Collectors.groupingBy方法的使用
简单使用
业务场景:现在有5个人,这些人都年龄分部在18-30岁之间。现要求把他们按照年龄进行分组
key:年龄
value:数据列表
package com.liudashuai;
import java.util.Arrays;
import java.util.List;
import java.util.Map;
import java.util.stream.Collectors;
public class Test{
public static void main(String[] args) {
People people1 = new People("张三", 19);
People people2 = new People("李四", 19);
People people3 = new People("王五", 27);
People people4 = new People("赵六", 37);
People people5 = new People("刘备", 37);
List<People> list = Arrays.asList(people1, people2, people3, people4, people5);
//按照age进行分组
Map<Integer, List<People>> result = list.stream()
.collect(Collectors.groupingBy(People::getAge));
//打印结果
result.forEach((k, v) -> {
System.out.println(k);
System.out.println(v);
System.out.println("--------------------");
});
}
}
class People{
public String name;
public int age;
public People() {
}
public People(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "People{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}
输出结果如下:
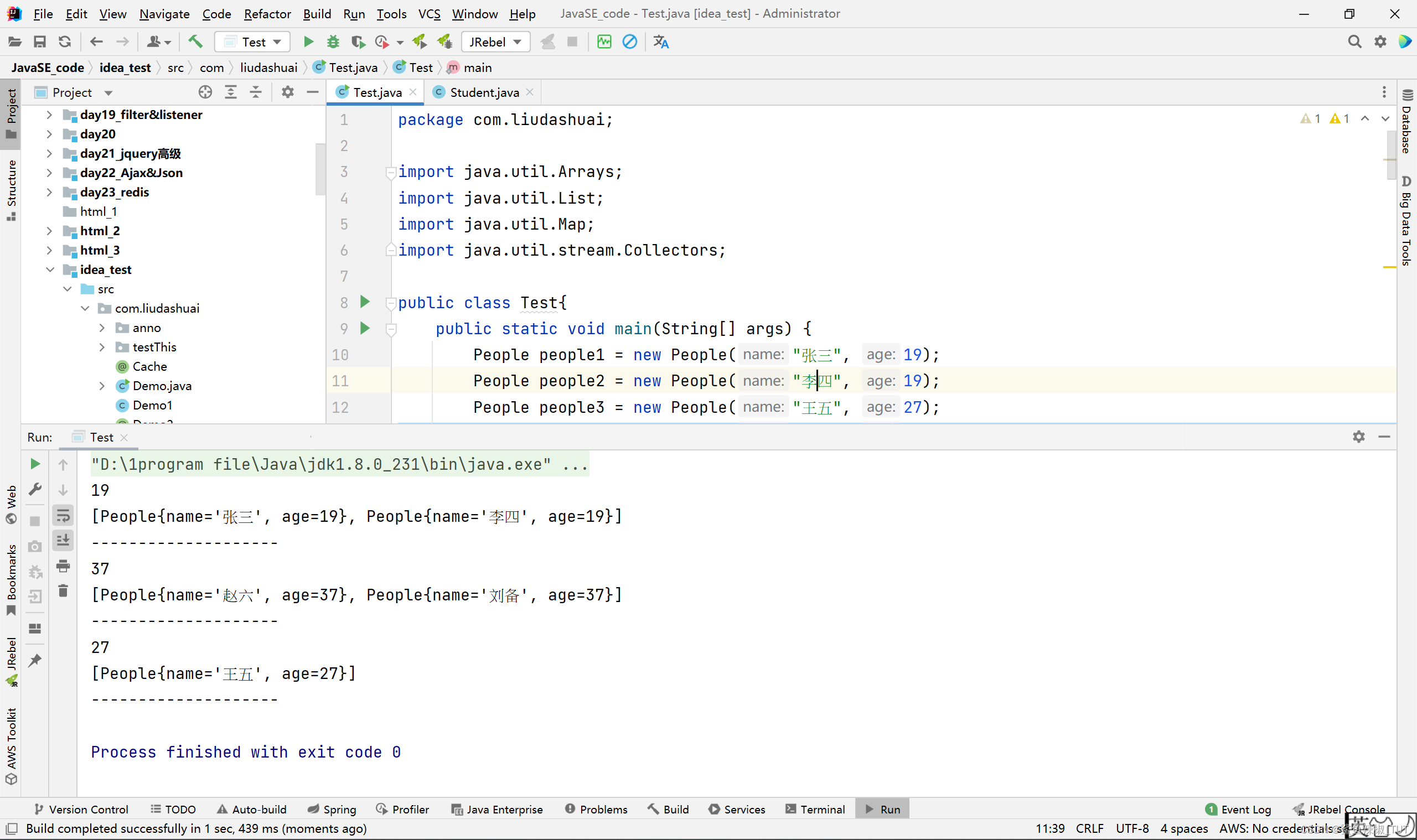
效果相当于是,把list这个集合里面存放的100个人每个人都调用Perple的getAge方法,按照getAge方法的返回值进行分组。每个组是一个Map<Integer, List>类型的对象。每个组,即Map<Integer, List>,这个对象中的键是getAge的返回值,即,分组的依据。Map<Integer, List>的值是这个年龄对应组中的成员列表,是一个list。
分组且排序
分组之后,是不能对每个分组进行比较的(也就无法排序),因为groupingBy方法的返回值是放在collect方法里面作为参数的,执行完后已经是终止了流。
Stream流中的collect方法长这样:
public interface Stream<T> extends BaseStream<T, Stream<T>> {
……
<R, A> R collect(Collector<? super T, A, R> collector);
……
}
collect方法能将流转换成其他的形式,他需要接收一个Collector接口的实现,用于给Stream中元素做汇总方法,即告诉程序怎么汇总。
collect中的参数一般我们都是写java.util.stream.Collectors类中内置的静态方法。比如,Collectors.toList()汇总成List、Collectors.toSet()汇总成Set、Collectors.toMap(……)汇总为Map、Collectors.counting()汇总为个数、Collectors.groupingBy(……)按照某个东西进行汇总分组等等
collect,收集,可以说是stream流中内容最繁多、功能最丰富的部分了。从字面上去理解,就是把一个流收集起来,最终可以是收集成一个值也可以收集成一个新的集合、收集为一个字符串等等。
Collectors中的groupingBy方法声明如下:
Collectors.groupingBy(Function<? super T, ? extends K> classifier, Collector<? super T, A, D> downstream)
好,然后我们去完成需求。
做法:
提前排序,再进行分组.
