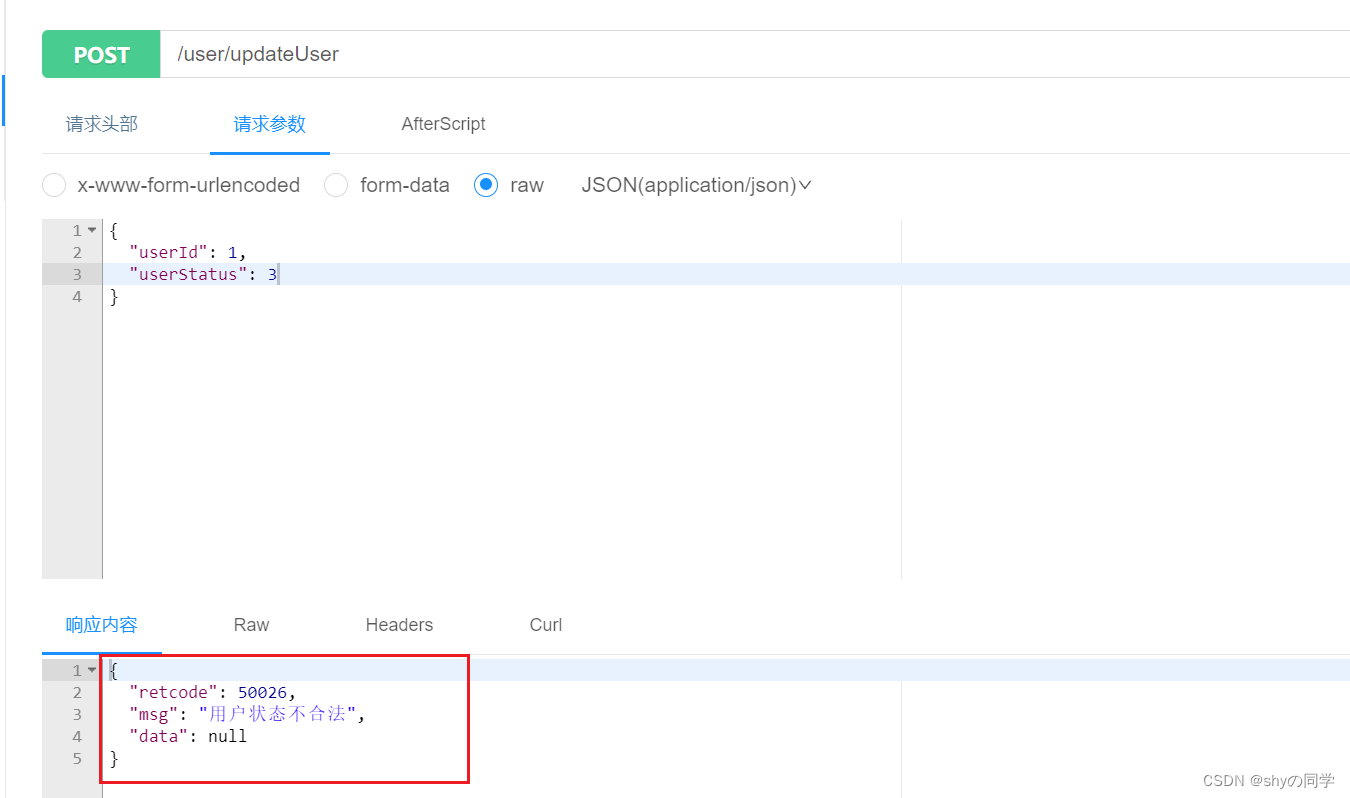
一、node下载版本报错:npm install --legacy-peer-deps
二、@Scheduled: 任务自动化调度
@Scheduled 标记要调度的方法的注解,必须指定 cron,fixedDelay或fixedRate属性之一
- fixedDelay:固定延迟
延迟执行任务,任务在上个任务完成后达到设置的延时时间就执行
@Scheduled(fixedDelay = 5000):任务会在上个任务完成后经过5s再执行
- fixedRate:定时执行
任务间隔规定时间即执行
@Scheduled(fixedRate = 5000):任务每隔5s执行一次
- cron:自定义规则
cron表达式:([秒] [分] [时] [日] [月] [周] [年])[年]为非必须,一般用6或7个标识符表示任务的执行规则
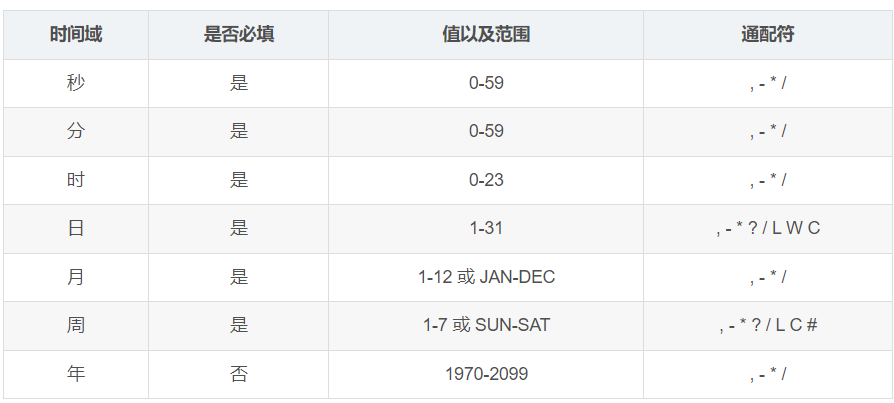
cron表达式:

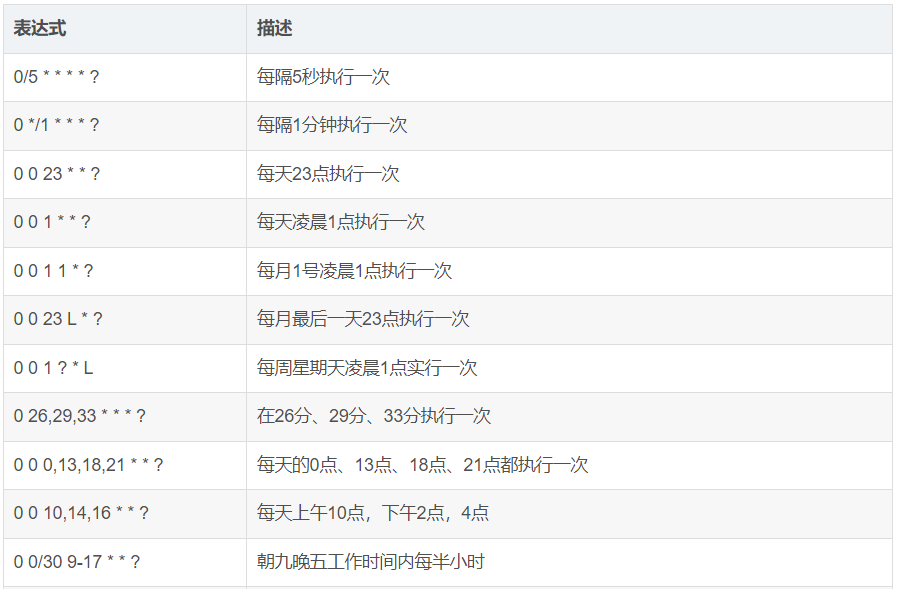
cron常用示例
三、Mixin
混入(mixin)提供了一种非常灵活的方式,来分发 Vue 组件中的可复用功能。一个混入对象可以包含任意组件选项(如data、methods、mounted等等)。当组件使用混入对象时,所有混入对象的选项将被“混合”进入该组件本身的选项
四、前后端数据传递
1.路径传参
①前端传参:http://localhost:8089/text/123
后端接参:
// /{}是必须写的,id是自定义的
// @PathVariable 这个注解也是必须写的,否则接不到参数
@GetMapping("/{id}")
//使用什么类型去接收id的值,要看你后端需要什么类型
public void t1(@PathVariable String id) {
log.info(id);
}
②前端传递多个参数:http://localhost:8089/text/123/456
后端接参:
// /{}是必须写的,id是自定义的
// @PathVariable 这个注解也是必须写的,否则接不到参数
@GetMapping("/{id}/{num}")
//使用什么类型去接收id的值,要看你后端需要什么类型
public void t1(@PathVariable String id,@PathVariable String num) {
log.info(id + num);
}
2.普通传参
前端传参:http://localhost:8080/text/test?id=123&name=admin
后端接参:
//首先要明确一点,前端访问的后端路径中 ?问号后边的都是参数
//@RequestParam 这个注解可以加,也可以不加
//当需要这个注解底层的一些功能时,需要加,否则,可以不加,不会出错
//value 这个可以改变前端传递参数的名字,"id" 他和前端的参数名一样即可,String id 这个id可以随便改名
//如果不加@RequestParam 前端传参时,name可以不传,不会报错
//但是加上@RequestParam 前端就必须传name的值,否则就i会出错
