2023年华为杯数学建模E题 代码复盘
- 写在最前面
- 目录
- 问题1a
- 计算时间间隔
- 思路说明
- 代码
- 输出结果
- 插值求解
- 思路
- 代码
- 输出结果
- 绘图
- 绘制3D图(待修改)
- 问题1b
- 数据预处理
- 思路
- 代码
- 模型训练
- 思路
- 代码
- 输出结果
- 网格调参代码
- 输出结果
写在最前面
超开心又有点遗憾
结果上来看 国二很可以了 顺便买个策略的教训
和数统专业队友——文月宝 配合相当默契 ~ 主要负责写代码,第一次建模比赛可以几乎不写论文,说一下思路就行,真的好爽啊;还能帮我把绘图优化,流程图也真的好好看
其他;
嘿嘿是每年一次的数模!每次都玩的好开心,这次也是!
每次数模建模有点像是一年一次的摸底考,通过实践感受自身的进步。
2023年,今年改代码时能捕捉到代码的内在逻辑,然后比较顺利的根据题目定制,改完之后几乎都能跑通,开心 ✿✿ヽ(°▽°)ノ✿
下面是这次的代码复盘,欢迎交流
整体框架:题目+问题1+a、b、c
题目+分解模块+思路+代码
目录
没错,这就是提交的论文目录。玩的很开心也很遗憾

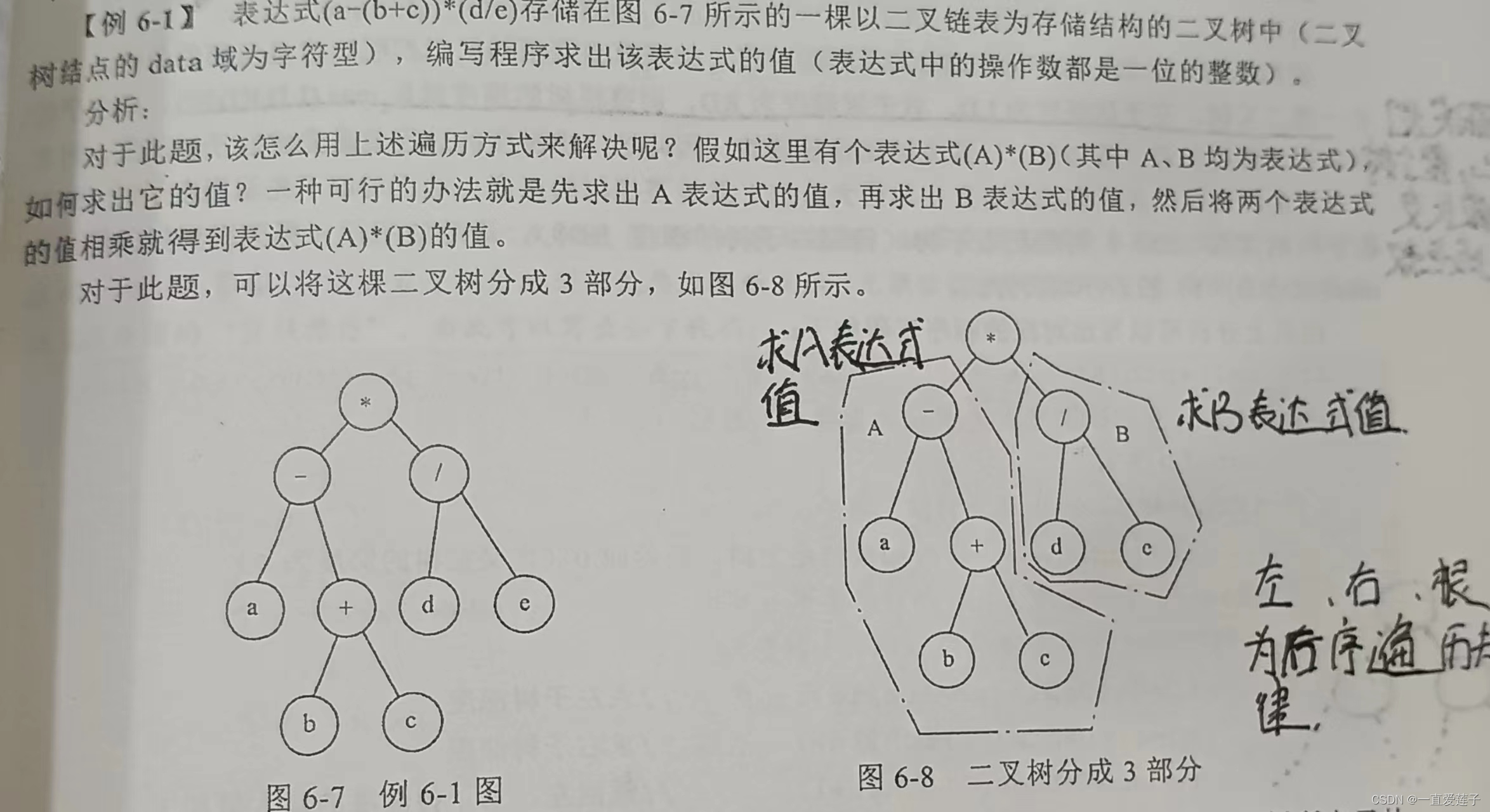
问题1a
1、计算时间间隔
2、三阶样条插值。三种插值区间:不插值、(xmin,48)、(0,48)
3、绘图。为了求解方便,代码长度缩小方便修改,因此上述代码不包含绘图
计算时间间隔
思路说明
简单的数据处理
包含:读取数据,转化为日期时间对象,
一些小设计:
① 由于一共有13个时间间隔,能循环的就不枚举
通过enumerate+df[f"随访{i}时间点"]实现
for i, interval_name in enumerate(time_intervals, start=1):
print(f"Index {i}: {interval_name}")
df[interval_name] = (df[f"随访{i}时间点"] - df["入院首次检查时间点"]).dt.total_seconds() / 3600 + df1["发病到首次影像检查时间间隔"]
计算两个日期间的时间间隔,并间隔时间的单位,从s换算成h
df["入院首次检查时间点"]).dt.total_seconds() / 3600
② 字符串转换为日期时间对象
# 使用循环将"随访i时间点"列的数据从字符串转换为日期时间对象(一共12个)
# for i in range(1,12):
for i in range(1,8):
df[f"随访{i}时间点"] = pd.to_datetime(df[f"随访{i}时间点"], format="%Y/%m/%d %H:%M:%S")
代码
import pandas as pd
# 读取Excel文件
file_path = "附表1-检索表格-流水号vs时间.xlsx"
df = pd.read_excel(file_path)
file_path1 = "表1-患者列表及临床信息.xlsx"
df1 = pd.read_excel(file_path1)
file_path2 = "表2-患者影像信息血肿及水肿的体积及位置.xlsx"
df2 = pd.read_excel(file_path2)
# 打印前几行数据
# print(df2.head())
column_list = df2.columns.tolist()
print(column_list)
# 将"入院首次检查时间点"列的数据从字符串转换为日期时间对象
df["入院首次检查时间点"] = pd.to_datetime(df["入院首次检查时间点"], format="%Y/%m/%d %H:%M:%S")
# 将"随访1时间点"列的数据从字符串转换为日期时间对象
# df["随访1时间点"] = pd.to_datetime(df["随访1时间点"], format="%Y/%m/%d %H:%M:%S")
# 使用循环将"随访i时间点"列的数据从字符串转换为日期时间对象(一共12个)
# for i in range(1,12):
for i in range(1,8):
df[f"随访{i}时间点"] = pd.to_datetime(df[f"随访{i}时间点"], format="%Y/%m/%d %H:%M:%S")
# 创建一个列表来存储不同随访时间点的时间间隔列名
time_intervals = []
# 使用循环创建列名并添加到列表中
# for i in range(1, 13): # 从1到12,包括1和12
for i in range(1, 9):
column_name = f"发病时间间隔{i}(h)"
time_intervals.append(column_name)
# 打印时间间隔列名列表
print(time_intervals)
# 使用循环计算每个随访时间点与入院首次检查时间点之间的时间间隔
# 使用循环读取时间间隔字符串并计算时间间隔interval
df['发病时间间隔0(h)']= df1["发病到首次影像检查时间间隔"]
for i, interval_name in enumerate(time_intervals, start=1):