这里还展示了一些groupingBy方法的扩展用法。
package com.liudashuai;
import java.util.*;
import java.util.stream.Collectors;
public class Test {
public static void main(String[] args) {
Student student1 = new Student(1, 10);
Student student2 = new Student(1, 10);
Student student3 = new Student(2, 20);
Student student4 = new Student(2, 30);
Student student5 = new Student(3, 30);
Student student6 = new Student(3, 40);
Student student7 = new Student(4, 100);
Student student8 = new Student(4, 100);
Student student9 = new Student(4, 20);
Student student10 = new Student(4, 10);
List<Student> list = Arrays.asList(student1, student2, student3, student4, student5, student6, student7, student8, student9, student10);
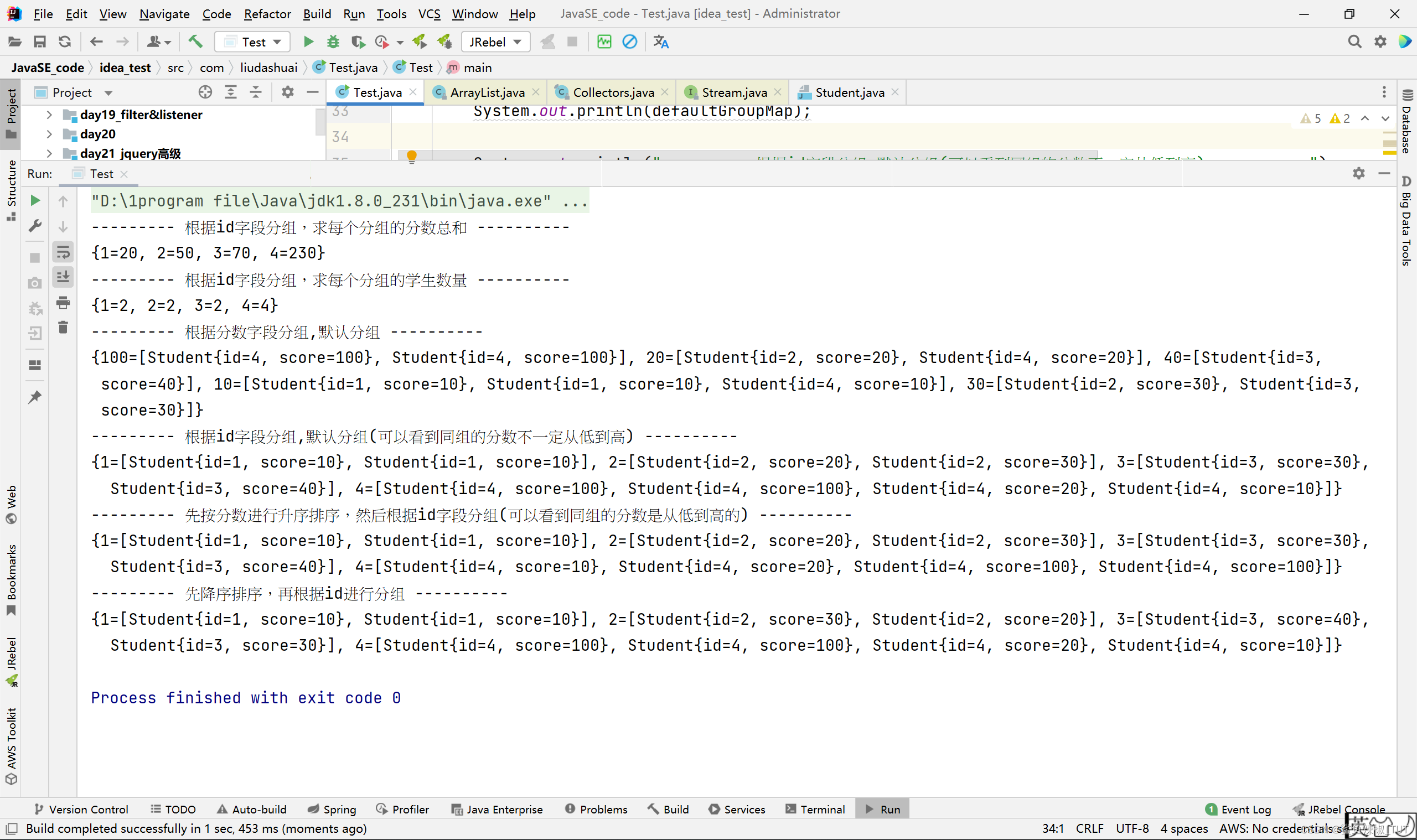
System.out.println("--------- 根据id字段分组,求每个分组的分数总和 ----------");
Map<Integer, Integer> collect = list.stream().collect(Collectors.groupingBy(Student::getId, Collectors.summingInt(Student::getScore)));
System.out.println(collect.toString());
System.out.println("--------- 根据id字段分组,求每个分组的学生数量 ----------");
Map<Integer, Long> countMap = list.stream().collect(Collectors.groupingBy(Student::getId, Collectors.counting()));
System.out.println(countMap.toString());
System.out.println("--------- 根据分数字段分组,默认分组 ----------");
Map<Integer, List<Student>> defaultGroupMap = list.stream().collect(Collectors.groupingBy(Student::getScore));
// System.out.println(JSONObject.toJSONString(defaultGroupMap));
System.out.println(defaultGroupMap);
System.out.println("--------- 根据id字段分组,默认分组(可以看到同组的分数不一定从低到高) ----------");