//required = false 加上他,就表示前端传参时,name可以不传,不会报错
@GetMapping("/testParam")
public void t2(@RequestParam(value = "id") String id,@RequestParam(required = false) String name) {
log.info(id + name);
}
3.post传参
①前端使用application/json,也就是json格式传参
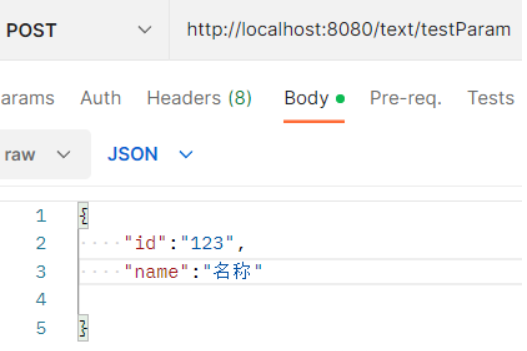
后端接收:
//如果前端是以json格式传递参数
//那么在接收请求的时候,需要加上@RequestBody注解,值才能成功传递到后端
//如果不加就是null对象,因为item也会被初始化
//item是一个封装的实体类,建议在接收post请求时根据前端传递的json内容封装成实体类接收
@PostMapping("/testParam")
public void t3(@RequestBody Item item) {
log.info(item.getId()+item.getName());
}
②前端使用form-data格式,也就是表单格式传参
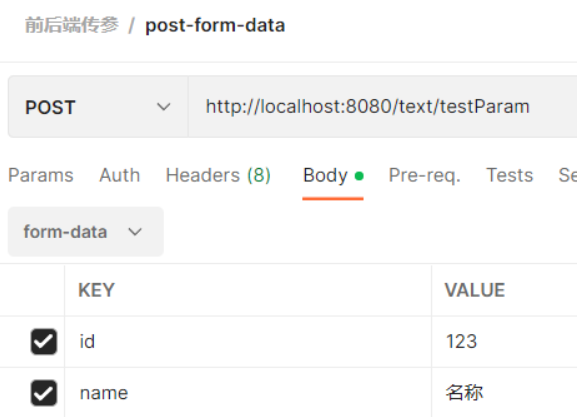
后端接收:
//如果前端使用form-data的格式传参,不可以写@RequestBody注解,否则会报错
//item是一个封装的实体类,建议在接收post请求时根据前端传递的json内容封装成实体类接收
@PostMapping("/testParam")
public void t4(Item item) {
log.info(item.getId()+item.getName());
}
4.集合&数组
前端传参:
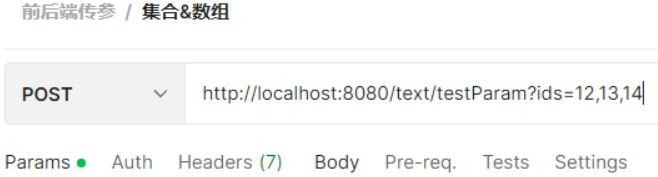
后端接收:
①使用list集合接收
//接收前端以逗号分隔的多个参数,使用集合必须加上@RequestParam
@PostMapping("/testParam")
public void t5(@RequestParam List<Long> ids) {
log.info("ids",ids);
}
②使用数组接收
//使用数组,加不加@RequestParam注解,都可以
@PostMapping("/testParam")
public void t6(Integer[] ids) {
log.info("ids",ids);
}
③使用可变参数接收
//使用可变参数,接收到的也是数组类型,也可以不加@RequestParam注解
@PostMapping("/testParam")
public void t6(Integer ...ids) {
log.info("ids",ids);
}
五、Content-type类型总结
content-type
- content-type是http请求的响应头和请求头的字段。当作为响应头时,告诉客户端实际返回的内容的内容类型。作为请求头时,客户端告诉服务器实际发送的数据类型。
- 前端开发过程中,需要跟后端工程师对接接口的数据格式,不同的数据类型对于服务器来说有不同的处理方式,因此我们需要关注不同的conten-type类型.
