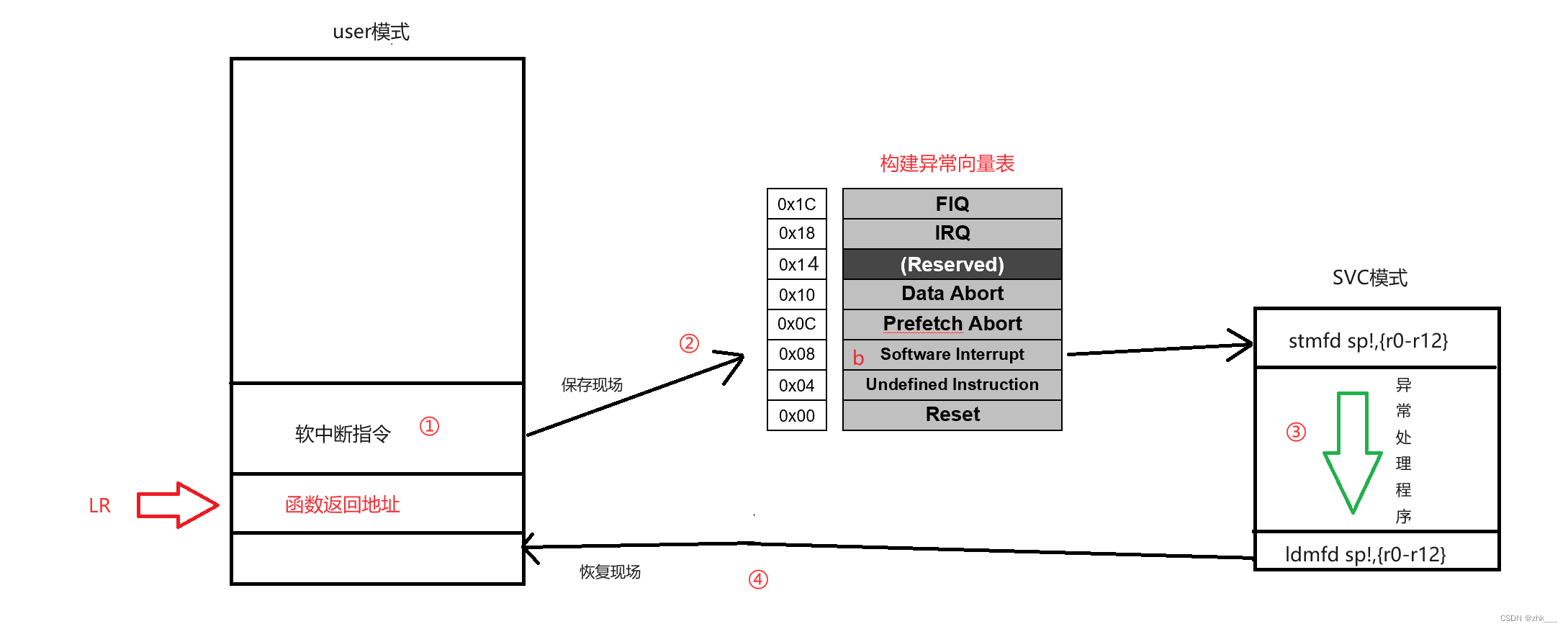
一、mapping属性
mapping属性的官方文档: https://elastic.co/guide/en/elasticsearch/reference/current/index.html
下面的表格是介绍elasticsearch中的各个概念以及含义,看的时候重点看第二、三列,第一列是为了让你更理解第二列的意思,所以在第一列拿MySQL的概念来做匹配。例如elasticsearch的Index表示索引也就是文档的集合,就相当于MySQL的Table(也就是表)
| MySQL | Elasticsearch | 说明 |
| Table | Index | 索引(index),就是文档的集合,类似数据库的表(table) |
| Row | Document | 文档(Document),就是一条条的数据,类似数据库中的行(Row)。这里的文档都是JSON格式 |
| Column | Field | 字段(Field),就是JSON文档中的字段,类似数据库中的列(Column) |
| Schema | Mapping | Mapping(映射)是索引中文档的约束,例如字段类型约束。类似数据库的表结构(Schema) |
| SQL | DSL | DSL是elasticsearch提供的JSON风格的请求语句,用来操作elasticsearch,实现CRUD |
mapping是对索引库中文档(es中的文档是json风格)的约束,常见的mapping属性包括如下