//注意:你collect(Collectors.groupingBy(Student::getId))和collect(Collectors.groupingBy(Student::getId),Collector.toList())效果是一样的,因为一个参数的groupingBy方法底层默认是用Collector.toList()作为值收集器的。当然带参的groupingBy方法不是默认用Collector.toList()作为值收集器的,是你自己指定的。比如上面“根据id字段分组,求每个分组的学生数量”案例里面我们就自己指定值收集器为Collectors.counting(),这样数据会被收集到一个Integer里面,然后放到Map中作为值。
Map<Integer, List<Student>> defaultGroupMap2 = list.stream().collect(Collectors.groupingBy(Student::getId));
// System.out.println(JSONObject.toJSONString(defaultGroupMap));
System.out.println(defaultGroupMap2);
System.out.println("--------- 先按分数进行升序排序,然后根据id字段分组(可以看到同组的分数是从低到高的) ----------");
Map<Integer, List<Student>> sortGroupMap = list.stream().sorted(Comparator.comparing(Student::getScore))
.collect(Collectors.groupingBy(Student::getId));
// System.out.println(JSONObject.toJSONString(sortGroupMap));
System.out.println(sortGroupMap);
System.out.println("--------- 先降序排序,再根据id进行分组 ----------");
Map<Integer, List<Student>> reversedSortGroupMap = list.stream().sorted(Comparator.comparing(Student::getScore).reversed())
.collect(Collectors.groupingBy(Student::getId));
// System.out.println(JSONObject.toJSONString(reversedSortGroupMap));
System.out.println(reversedSortGroupMap);
}
}
class Student {
public Student(Integer id, Integer score) {
this.id = id;
this.score = score;
}
private Integer id;
private Integer score;
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public Integer getScore() {
return score;
}
public void setScore(Integer score) {
