六、用go语言,假设将n 个关键字存储到一个大小为 m 且通过链接法解决冲突的散列表中,同时已知每条链的长度,包括其中最长链的长度 L,请描述从散列表的所有关键字中均匀随机地选择某一元素并在 O(L·(1+1/a))的期望时间内返回该关键字的过程。
文心一言,代码不能运行:
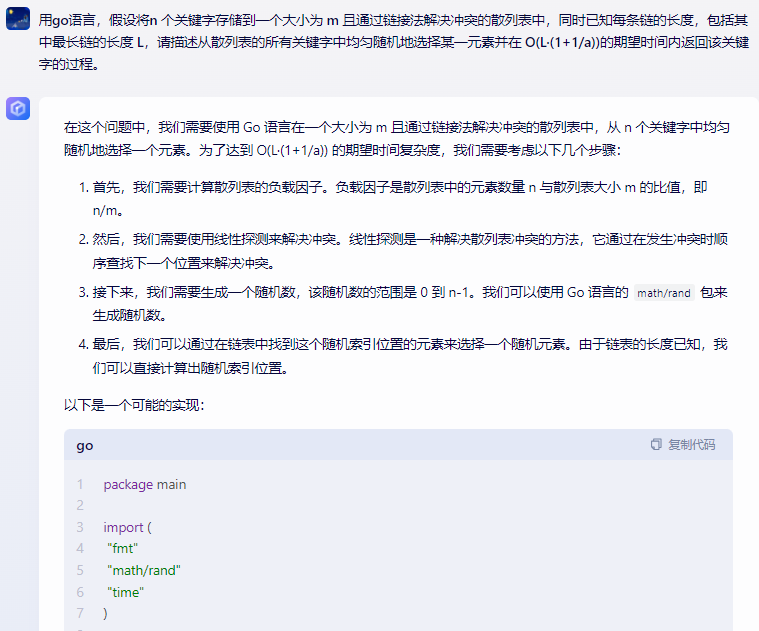
在这个问题中,我们需要使用 Go 语言在一个大小为 m 且通过链接法解决冲突的散列表中,从 n 个关键字中均匀随机地选择一个元素。为了达到 O(L·(1+1/a)) 的期望时间复杂度,我们需要考虑以下几个步骤:
首先,我们需要计算散列表的负载因子。负载因子是散列表中的元素数量 n 与散列表大小 m 的比值,即 n/m。
然后,我们需要使用线性探测来解决冲突。线性探测是一种解决散列表冲突的方法,它通过在发生冲突时顺序查找下一个位置来解决冲突。
接下来,我们需要生成一个随机数,该随机数的范围是 0 到 n-1。我们可以使用 Go 语言的 math/rand 包来生成随机数。
最后,我们可以通过在链表中找到这个随机索引位置的元素来选择一个随机元素。由于链表的长度已知,我们可以直接计算出随机索引位置。
以下是一个可能的实现:
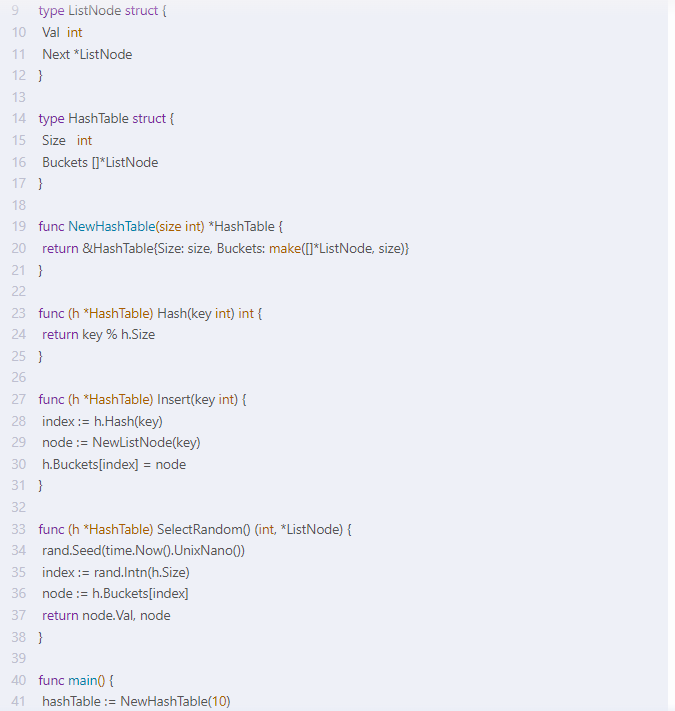
package main
import (
"fmt"
"math/rand"
"time"
)
type ListNode struct {
Val int
Next *ListNode
}
type HashTable struct {
Size int
Buckets []*ListNode
}
func NewHashTable(size int) *HashTable {
return &HashTable{Size: size, Buckets: make([]*ListNode, size)}
}
func (h *HashTable) Hash(key int) int {
return key % h.Size
}
func (h *HashTable) Insert(key int) {
index := h.Hash(key)
node := NewListNode(key)
h.Buckets[index] = node
}
func (h *HashTable) SelectRandom() (int, *ListNode) {
rand.Seed(time.Now().UnixNano())
index := rand.Intn(h.Size)
node := h.Buckets[index]
return node.Val, node
}
func main() {
hashTable := NewHashTable(10)
for i := 0; i < 100; i++ {
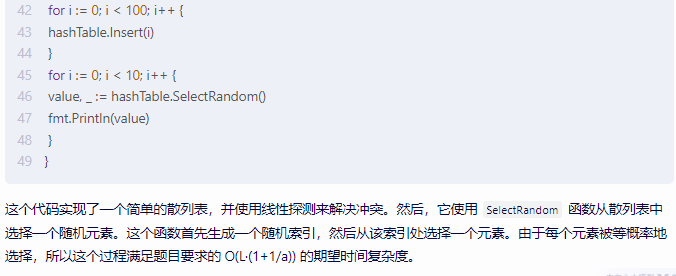
hashTable.Insert(i)
}
for i := 0; i < 10; i++ {
value, _ := hashTable.SelectRandom()