- type: 字段数据类型
-
- 字符串(分两种): text(可分词的文本)、keyword(精确值,例如:品牌、国家、ip地址等不可分词的词语)
- 数值: long、integer、short、byte、double、float
- 布尔: boolean
- 日期: date
- 对象:object
- index: 是否创建倒排索引,默认为true(也就是可参与分词搜索),改成false的话,别人就搜索不到你
- analyzer: 分词器,当字段类型是text时必须指定分词器。如果字段类型是keyword,那么不需要指定分词器
- properties: 子字段,也就是属性和子属性
二、创建索引库
ES中通过Restful请求操作索引库、文档。请求内容用DSL语句来表示。创建索引库和mapping的DSL语法如下
PUT /索引库名称
{
"mappings": {//映射
"properties": {//字段
"字段名":{
"type": "text",
"analyzer": "ik_smart"
},
"字段名2":{
"type": "keyword",
"index": false //false表示这个字段不参与搜索,该字段不会创建为倒排索引,false不加双引号
},
"字段名3":{
"properties": {//这个就是子字段
"子字段": {
"type": "keyword"
}
}
},
// ...略
}
}
}具体操作: 首先保证你已经做好了 '实用篇-ES-环境搭建' ,然后开始下面的操作
systemctl start docker # 启动docker服务
docker restart es #启动elasticsearch容器
docker restart kibana #启动kibana容器第一步: 浏览器访问 http://192.168.229.129:5601 。输入如下,注意把注释删掉
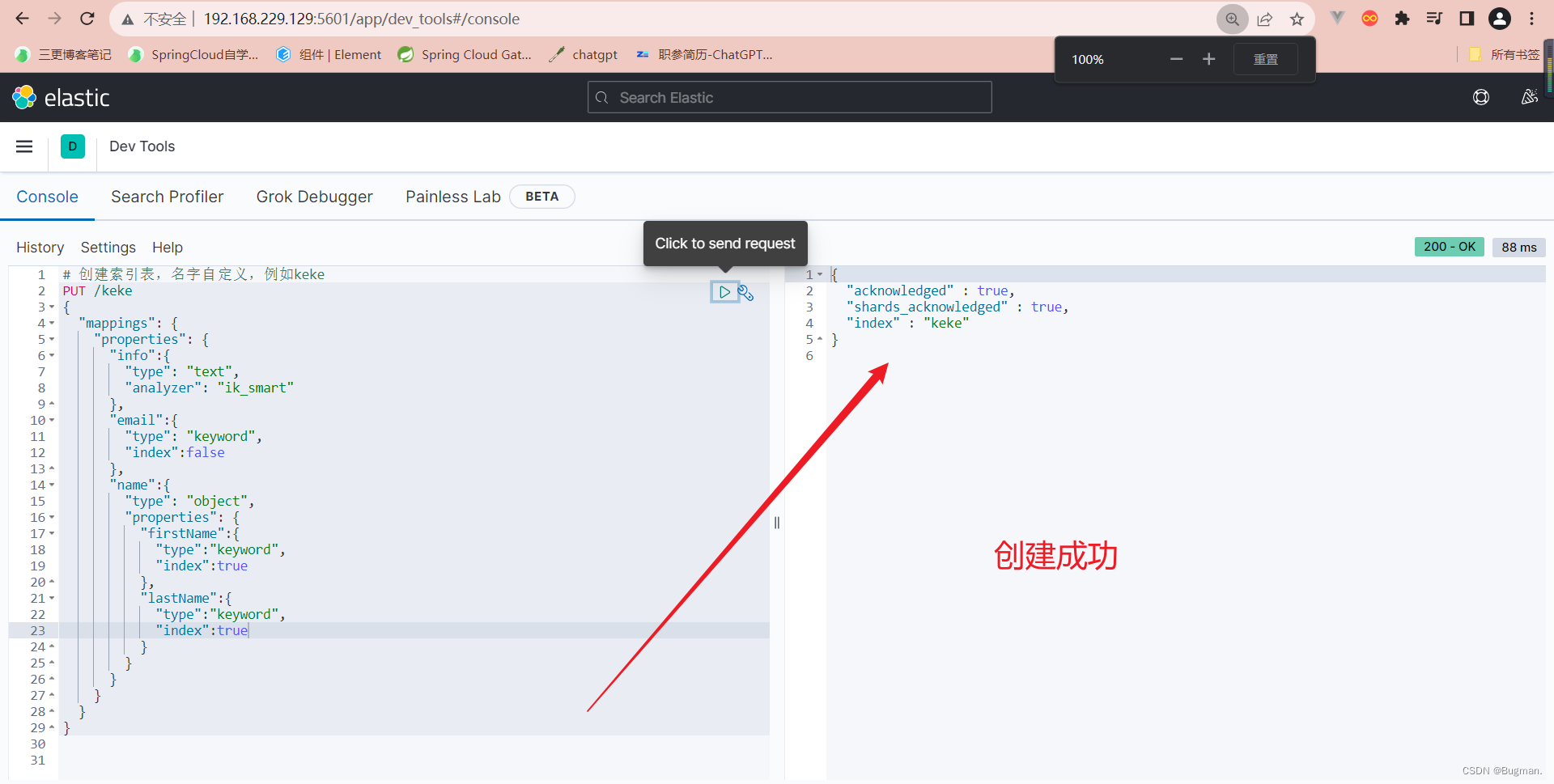
# 创建索引库,名字自定义,例如keke
PUT /keke
{
"mappings": {
"properties": {
"xxinfo": {
"type": "text", //文本类型,可以被分词器分词
"analyzer": "ik_smart" //必须指定分词器
},
"xxemail": {
"type": "keyword", //精确值类型,不可被分词器分词,本身就是最简的
"index": false //不参与搜索,用户不能通过搜索搜到xxemail字段
},
"name": {
"type": "object", //对象类型
"properties": { //父字段
"firstName": { //子字段
"type": "keyword", //精确值类型,不可被分词器分词,本身就是最简的
"index": true //参与搜索,用户通过可搜索到firstName字段
},
"lastName": { //子字段
"type": "keyword", //精确值类型,不可被分词器分词,本身就是最简的
"index": true //参与搜索,用户通过可搜索到lastName字段