this.score = score;
}
@Override
public String toString() {
return "Student{" +
"id=" + id +
", score=" + score +
'}';
}
}
执行结果:
分组后再进行分组(一二级分组)
package com.liudashuai;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
import java.util.stream.Collectors;
public class Test {
public static void main(String[] args) {
List<Person> personList = new ArrayList<>();
personList.add(new Person("Ram", 30,"浙江"));
personList.add(new Person("Shyam", 25,"江苏"));
personList.add(new Person("Shiv", 25,"江苏"));
personList.add(new Person("Aim", 25,"浙江"));
personList.add(new Person("Mahesh", 30,"江苏"));
personList.add(new Person("Make", 30,"江苏"));
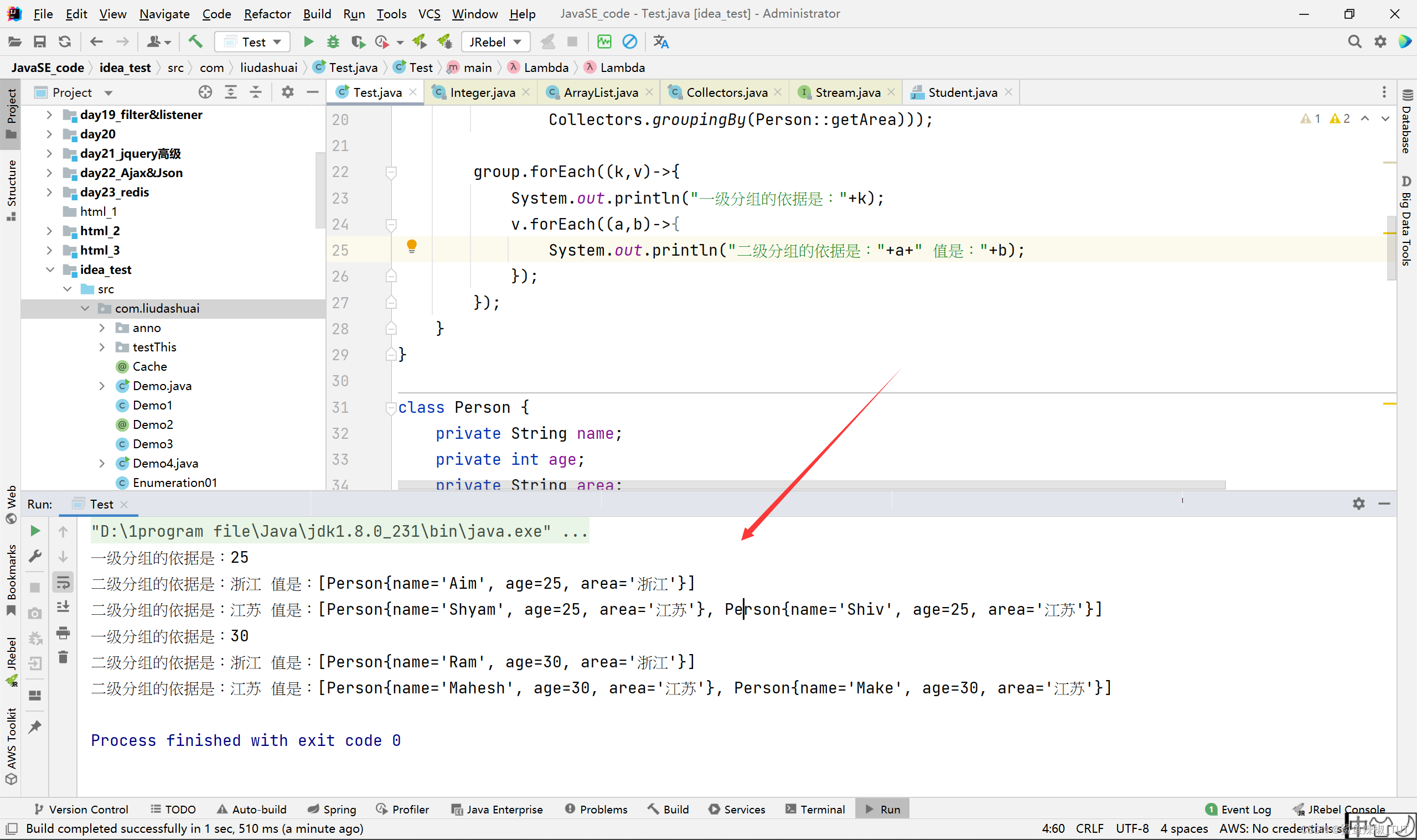
// 将员工先按性别分组,再按地区分组
Map<Integer, Map<String, List<Person>>> group = personList.stream().collect(Collectors.groupingBy(Person::getAge,
Collectors.groupingBy(Person::getArea)));
group.forEach((k,v)->{
System.out.println("一级分组的依据是:"+k);
v.forEach((a,b)->{
System.out.println("二级分组的依据是:"+a+" 值是:"+b);
});
});
}
}
class Person {
private String name;
private int age;
private String area;
public Person(String name, int age, String area) {
this.name = name;
this.age = age;
this.area = area;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public String getArea() {
return area;
}
public void setArea(String area) {
this.area = area;
}
@Override
public String toString() {
return "Person{" +
"name='" + name + '\'' +
", age=" + age +
", area='" + area + '\'' +
'}';
}
}
结果如下:
补充一句:groupingBy分组是通过