print(f"Index {i}: {interval_name}")
df[interval_name] = (df[f"随访{i}时间点"] - df["入院首次检查时间点"]).dt.total_seconds() / 3600 + df1["发病到首次影像检查时间间隔"]
# 绝对体积增加
deltaV0 = []
for i in range(1, 9):
column_name = f"绝对体积增加{i}"
deltaV0.append(column_name)
print(deltaV0)
for i in range(1, 9):
# print(f"绝对体积增加{i}")
# 用sub()方法计算差值,只处理不是空值的行
# df2[f"绝对体积增加{i}"] = df2[f'HM_volume.{i}'].sub(df2['HM_volume'], fill_value=0)
df2[f"绝对体积增加{i}"] = df2[f'HM_volume.{i}'].sub(df2['HM_volume'])
# 相对体积增加
deltaV1 = []
for i in range(1, 9):
column_name = f"相对体积增加{i}"
deltaV1.append(column_name)
print(deltaV1)
# 相对体积增加
for i in range(1, 9):
df2[f"相对体积增加{i}"] = df2[f"绝对体积增加{i}"] / df2['HM_volume']
# 选择只包括"编号"和时间间隔列的子数据框
result_df0 = df[["编号"] + ['发病时间间隔0(h)'] + time_intervals]
result_df1 = df2[["ID"] + deltaV0 + deltaV1]
# 表连接
merged_df = pd.merge(result_df0, result_df1, left_on="编号", right_on="ID")
# 保存结果到新的Excel文件
result_file_path = "1a血肿体积增加的时间间隔.xlsx"
merged_df.to_excel(result_file_path, index=False)
输出结果
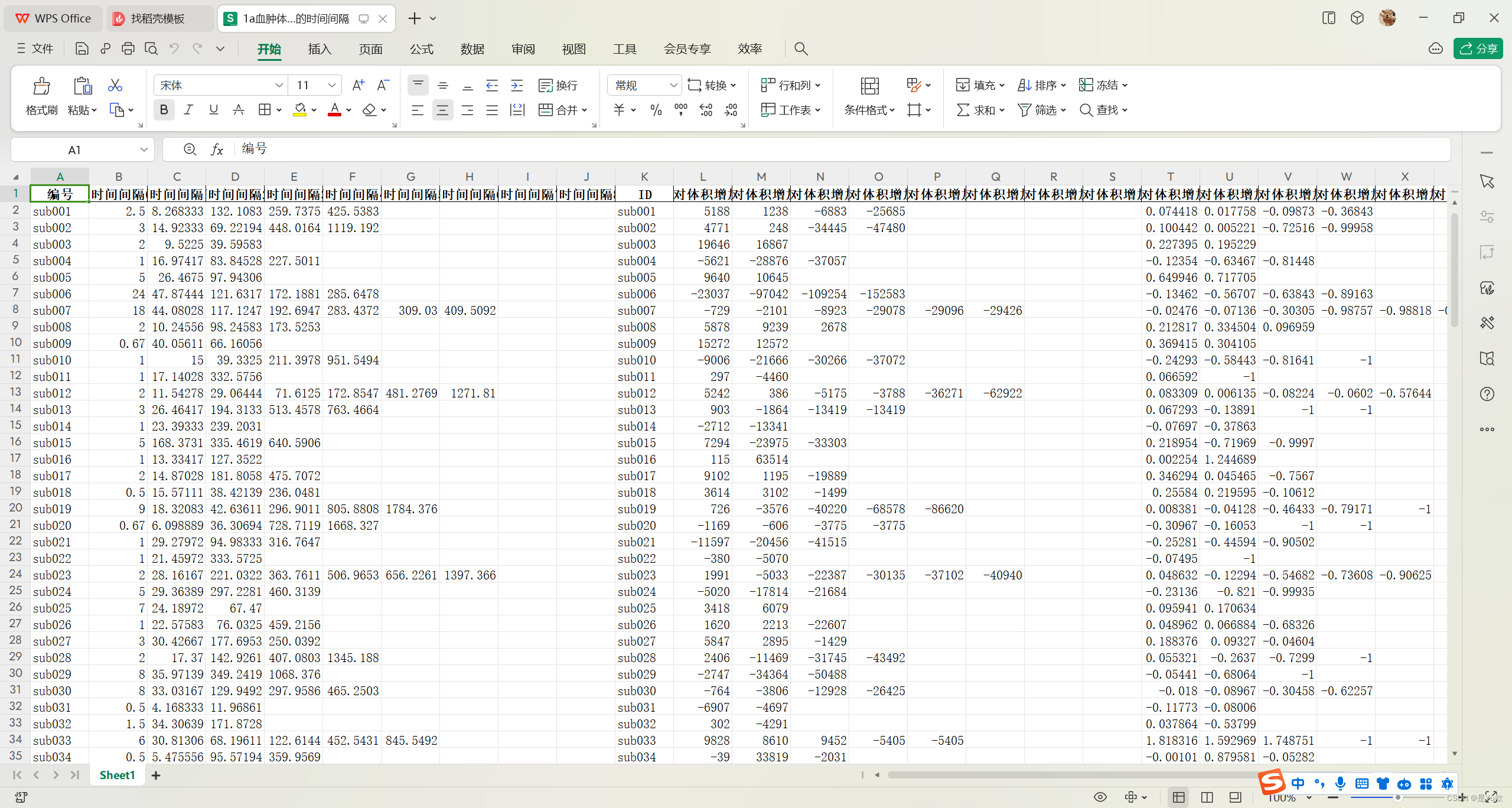
插值求解
思路
1、绝对体积增加、相对面积增加
2、三阶样条插值,并绘图。三种插值区间:不插值、(xmin,48)、(0,48)
通过修改u = np.linspace(x.min(), 48, 1000)中的(x.min(), 48)更改区间
# 用三阶样条插值拟合曲线,指定边界条件
f = spi.CubicSpline(x, y, bc_type='natural')
u = np.linspace(x.min(), 48, 1000) # 生成更多的数据点进行插值
u1 = np.linspace(0, 48, 1000) # 生成更多的数据点进行插值
v = f(u)
v1= f(u1)
3、合并绝对体积和相对体积的三种插值方式的时间最小值
for x, y in zip(first_increase_times00, first_increase_times10):
if x is None and y is None:
result0.append(None)
elif x is None:
result0.append(y)
elif y is None:
result0.append(x)
else:
result0.append(min(x, y))
4、通过发生时间,判断"是否发生血肿扩张"列中的相应行设置为1
# 使用条件语句将"是否发生血肿扩张"列中的相应行设置为1
df5.loc[df5["血肿扩张发生时间"].notna(), "是否发生血肿扩张"] = 1
5、求解个数
count_of_ones = (df5["是否发生血肿扩张"] == 1).sum()
print("不插值,前48h血肿扩张的个数:", count_of_ones)
代码
import pandas as pd
# 读取Excel文件
file_path3 = "1a血肿体积增加的时间间隔.xlsx"
df3 = pd.read_excel(file_path3)
# combined_range = list(range(0, 100))
# 创建两个范围对象
# df3 = df3.drop(range(100, 130))
range1 = range(0, 100) # 从0到99
range2 = range(130, 160) # 从129到159
# 合并两个范围
combined_range = list(range1) + list(range2)
print(combined_range)
df3 = df3.iloc[combined_range]
print(df3.shape)
print(list(df3["ID"]))
import matplotlib.pyplot as plt
import scipy.interpolate as spi
import numpy as np
