你是否想过,有朝一日能够仅输入寥寥数语或图片,就可以一键检索最为匹配的短视频内容。不是凭借视频标签、也不是依靠标题字幕,而是大模型真正理解了视频内容。近期,来自快手的新研究利用视觉分词器统一图文信息,LaVIT 让这个创想逐步变为现实。
近年来,研究人员对多模态大模型(MLLM)理解能力进行探索,旨在将强大的纯文本 LLM 扩展到处理多模态输入。如图 1(a) 所示,常规方法主要将由预训练视觉主干编码的视觉特征映射到 LLM 的语义空间。尽管在零样本多模态理解上初有成效,但仍存在设计缺陷:
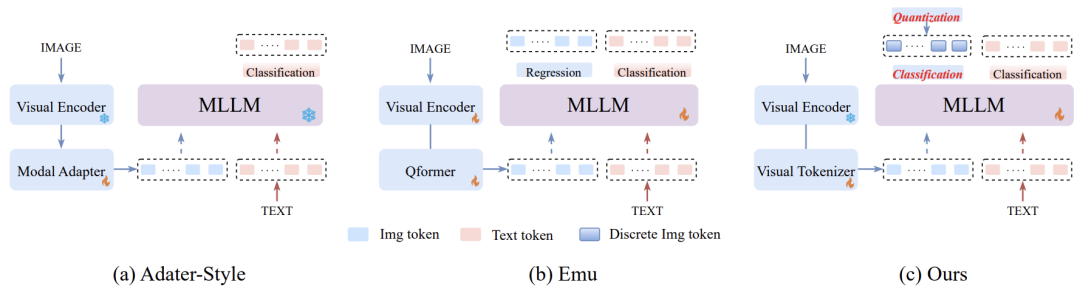
▲图1 不同 MLLM 之间的比较
-
在训练中主要基于视觉内容预测文本描述,但仅将视觉部分视为提示,没有监督学习。
-
将视觉-语言对齐的任务完全交给了新添加的适配器,但由于适配器的可训练参数有限,未能充分利用 LLM 在学习跨模态交互时的卓越推理能力。
如图 1(b) 所示,虽然同时期工作提出了通过在预训练期间回归下一个视觉 embedding 来解锁文本预训练的 LLM,但由于图像和文本的不一致优化目标,并不有利于统一的多模态建模。
因此,在来自快手的这篇论文中,作者提出一种名为 LaVIT 的新型通用多模态基础模型,借鉴了 LLM 成功的学习方法,即以自回归方式预测下一个图像或文本 token。
它引入了一个设计良好的视觉 token 生成器,用于将非语言图像转换为离散 token 序列,就像 LLM 能够理解的外语一样。因此,LaVIT 能在统一的生成目标上同时处理图像和文本,如图 1(c) 所示。
论文题目:
Unified Language-Vision Pretraining in LLM with Dynamic Discrete Visual Tokenization
论文链接:
https://arxiv.org/abs/2309.04669
Github 地址:
https://github.com/jy0205/LaVIT
论文速览
在经过预训练后,LaVIT 可以充当多模态通用模型,执行多模态理解和生成任务,无需进一步的微调。具体而言,LaVIT 具有这些能力:
-
高质量文本到图像的生成:LaVIT 能够根据给定的图像提示合成高质量、多种纵横比和高美感的图像。其图像生成能力与最先进的图像生成器(如 Parti、SDXL 和 DALLE-3)相媲美。

-
通过多模态提示进行图像合成:由于在 LLM 中,图像和文本都统一表示为离散 token,因此 LaVIT 可以接受多种模态组合(例如文本、图像+文本、图像+图像)作为提示,生成相应的图像,而无需进行任何微调。

-
读取图像内容并回答问题:在给定输入图像的情况下,LaVIT 能够阅读图像内容并理解其语义。例如,模型可以为输入的图像提供说明文字并回答相应的问题。

模型方法
本文将文本和视觉两种模态以统一的形式表示,以便复刻 LLM 的学习方法——下一个 token 预测,模型如图 2 所示。
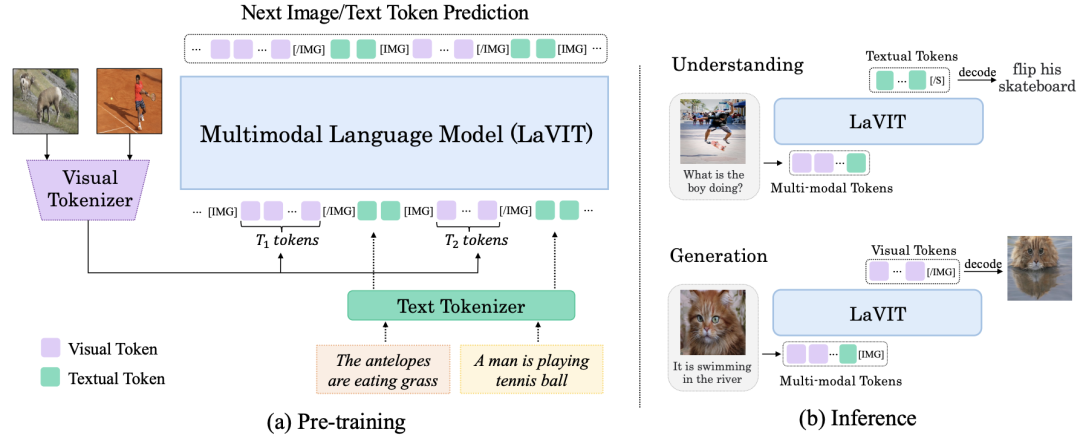
▲图2 给定一对图像和文本,图像被分词成离散 token,并与文本 token 连接形成多模态序列。然后,LaVIT 在统一的生成目标下进行优化
-
视觉分词器:将非语言图像转换为 LLM 可以理解的输入。视觉分词器接收预训练的视觉编码器的视觉特征,并输出一系列具有类似词汇高级语义的离散视觉 token。
-
通过精心设计的分词器,视觉输入可以与文本 token 集成,形成一个多模态序列,然后在统一的自回归训练目标下输入到 LLM 中。
阶段 1:动态视觉分词器
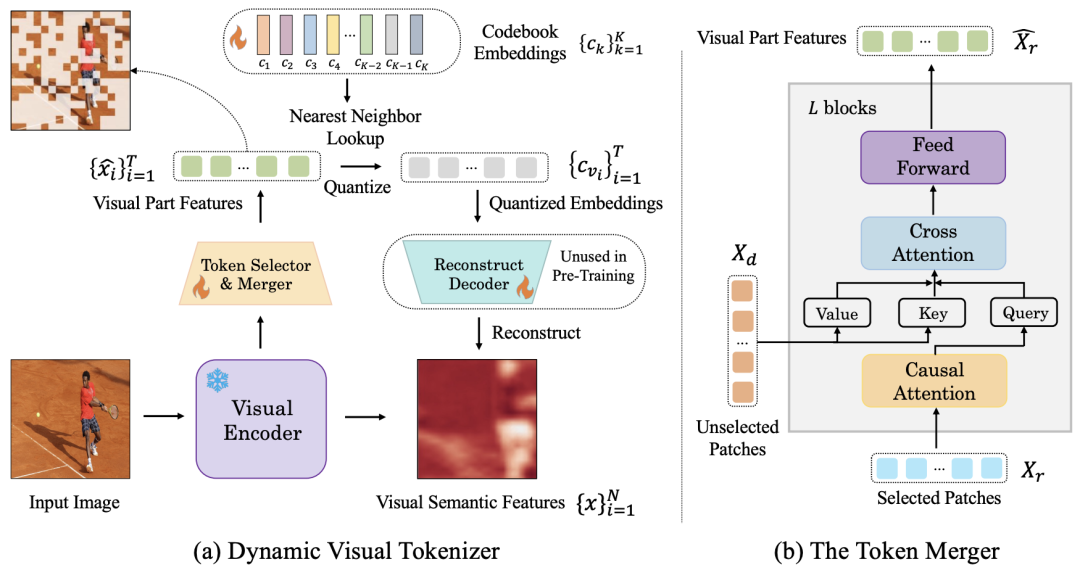
▲图3 (a)动态视觉 token 生成器 (b) token 合并器
动态视觉分词器包括 token 选择器和 token 合并器。如图 3(a) 所示,动态视觉 token 生成器使用 token 选择器来选择最具信息的图像区块,用 token 合并器将被舍弃的区块信息压缩到保留的区块上。整个 token 生成器通过最大限度地重构输入图像的语义进行训练。
token 选择器