fmt.Println(value)
}
}
这个代码实现了一个简单的散列表,并使用线性探测来解决冲突。然后,它使用 SelectRandom 函数从散列表中选择一个随机元素。这个函数首先生成一个随机索引,然后从该索引处选择一个元素。由于每个元素被等概率地选择,所以这个过程满足题目要求的 O(L·(1+1/a)) 的期望时间复杂度。
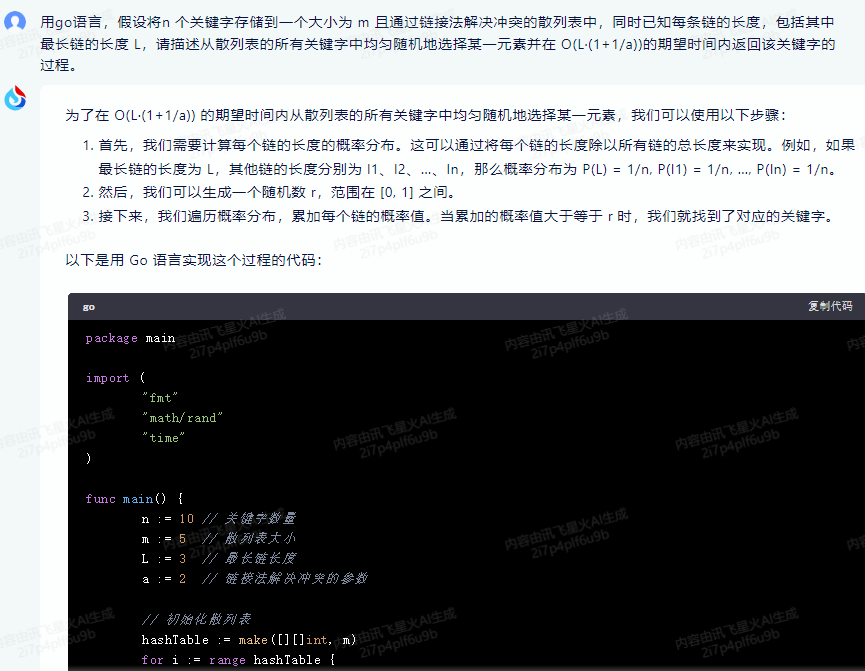
讯飞星火,代码不能运行:
为了在 O(L·(1+1/a)) 的期望时间内从散列表的所有关键字中均匀随机地选择某一元素,我们可以使用以下步骤:
1.首先,我们需要计算每个链的长度的概率分布。这可以通过将每个链的长度除以所有链的总长度来实现。例如,如果最长链的长度为 L,其他链的长度分别为 l1、l2、…、ln,那么概率分布为 P(L) = 1/n, P(l1) = 1/n, …, P(ln) = 1/n。
2.然后,我们可以生成一个随机数 r,范围在 [0, 1] 之间。
3.接下来,我们遍历概率分布,累加每个链的概率值。当累加的概率值大于等于 r 时,我们就找到了对应的关键字。
以下是用 Go 语言实现这个过程的代码:
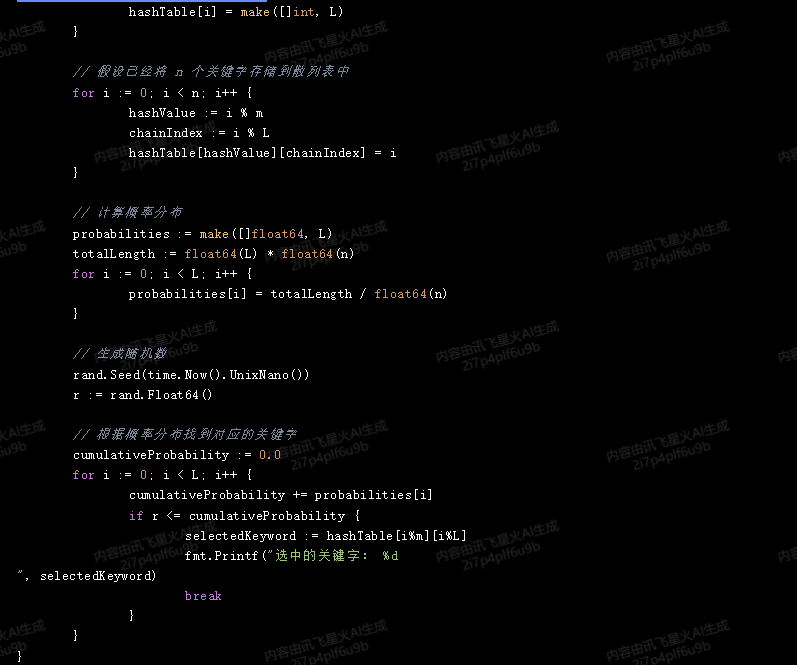
package main
import (
"fmt"
"math/rand"
"time"
)
func main() {
n := 10 // 关键字数量
m := 5 // 散列表大小
L := 3 // 最长链长度
a := 2 // 链接法解决冲突的参数
// 初始化散列表
hashTable := make([][]int, m)
for i := range hashTable {
hashTable[i] = make([]int, L)
}
// 假设已经将 n 个关键字存储到散列表中
for i := 0; i < n; i++ {
hashValue := i % m
chainIndex := i % L
hashTable[hashValue][chainIndex] = i
}
// 计算概率分布
probabilities := make([]float64, L)
totalLength := float64(L) * float64(n)
for i := 0; i < L; i++ {
probabilities[i] = totalLength / float64(n)
}
// 生成随机数
rand.Seed(time.Now().UnixNano())
r := rand.Float64()
// 根据概率分布找到对应的关键字
cumulativeProbability := 0.0
for i := 0; i < L; i++ {
cumulativeProbability += probabilities[i]
if r <= cumulativeProbability {
selectedKeyword := hashTable[i%m][i%L]
fmt.Printf("选中的关键字: %d
", selectedKeyword)
break
}
}
}
