0、配准环境教程
1、开始导入相应的包
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision.transforms import ToTensor
torch是pytorch的简写
torch.utils.data import DataLoader 是用于读取数据的迭代器
torchvision是视觉处理包,datasets导入的是视觉相关的数据集
transforms 是用于图像变换的。
2、下载数据集(准备数据集)
# Download training data from open datasets.
training_data = datasets.FashionMNIST(
root="data",
train=True,
download=True,
transform=ToTensor(),
)
# Download test data from open datasets.
test_data = datasets.FashionMNIST(
root="data",
train=False,
download=True,
transform=ToTensor(),
)
datasets.FashionMNIST,指的是一个数据集,这个数据集用于服饰的识别。FashionMNIST是一个非常流行的图像分类数据集,其中包含10个类别的70000个28x28灰度图像。
当然,pytorch还有很多其他的数据集格式。例如以下的数据集。其他数据集可点击这个连接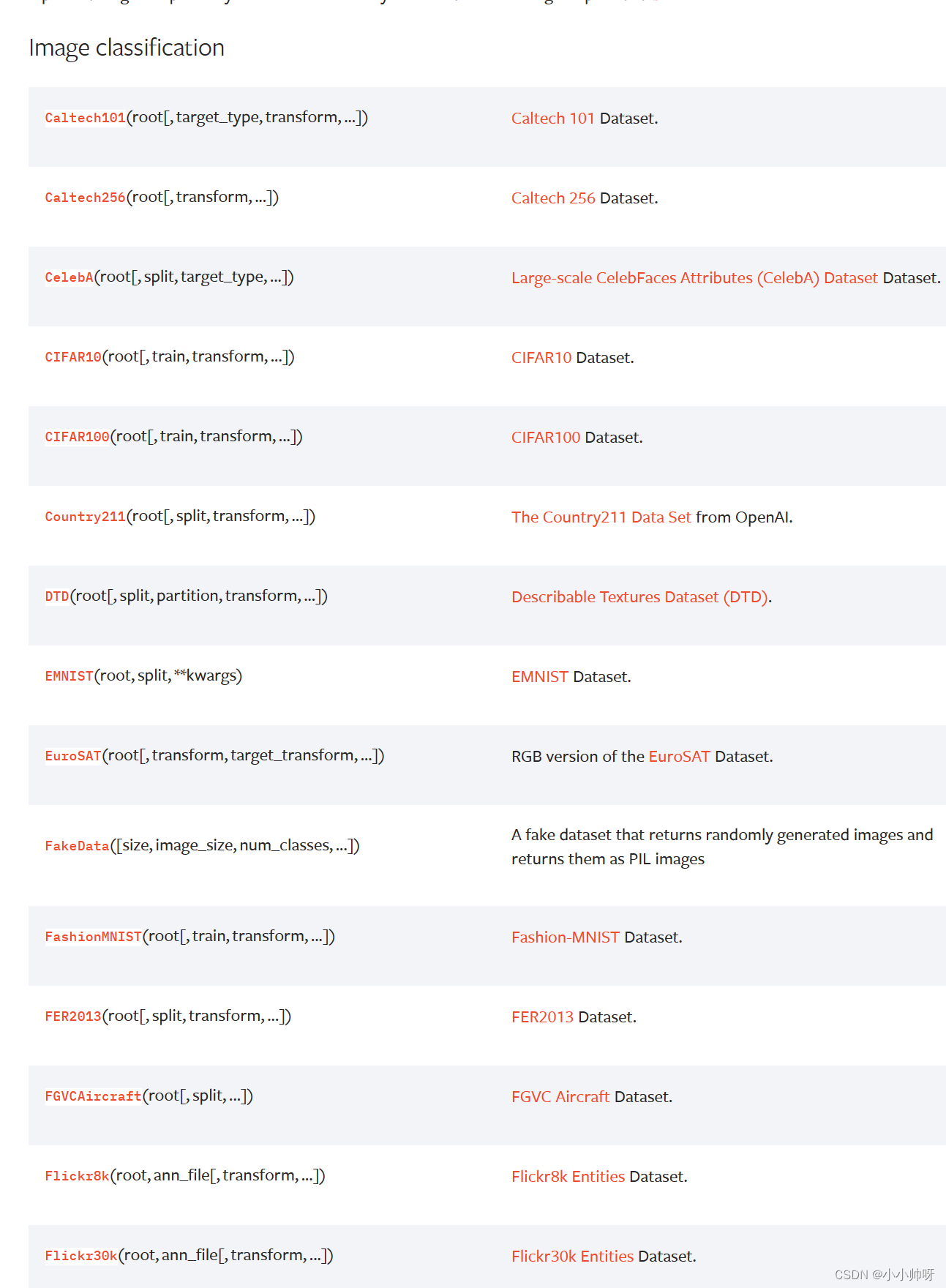