hashcode和equals方法来判断两个对象是否相等的,相等才会被放到一个组里。因为String重写了equals和hashcode方法,所以按照字符串进行分组只要两个字符串内容是一样的,就算他们是两个不同的对象,那么也会被放到一个组里面。
按照int类型的值进行分组,会被自动装箱为Integer,因为Integer中的equals和hashcode方法也不重写了,所以,两个int值一样,也会被放到一个组里面。所以放心按照int和String来进行分组,不会出现内容一样,被分到两个组里面去的情况的。当然Double也一样,很多java提供的类型都重写了hashcode和equals方法。
而且java中有一个规范,就是equals判断相等的,那么hashcode的判断就要相等。所以我们不知道两个对象是否equals和hashcode的判断结果都是相等的,你就看两个对象进行equals判断是否相当于,如果equals判断相等,那么一般来说hashcode的判断也会相等的。除非你不遵守java的规范来写代码。
groupingBy分组指定键名
package com.liudashuai;
import java.util.List;
import java.util.Map;
import java.util.stream.Collectors;
import java.util.stream.Stream;
public class Test {
public static void main(String[] args) {
Stream<Student> studentStream = Stream.of(
new Student("赵丽颖", 52, 95),
new Student("杨颖", 56, 88),
new Student("貂蝉", 56, 88),
new Student("迪丽热巴", 56, 55),
new Student("柳岩", 52, 33)
);
//多级分组
//1.先根据年龄分组,然后再根据成绩分组,又按及格和不及格分组
// 分析:
// 第一个Collectors.groupingBy() 使用的是年龄分组
// 第二个Collectors.groupingBy() 使用分数进行分组
// 第三个Collectors.groupingBy() 使用及格和不及格进行分组
Map<Integer, Map<Integer, Map<String, List<Student>>>> map = studentStream.collect(Collectors.groupingBy(str -> str.getAge(), Collectors.groupingBy(str -> str.getScore(), Collectors.groupingBy((student) -> {
if (student.getScore() >= 60) {
return "及格";
} else {
return "不及格";
}
}))));
map.forEach((key,value)->{
System.out.println("年龄:" + key);
value.forEach((k2,v2)->{
System.out.println("\t" + v2);
});
});
}
}
class Student {
private String name;
private int age;
private int score;
public Student(String name, int age, int score) {