token 选择器接收 N 个图像区块级的特征作为输入,其目标是评估每个图像区块的重要性并选择信息量最高的区块,以充分代表整个图像的语义。为实现这一目标,采用轻量级模块,由多个 MLP 层组成,用于预测分布 π。通过从分布 π 中采样,生成一个二进制决策 mask,用于指示是否保留相应的图像区块。
token 合并器
根据生成的决策掩码,将N个图像区块划分为保留 和舍弃 两组。
与直接丢弃 不同,作者设计了 token 合并器,以最大限度地保留输入图像的详细语义。token 合并器通过 L 个堆叠的块组成,每个块包括因果自注意力层、交叉注意力层和前馈层。
-
因果自注意力层中, 中的每个 token 关注其前面的 token,以确保与 LLM 中的文本 token 一致。与双向自注意相比,这种策略表现更好。
-
交叉注意力层将保留的 token 作为查询,并根据它们在嵌入空间中的相似性合并 中的 token。
最终实现对被舍弃图像区块信息的渐进性压缩,以保持整体语义的完整性。
阶段 2:统一生成建模
这里通过视觉 token 生成器处理视觉和文本输入,将二者均视为离散 token。对于给定的图像和文本对,2D 图像被分词成有因果依赖性的 1D 序列,然后与文本 token 连接形成多模态序列。
为了区分两种模态,作者在图像 token 序列的开头和结尾插入了特殊 token [IMG] 和 [/IMG]。LaVIT 能够生成文本和图像,采用两种连接形式:[image, text] 和 [text; image]。
当图像用作条件生成文本时,使用 token 合并器的连续视觉特征而非量化的视觉嵌入作为 LLM 的输入,以减轻信息丢失的问题。
LaVIT 采用通用语言建模目标,以自回归方式直接最大化每个多模态序列的似然性。LaVIT 在表示空间和训练方式上实现了完全统一,有助于 LLM 更好地学习多模态交互和对齐。
在预训练完成后,LaVIT 具有感知图像的能力,可以像处理文本一样理解和生成图像。然而,大多数现有方法仅将图像作为引导文本生成的提示,没有监督,限制了其仅执行图像到文本的任务。
实验
零样本多模态理解
该实验评估了 LaVIT 在图像字幕生成(NoCaps、Flickr30k)和视觉问答(VQAv2、OKVQA、GQA、VizWiz)等零样本多模态理解任务上的性能。在视觉问答任务中,使用了简单的提示:“问题:{} 答案:{}”。
