学习以此加深理解。
输出结果如下:
A B C D E
A B D E
集合中是否包含"A":true
集合中是否包含"C":false
测试代码分析
根据如上测试用例,在此我给大家进行深入详细的解读一下测试代码,以便于更多的同学能够理解并加深印象。
该代码演示了如何使用Java中的LinkedHashSet类。LinkedHashSet是HashSet的一个子类,它保留了元素插入的顺序。具体实现过程如下:
-
创建一个LinkedHashSet实例,该实例用于存储字符串类型的元素。
-
使用add方法向集合中添加元素。
-
使用for-each循环遍历集合中的元素,并输出它们的顺序。
-
使用remove方法删除集合中的元素。
-
再次使用for-each循环遍历集合中的元素,并输出它们的顺序。
-
使用contains方法判断集合中是否包含指定元素,并输出判断结果。
在实际开发中,LinkedHashSet通常用于需要保留元素插入顺序的场景,例如需要记录日志的应用程序等。由于LinkedHashSet实现了Set接口,因此它也具有Set接口的特性,即不能包含重复元素。
全文小结
本篇文章介绍了LinkedHashSet的原理和实现。LinkedHashSet继承了HashSet的高效性和LinkedHashMap的有序性,可以在保证元素唯一性的同时,还保留了元素的插入顺序。底层使用LinkedHashMap实现,使用双向链表维护了元素的插入顺序。在应用场景上,LinkedHashSet常用于缓存、配置文件和去重等场景。其优点在于高效的元素查找、插入和删除等操作,而缺点在于需要维护一个双向链表,可能会略微占用一些空间。在使用上,LinkedHashSet提供了一系列方法,如add、remove、contains等,同时还具备Iterator迭代器用于遍历集合中的元素。最后,我们也给出了一个使用LinkedHashSet的简单测试用例。
总结
本文介绍了LinkedHashSet的概念、原理和实现。LinkedHashSet是Java中的一个集合类,它继承了HashSet的高效性和LinkedHashMap的有序性,同时支持高效的元素查找、插入和删除等操作。在应用场景上,LinkedHashSet常用于缓存、配置文件和去重等场景。其优点在于保证元素唯一性的同时,还保留了元素的插入顺序,同时具备高效的操作。类方法包括add、remove、contains等,同时还具备Iterator迭代器用于遍历集合中的元素。对于想要深入理解Java集合框架的同学,学习LinkedHashSet是必不可少的一部分。
…
好啦,这期的内容就基本接近尾声啦,若你想学习更多,可以参考这篇专栏总结《「滚雪球学Java」教程导航帖》,本专栏致力打造最硬核 Java 零基础系列学习内容,🚀打造全网精品硬核专栏,带你直线超车;欢迎大家订阅持续学习。
附录源码
如上涉及所有源码均已上传同步在「Gitee」,提供给同学们一对一参考学习,辅助你更迅速的掌握。
☀️建议/推荐你
无论你是计算机专业的学生,还是对编程有兴趣的小伙伴,都建议直接毫无顾忌的学习此专栏「滚雪球学Java」,bug菌郑重承诺,凡是学习此专栏的同学,均能获取到所需的知识和技能,全网最快速入门Java编程,就像滚雪球一样,越滚越大,指数级提升。
最后,如果这篇文章对你有所帮助,帮忙给作者来个一键三连,关注、点赞、收藏,您的支持就是我坚持写作最大的动力。
同时欢迎大家关注公众号:「猿圈奇妙屋」 ,以便学习更多同类型的技术文章,免费白嫖最新BAT互联网公司面试题、4000G pdf电子书籍、简历模板、技术文章Markdown文档等海量资料。
📣关于我
我是bug菌,CSDN | 掘金 | infoQ | 51CTO 等社区博客专家,历届博客之星Top30,掘金年度人气作者Top40,51CTO年度博主Top12,华为云 | 阿里云| 腾讯云等社区优质创作者,全网粉丝合计15w+ ;硬核微信公众号「猿圈奇妙屋」,欢迎你的加入!免费白嫖最新BAT互联网公司面试题、4000G pdf电子书籍、简历模板等海量资料。