3、加载数据集
batch_size = 64
# Create data loaders.
train_dataloader = DataLoader(training_data, batch_size=batch_size)
test_dataloader = DataLoader(test_data, batch_size=batch_size)
for X, y in test_dataloader:
print(f"Shape of X [N, C, H, W]: {X.shape}")
print(f"Shape of y: {y.shape} {y.dtype}")
break
DataLoader是PyTorch中一个非常有用的模块,它主要用于批量加载数据,特别是当数据集非常大时,DataLoader可以极大地提高数据加载速度并减少内存占用。
DataLoader的主要功能包括:
批量处理数据:DataLoader可以将数据划分为多个批次(batch),每个批次包含一定数量的数据样本,然后一次处理一个批次的数据,这样可以大大减少内存占用。
数据打乱:通过设置shuffle=True参数,DataLoader可以在每个epoch开始时随机打乱数据集的顺序,这样可以增加模型的泛化能力。
batch_size 指的是每次读取的数据的大小,这里设置一次读取64张
4、创建训练的模型
# Get cpu, gpu or mps device for training.
device = (
"cuda"
if torch.cuda.is_available()
else "mps"
if torch.backends.mps.is_available()
else "cpu"
)
print(f"Using {device} device")
# Define model
class NeuralNetwork(nn.Module):
def __init__(self):
super().__init__()
self.flatten = nn.Flatten()
self.linear_relu_stack = nn.Sequential(
nn.Linear(28*28, 512),
nn.ReLU(),
nn.Linear(512, 512),
nn.ReLU(),
nn.Linear(512, 10)
)
def forward(self, x):
x = self.flatten(x)
logits = self.linear_relu_stack(x)
return logits
model = NeuralNetwork().to(device)
print(model)
super().init()表示调用父类(nn.Module)的 init() 方法
self.flatten = nn.Flatten(),这行代码的作用主要是在神经网络模型中的作用是将输入数据从多维(例如二维或三维)转化为一维,这个操作通常被称为"flatten"。
在这个例子中,该模型预期的输入是一个形状为[batch_size, 28, 28]的张量,即一个包含多个(这里是28*28=784个)特征值的数据集。nn.Flatten()层将这个三维数据转化为一维数组,以便后续的线性层(nn.Linear)能以更高效的方式进行操作。
nn.Sequential 是 PyTorch 中一个用于创建顺序神经网络模型的模块。它是一个有序的容器,可以包含任意数量的其他模块。当你将数据输入到 nn.Sequential 模型时,数据会按照你在容器中定义的顺序通过每个模块。
5、设置优化器以及损失函数
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=1e-3)
损失函数还有很多种,其他的参考点击这个链接
优化器也有很多种,如ASGD,ADAM等等,其他的参考这个链接
6、模型的训练
定义训练的过程
def train(dataloader, model, loss_fn, optimizer):
size = len(dataloader.dataset)
model.train()
for batch, (X, y) in enumerate(dataloader):
X, y = X.to(device), y.to(device)
# Compute prediction error
pred = model(X)
loss = loss_fn(pred, y)
# Backpropagation
loss.backward()
optimizer.step()
optimizer.zero_grad()
if batch % 100 == 0:
loss, current = loss.item(), (batch + 1) * len(X)
print(f"loss: {loss:>7f} [{current:>5d}/{size:>5d}]")
从数据集中,每次取一个图像个标签进行训练,然后反向传播,梯度优化,完成训练。
item():.item()是用来从张量中提取标量值的方法。当你调用.item()方法时,如果张量中只有一个元素,那么这个元素会被返回;如果张量中有多个元素,则会抛出一个错误。
def test(dataloader, model, loss_fn):
size = len(dataloader.dataset)
num_batches = len(dataloader)
model.eval()
test_loss, correct = 0, 0
with torch.no_grad():
for X, y in dataloader:
X, y = X.to(device), y.to(device)
pred = model(X)
test_loss += loss_fn(pred, y).item()
correct += (pred.argmax(1) == y).type(torch.float).sum().item()
test_loss /= num_batches
correct /= size
print(f"Test Error: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f} \n")
correct += (pred.argmax(1) == y).type(torch.float).sum().item():解释:
(pred.argmax(1) == y):首先,这行代码通过argmax(1)获取了每个样本的预测类别。然后,它将预测类别与真实类别进行比较(==)。这将返回一个布尔型的张量,表示每个样本的预测是否正确。
(pred.argmax(1) == y).type(torch.float):接下来,这行代码将布尔型的张量转换为浮点型。在PyTorch中,布尔型的张量会自动转换为浮点型。
(pred.argmax(1) == y).type(torch.float).sum():然后,这行代码计算了所有样本中预测正确的总数。这是通过调用sum()函数实现的,该函数会返回一个张量中所有元素的和。
correct += …:最后,这行代码将预测正确的总数加到了变量correct上。+=是一个累加操作符,它将左侧的变量与右侧的表达式结果相加。
7、定义训练的轮次
epochs = 5
for t in range(epochs):
print(f"Epoch {t+1}\n-------------------------------")
train(train_dataloader, model, loss_fn, optimizer)
test(test_dataloader, model, loss_fn)
print("Done!")