}
}
}
}
}
}
三、查询、修改、删除索引库
1. 查询索引库
查询索引库语法
GET /索引库名
2. 修改索引库
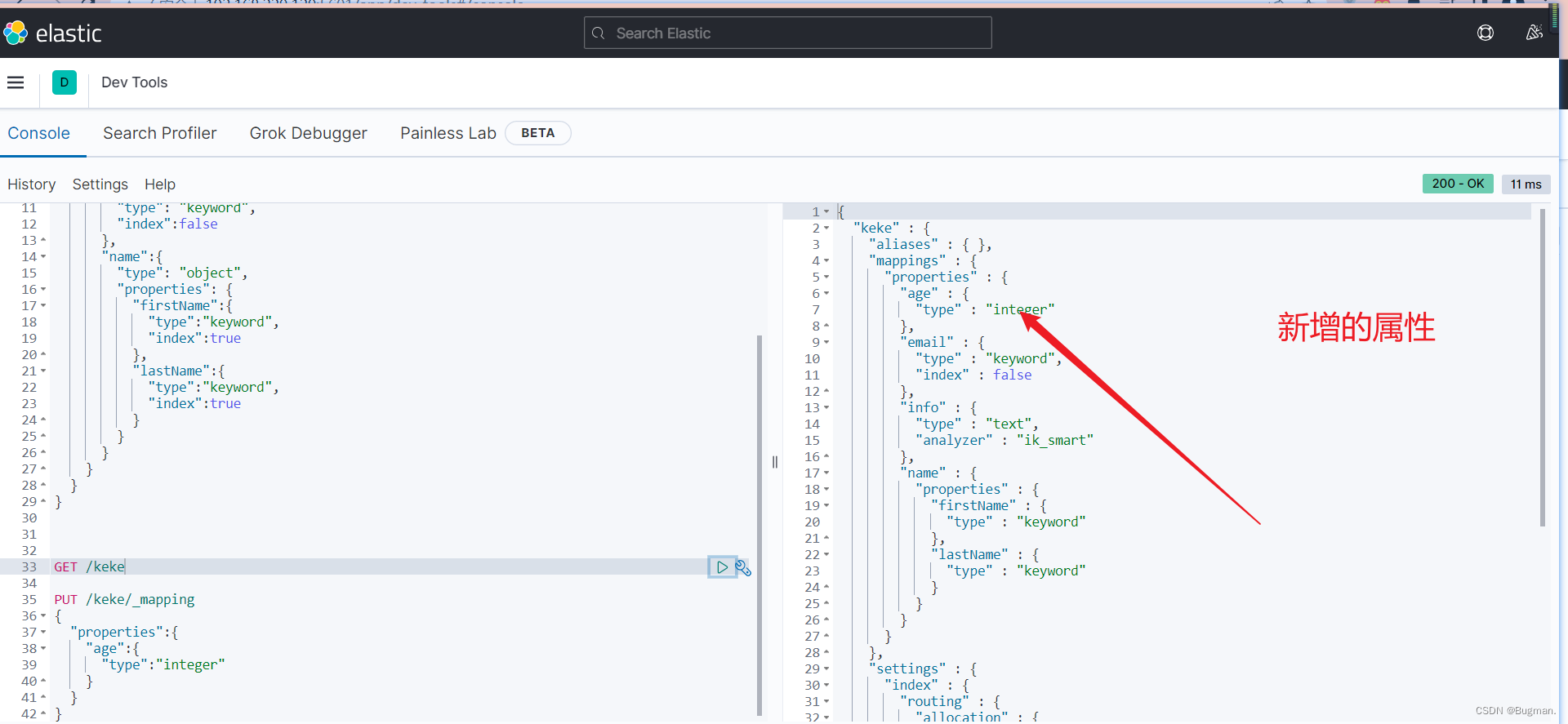
往索引库添加新字段,注意: 索引库是无法被修改的,但是可以添加新字段(不能和已有的重复,否则报错)
PUT /索引库名/_mapping
{
"properties": {
"新字段名":{
"type": "integer"
}
}
}
//例如如下
PUT /keke/_mapping
{
"properties": {
"age": {
"type": "integer"
}
}
}
3. 删除索引库
DELETE /索引库名四、新增、查询、删除文档
具体操作: 首先保证你已经做好了 '实用篇-ES-环境搭建' ,然后开始下面的操作。并且已经创建了名为keke的索引库
systemctl start docker # 启动docker服务
docker restart es #启动elasticsearch容器
docker restart kibana #启动kibana容器1. 新增文档
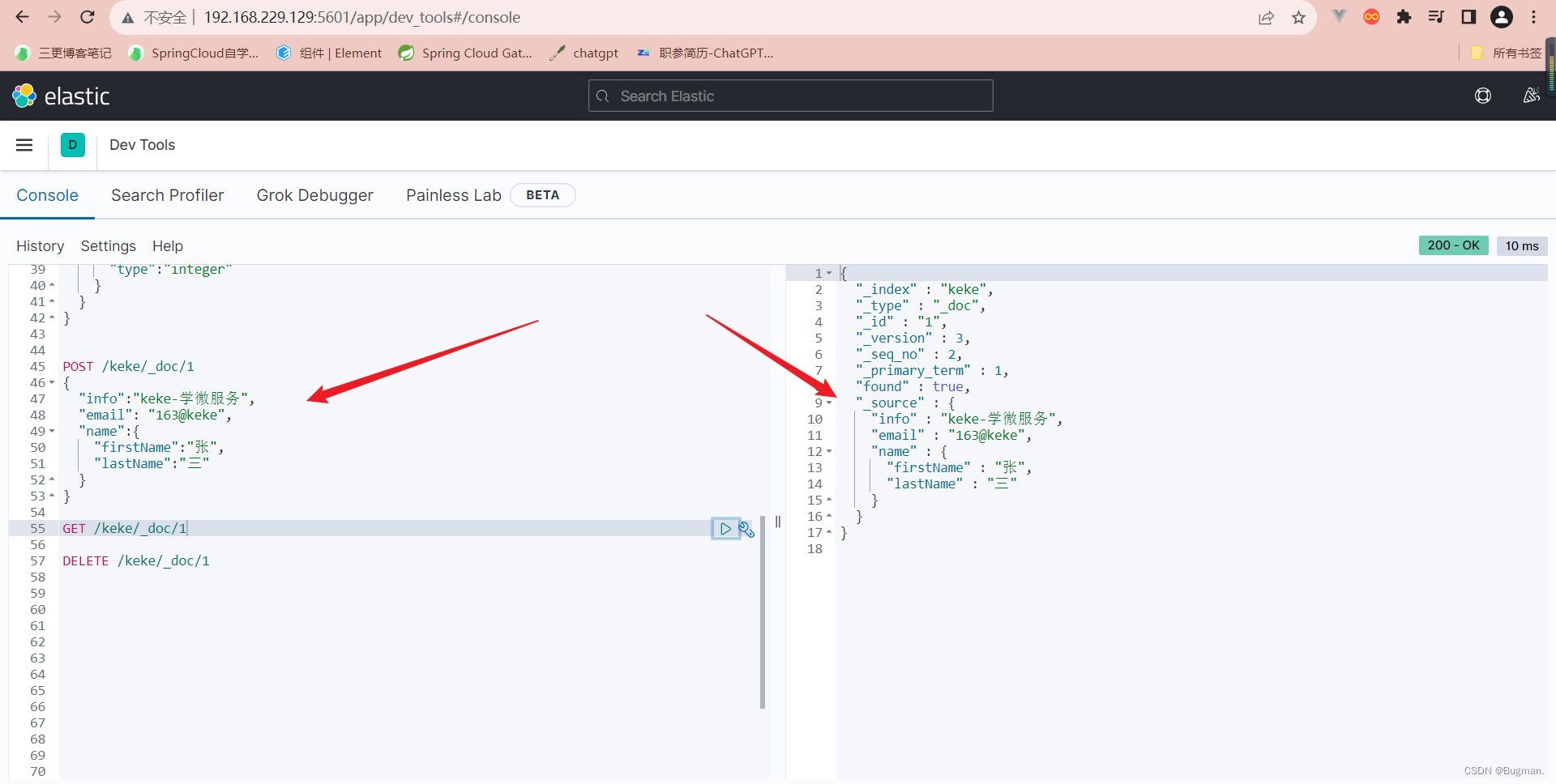
新增文档的DSL语法,其实就是告诉kibana,我们要把文档添加到es的哪个索引库,如果省略文档id的话,es会默认随机生成一个,建议自己指定文档id
POST /索引库名/_doc/文档id
{
"字段1": "值1",
"字段2": "值2",
"字段3": {
"子属性1": "值3",