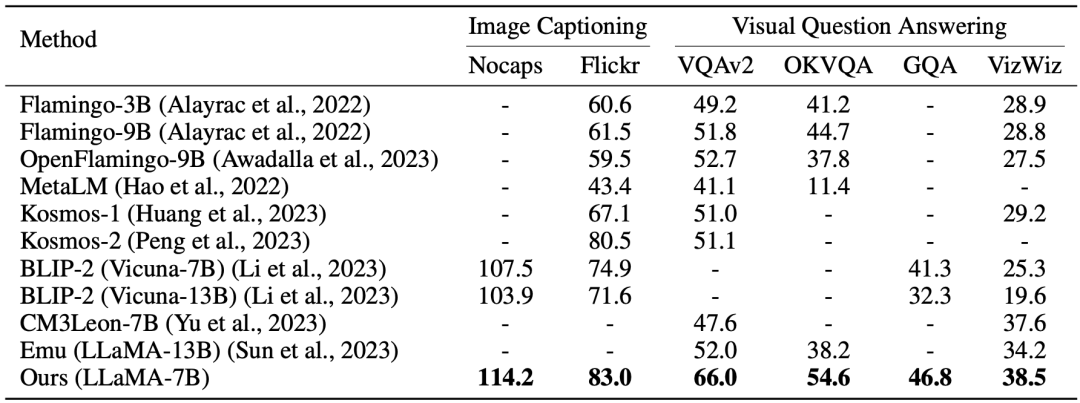
▲表1 多模态理解任务的零样本评估概述
表 1 展示了 LaVIT 出色的跨模态建模能力。而且,尽管同时期的方法 Emu 也利用 LLM 共同建模视觉和语言,但其对视觉输入采用直接特征回归目标,使其与文本输入不兼容。因此,尽管使用了更多训练数据和更大的 LLM 规模,但在所有评估基准上性能仍然不及 LaVIT。
零样本多模态生成
在这个实验中,由于所提出的视觉 token 生成器能够将图像表示为离散 token,LaVIT 具有通过自回归生成类似文本的视觉 token 来合成图像的能力。作者对模型进行了零样本文本条件下的图像合成性能的定量评估,比较结果如表 2 所示。
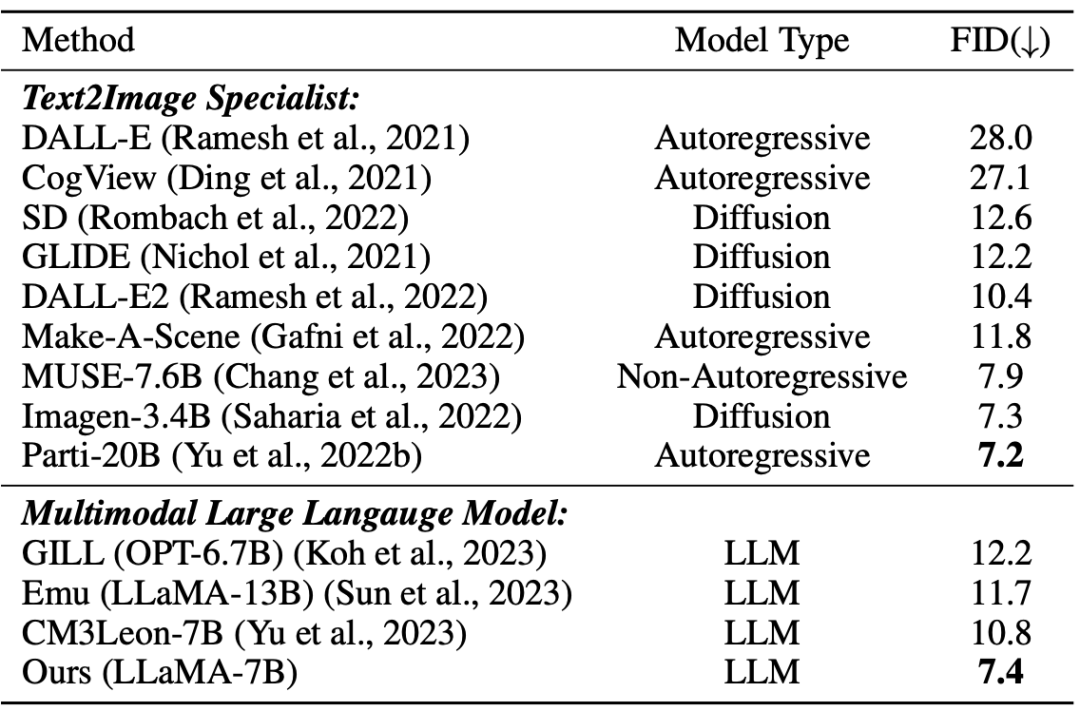
▲表2 不同模型的零样本文本到图像生成性能
从表中可以看出,LaVIT 的表现优于所有其他多模态语言模型。与 Emu 相比,LaVIT 在更小的 LLM 模型上取得了进一步改进,展现了出色的视觉-语言对齐能力。此外,LaVIT在使用更少的训练数据的情况下,实现了与最先进的文本到图像专家 Parti 可比的性能。
多模态提示生成
LaVIT 能够无缝地接受多种模态组合作为提示,生成相应的图像,而无需进行任何微调。

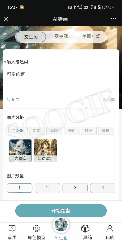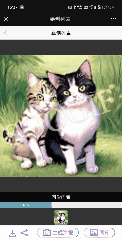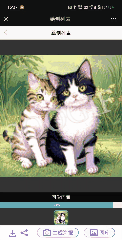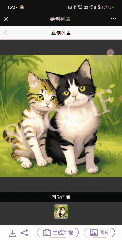
▲图4 多模态图像生成结果的示例
如图 4 所示,LaVIT 能生成高质量的图像,准确反映给定多模态提示的风格和语义。而且它可以通过输入的多模态提示修改原始输入图像。在没有额外微调的下游数据的情况下,传统的图像生成模型如 Stable Diffusion 无法达到这种能力。
消融实验