8、保存模型
torch.save(model.state_dict(), "model.pth")
print("Saved PyTorch Model State to model.pth")
model.state_dict():解释:
model.state_dict()函数返回一个包含模型所有参数的字典,torch.save()函数则将这个字典保存到磁盘上的一个文件。
9、加载模型
model = NeuralNetwork().to(device)
model.load_state_dict(torch.load("model.pth"))
10、模型的测试
classes = [
"T-shirt/top",
"Trouser",
"Pullover",
"Dress",
"Coat",
"Sandal",
"Shirt",
"Sneaker",
"Bag",
"Ankle boot",
]
model.eval()
x, y = test_data[0][0], test_data[0][1]
with torch.no_grad():
x = x.to(device)
pred = model(x)
predicted, actual = classes[pred[0].argmax(0)], classes[y]
print(f'Predicted: "{predicted}", Actual: "{actual}"')
所有的完整代码:
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision.transforms import ToTensor
# Download training data from open datasets.
training_data = datasets.FashionMNIST(
root="data",
train=True,
download=True,
transform=ToTensor(),
)
# Download test data from open datasets.
test_data = datasets.FashionMNIST(
root="data",
train=False,
download=True,
transform=ToTensor(),
)
batch_size = 64
# Create data loaders.
train_dataloader = DataLoader(training_data, batch_size=batch_size)
test_dataloader = DataLoader(test_data, batch_size=batch_size)
for X, y in test_dataloader:
print(f"Shape of X [N, C, H, W]: {X.shape}")
print(f"Shape of y: {y.shape} {y.dtype}")
break
# Get cpu, gpu or mps device for training.
device = (
"cuda"
if torch.cuda.is_available()
else "mps"
if torch.backends.mps.is_available()
else "cpu"
)
print(f"Using {device} device")
# Define model
class NeuralNetwork(nn.Module):
def __init__(self):
super().__init__()
self.flatten = nn.Flatten()
self.linear_relu_stack = nn.Sequential(
nn.Linear(28*28, 512),
nn.ReLU(),
nn.Linear(512, 512),
nn.ReLU(),
nn.Linear(512, 10)
)
def forward(self, x):
x = self.flatten(x)
logits = self.linear_relu_stack(x)
return logits
model = NeuralNetwork().to(device)
print(model)
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=1e-3)
def train(dataloader, model, loss_fn, optimizer):
size = len(dataloader.dataset)
model.train()
for batch, (X, y) in enumerate(dataloader):
X, y = X.to(device), y.to(device)
# Compute prediction error
pred = model(X)
loss = loss_fn(pred, y)
# Backpropagation
loss.backward()
optimizer.step()
optimizer.zero_grad()
if batch % 100 == 0:
loss, current = loss.item(), (batch + 1) * len(X)
print(f"loss: {loss:>7f} [{current:>5d}/{size:>5d}]")
def test(dataloader, model, loss_fn):
size = len(dataloader.dataset)
num_batches = len(dataloader)
model.eval()
test_loss, correct = 0, 0
with torch.no_grad():
for X, y in dataloader:
X, y = X.to(device), y.to(device)
pred = model(X)
test_loss += loss_fn(pred, y).item()
correct += (pred.argmax(1) == y).type(torch.float).sum().item()
test_loss /= num_batches
correct /= size
print(f"Test Error: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f} \n")
epochs = 5
for t in range(epochs):
print(f"Epoch {t+1}\n-------------------------------")
train(train_dataloader, model, loss_fn, optimizer)
test(test_dataloader, model, loss_fn)
print("Done!")