1.application/x-www-form-urlencoded
- 浏览器原生form表单默认的提交方式(在不设置enctype的情况下)。
- 提交的数据按照 k1=v1&k2=v2的方式进行编码,key和val都进行了URL转码.此时请求头的格式如下:
content-type: application/x-www-form-urlencoded;charset=utf-8
form-data: k1=v1&k2=v2
- 非字母或数字的字符会被进行编码
2.mutipart/form-data
- 与application/x-www-form-urlencoded 的区别是它支持文件的传输,并且它的传输数据放在request-payload里,并且以bounday进行分隔。
- 常见的 POST 数据提交的方式。我们使用表单上传文件时,必须让 form 的 enctype 等于这个值。
<form action="/" method="post" enctype="multipart/form-data">
<input type="text" name="name" value="some text">
<input type="file" name="fileName">
<button type="submit">Submit</button>
</form>
- 请求头
POST /foo HTTP/1.1
Content-Length: 68137
Content-Type: multipart/form-data;
boundary=---------------------------974767299852498929531610575
---------------------------974767299852498929531610575
Content-Disposition: form-data; name=“name” value=“some text”
---------------------------974767299852498929531610575
Content-Disposition: form-data; name=“fileName”; filename=“foo.txt”
Content-Type: text/plain
(content of the uploaded file foo.txt)
---------------------------974767299852498929531610575–
3.application/json
- 消息主体是序列化后的JSON字符串
POST http://www.example.com HTTP/1.1
Content-Type: application/json;charset=utf-8{“title”:“test”,“sub”:[“a”,“b”,“c”]}
- 它用来告诉服务端消息主体是序列化后的 JSON 字符串,其中一个好处就是JSON 格式支持比键值对复杂得多的结构化数据。
- 特别适合 RESTful 的接口。传递JSON字符串可以方便的让前端转为js的对象,进行显示和逻辑操作
4.text/plain
- 传统的Ajax请求提交
function submit2() {
var xhr = new XMLHttpRequest();
xhr.timeout = 2000;
var obj = {a: 1, b: 2};
xhr.open(‘POST’, ‘/’);
xhr.send(obj);
}
5.text/html
- 一种使用HTTP作为传输协议,XML作为编程方式的远程调用规范
POST http://www.example.com HTTP/1.1
method1 50
Content-Type: text/xml
注意:
对于axios请求,不同的请求方式content-type也不同
- 当传递的是字符串的时候:application/x-www-form-urlencoded
- 当传递的是对象的时候:application/json
六、MySQL连表查询
内连接:指连接结果仅包含符合连接条件的行,参与连接的两个表都应该符合连接条件
外连接:连接结果不仅包含符合连接条件的行同时也包含自身不符合条件的行。包括左外连接、右外连接和全外连接
左外连接:左边表数据行全部保留,右边表保留符合连接条件的行
右外连接:右边表数据行全部保留,左边表保留符合连接条件的行
全外连接:左外连接 union 右外连接
union:会对两个结果集进行并集操作,不包括重复行,同时进行默认规则的排序
union all:对两个结果集进行并集操作,包括重复行,不会对结果进行排序
#1.sql Union用法
select 字段1 from 表名1 Union select 字段2 from 表名2;
#2.sql Union All用法
select 字段1 from 表名1 Union all select 字段2 from 表名2;
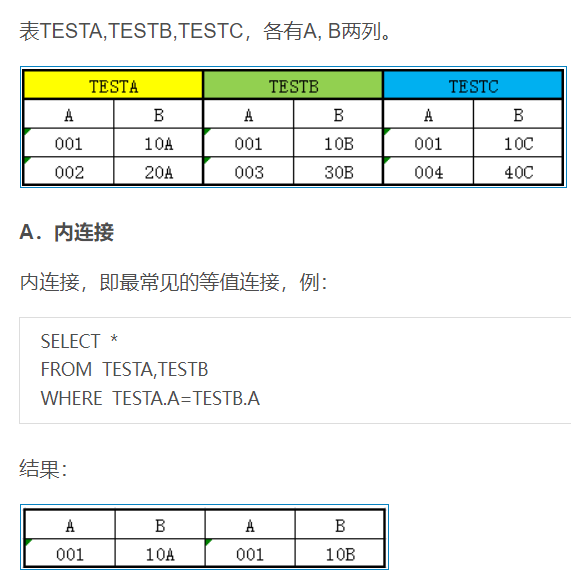


1.内连接
- 隐式内连接:select 字段列表 from 表1,表2,… where 条件
示例:
-- 1.查询员工的姓名,及其所属的部门(使用隐式内连接)
select tb_emp.name, tb_dept.name
from tb_emp,
tb_dept
where tb_dept.id = tb_emp.dept_id;
- 显式内连接:select 字段名称 from 表1 [inner] join 表2 on 连接条件
示例:
-- 2.查询员工的姓名,及其所属的部门(使用显式内连接)
select tb_emp.name, tb_dept.name
from tb_emp
inner join tb_dept on tb_emp.dept_id = tb_dept.id;
-- inner join 表示两张表进行内连接,on之后加上进行连接的条件
2.外连接
- 左外连接:select 字段列表 from 表1 left [outer] join 表2 on 条件
相当于查询表1(左表)全表扫描,然后到右表匹配,示例:
-- 3.查询user表的所有数据,和对应的user_role表中角色id
SELECT
a.*,
b.role_id
FROM
user a
LEFT JOIN user_role b ON a.user_id = b.user_id;
- 右外连接:select 字段列表 from 表1 right [outer] join 表2 on 条件
相当于查询表2(右表)全表扫描,然后到左表匹配,示例:
SELECT
b.* ,
a.user_name
FROM
USER a
RIGHT JOIN user_role b ON a.user_id = b.user_id;
3.自连查询
- 自己与自己相连查询:select * from A表 join B表 on 连表条件
-- 4.查询员工及其所属领导的名字。你要查询的结果再一张表中,但是还不能使用单表查询得到结果。
select a.name,b.name from tb_emp a join tb_emp b on a.managerid=b.id;
4.子查询
- 一个查询的结果作为另一个查询的条件或者临时表
-- 查询市场部的员工信息-----
-- 子查询返回的结果一列一条记录。 这个时候可以用=
select * from tb_emp where dept_id=(select id from tb_dept where name='市场部')
-- 多条记录
select * from tb_emp where dept_id in (select id from tb_dept where name in('市场部','研发部'))
5.组合查询
- 多个查询的结果组合到一起
- sql union sql —>把这两条sql查询的结果组合到一起。如果有重复记录则合并成一条
sql union all sql—>把这两条sql查询的结果组合到一起。如果有重复记录,不合并 - 注意:这两条sql返回的字段必须相同
SELECT NAME FROM tb_emp
WHERE salary > 8000 UNION
SELECT * FROM tb_emp
WHERE age > 40;
七、SQL查询时间
1.select * 效率低的原因
- 不需要的列会增加数据传输时间和网络开销
- 对于无用的大字段,如 varchar、blob、text,会增加 io 操作
- 失去MySQL优化器“覆盖索引”策略优化的可能性
八、Windows杀死进程
- 打开命令面板 win+R => cmd
- 查看端口对应的进程ID:netstat -nao | findstr 端口号
- 查看关于该进程的细节:tasklist | findstr PID
- 查杀任务:taskkill /pid PID
- 强制终止任务:taskkilll/F /pid PID
九、async和await
1.async/await概念
async用于声明一个function是异步的;await是等待一个异步方法执行完成
2.基础使用
- async表示这是一个async函数,await只能用在async函数里面,不能单独使用
- async返回的是一个Promise对象,await就是等待这个Promise的返回结果后,再继续执行
- await等待的是一个Promise对象,直接可以得到返回值
3.特点
- Async作为关键字放在函数前面,普通函数变成了异步函数
- 异步函数async函数调用,跟普通函数调用方式一样。在一个函数前面加上async,变成 async函数,异步函数
- 返回的是promise成功的对象
- Async函数配合await关键字使用
4.优点
- 方便级联调用:即调用依次发生的场景
- 同步代码编写方式:Promise使用then函数进行链式调用,一直点点点,是一种从左向右的横向写法;async/await从上到下,顺序执行,就像写同步代码一样,更符合代码编写习惯;
- 多个参数传递:Promise的then函数只能传递一个参数,虽然可以通过包装成对象来传递多个参数,但是会导致传递冗余信息,频繁的解析又重新组合参数,比较麻烦;async/await没有这个限制,可以当做普通的局部变量来处理,用let或者const定义的块级变量想怎么用就怎么用,想定义几个就定义几个,完全没有限制,也没有冗余工作;
- 同步代码和异步代码可以一起编写:使用Promise的时候最好将同步代码和异步代码放在不同的then节点中,这样结构更加清晰;async/await整个书写习惯都是同步的,不需要纠结同步和异步的区别,当然,异步过程需要包装成一个Promise对象放在await关键字后面
- 基于协程:Promise是根据函数式编程的范式,对异步过程进行了一层封装,async/await基于协程的机制,是真正的“保存上下文,控制权切换……控制权恢复,取回上下文”这种机制,是对异步过程更精确的一种描述;
- async/await是对Promise的优化:async/await是基于Promise的,是进一步的一种优化,不过在写代码时,Promise本身的API出现得很少,很接近同步代码的写法
十、Http/https
1.概念
http协议:客户端浏览器或其他程序与web服务器之间的应用层通信协议
https协议:简单可以理解为http+SSL/TLS,在http下加入SSL层,SSL用于保证安全的http数据传输
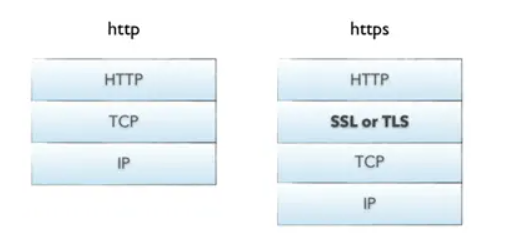
SSL(Secure Socket Layer,安全套接字层):SSL协议位于TCP/IP协议与各种应用层协议之间
TLS(Transport Layer Security,传输层安全):是一种基于SSL,更新出的更安全的密码协议
2.加密算法
- 对称加密:加密和解密都使用同一个密钥
- 非对称加密:加密使用的密钥和解密使用的密钥不相同,分别为公钥和私钥,公钥和算法对外公开,私钥保密,使用公钥加密的数据只能用私钥来进行解密,使用私钥加密的数据只能通过私钥进行解密,如RSA、DH、ECDSA
- 哈希算法:将任意长度的信息转换为较短的固定长度的值,算法不可逆,如MD5、SHA-1、SHA-2
- 数字签名:签名就是在信息的后面再加上一段内容,可以证明信息没有被修改过
3.详解
