一.数据预处理作用
数据预处理会将选定的数据转换为我们可以使用的形式或可以提供给ML算法的形式,以使其符合机器学习算法的期望。
二.数据处理的常用方法
1.规范化
数据规范化是使属性数据按比例缩放,这样就将原来的数值映射到一个新的特定区域中,包括归一化,标准化等。
1.1.归一化
1.1.1:概念
把数据变成(0,1)或者(1,1)之间的小数。主要是为了数据处理方便提出来的,把数据映射到0~1范围之内处理,更加便捷快速。把有量纲表达式变成无量纲表达式,便于不同单位或量级的指标能够进行比较和加权。归一化是一种简化计算的方式,即将有量纲的表达式,经过变换,化为无量纲的表达式,成为纯量。
1.1.2:MinMaxScaler 归一
将数据缩放到指定的范围内。它通过对数据进行线性变换,将数据映射到指定的最小值和最大值之间。
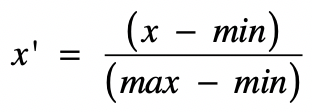
- 代码:
path=r"D:\DevelopWorkSpace\vsCodeWorkSpaces\python\pythonDemo\数据集\kindey stone urine analysis.csv"
names =["比重","氢离子的负对数","渗透压","电导率","尿素浓度","钙浓度","结果"]
data=read_csv(path,names=names)
print(data)
#-------数据截取--------------------
# data1=data.iloc[:,0:6]
# print("data1-------------------------------")
# print(data1)
#gravity,ph,osmo,cond,urea,calc,target
data2=data.loc[:,["比重","氢离子的负对数","渗透压","电导率","尿素浓度","钙浓度","结果"]]
print("data2-------------------------------")
print(data2[0:10])
array = data2.values
#"比重","氢离子的负对数","氢离子的负对数","电导率","尿素浓度","钙浓度"
#-------数据归一化
#通过对原始数据进行变换把数据映射到(默认为[0,1])之间
data_scaler = preprocessing.MinMaxScaler(feature_range=(0,1))
data_rescaled = data_scaler.fit_transform(array)
set_printoptions(precision=1)
print ("数据归一化:\n", data_rescaled[0:10])- 数据集(10行):
data2-------------------------------
比重 氢离子的负对数 渗透压 电导率 尿素浓度 钙浓度 结果
0 1.021 4.91 725 14.0 443 2.45 0
1 1.017 5.74 577 20.0 296 4.49 0
2 1.008 7.20 321 14.9 101 2.36 0
3 1.011 5.51 408 12.6 224 2.15 0
4 1.005 6.52 187 7.5 91 1.16 0
5 1.020 5.27 668 25.3 252 3.34 0
6 1.012 5.62 461 17.4 195 1.40 0
7 1.029 5.67 1107 35.9 550 8.48 0
8 1.015 5.41 543 21.9 170 1.16 0
9 1.021 6.13 779 25.7 382 2.21 0- 结果:
数据归一化:
[[0.5 0. 0.5 0.3 0.7 0.2 0. ]
[0.3 0.3 0.4 0.5 0.5 0.3 0. ]
[0.1 0.8 0.1 0.3 0.1 0.2 0. ]
[0.2 0.2 0.2 0.2 0.4 0.1 0. ]
[0. 0.6 0. 0.1 0.1 0.1 0. ]
[0.4 0.2 0.5 0.6 0.4 0.2 0. ]
[0.2 0.3 0.3 0.4 0.3 0.1 0. ]
[0.7 0.3 0.9 0.9 0.9 0.6 0. ]
[0.3 0.2 0.3 0.5 0.3 0.1 0. ]
[0.5 0.4 0.6 0.6 0.6 0.1 0. ]]1.1.3 :L1、L2范数归一化
- 描述:
L1范数:每个向量绝对值和
L2范数:每个向量平方和开根

L1范数归一:向量值/每个向量绝对值和
L2范数归一:向量值/每个向量平方和开根
- 代码:
#---L1归一
Data_normalizer_l1 = preprocessing.Normalizer(norm='l1').fit(array)
Data_normalized_l1 = Data_normalizer_l1.transform(array)
set_printoptions(precision=2)
print ("L1归一", Data_normalized_l1 [0:3])
#---L2归一
Data_normalizer_l2 = preprocessing.Normalizer(norm='l2').fit(array)
Data_normalized_l2 = Data_normalizer_l2.transform(array)
set_printoptions(precision=3)
print ("L2归一", Data_normalized_l2 [0:3])- 数据集:
data2-------------------------------
比重 氢离子的负对数 渗透压 电导率 尿素浓度 钙浓度 结果
0 1.021 4.91 725 14.0 443 2.45 0
1 1.017 5.74 577 20.0 296 4.49 0
2 1.008 7.20 321 14.9 101 2.36 0
3 1.011 5.51 408 12.6 224 2.15 0
4 1.005 6.52 187 7.5 91 1.16 0
5 1.020 5.27 668 25.3 252 3.34 0