"子属性2": "值4"
},
// ...
}POST /keke/_doc/1
{
"info":"keke-学微服务",
"email": "163@keke",
"name":{
"firstName":"张",
"lastName":"三"
}
}
2. 查询文档
GET /索引库名/_doc/文档id3. 删除文档
DELETE/索引库名/_doc/文档id 五、修改文档
方式一: 全量修改,会删除旧文档,添加新文档。修改文档的DSL语法,如下
注意: 这种操作是直接用新值覆盖掉旧的,如果只put一个字段那么其它字段就没了,所以,你不想修改的字段也要原样写出来,不然就没了
注意: 如果你写的文档id或字段不存在的话,本来是修改操作,结果就变成新增操作
PUT /索引库名/_doc/文档id
{
"字段1": "值1",
"字段2": "值2",
// ... 略
}PUT /keke/_doc/1
{
"xxinfo":"keke-学三更博客项目",
"email": "123@keke.cn",
"name":{
"firstName":";李",
"lastName":"四"
}
}
方式二: 增量修改。修改指定字段的值
注意: 如果你写的文档id或字段不存在的话,本来是修改操作,结果就变成新增操作
POST /索引库名/_update/文档id
{
"doc": {
"要修改的字段名": "新的值",
}
}POST /keke/_update/1
{
"doc": {
"firstName": "theshy or faker"
}
}