time_intervals = ['发病时间间隔1(h)', '发病时间间隔2(h)', '发病时间间隔3(h)', '发病时间间隔4(h)', '发病时间间隔5(h)', '发病时间间隔6(h)', '发病时间间隔7(h)', '发病时间间隔8(h)']
deltaV0 = ['绝对体积增加1', '绝对体积增加2', '绝对体积增加3', '绝对体积增加4', '绝对体积增加5', '绝对体积增加6', '绝对体积增加7', '绝对体积增加8']
time0 = df3[time_intervals]
deltaV00 = df3[deltaV0]
# 不插值初始化一个列表来存储每个患者的第一次绝对体积增加至少6 mL的时间点
first_increase_times00 = []
# (xmin,48)初始化一个列表来存储每个患者的第一次绝对体积增加至少6 mL的时间点
first_increase_times01 = []
# (0,48)初始化一个列表来存储每个患者的第一次绝对体积增加至少6 mL的时间点
first_increase_times02 = []
flag00 = 0
flag01 = 0
flag02 = 0
# 循环绘制100条曲线
for i in combined_range:
x0 = time0.loc[i]
y0 = deltaV00.loc[i]
# 删除包含NaN值的列,然后重新创建一个DataFrame
x = x0.dropna().reset_index(drop=True)
y = y0.dropna().reset_index(drop=True)
# print(i,x.shape,y.shape)
# 如果 x 只有一个元素,将 y 设置为恒等于 x
if len(x) == 1:
f = np.full_like(x, x[0])
v = f
v1 = f
else:
# 用三阶样条插值拟合曲线,指定边界条件
f = spi.CubicSpline(x, y, bc_type='natural')
u = np.linspace(x.min(), 48, 1000) # 生成更多的数据点进行插值
u1 = np.linspace(0, 48, 1000) # 生成更多的数据点进行插值
v = f(u)
v1= f(u1)
# 寻找插值前第一次绝对体积增加至少6 mL的时间点
threshold = 6000
for t, volume in zip(x, y):
if volume >= threshold and 0 < t <= 48:
first_increase_times00.append(t)
flag00 = flag00 + 1
break # 找到后跳出循环
else:
first_increase_times00.append(None) # 如果未找到,添加 None
# 寻找插值后第一次绝对体积增加至少6 mL的时间点
for t, volume in zip(u, v):
if volume >= threshold and t <= 48:
first_increase_times01.append(t)
flag01 = flag01 + 1
break # 找到后跳出循环
else:
first_increase_times01.append(None) # 如果未找到,添加 None
# 寻找插值后第一次绝对体积增加至少6 mL的时间点
for t, volume in zip(u1, v1):
if volume >= threshold and t <= 48:
first_increase_times02.append(t)
flag01 = flag02 + 1
break # 找到后跳出循环
else:
first_increase_times02.append(None) # 如果未找到,添加 None
print("插值前,前48h绝对体积增加至少6mL的有",flag00,"个")
print(len(first_increase_times00))
print(first_increase_times00)
print("插值后,前48h绝对体积增加至少6mL的有",flag01,"个")
print(len(first_increase_times01))
print(first_increase_times01)
print("(0,48)插值后,前48h绝对体积增加至少6mL的有",flag02,"个")
print(len(first_increase_times02))
print(first_increase_times02)
相对体积
import matplotlib.pyplot as plt
import scipy.interpolate as spi
import numpy as np
deltaV1 = ['相对体积增加1', '相对体积增加2', '相对体积增加3', '相对体积增加4', '相对体积增加5', '相对体积增加6', '相对体积增加7', '相对体积增加8']
time0 = df3[time_intervals]
deltaV01 = df3[deltaV1]
flag10 = 0
flag11 = 0
flag12 = 0