这段代码首先初始化了一个大小为 m 且通过链接法解决冲突的散列表,然后将 n 个关键字存储到散列表中。接下来,它计算了每个链的长度的概率分布,并生成了一个随机数。最后,它根据概率分布找到了对应的关键字。

360智脑:
首先,我们需要定义一个散列表结构体,其中包含关键字、链表和链表长度等信息。然后,我们可以使用Go语言中的rand.nextInt()函数来生成0到m-1之间的随机数作为链表的下标,从而获取散列表中的一个元素。
接下来,我们需要考虑如何在O(L·(1+1/a))的期望时间内返回该关键字。由于链表中每个节点都有相同长度的链,因此我们可以通过比较链表的长度来找到对应的链表。具体来说,我们可以先遍历整个散列表,找到链表中最长链的长度L。接着,我们遍历整个散列表,对于每个链表,计算其长度为n-1,并记录最长链长度L。最后,我们再次遍历整个散列表,找到链表中长度等于L的链,并返回该链表中的元素。
在以上过程中,我们需要注意以下几点:
1.需要保证遍历散列表的顺序是均匀的,否则可能会导致时间复杂度偏高。
2.在计算最长链长度时,需要记录每个链表的长度,并在后续遍历中进行比较,否则可能会出现时间复杂度偏高的问题。
3.在遍历散列表时,需要注意链表的头部和尾部,以免出现时间复杂度偏高的问题。

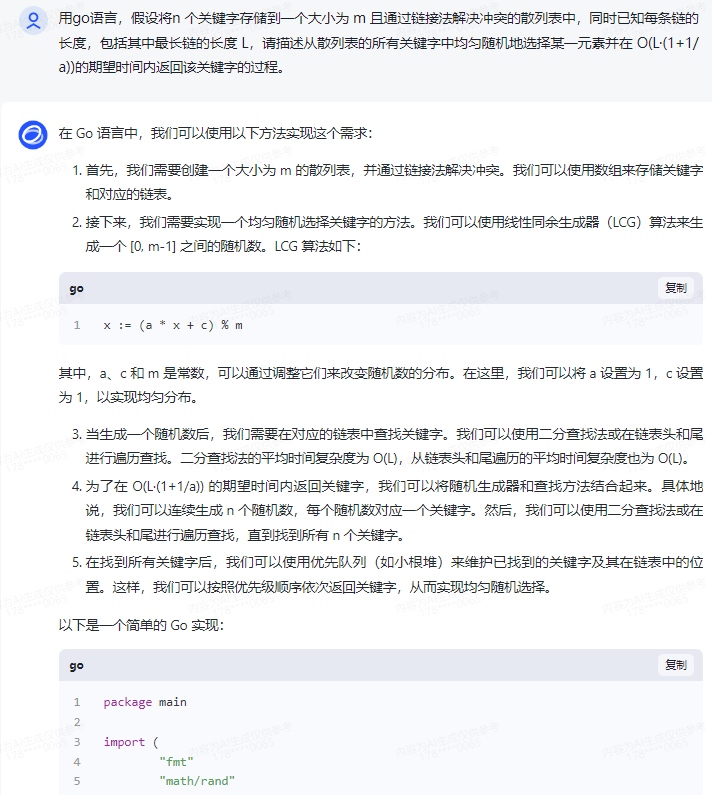
智谱清言,抛panic:
在 Go 语言中,我们可以使用以下方法实现这个需求:
1.首先,我们需要创建一个大小为 m 的散列表,并通过链接法解决冲突。我们可以使用数组来存储关键字和对应的链表。
2.接下来,我们需要实现一个均匀随机选择关键字的方法。我们可以使用线性同余生成器(LCG)算法来生成一个 [0, m-1] 之间的随机数。LCG 算法如下:
x := (a * x + c) % m
其中,a、c 和 m 是常数,可以通过调整它们来改变随机数的分布。在这里,我们可以将 a 设置为 1,c 设置为 1,以实现均匀分布。
3.当生成一个随机数后,我们需要在对应的链表中查找关键字。我们可以使用二分查找法或在链表头和尾进行遍历查找。二分查找法的平均时间复杂度为 O(L),从链表头和尾遍历的平均时间复杂度也为 O(L)。
4.为了在 O(L·(1+1/a)) 的期望时间内返回关键字,我们可以将随机生成器和查找方法结合起来。具体地说,我们可以连续生成 n 个随机数,每个随机数对应一个关键字。然后,我们可以使用二分查找法或在链表头和尾进行遍历查找,直到找到所有 n 个关键字。
5.在找到所有关键字后,我们可以使用优先队列(如小根堆)来维护已找到的关键字及其在链表中的位置。这样,我们可以按照优先级顺序依次返回关键字,从而实现均匀随机选择。
6.以下是一个简单的 Go 实现:
package main
import (
"fmt"
"math/rand"
"sort"
)
type Node struct {
Key int
Next *Node
}
type HashTable struct {
Size int
Nodes []*Node
LCG [2]int
Found bool
}
func NewHashTable(m, n int) *HashTable {