this.name = name;
this.age = age;
this.score = score;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public int getScore() {
return score;
}
public void setScore(int score) {
this.score = score;
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", age=" + age +
", score=" + score +
'}';
}
}
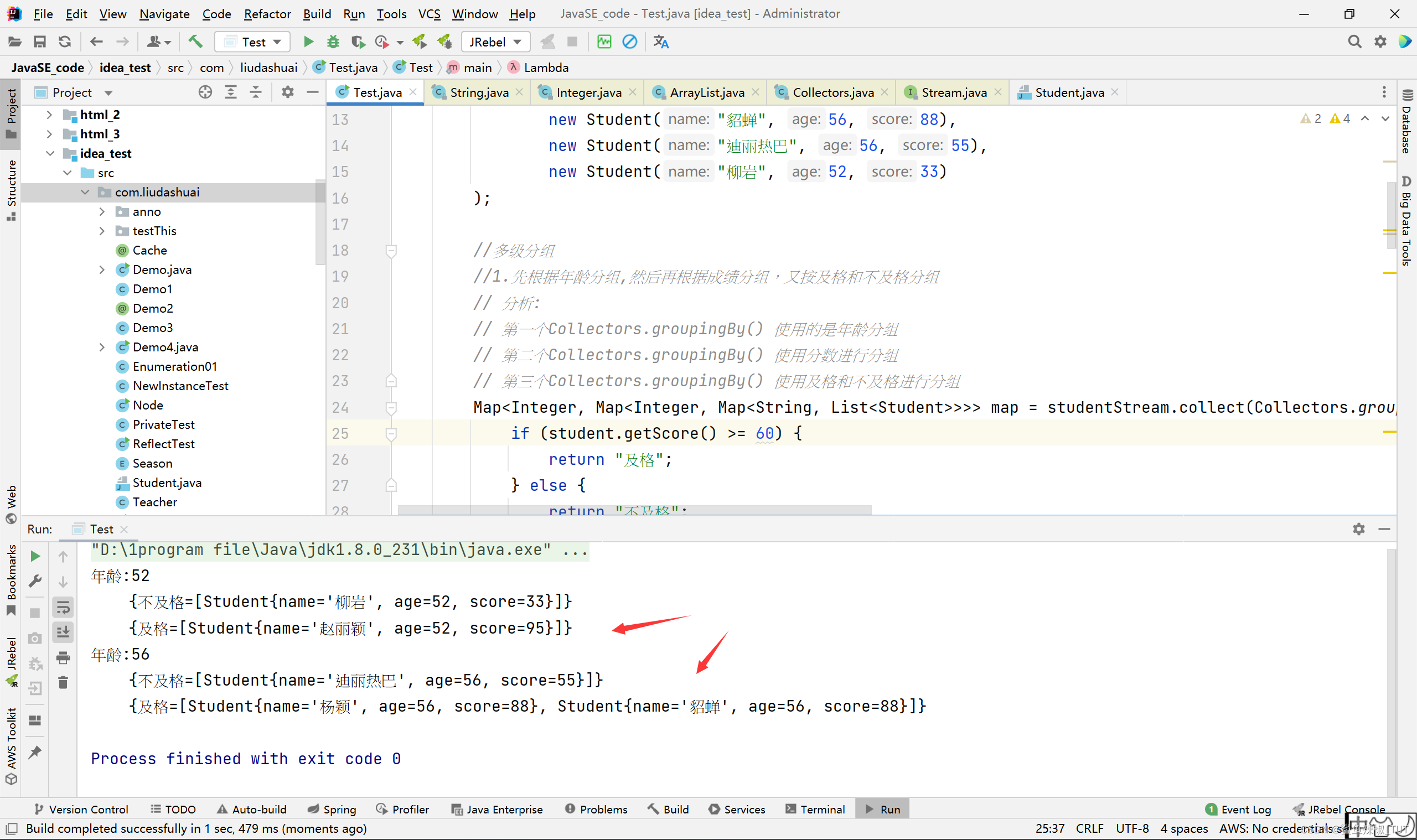
之前我们用方法引用,相当于是借别人的方法来做groupingBy形参接口的方法实现来进行分组,这里我们自己写的就相当于是自己写groupingBy形参接口的方法实现来进行分组。他是怎么进行分组的呢?其实就是看这个实现的返回值是什么,然后根据返回值的equals和hashcode判断是否相等来进行分组的。所以,我们上面第二个分组groupingBy方法的return "及格"可以把”年龄一样,分数一样,且分数>60“的”杨颖“和”貂蝉“分为一组。
package com.liudashuai;
import java.util.List;
import java.util.Map;
import java.util.stream.Collectors;
import java.util.stream.Stream;
public class Test {
public static void main(String[] args) {
Stream<Student> studentStream = Stream.of(
new Student("赵丽颖", 52, 95),
new Student("杨颖", 56, 88),
new Student("杨颖", 56, 88),
new Student("貂蝉", 56, 88),
new Student("迪丽热巴", 56, 55),
new Student("柳岩", 52, 33)
);
//多级分组
//1.先根据年龄分组,然后再根据成绩分组,又按及格和不及格分组
// 分析:
// 第一个Collectors.groupingBy() 使用的是年龄分组
// 第二个Collectors.groupingBy() 使用分数进行分组
// 第三个Collectors.groupingBy() 使用及格和不及格进行分组
Map<Integer, Map<Integer, Map<String, List<Student>>>> map = studentStream.collect(Collectors.groupingBy(str -> str.getAge(), Collectors.groupingBy(str -> str.getScore(), Collectors.groupingBy((student) -> {
if (student.getName().equals("杨颖")) {
return "是杨颖";
} else {
return "不是杨颖";
}
}))));
map.forEach((key,value)->{
System.out.println("年龄:" + key);
value.forEach((k2,v2)->{