# 初始化一个列表来存储每个患者的第一次相对体积增加至少0.33 mL的时间点
first_increase_times10 = []
first_increase_times11 = []
first_increase_times12 = []
# 循环绘制100条曲线
for i in combined_range:
x0 = time0.loc[i]
y0 = deltaV01.loc[i]
# 删除包含NaN值的行,然后重新创建一个DataFrame
x = x0.dropna().reset_index(drop=True)
y = y0.dropna().reset_index(drop=True)
# 如果 x 只有一个元素,将 y 设置为恒等于 x
if len(x) == 1:
f = np.full_like(x, x[0])
v = f
v1 = f
else:
# 用三阶样条插值拟合曲线,指定边界条件
f = spi.CubicSpline(x, y, bc_type='natural')
u = np.linspace(x.min(), 48, 1000) # 生成更多的数据点进行插值
u1 = np.linspace(0, 48, 1000) # 生成更多的数据点进行插值
v = f(u)
v1 = f(u1)
# 寻找插值前第一次相对体积增加至少33%的时间点
threshold = 0.33
for t, volume in zip(x,y):
if volume >= threshold and t <= 48:
first_increase_times10.append(t)
flag10 = flag10 + 1
break # 找到后跳出循环
else:
first_increase_times10.append(None) # 如果未找到,添加 None
# 寻找插值后第一次相对体积增加至少33%的时间点
for t, volume in zip(u, v):
if volume >= threshold and t <= 48:
first_increase_times11.append(t)
flag11 = flag11 + 1
break # 找到后跳出循环
else:
first_increase_times11.append(None) # 如果未找到,添加 None
# 寻找(0,48)插值后第一次相对体积增加至少33%的时间点
for t, volume in zip(u1, v1):
if volume >= threshold and t <= 48:
first_increase_times12.append(t)
flag12 = flag12 + 1
break # 找到后跳出循环
else:
first_increase_times12.append(None) # 如果未找到,添加 None
print("插值前,前48h相对体积增加至少33%的有",flag10,"个")
print(len(first_increase_times10))
print(first_increase_times10)
print("插值后,前48h相对体积增加至少33%的有",flag11,"个")
print(len(first_increase_times11))
print(first_increase_times11)
print("(0,48)插值后,前48h相对体积增加至少33%的有",flag12,"个")
print(first_increase_times12)
print(len(first_increase_times12))
# 合并绝对体积和相对体积
import math
result0 = []
result1 = []
result2 = []
for x, y in zip(first_increase_times00, first_increase_times10):
if x is None and y is None:
result0.append(None)
elif x is None:
result0.append(y)
elif y is None:
result0.append(x)
else:
result0.append(min(x, y))
print(result0)
print(len(result0))
for x, y in zip(first_increase_times01, first_increase_times11):
if x is None and y is None:
result1.append(None)
elif x is None:
result1.append(y)
elif y is None:
result1.append(x)
else:
result1.append(min(x, y))
print(result1)
print(len(result1))
for x, y in zip(first_increase_times02, first_increase_times12):
if x is None and y is None:
result2.append(None)
elif x is None:
result2.append(y)
elif y is None:
result2.append(x)
else:
result2.append(min(x, y))
print(result2)
print(len(result2))
输出结果
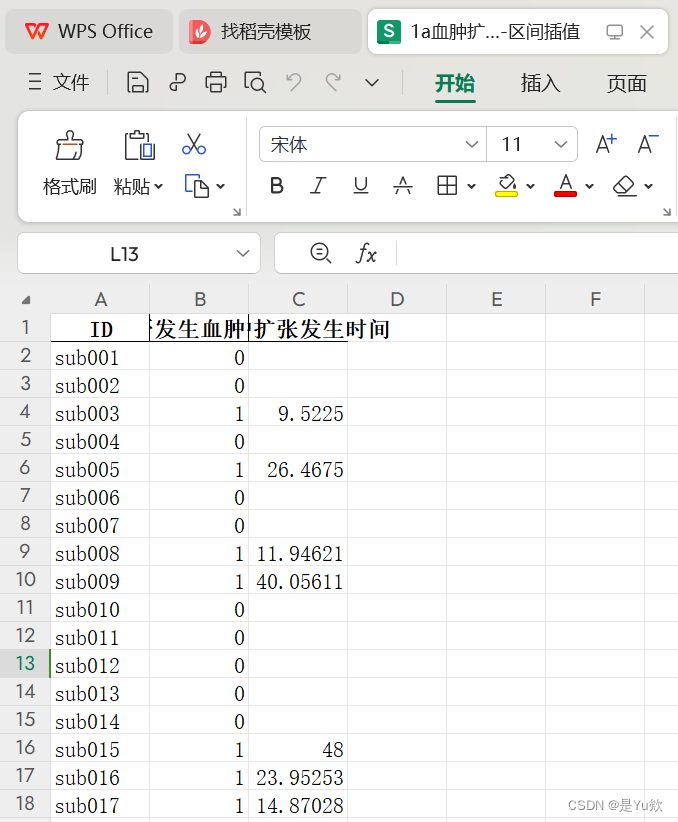
绘图
为了求解方便,代码长度缩小方便修改,因此上述代码不包含绘图,下面是绘图示例:
import matplotlib.pyplot as plt
import scipy.interpolate as spi
import numpy as np
# 支持中文
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
time_intervals = ['发病时间间隔1(h)', '发病时间间隔2(h)', '发病时间间隔3(h)', '发病时间间隔4(h)', '发病时间间隔5(h)', '发病时间间隔6(h)', '发病时间间隔7(h)', '发病时间间隔8(h)']
deltaV0 = ['绝对体积增加1', '绝对体积增加2', '绝对体积增加3', '绝对体积增加4', '绝对体积增加5', '绝对体积增加6', '绝对体积增加7', '绝对体积增加8']
time0 = df3[time_intervals]
deltaV00 = df3[deltaV0]
# 循环绘制100条曲线
for i in range(100):
x0 = time0.loc[i]
y0 = deltaV00.loc[i]
# 删除包含NaN值的列,然后重新创建一个DataFrame
x = x0.dropna().reset_index(drop=True)
y = y0.dropna().reset_index(drop=True)
# 用三阶样条插值拟合曲线,指定边界条件
f = spi.CubicSpline(x, y, bc_type='natural')
u = np.linspace(x.min(), x.max(), 1000) # 生成更多的数据点进行插值
v = f(u)
plt.plot(u, v)
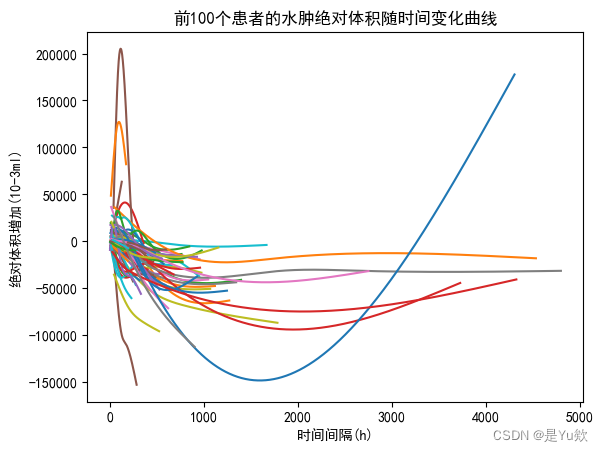
# 设置图表标题和轴标签
plt.title('前100个患者的水肿绝对体积随时间变化曲线')
plt.xlabel('时间间隔(h)')
plt.ylabel('绝对体积增加(10-3ml)')
# 显示图表
plt.show()
import matplotlib.pyplot as plt
import scipy.interpolate as spi
import numpy as np
# 支持中文
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.figure(figsize=(5, 10))
flag10 = 0
flag11 = 0
time0 = df3[time_intervals]
deltaV01 = df3[deltaV1]
# 初始化一个列表来存储每个患者的第一次相对体积增加至少0.33 mL的时间点
first_increase_times1 = []
# 循环绘制100条曲线
for i in range(100):
x0 = time0.loc[i]
y0 = deltaV01.loc[i]
# 删除包含NaN值的行,然后重新创建一个DataFrame
x = x0.dropna().reset_index(drop=True)
y = y0.dropna().reset_index(drop=True)
# 绘制原始数据点的散点图
plt.scatter(x, y, color='red', s=10) # 设置散点颜色为红色,大小为10
# 用三阶样条插值拟合曲线,指定边界条件
f = spi.CubicSpline(x, y, bc_type='natural')
# u = np.linspace(0,48, 1000) # 生成更多的数据点进行插值
# u = np.linspace(x.min(), x.max(), 1000) # 生成更多的数据点进行插值
u = np.linspace(x.min(), 48, 1000) # 生成更多的数据点进行插值
v = f(u)
plt.plot(u, v)
# 寻找插值前第一次相对体积增加至少33%的时间点
threshold = 0.33
for t, volume in zip(x,y):
if volume >= threshold and t <= 48:
flag10 = flag10 + 1
break # 找到后跳出循环
# 寻找插值后第一次相对体积增加至少33%的时间点
for t, volume in zip(u, v):
if volume >= threshold and t <= 48:
first_increase_times1.append(t)
flag11 = flag11 + 1
break # 找到后跳出循环
else:
first_increase_times1.append(None) # 如果未找到,添加 None
print("插值前,前48h相对体积增加至少33%的有",flag10,"个")