token 分类还是特征回归?
在联合训练视觉和语言时,选择适当的优化目标对于 2D 栅格顺序的视觉输入至关重要。在将连续的视觉 token 量化为离散形式时,使用交叉熵损失来监督下一个视觉 token 的预测,类似于对文本 token 的监督。
作者认为,这样的统一目标有助于在 LLM 中整合视觉和语言。为验证所提出的视觉量化的优越性,作者采用了类似于 Emu 的回归头,将视觉 token 的优化目标改为回归下一个视觉嵌入。

▲表3 不同训练目标的结果
从表 3(a) 中观察到,采用回归损失来预测下一个视觉 token 会严重降低模型的性能。
动态或固定 token 长度
在实验中,作者比较了两种不同的视觉 tokenization 策略:
-
将所有补丁嵌入 token 为固定长度的视觉 token (256),
-
采用动态视觉 tokenization 策略。
表 3(b) 表明,动态视觉 tokenizer 在平均每个输入图像上只需要约为固定 token 的 36%,并实现了更优越的性能。考虑到在 LLM 中,采用动态 tokenization 可以加速训练时间 40%,并降低推理中的计算成本。
定性分析
如图 5 所示,分词器可以根据图像内容动态选择最具信息量的图像块,学习到的代码本可以产生具有高层语义的视觉编码。

▲图5 动态视觉分词器(左)和学习到的代码本(右)的可视化
总结
当前,多模态研究领域蓬勃发展,不断涌现出新的工作。快手的这个算法团队,让 LaVIT 的出现为多模态任务的处理又提供了一种创新范式,通过动态视觉分词器,它成功地将视觉和语言信息整合到一个共同的生成目标中,为模型提供了强大的跨模态建模能力。
它超越了以前的适配器方法,通过使用动态视觉分词器将视觉和语言表示为统一的离散 token 表示,继承了 LLM 成功的自回归生成学习范式。通过在统一生成目标下进行优化,LaVIT 可以将图像视为一种外语,像文本一样理解和生成它们。
这一方法的成功为未来多模态研究的发展方向提供了新的启示,也期待着在这个充满活力的领域中,今后有更多前沿技术的涌现,为实现更智能、更全面的多模态理解和生成打开新的可能性~