6 1.012 5.62 461 17.4 195 1.40 0
7 1.029 5.67 1107 35.9 550 8.48 0
8 1.015 5.41 543 21.9 170 1.16 0
9 1.021 6.13 779 25.7 382 2.21 0- L1结果:(每行绝对值相加=1)
[[8.58e-04 4.12e-03 6.09e-01 1.18e-02 3.72e-01 2.06e-03 0.00e+00]
[1.12e-03 6.35e-03 6.38e-01 2.21e-02 3.27e-01 4.97e-03 0.00e+00]
[2.25e-03 1.61e-02 7.17e-01 3.33e-02 2.26e-01 5.27e-03 0.00e+00]
[1.55e-03 8.43e-03 6.25e-01 1.93e-02 3.43e-01 3.29e-03 0.00e+00]
[3.42e-03 2.22e-02 6.36e-01 2.55e-02 3.09e-01 3.94e-03 0.00e+00]
[1.07e-03 5.52e-03 7.00e-01 2.65e-02 2.64e-01 3.50e-03 0.00e+00]
[1.49e-03 8.25e-03 6.77e-01 2.55e-02 2.86e-01 2.05e-03 0.00e+00]
[6.02e-04 3.32e-03 6.48e-01 2.10e-02 3.22e-01 4.96e-03 0.00e+00]
[1.37e-03 7.29e-03 7.31e-01 2.95e-02 2.29e-01 1.56e-03 0.00e+00]
[8.54e-04 5.13e-03 6.51e-01 2.15e-02 3.19e-01 1.85e-03 0.00e+00]]- L2结果:(每行平方和相加=1)
L2归一
[[1.202e-03 5.778e-03 8.532e-01 1.648e-02 5.213e-01 2.883e-03 0.000e+00]
[1.567e-03 8.846e-03 8.893e-01 3.082e-02 4.562e-01 6.920e-03 0.000e+00]
[2.992e-03 2.137e-02 9.527e-01 4.422e-02 2.998e-01 7.004e-03 0.000e+00]
[2.171e-03 1.183e-02 8.762e-01 2.706e-02 4.810e-01 4.617e-03 0.000e+00]
[4.827e-03 3.131e-02 8.981e-01 3.602e-02 4.371e-01 5.571e-03 0.000e+00]
[1.428e-03 7.377e-03 9.350e-01 3.541e-02 3.527e-01 4.675e-03 0.000e+00]
[2.020e-03 1.122e-02 9.204e-01 3.474e-02 3.893e-01 2.795e-03 0.000e+00]
[8.321e-04 4.585e-03 8.951e-01 2.903e-02 4.447e-01 6.857e-03 0.000e+00]
[1.782e-03 9.501e-03 9.536e-01 3.846e-02 2.985e-01 2.037e-03 0.000e+00]
[1.176e-03 7.062e-03 8.974e-01 2.961e-02 4.401e-01 2.546e-03 0.000e+00]]1.2.标准化
sklearn 库的 preprocessing的StandardScaler(z-score 标准化)
1.2.1.概念:
标准化需要计算特征的均值和标准差,公式表达为:
![]()
标准化的前提是特征值服从正态分布,标准化后,其转换成标准正态分布。区间缩放法利用了边界值信息,将特征的取值区间缩放到某个特点的范围,例如[0, 1]等。
1.2.2.示例:
#标准化
data_scaler = preprocessing.StandardScaler().fit(array)
data_rescaled = data_scaler.transform(array)
set_printoptions(precision=2)
print ("标准化:\n", data_rescaled [0:10])1.2.3.结果:
标准化:
[[ 0.4 -1.55 0.48 -0.86 1.35 -0.52 -0.87]
[-0.15 -0.4 -0.15 -0.1 0.23 0.11 -0.87]
[-1.41 1.63 -1.24 -0.75 -1.27 -0.55 -0.87]
[-0.99 -0.72 -0.87 -1.04 -0.33 -0.61 -0.87]
[-1.82 0.68 -1.8 -1.69 -1.34 -0.92 -0.87]
[ 0.26 -1.05 0.23 0.57 -0.11 -0.25 -0.87]
[-0.85 -0.57 -0.64 -0.43 -0.55 -0.85 -0.87]
[ 1.51 -0.5 2.09 1.91 2.17 1.34 -0.87]
[-0.43 -0.86 -0.3 0.14 -0.74 -0.92 -0.87]
[ 0.4 0.14 0.7 0.62 0.89 -0.6 -0.87]]2. 2值化
2.1.概念:
使数据二进制化。我们可以使用二进制阈值来使数据二进制。高于该阈值的值将转换为1,低于该阈值的值将转换为0。
例如,如果我们选择阈值= 0.5,则其上方的数据集值将变为1,而低于此值的数据集值将变为0。这就是为什么我们可以将其称为 二进制化数据或 阈值数据。当我们在数据集中有几率并希望将其转换为清晰的值时,此技术很有用。
2.2.示例:
#2值化
binarizer = preprocessing.Binarizer(threshold=50).fit(array)
Data_binarized = binarizer.transform(array)
print ("2值化:\n", Data_binarized [0:10])2.3.结果:
2值化:
[[0. 0. 1. 0. 1. 0. 0.]