print("插值后,前48h相对体积增加至少33%的有",flag11,"个")
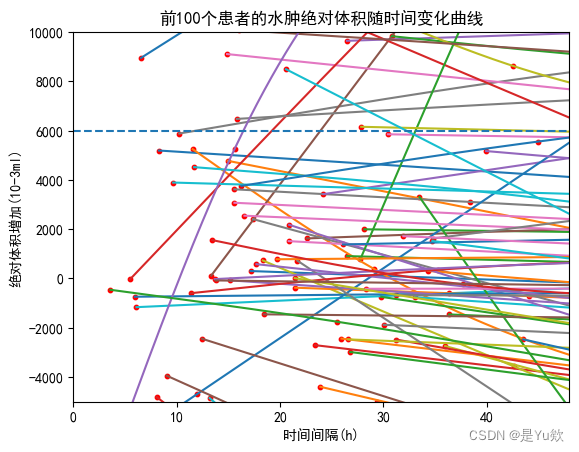
# 设置图表标题和轴标签
plt.title('前100个患者的水肿相对体积随时间变化曲线')
plt.xlabel('时间间隔(h)')
plt.ylabel('相对体积增加(%)')
# 设置 x 轴范围
plt.xlim(0, 48)
plt.ylim(-0.75, 1)
# 绘制虚线
a = np.linspace(0, 48, 1000)
plt.plot(a , np.full_like(a, 0.33), '--', label='y=6000')
# 显示图表
plt.show()
print(first_increase_times1)
绘制3D图(待修改)
问题1b
1、承接1a,分三个插值区域分别进行求解
数据预处理
思路
1、读取表格对应字段
2、对性别、血压进行处理
# 使用replace方法将'男'替换为1,'女'替换为0
final_merged_table['性别'] = final_merged_table['性别'].replace({'男': 1, '女': 0})
# 创建新的'血压高'和'血压低'列,根据'血压'列的值拆分
final_merged_table[['血压高', '血压低']] = final_merged_table['血压'].str.split('/', expand=True)
代码
import pandas as pd
# 读取Excel文件
file_path1 = "表1-患者列表及临床信息.xlsx"
df1 = pd.read_excel(file_path1)
file_path2 = "表2-患者影像信息血肿及水肿的体积及位置.xlsx"
df2 = pd.read_excel(file_path2)
file_path3 = "表3-血肿.xlsx"
df3 = pd.read_excel(file_path3)
file_path4 = "1a血肿扩张发生时间-不插值.xlsx"
df4 = pd.read_excel(file_path4)
file_path5 = "1a血肿扩张发生时间-区间插值.xlsx"
df5 = pd.read_excel(file_path5)
file_path6 = "1a血肿扩张发生时间-0h插值.xlsx"
df6 = pd.read_excel(file_path6)
subset_df1 = df1.iloc[:,[0] + list(range(3, 23))] # 入院首次影像检查流水号+字段E至W
subset_df2 = df2.iloc[:,[0] + list(range(2, 24))] # 字段C至X
subset_df3 = df3.iloc[:,list(range(1, 32))] # 流水号+字段C至AG
# 打印筛选后的数据框(DataFrame)以进行验证
# print(subset_df1)
merged_table0 = pd.merge(df6, subset_df1, on='ID', how='outer')
merged_table = pd.merge(merged_table0, subset_df2, on='ID', how='outer')
final_merged_table = pd.merge(merged_table, subset_df3, left_on='入院首次影像检查流水号',right_on='流水号', how='inner')
# 打印最终合并的表格以进行验证
# print(final_merged_table)
print(final_merged_table.shape)
import pandas as pd
# 使用replace方法将'男'替换为1,'女'替换为0
final_merged_table['性别'] = final_merged_table['性别'].replace({'男': 1, '女': 0})
# 创建新的'血压高'和'血压低'列,根据'血压'列的值拆分
final_merged_table[['血压高', '血压低']] = final_merged_table['血压'].str.split('/', expand=True)
# 使用 drop 方法删除名为"流水号"的列,axis=1 表示按列删除
final_merged_table = final_merged_table.drop(['入院首次影像检查流水号',"流水号","血肿扩张发生时间",'血压'], axis=1)
final_merged_table = final_merged_table.sort_values(by='ID', ascending=True)
# 打印更新后的DataFrame以进行验证
print(final_merged_table)
# 保存结果到新的Excel文件
result_file_path = "1b合并的表.xlsx"
final_merged_table.to_excel(result_file_path, index=False)
模型训练
思路