HTTP访问过程:HTTP请求过程中,客户端和服务器之间没有任何的身份确认过程,数据全部明文传输,易受到黑客攻击,面临各种风险,如窃听风险、篡改风险和冒充风险
HTTP向HTTPS演化过程:
- 使用对称加密:客户端和浏览器进行交互时,双方拥有相同的密钥,将传输的数据进行加密传输,但是密钥传输过程中容易泄露
- 非对称加密:客户端使用公钥对请求内容加密,服务器使用私钥对内容解密,存在的问题:公钥公开,黑客也可以拦截数据,使用公钥进行解密,获取其中的内容
- 对称+非对称加密:
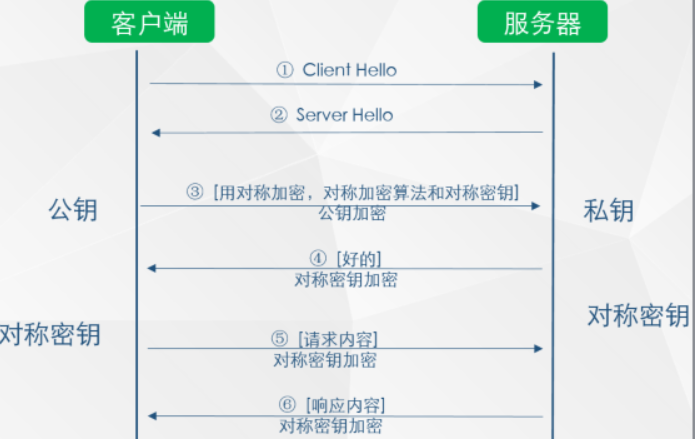
存在的问题:黑客也可以利用公钥获取客户端发送的数据,从而冒充服务器,发送给客户端假的公钥,为了防止黑客冒充,服务器向客户端发送一个SSL证书,包括证书的发布机构CA、证书的有效期、公钥、证书所有者和签名等信息,客户端接收到服务器发来的SSL证书时,会对证书进行校验
十一、Cookie/Session/SessionStorage/LocalStorage
普通请求步骤:客户端发送请求给服务器——服务器处理该请求——服务器将处理结果响应给该客户端
1.Cookie(保存在客户端)
介绍:cookie由网络服务器发送出来以存储在网络浏览器上,下次该用户又回到该网络服务器时,可以从该浏览器中读取回该信息
生命周期:创建Cookie的时候可以指定一个Expire值,这就是Cookie的生存周期,在这个周期内Cookie有效,超出周期Cookie就会被清除(毫秒)。注:Cookie的生存周期设置为 ‘0’或负值 ,这样在关闭浏览器时,就马上清除Cookie,不会记录用户信息,更加安全
2.Session(保存在服务端)
介绍:session是另一种记录客户状态的机制,不同的是Cookie保存在客户端浏览器中,session保存在服务器上,客户端浏览器访问服务器的时候,服务器把客户端信息以某种形式记录在服务器上,这就是session。客户端浏览器再次访问时只需要从该Session中查找该客户的状态就可以了
当会话过期或放弃后,服务器终止该对话
3.SessionStorage(客户端)
页面会话结束回将sessionstorage中的数据清除
生命周期:
- 页面会话在浏览器打开期间一直保持,并且 重新加载 或 恢复页面 仍会保持原来的页面会话(恢复数据)
- 在 新标签或窗口打开一个页面(从项目跳转新开一个页面) 时会复制顶级浏览会话的上下文作为新会话的上下文,这点和 session cookies 的运行方式不同
- 打开多个相同的URL的Tabs页面,会创建 各自的sessionStorage(多开同一项目,不会共享sessionStorage)
- 关闭对应浏览器窗口(Window)/ tab,会清除对应的sessionStorage
4.LocalStorage(客户端)
数据长期保存,关闭浏览器/标签页,数据仍然存在
十二、Nginx详解
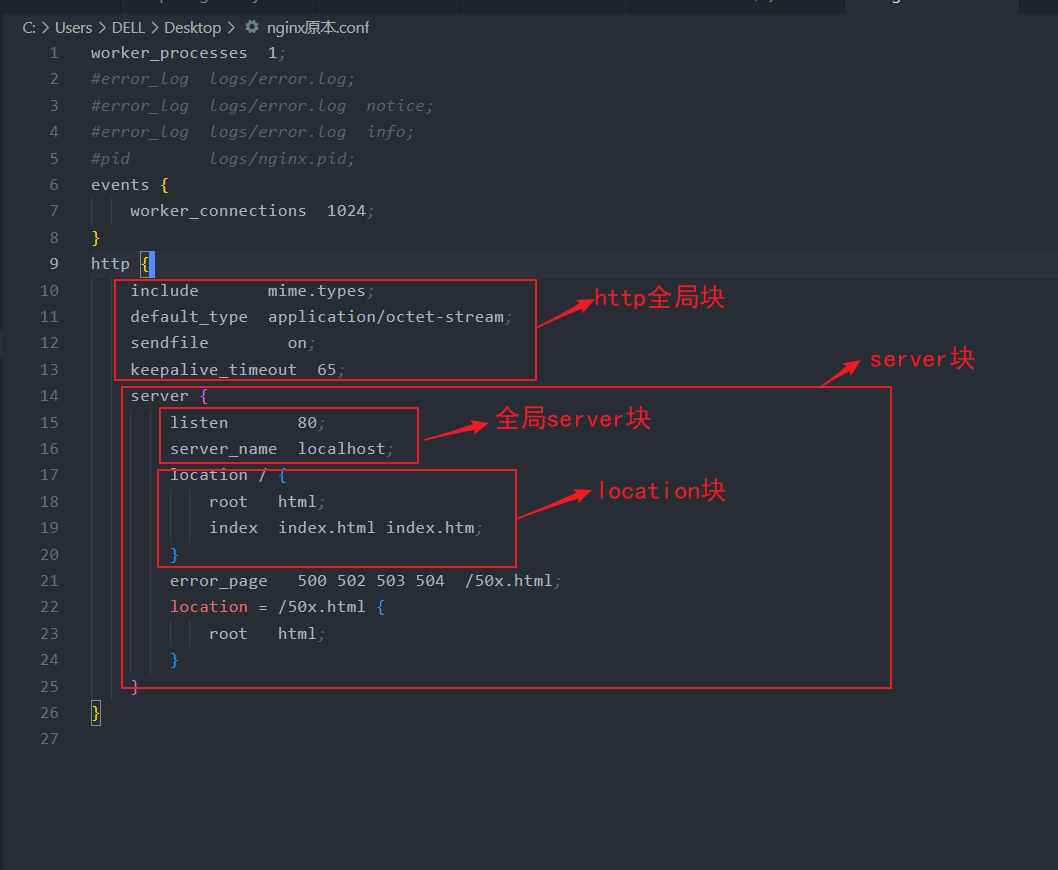
1.nginx.conf注解版本
#nginx进程数,建议设置为等于CPU总核心数。
worker_processes 1;
# 事件区块开始
events {
#单个进程最大连接数(最大连接数=连接数*进程数)
#根据硬件调整,和前面工作进程配合起来用,尽量大,但是别把cpu跑到100%就行。每个进程允许的最多连接数,理论上每台nginx服务器的最大连接数为。
worker_connections 1024;
}
#设定http服务器,利用它的反向代理功能提供负载均衡支持
http {
#include:导入外部文件mime.types,将所有types提取为文件,然后导入到nginx配置文件中
include mime.types;
#默认文件类型
default_type application/octet-stream;
#开启高效文件传输模式,sendfile指令指定nginx是否调用sendfile函数来输出文件,对于普通应用设为 on,如果用来进行下载等应用磁盘IO重负载应用,可设置为off,以平衡磁盘与网络I/O处理速度,降低系统的负载。注意:如果图片显示不正常把这个改成off。
#sendfile指令指定 nginx 是否调用sendfile 函数(zero copy 方式)来输出文件,对于普通应用,必须设为on。如果用来进行下载等应用磁盘IO重负载应用,可设置为off,以平衡磁盘与网络IO处理速度,降低系统uptime。
sendfile on;
#长连接超时时间,单位是秒
keepalive_timeout 65;
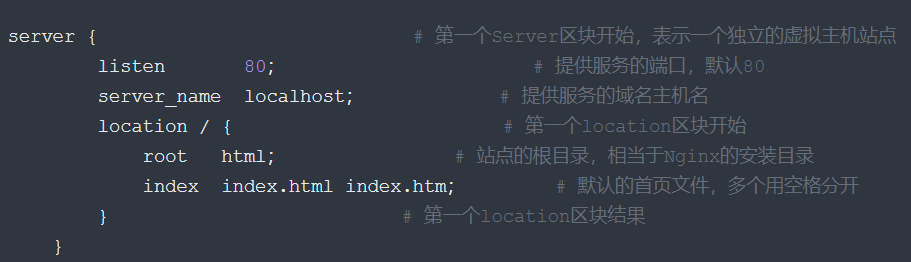
# 第一个Server区块开始,表示一个独立的虚拟主机站点
server {
# 提供服务的端口,默认80
listen 80;
# 提供服务的域名主机名
server_name localhost;
#对 "/" 启用反向代理,第一个location区块开始
location / {
root html; #服务默认启动目录
index index.html index.htm; # 默认的首页文件,多个用空格分开
}
# 错误页面路由
error_page 500 502 503 504 /50x.html; # 出现对应的http状态码时,使用50x.html回应客户
location = /50x.html { # location区块开始,访问50x.html
root html; # 指定对应的站点目录为html
}
}
}
2.整体理解
三部分组成:
- 全局块
- events块
- http块
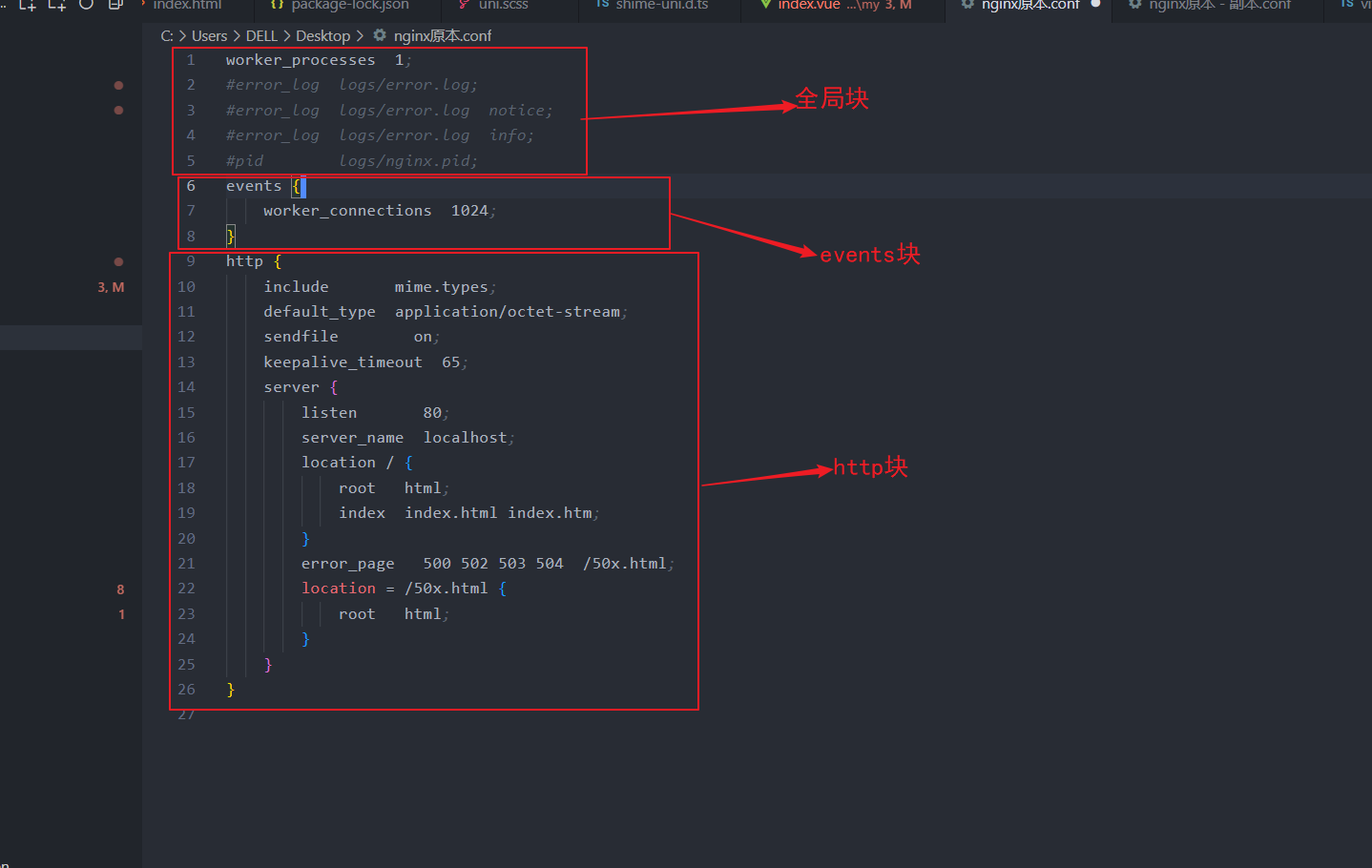
全局块:
主要设置一些nginx服务器整体运行的配置指令,包括配置运行nginx服务器的用户(组)、允许生成的worker process数,进程PID存放路径、日志存放路径和类型以及配置文件的引入等
events块:
events块涉及的指令主要影响 Nginx 服务器与用户的网络连接,常用的设置包括是否开启对多 work process 下的网络连接进行序列化,是否允许同时接收多个网络连接,选取哪种事件驱动模型来处理连接请求,每个 word process 可以同时支持的最大连接数等