[0. 0. 1. 0. 1. 0. 0.]
[0. 0. 1. 0. 1. 0. 0.]
[0. 0. 1. 0. 1. 0. 0.]
[0. 0. 1. 0. 1. 0. 0.]
[0. 0. 1. 0. 1. 0. 0.]
[0. 0. 1. 0. 1. 0. 0.]
[0. 0. 1. 0. 1. 0. 0.]
[0. 0. 1. 0. 1. 0. 0.]
[0. 0. 1. 0. 1. 0. 0.]]
3.标签编码:
PS1:大多数sklearn函数都希望带有数字标签而不是单词标签的数据。因此,我们需要将此类标签转换为数字标签。此过程称为标签编码。
PS2:因为回归和机器学习都是基于数学函数方法的,所以当我们要分析的数据集中出现了类别数据(categorical data),此时的数据是不理想的,因为我们不能用数学的方法处理它们。例如,在处理男和女两个性别数据时,我们用0和1将其代替,再进行分析。由于这种情况的出现,我们需要可以将文字数字化的现成方法。
3.1.LabelEncoder :
3.1.1.概念:
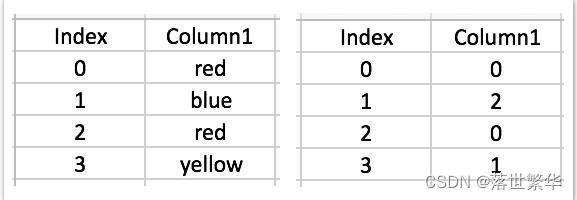
- LabelEncoder 将一列文本数据转化成数值。
- 例如,[red, blue, red, yellow] = [0,2,0,1]
3.1.2.示例:
#标签编码
input_labels = ['猫','狗','猫','兔子','老虎','鸭子','大鹅']
encoder = preprocessing.LabelEncoder()
labelsList=encoder.fit_transform(input_labels)
print("标签:\n",input_labels)
print("编码后:\n",labelsList)
test_labels=['猫','兔子','老虎']
testLabelList=encoder.transform(test_labels)
print("测试数据:\n",test_labels)
print("验证编码:\n",testLabelList)
test_labels2=[0,3,5]
testLabelList2=encoder.inverse_transform(test_labels2)
print("测试数据:\n",test_labels2)
print("验证解码:\n",testLabelList2)3.1.3.结果:
标签:
['猫', '狗', '猫', '兔子', '老虎', '鸭子', '大鹅']
编码后:
[3 2 3 0 4 5 1]
测试数据:
['猫', '兔子', '老虎']
验证编码:
[3 0 4]
测试数据:
[0, 3, 5]
验证解码:
['兔子' '猫' '鸭子']3.2.OneHotEncoder:
3.2.1.概念:
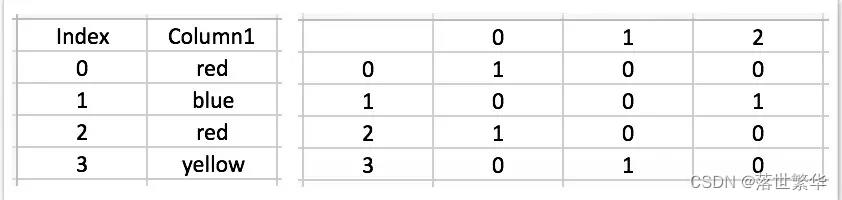
- OneHotEncoder 将一列文本数据转化成一列或多列只有0和1的数据。
- 例如,[red, blue, red, yellow] = [1,2,1,3] 会被转化成3列用0和1表示的数据列
- 相对于转换成0、1、2、3 ,数值本身也有大小,所以在标签值大小影响后续计算时,OneHotEncoder有优势
3.2.2.示例:
- #OneHotEncoder-----sklearn
#OneHotEncoder
input_labels = ['猫','狗','猫','兔子','老虎','鸭子','大鹅']
#input_labels = ['red','green','blue','black']
encoder2 = preprocessing.OneHotEncoder()
import numpy as np
arr=(np.array(input_labels)).reshape(-1, 1)