1、随机森林分类器,分层 K 折交叉验证评估模型性能
2、对比三种数据缩放技术,过采样前后,选择最优的模型
3、最优的技术组合下,随机森林、梯度提升树分类器、SVM三种方法进行网格调参
4、绘制ROC曲线、打印混淆矩阵
代码
from sklearn.model_selection import train_test_split, cross_val_score, StratifiedKFold
from sklearn.ensemble import RandomForestClassifier
from sklearn.preprocessing import StandardScaler
import numpy as np
from imblearn.over_sampling import SMOTE
file_path5 = "1b合并的表.xlsx"
df00 = pd.read_excel(file_path5)
df = df00[:100]
print(df.shape)
X = df.drop(["ID","是否发生血肿扩张"], axis=1)
y = df["是否发生血肿扩张"]
# 过采样:使用SMOTE进行过采样
smote = SMOTE(random_state=42)
X_resampled, y_resampled = smote.fit_resample(X, y)
# 标准化数据
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X_resampled)
# 初始化随机森林分类器
classifier = RandomForestClassifier(random_state=42)
# 创建分层 K 折交叉验证对象,确保每个折中的类别分布与整个数据集相似
cv = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)
# 初始化评估指标的列表
accuracies = []
precisions = []
recalls = []
f1_scores = []
roc_aucs = []
# 使用交叉验证来评估模型性能
for train_idx, test_idx in cv.split(X_scaled, y_resampled):
X_train, X_test = X_scaled[train_idx], X_scaled[test_idx]
y_train, y_test = y_resampled[train_idx], y_resampled[test_idx]
classifier.fit(X_train, y_train)
y_pred = classifier.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
precision = precision_score(y_test, y_pred, zero_division=1) # 设置zero_division参数
recall = recall_score(y_test, y_pred, zero_division=1) # 设置zero_division参数
f1 = f1_score(y_test, y_pred, zero_division=1) # 设置zero_division参数
roc_auc = roc_auc_score(y_test, classifier.predict_proba(X_test)[:, 1])
accuracies.append(accuracy)
precisions.append(precision)
recalls.append(recall)
f1_scores.append(f1)
roc_aucs.append(roc_auc)
# 计算平均值
avg_accuracy = np.mean(accuracies)
avg_precision = np.mean(precisions)
avg_recall = np.mean(recalls)
avg_f1 = np.mean(f1_scores)
avg_roc_auc = np.mean(roc_aucs)
# 打印结果
print(f'Accuracy: {avg_accuracy}')
print(f'Precision: {avg_precision}')
print(f'Recall: {avg_recall}')
print(f'F1-Score: {avg_f1}')
print(f'ROC-AUC: {avg_roc_auc}')
# 绘制ROC曲线
fpr, tpr, thresholds = roc_curve(y_test, classifier.predict_proba(X_test)[:, 1])
plt.figure()
plt.plot(fpr, tpr, label=f'ROC Curve (AUC = {roc_auc:.2f})')
plt.plot([0, 1], [0, 1], 'k--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver Operating Characteristic (ROC)')
