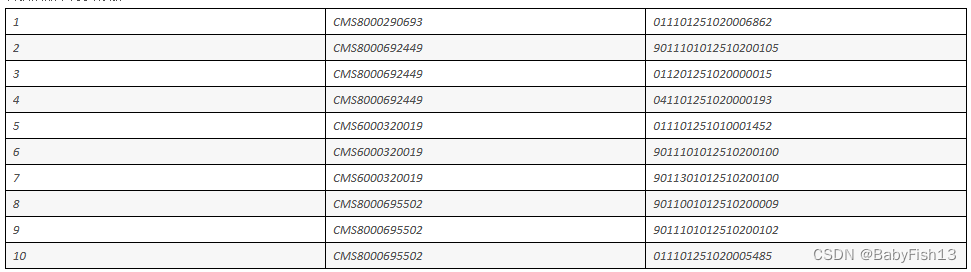
首先,我们需要使用open-uri模块来打开网页,并使用Nokogiri模块来解析网页内容。然后,我们可以使用Nokogiri的css方法来选择我们想要的元素,例如标题,作者,内容等。最后,我们可以使用open-uri模块来下载文件。
以下是一个简单的例子:
require 'open-uri'
require 'nokogiri'
proxy_host = 'jshk.com.cn'
# 使用open-uri打开网页
html = open(" proxy_opts: { host: proxy_host, port: proxy_port })
# 使用Nokogiri解析网页内容
doc = Nokogiri::HTML(html)
# 选择我们想要的元素,例如标题,作者,内容等
title = doc.css('div.h2').text
author = doc.css('div.p1').text
content = doc.css('div.content').text
# 输出结果
puts "Title: #{title}"
puts "Author: #{author}"
puts "Content: #{content}"
注意:在使用代理时,需要确保代理服务器的稳定性.此外,爬虫程序的编写需要考虑到效率问题,避免对目标网站的服务器造成过大的负担。