http块:
配置核心!!!代理、缓存和日志等绝大数功能和第三方模块的相关配置
http块 = http全局块 + server块
http全局块
http全局块配置的指令包括文件引入、MIME-TYPE 定义、日志自定义、连接超时时间、单链接请求数上限等。
server 块
这块和虚拟主机有密切关系,虚拟主机从用户角度看,和一台独立的硬件主机是完全一样的,
该技术的产生是为了 节省互联网服务器硬件成本。
每个 http 块可以包括多个 server 块,而每个 server 块就相当于一个虚拟主机。
而每个 server 块也分为全局 server 块,以及可以同时包含多个 location 块。
全局 server 块
最常见的配置是本虚拟机主机的监听配置和本虚拟主机的名称或IP配置。
location 块
一个 server 块可以配置多个 location 块。
这块的主要作用是基于 Nginx 服务器接收到的请求字符串(例如 server_name/uri-string),
对虚拟主机名称 (也可以是IP 别名)之外的字符串(例如 前面的 /uri-string)进行匹配,
对特定的请求进行处理。 地址定向、数据缓 存和应答控制等功能,
还有许多第三方模块的配置也在这里进行。
3.简单配置上线
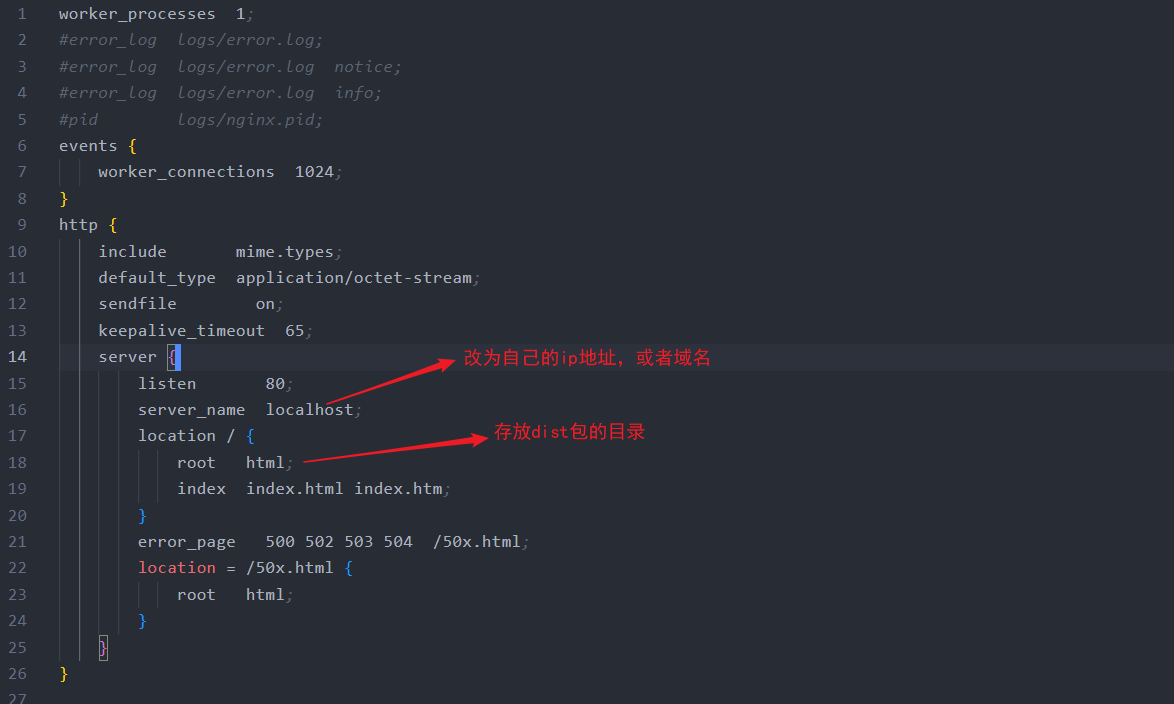
使用默认简单的配置,然后指定server_name和root,主要是告诉nginx代理的ip是xxx,然后我放在服务器的文件在bbb文件夹即可。nginx便会在用户访问这个ip时,自动的将bbb文件夹中的index.html返回到浏览器来展示页面
4.常见面试题
- Nginx优点:
- 占用内存小,可以实现高并发连接,处理响应快
- 可实现http服务器、虚拟主机、反向代理、负载均衡
- 配置简单
- 可以不暴露正式得服务器IP地址
- Nginx缺点:
- 动态处理差:nginx处理静态文件好,耗费内存少,但是处理动态页面不太理想,现在一般前端使用nginx作为反向代理抗住压力,apache作为后端处理动态请求
- rewrite弱
- Nginx如何处理请求
nginx接收到一个请求后,首先由listen和server_home指令匹配server模块,再匹配server模块里面得location,location就是实际地址
- 常用命令
- 启动:./nginx
- 停止:./nginx -s stop
- 重启:./nginx -s reload
- 检查nginx配置文件是否正确:./nginx -t
- 查询nginx服务:ps -ef | grep nginx
- 动静态资源分离
- 目的:加快网站的解析速度,静态资源走静态资源服务器,动态走动态服务器,后台应用分开部署,可以提高用户访问静态代码的速度
- 对于静态资源,如图片、js和css等文件,在nginx中设置缓存,当浏览器请求一个静态资源时,代理服务器nginx就可以直接处理,无需将请求转发给后端服务器tomcat
- 对于动态文件,nginx将请求转发给tomcat服务器处理
- nginx进程模型
nginx采用异步非阻塞的I/O多路复用时间驱动模型,可以同时处理大量的并发请求:
- Master进程:负责启动和关闭Worker进程,以及管理nginx的主配置文件和全局变量
- Worker进程:实际处理请求的进程,每个Worker进程独立处理连接,可以同时处理多个请求
优点:
- 资源占用少:Nginx的Master进程仅负责管理,不处理连接,占用资源少
- 可扩展性强:可以通过增加Worker进程来扩展处理能力
- 并发能力强:采用I/O多路复用技术,能够处理大量的并发连接
- 稳定性高:Worker进程之间互相独立,一个进程的崩溃不会影响其他进程
- 如何优化nginx性能
- 调整Worker进程数:根据服务器的CPU核心数和预计的并发连接数,适当调整Worker进程数,充分利用服务器资源
- 调整TCP连接参数:修改TCP缓冲区大小、TCP连接的超时时间等参数,以提高网络传输效率
- 启动文件缓存:将经常访问的静态文件缓存到内存中,可以减少对磁盘的访问,提高读取速度
- 启动gzip压缩:开启gzip压缩功能,可以减少响应数据的传输大小
- 启用SSL加密:使用SSL加密可以提高网站的安全性,但是也会增加CPU的负担,需要合理调整加密算法和参数
- 启动HTTP缓存:使用HTTP缓存技术可以减少对后端应用服务器的访问
十三、git 问题汇总
1.undo/revert/drop commit
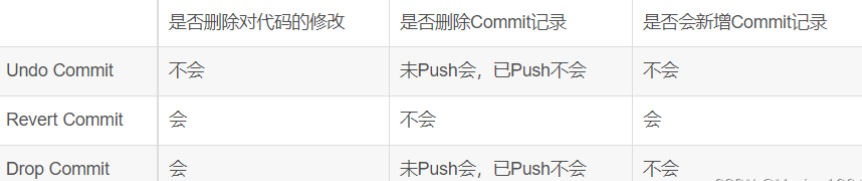
- undo commit:让commit的代码恢复到提交的状态,执行后和未commit之前完全一样
- revert commit:执行后将提交的相关代码记录修改删除,回到修改前的状态,会新增commit记录
- drop commit:执行后将提交的相关代码记录修改删除,回到修改前的状态,不会新增commit记录
十四、Java实现HTTP请求
1.使用HttpClient(第三方工具)
- 导入maven依赖
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpclient</artifactId>
<version>4.5.13</version>
</dependency>
- 使用httpClient发送请求
import org.apache.http.client.HttpClient;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
public class HttpClientExample {
public static void main(String[] args) throws Exception {
HttpClient httpClient = HttpClients.createDefault();
HttpGet httpGet = new HttpGet("https://api.example.com/endpoint"); // 替换为目标项目的URL
HttpResponse response = httpClient.execute(httpGet);