plt.legend(loc='lower right')
plt.show()
# 绘制混淆矩阵
conf_matrix = confusion_matrix(y_test, y_pred)
print('Confusion Matrix:')
print(conf_matrix)
输出结果
(100, 74)
Accuracy: 0.7857142857142858
Precision: 0.7811951447245564
Recall: 0.8142857142857143
F1-Score: 0.7891089305577627
ROC-AUC: 0.835204081632653
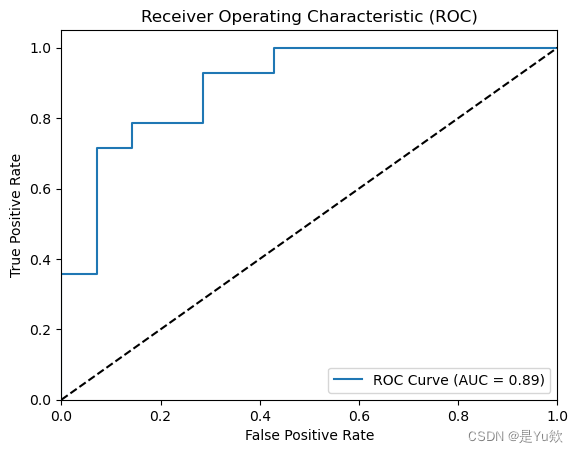
Confusion Matrix:
[[10 4]
[ 3 11]]
网格调参代码
## 网格搜索调参
from sklearn.model_selection import GridSearchCV
# 初始化随机森林分类器
classifier = RandomForestClassifier(random_state=42)
# 网格搜索参数
param_grid = {
'n_estimators': [50, 100, 200],
'max_depth': [None, 10, 20, 30],
'min_samples_split': [2, 5, 10],
'min_samples_leaf': [1, 2, 4]
}
# 创建网格搜索对象
# y_resampled = y_resampled[:100]
grid_search = GridSearchCV(classifier, param_grid, scoring='roc_auc', cv=cv, n_jobs=-1)
grid_search.fit(X_train, y_train)
# 打印最佳参数
print("Best Parameters: ", grid_search.best_params_)
# 使用最佳参数的分类器进行训练和预测
best_classifier = grid_search.best_estimator_
best_classifier.fit(X_train, y_train)
y_pred = best_classifier.predict(X_test)
# 计算性能指标
accuracy = accuracy_score(y_test, y_pred)
precision = precision_score(y_test, y_pred)
recall = recall_score(y_test, y_pred)
f1 = f1_score(y_test, y_pred)
roc_auc = roc_auc_score(y_test, best_classifier.predict_proba(X_test)[:, 1])
# 打印性能指标
print(f'Accuracy: {accuracy}')
print(f'Precision: {precision}')
print(f'Recall: {recall}')
print(f'F1-Score: {f1}')
print(f'ROC-AUC: {roc_auc}')
# 绘制ROC曲线
fpr, tpr, thresholds = roc_curve(y_test, best_classifier.predict_proba(X_test)[:, 1])
plt.figure()
plt.plot(fpr, tpr, label=f'ROC Curve (AUC = {roc_auc:.2f})')
plt.plot([0, 1], [0, 1], 'k--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver Operating Characteristic (ROC)')
plt.legend(loc='lower right')
plt.show()
# 绘制混淆矩阵
conf_matrix = confusion_matrix(y_test, y_pred)
print('Confusion Matrix:')
print(conf_matrix)
输出结果
Best Parameters: {‘max_depth’: 10, ‘min_samples_leaf’: 1, ‘min_samples_split’: 5, ‘n_estimators’: 200}
Accuracy: 0.8928571428571429
Precision: 0.8666666666666667
Recall: 0.9285714285714286
F1-Score: 0.896551724137931
ROC-AUC: 0.9081632653061225
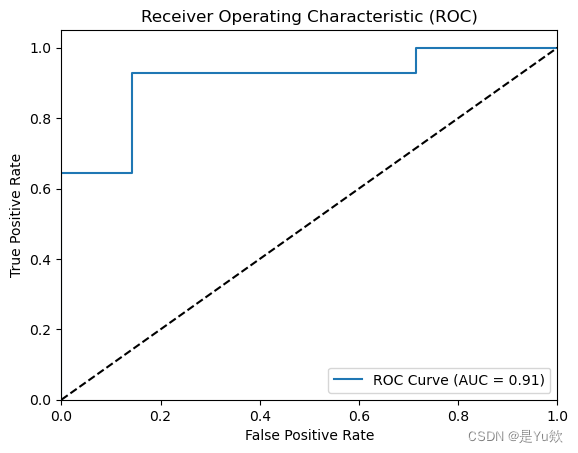
Confusion Matrix:
[[12 2]
[ 1 13]]







![[Linux] DHCP网络](https://img-blog.csdnimg.cn/73d05537fc194b188963ec926ada891a.png)