# PS:不能直接编码数组 需要转换
# OneHotLabel=encoder2.fit_transform(input_labels)
# 报错:
# Reshape your data either using array.reshape(-1, 1)
# if your data has a single feature or array.reshape(1, -1) if it contains a single sample.
print(arr)
OneHotLabel=encoder2.fit_transform(arr).toarray()
print(OneHotLabel)-
#OneHotEncoder-----pandas
#OneHotEncoder-----pandas
import pandas as pd
# 创建一个包含标签的数据集
input_labels = ['猫','狗','猫','兔子','老虎','鸭子','大鹅']
# 对 'color' 列进行独热编码
one_hot_encoded = pd.get_dummies(input_labels)
print(one_hot_encoded)3.2.3.结果:
- #OneHotEncoder-----sklearn
原数组:
['猫', '狗', '猫', '兔子', '老虎', '鸭子', '大鹅']
转换后数组:
[['猫']
['狗']
['猫']
['兔子']
['老虎']
['鸭子']
['大鹅']]
编码后:
[[0. 0. 0. 1. 0. 0.]
[0. 0. 1. 0. 0. 0.]
[0. 0. 0. 1. 0. 0.]
[1. 0. 0. 0. 0. 0.]
[0. 0. 0. 0. 1. 0.]
[0. 0. 0. 0. 0. 1.]
[0. 1. 0. 0. 0. 0.]]- #OneHotEncoder-----pandas
兔子 大鹅 狗 猫 老虎 鸭子
0 0 0 0 1 0 0
1 0 0 1 0 0 0
2 0 0 0 1 0 0
3 1 0 0 0 0 0
4 0 0 0 0 1 0
5 0 0 0 0 0 1
6 0 1 0 0 0 03.3:OrdinalEncoder
3.3.1:概念:
将分类特征转化为整数数组,它的输入应该是整数或字符串的类数组,也可以理解为矩阵,每一列表示一个特征,每一个特征中的数字或者是字符串表示一类特征,也就是分类(离散)特征所接受的值。特征按顺序转换为有序整数。结果就是每个特征对应一个整数列,取值范围0到n_categories -1。
3.3.2:示例:
#OrdinalEncoder-----sklearn
input_arrays = [['猫',2],['狗',8],['猫',7],['兔子',6],['老虎',5],['鸭子',4],['大鹅',3]]
encoder3 = preprocessing.OrdinalEncoder()
print("原数组:\n",input_arrays)
OrdinalArr=encoder3.fit_transform(input_arrays)
print("编码后:\n",OrdinalArr)
testArr =[[2,4]]
print("测试数组:\n",testArr)
print("解码后:\n",encoder3.inverse_transform(testArr))3.3.3:结果:
原数组:
[['猫', 2], ['狗', 8], ['猫', 7], ['兔子', 6], ['老虎', 5], ['鸭子', 4], ['大鹅', 3]]
编码后:
[[3. 0.]
[2. 6.]
[3. 5.]
[0. 4.]
[4. 3.]
[5. 2.]
[1. 1.]]
测试数组:
[[2, 4]]
解码后:
[['狗' 6]]3.4.LabelEncoder和OrdinalEncoder区别
LabelEncoder和OrdinalEncoder类似,都可以将分类型变量转化成数值型索引变量,区别在于OrdinaEncoder可以直接处理shape为[m,n]的数组或类数组对象,而LabelEncoder只能处理[m,]的一维对象。
既:
LabelEncoder用来编码结果Target为字符标签情况
OrdinalEncoder用来编码矩阵特征为字符串,非数字的情况
三.参考
PS:关于标准化 归一化概念混乱的看这篇,都是因为中英文翻译导致的概念混乱。
http://t.csdnimg.cn/BizzI
LabelEncoder 和OneHotEncoder概念来源:
数据预处理之将类别数据数字化的方法 —— LabelEncoder VS OneHotEncoder - 知乎