String responseBody = EntityUtils.toString(response.getEntity());
System.out.println("Response Status Code: " + response.getStatusLine().getStatusCode());
System.out.println("Response Body: " + responseBody);
}
}
2.使用HttpURLConnection(Java标准库实现)
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
public class HttpURLConnectionExample {
public static void main(String[] args) throws Exception {
URL url = new URL("https://api.example.com/endpoint"); // 替换为目标URL
HttpURLConnection connection = (HttpURLConnection) url.openConnection();
// 设置请求方法(GET、POST、PUT等)
connection.setRequestMethod("GET");
// 获取响应状态码
int responseCode = connection.getResponseCode();
System.out.println("Response Code: " + responseCode);
// 读取响应内容
BufferedReader reader = new BufferedReader(new InputStreamReader(connection.getInputStream()));
StringBuilder response = new StringBuilder();
String line;
while ((line = reader.readLine()) != null) {
response.append(line);
}
reader.close();
System.out.println("Response Body: " + response.toString());
}
}
3.使用Spring RestTemplate(Spring框架)
import org.springframework.http.ResponseEntity;
import org.springframework.web.client.RestTemplate;
public class RestTemplateExample {
public static void main(String[] args) {
RestTemplate restTemplate = new RestTemplate();
ResponseEntity<String> response = restTemplate.getForEntity("https://api.example.com/endpoint", String.class); // 替换为目标URL
String responseBody = response.getBody();
System.out.println("Response Status Code: " + response.getStatusCode());
System.out.println("Response Body: " + responseBody);
}
}
十五、Linux命令
1.查看文件和目录
- ls : 列出当前目录的文件和子目录
- ls -l : 以长格式列出文件和目录,显示详细信息(权限、所有者、大小等)
- ls -lh : 以人可读的格式显示文件和目录的大小
2.文件和目录操作
- mkdir newdirectory:创建新目录
- touch newfile.txt : 创建新文件
- cp oldfile.txt newfile.txt : 复制文件
- mv oldfile.txt newfile.txt : 重命名文件
- rm myfile.txt : 删除文件
3.系统信息和管理
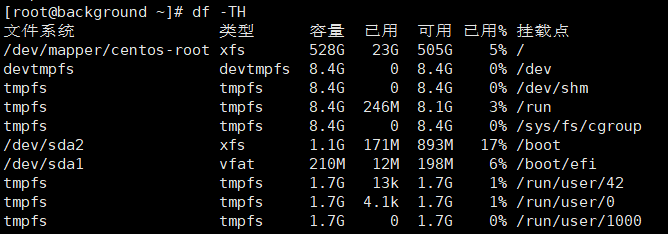
- 查看系统磁盘使用情况:df -TH
df : 表示显示文件系统的磁盘使用情况;-T :表示显示文件系统的类型;-H:表示以人可读的格式显示磁盘容量,以适应更容易阅读的输出格式
- 查看指定目录或文件夹磁盘使用情况:du -h /path/to/directory
- 查找1GB大文件:find /path/to/directory -type f -size +1G
- 移除大文件:rm /path/to/directory/file
- 查看特定进程信息:ps -ef | grep process_name
- 查看内存使用情况:free -h
- 查看系统文件删除后是否存在进程活着:lsof | grep deleted

- 查看服务器CPU使用情况:top
- 查看每个CPU核心的使用情况和平均值:mpstat -P ALL
4.项目启动部署
- 查看项目启动pid:lsof -i :端口号
- 后台挂载:nohup java -jar xxx.jar &
- 后台挂载指定输出日志文件out.log:nohup java -jar xxx.jar > out.log 2>&1 &
- 直接执行jar包:java -jar xxx.jar
注意: 如果nohup方式启动项目失败,使用java -jar 的方式启动,观察输出日志报错
十六、SQL的问题总结
1.not exists 和 not in
not exists:
- 通常与子查询一起使用
- 用于检查主查询中的行是否存在于子查询的结果集中
- 通常用于检查是否存在某种相关性,例如检查一个表中的值是否在另一个表中存在
- SELECT column1 FROM table1 WHERE NOT EXISTS (SELECT 1 FROM table2 WHERE table2.column2 = table1.column1);