System.out.println("\t" + v2);
});
});
}
}
class Student {
private String name;
private int age;
private int score;
public Student(String name, int age, int score) {
this.name = name;
this.age = age;
this.score = score;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public int getScore() {
return score;
}
public void setScore(int score) {
this.score = score;
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", age=" + age +
", score=" + score +
'}';
}
}
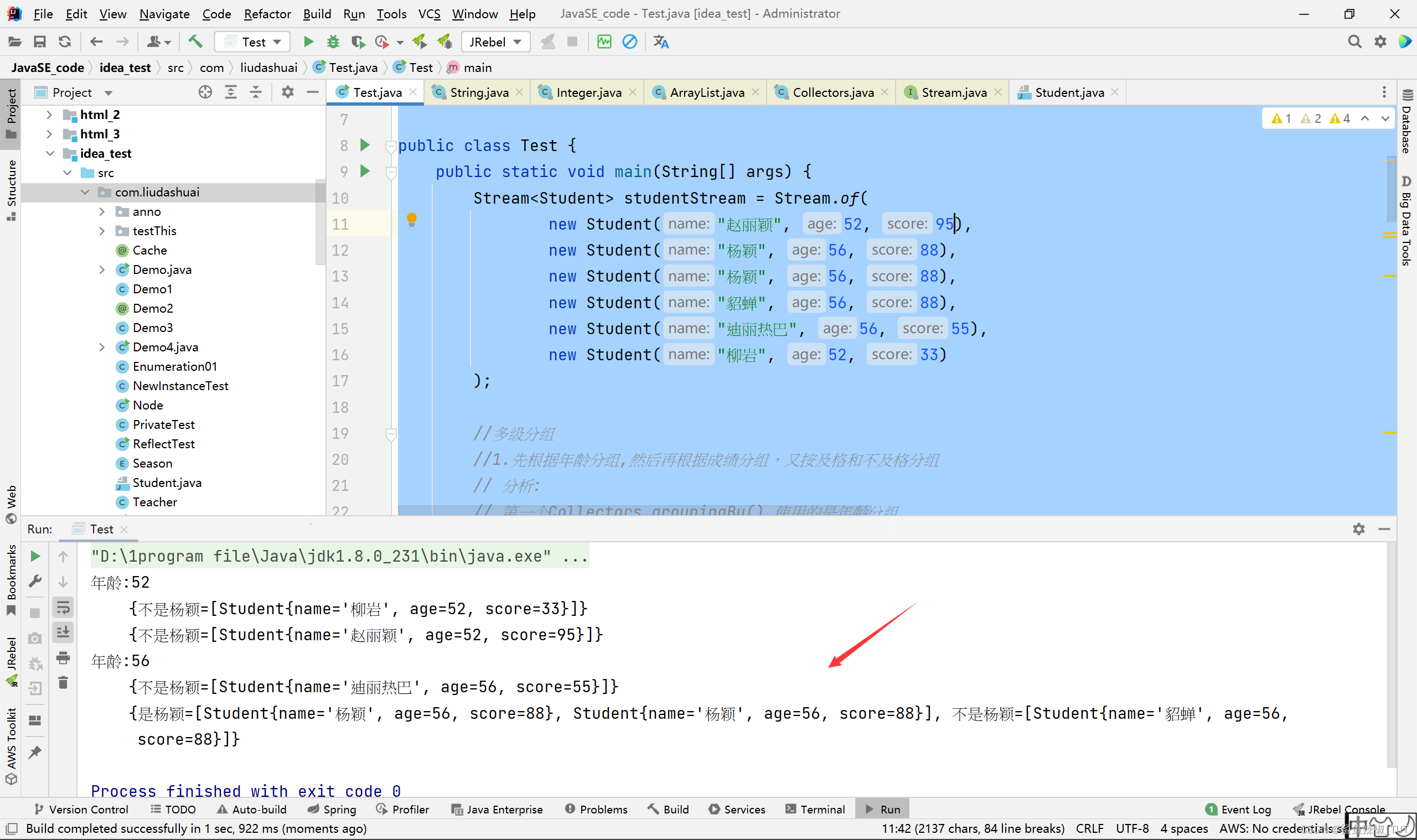
上面这个例子里面,把”年龄一样,分数一样,名字是杨颖的分为一组“,”年龄一样,分数一样,名字不是杨颖的分为另一组“。
Collectors.mapping()方法的使用
package com.liudashuai;
import java.util.ArrayList;
import java.util.List;
import java.util.stream.Collectors;
public class Test {
public static void main(String[] args) {
List<Person> list = new ArrayList<>();
list.add(new Person("Ram", 30));
list.add(new Person("Shyam", 20));
list.add(new Person("Shiv", 20));
list.add(new Person("Mahesh", 30));
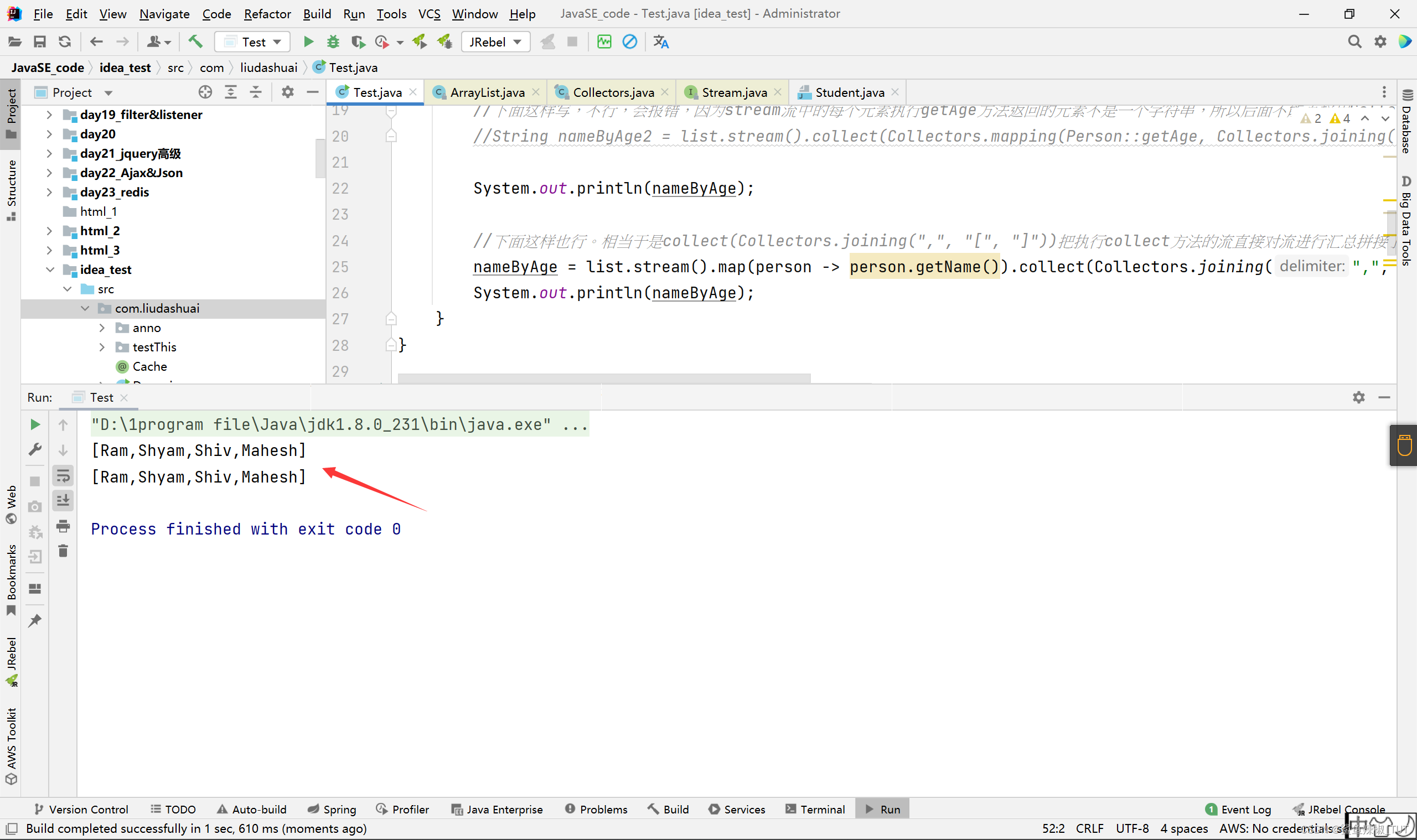
//Collectors.mapping(Person::getName, Collectors.joining(",", "[", "]"))相当于把stream流中的每个元素的getName返回值作为新Stream流中元素,然后进行拼接,元素与元素之间用逗号隔开,最前面用"[",最后面用"]"拼接。Collectors.mapping相当于是对流中的元素再继续进行一次操作形成一个流,然后如果有第二个参数会用第二个参数再对这个流进行汇总。
String nameByAge = list.stream().collect(Collectors.mapping(Person::getName, Collectors.joining(",", "[", "]")));
//下面这样写,不行,会报错,因为stream流中的每个元素执行getAge方法返回的元素不是一个字符串,所以后面不能直接用Collectors.joining来拼接。
//String nameByAge2 = list.stream().collect(Collectors.mapping(Person::getAge, Collectors.joining(",", "[", "]")));