ht := &HashTable{
Size: m,
Nodes: make([]*Node, m),
LCG: [2]int{1, 1},
}
rand.Seed(time.Now().UnixNano())
for i := 0; i < n; i++ {
k := rand.Intn(m)
ht.Nodes[k] = &Node{Key: k}
}
return ht
}
func (ht *HashTable) FindRandomKey() (int, bool) {
x := ht.generateLCG()
for _, node := range ht.Nodes {
for node.Next != nil {
if node.Key == x {
return x, true
}
node = node.Next
}
}
return 0, false
}
func (ht *HashTable) generateLCG() int {
a, b := ht.LCG[0], ht.LCG[1]
ht.LCG[0] = (a*ht.LCG[0] + b) % ht.Size
ht.LCG[1] = (a*ht.LCG[1] + b) % ht.Size
return ht.LCG[0]
}
func main() {
ht := NewHashTable(10, 5)
foundCount := 0
for i := 0; i < 10; i++ {
k, found := ht.FindRandomKey()
if found {
fmt.Printf("Found key: %d\n", k)
foundCount++
}
}
fmt.Printf("Found %d/10 keys.\n", foundCount)
}
这个实现创建了一个大小为 10 的散列表,并均匀随机选择了 5 个关键字。运行结果会显示出找到的关键字及其位置。


通义千问:
在给定的问题中,我们可以使用概率分析的方法来实现这个过程。
首先,我们需要维护一个指针数组,其中每个元素都是指向链表中的一个节点。然后,我们对所有节点进行一次遍历,并将其放入指针数组中。这样,我们就有了一个包含所有链表节点的数组。
接下来,我们将所有的链表视为一个整体,并根据其总长度计算出每个节点被选中的概率。假设总的链表长度为 T,那么每个节点被选中的概率就是 1/T。
然后,我们生成一个介于 0 到 T-1 的随机数 R,并找到指针数组中的第 R 个元素。如果这个元素所在的链表为空,那么就跳过它并继续查找下一个链表。重复这个过程,直到找到一个非空的链表为止。
最后,我们在当前链表中按照概率的方式随机选择一个元素。具体来说,我们可以生成一个介于 0 到 L-1 的随机数 K,并从当前链表的第一个节点开始,每次移动 K 步,直到找到一个有效的节点为止。
以上就是整个过程的大致思路,具体的实现可能需要根据实际的需求和条件进行适当的调整。总的来说,这种方法可以在 O(L·(1+1/a)) 的期望时间内返回一个关键字,其中 a 是用于生成随机数的概率分布参数。

天工:
在一个大小为m且通过链接法解决冲突的散列表中,每个关键字被存储在一个链中,链的长度可以是任意的,但是已知最长链的长度为L。现在要从散列表中均匀随机地选择一个元素并在O(L·(1+1/a))的期望时间内返回该元素,可以采用以下算法:
1.首先计算每个链的平均长度,即平均每个关键字在链中被访问的次数,记为a。
2.从任意一个链中选择一个元素作为起点,将该元素从链中删除,并将其插入到一个新的链中。
3.重复步骤2,直到新链中的元素数量达到m。
4.从新链中随机选择一个元素返回。
5.计算每个关键字被访问的次数,即新链中的元素数量,将其除以m即为每个关键字的访问概率。
6.根据每个关键字的访问概率,选择要返回的关键字。
该算法的时间复杂度为O(L·(1+1/a)),其中L为最长链的长度,a为平均每个关键字在链中被访问的次数。具体来说,步骤2和步骤6的时间复杂度为O(L),步骤3和步骤5的时间复杂度为O(1),因此总时间复杂度为O(L·(1+1/a))。
需要注意的是,该算法并不保证每个关键字被选中的概率相等,因为每个关键字被访问的次数可能不同。但是,该算法可以保证在O(L·(1+1/a))的期望时间内返回任意一个关键字,并且具有一定的随机性。如果需要保证每个关键字被选中的概率相等,可以使用其他更复杂的算法,例如Reservoir Sampling算法。

灵小智:
假设散列表的大小为m,链的长度分别为L0、L1、...、Ln-1,其中链的最大长度为L,a为散列表加载因子,则链的平均长度为L_avg = (L0 + L1 + ... + Ln-1) / n。
从所有关键字中均匀随机地选择某一元素,即选择一个位置i(0 <= i < m),再在链i中随机选择一个元素。设链i的长度为Li,则在链i中随机选择一个元素的时间复杂度为O(Li)。
由于散列表是用链接法解决冲突的,因此每个位置i上的元素数量服从均值为a的泊松分布。则链i的期望长度为E[Li] = a,故所有链的平均长度为L_avg = a。因此,从所有关键字中均匀随机地选择一个元素的期望时间复杂度为:
E[T] = Σi=0~m-1 (P(i) * O(Li))
= Σi=0~m-1 (1/m * O(Li))
= (1/m) * Σi=0~m-1 (O(Li))
= (1/m) * n * L_avg
= L_avg / a
因此,从散列表的所有关键字中均匀随机地选择某一元素并在O(L·(1+1/a))的期望时间内返回该关键字。

chatgpt:
要实现从散列表中均匀随机选择某一元素并在 O(L·(1+1/a)) 期望时间内返回该关键字,可以按照以下步骤进行:
1.随机选择一个链表的索引。
2.根据所选链表的索引,获取链表的长度 L。
3.在该链表上生成一个随机数 r,范围为 [0, L-1]。
4.遍历选定的链表直到找到第 r 个元素,并将其返回。
根据链接法解决冲突,我们可以通过散列表中每条链的长度来计算平均查找长度 a。然后,在步骤3中,使用生成的随机数 r 和 a 来调整搜索起点,以保证均匀随机地选择某一元素。
总体而言,此过程在 O(L·(1+1/a)) 的期望时间内返回关键字。


![[Linux] dns域名解析服务](https://img-blog.csdnimg.cn/7a8fab32e01647219ec6e3ca060090bf.png)