not in:
- 这是一个条件运算符,用于过滤主查询的值,已排除与子查询中指定列的值匹配的情况
- 通常用于检查一个值是否不在子查询的结果集中
- 如果子查询中的结果集包含主查询中的任何值,主查询中的行将被排除
- SELECT column1 FROM table1 WHERE column1 NOT IN (SELECT column2 FROM table2);
主要区别:
- “NOT EXISTS” 对于子查询的结果集只关心是否为空,它通常用于检查相关性。如果子查询中有匹配的行,它就返回结果
- “NOT IN” 是对主查询中的值进行筛选,只要主查询中的值在子查询的结果集中找到,它就排除这些值
2.左连接 和 where条件的执行先后顺序
执行顺序:先执行on and 条件,后执行where条件筛选
3.SQL存储过程
执行顺序:
在 SQL Server 存储过程中,内部 SQL 语句的执行顺序通常是按照它们在存储过程中的定义顺序执行的。SQL Server 会逐一执行存储过程中的每个 SQL 语句,确保它们按照定义的顺序执行
begin … end:
- 事务控制:BEGIN 和 END 组合通常用于定义一个事务块,将一组 SQL 语句包装在其中,以确保这些语句要么全部成功执行,要么全部失败回滚。例如,你可以使用 BEGIN 和 END 定义一个事务块来确保一系列数据库更新操作是原子性的,要么全部成功,要么全部失败
BEGIN
-- 一组数据库更新操作
UPDATE table1 SET column1 = value1;
INSERT INTO table2 (column2) VALUES (value2);
-- 其他操作
END
- 流程控制:BEGIN 和 END 通常用于定义条件语句(如 IF…ELSE 或 WHILE 循环)中的代码块。这允许你根据条件执行不同的代码块
IF condition
BEGIN
-- 如果条件为真,执行此代码块
END
ELSE
BEGIN
-- 如果条件为假,执行此代码块
END
- 存储过程和触发器:BEGIN 和 END 通常用于定义存储过程和触发器中的代码块。它们将一系列 SQL 语句封装在一个存储过程或触发器中,以便以后可以调用或触发它们
CREATE PROCEDURE MyProcedure
AS
BEGIN
-- 存储过程中的 SQL 语句
END
4.SQL优化
1.避免使用select *
- 多查询出来的数据,通过网络IO传输过程中,会增加数据传输的时间
- select * 不会走覆盖索引(包含了所有查询所需的字段的索引),会出现大量回表操作
2.使用union all 代替union
- union关键字可以获取排重后的数据,union all关键字获取的是所有数据包括重复数据
- 排重需要遍历、排序和比较,更加耗时和消耗cpu资源,除非一些特殊场景,如不需要重复数据,其余情况都可以使用union all来加速
3.小表驱动大表
- 小表数据集驱动大表数据集
- in适用于左边大表,右边小表
- exists适用于左边小表,右边大表
例子:
假如有order和user两张表,其中order表有10000条数据,而user表有100条数据。时如果想查一下,所有有效的用户下过的订单列表。可以使用in关键字实现:
select * from order
where user_id in (select id from user where status=1)
也可以使用exists关键字实现:
select * from order
where exists (select 1 from user where order.user_id = user.id and status=1)
在以上这种业务场景,使用in关键字去实现业务需求,更加合适:
- sql语句中包含了in关键字,会优先执行in里面的子查询语句,再执行in外面的语句,如果in里面的数据量很少,那么作为条件查询速度更快
- sql语句包含了exists关键字,它优先执行exists左边的语句,即主查询语句,然后将它作为条件和右边的语句匹配
4.批量操作
如果我们需要批量向数据库中插入一批数据,应该避免在业务代码里面for循环里面重复插入,而是减少与数据库的连接次数,批量插入,因为每次远程请求数据库都会消耗性能。
批量操作每批的数据数量尽量控制在500以内,数据多余500,需要分多批次处理
5.用连接查询代替子查询
- 执行子查询时,先运行在嵌套在最内层的语句,再执行外层的语句,缺点是执行子查询时,需要创建临时表,查询完毕后,再删除这些临时表,有额外性能消耗
例子:
子查询
select * from order
where user_id in (select id from user where status=1)
连接查询
select o.* from order o
inner join user u on o.user_id = u.id
where u.status=1
6.选择合理的字段类型
- 能用数字类型,就不用字符串,因为字符的处理往往比数字要慢
- 尽可能使用小的类型,比如:用bit存布尔值,用tinyint存枚举值等
- 长度固定的字符串字段,用char类型
- 长度可变的字符串字段,用varchar类型
- 金额字段用decimal,避免精度丢失问题
char表示固定字符串类型,该类型的字段存储空间的固定的,会浪费存储空间
varchar表示变长字符串类型,该类型的字段存储空间会根据实际数据的长度调整,不会浪费存储空间
7.提升group by效率
例子:过滤订单中用户大于等于200的用户
反例:
select user_id,user_name from order
group by user_id
having user_id <= 200;
正例:
select user_id,user_name from order
where user_id <= 200
group by user_id
先筛选再分组可以有效缩小数据范围,进而提高分组效率
8.索引优化
- 根据查询频率添加索引:考虑哪些列经常进行查询的条件,如where子句中的某一列
- 联合索引:对于包含多个列的查询条件,可以考虑创建联合索引