System.out.println(nameByAge);
//下面这样也行。相当于是collect(Collectors.joining(",", "[", "]"))把执行collect方法的流直接对流进行汇总拼接了。不像上面collect(Collectors.mapping(Person::getAge, Collectors.joining(",", "[", "]")))这样对调用collection方法的流汇总前还进行一次操作形成流,才汇总。
nameByAge = list.stream().map(person -> person.getName()).collect(Collectors.joining(",", "[", "]"));
System.out.println(nameByAge);
}
}
class Person {
private String name;
private int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public int getAge() {
return age;
}
@Override
public String toString() {
return "Person{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}
执行结果:
Collectors的groupingBy和mapping一起用
package com.liudashuai;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
import java.util.stream.Collectors;
public class Test {
public static void main(String[] args) {
List<Person> list = new ArrayList<>();
list.add(new Person("Ram", 30));
list.add(new Person("Shyam", 20));
list.add(new Person("Shiv", 20));
list.add(new Person("Mahesh", 30));
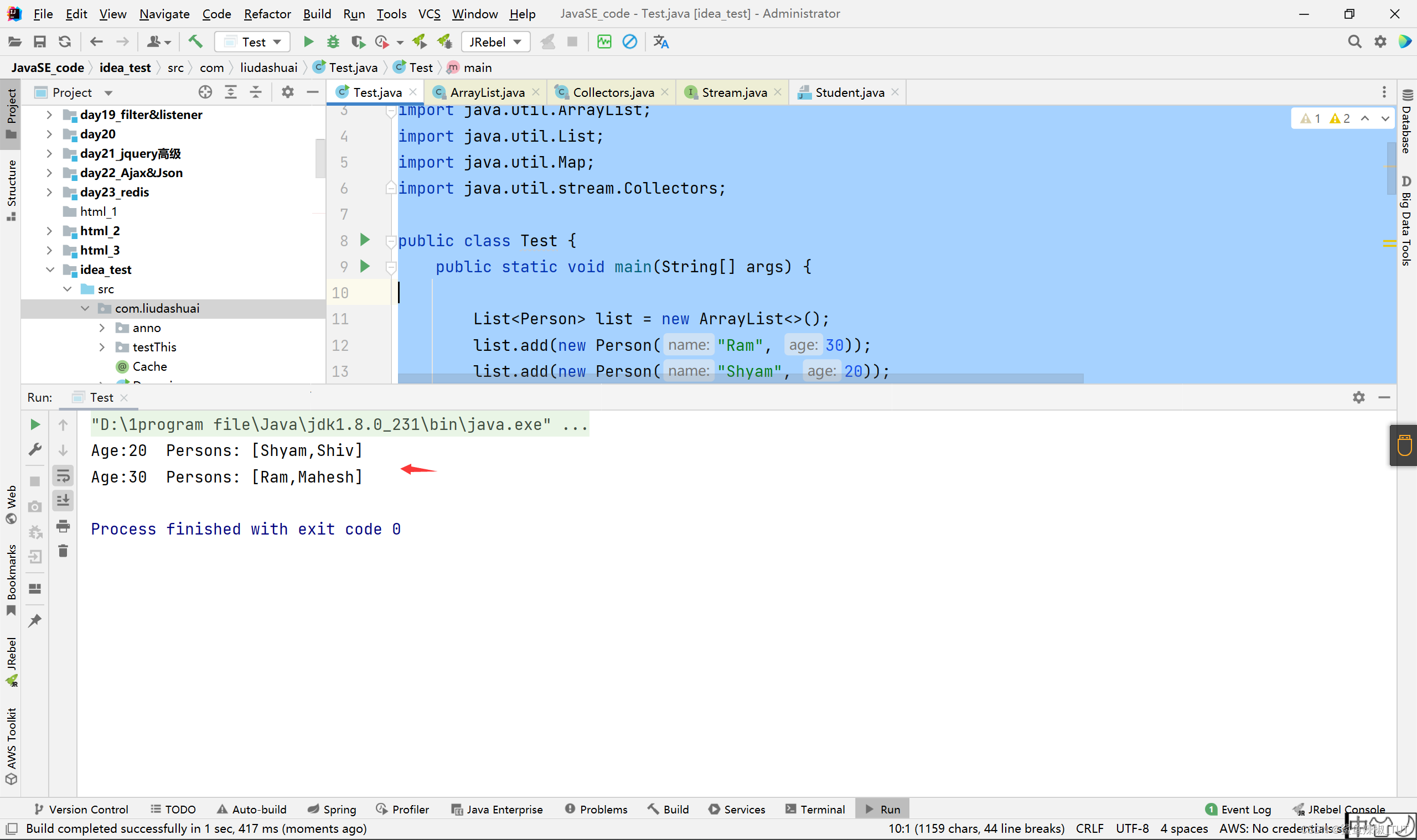
//按年龄进行分组形成多个流,一个分组一个流,然后把每个分组对应的stream流中的元素改造为那些元素执行getName的返回值得到多个新的Stream流(一个分组一个新的流),并且把这多个新的Stream流进行拼接,元素与元素之间用逗号隔开,最前面用"["最后面用"]"拼接,然后返回,放在一个Map<Integer, String>里中一个键值对的里,作为值,这个键值对的键是分组的依据,即那个getName。
Map<Integer, String> nameByAgeMap = list.stream().collect(
Collectors.groupingBy(Person::getAge, Collectors.mapping(Person::getName, Collectors.joining(",", "[", "]"))));
//输出Map数据
nameByAgeMap.forEach((k, v) -> System.out.println("Age:" + k + " Persons: " + v));
}
}
class Person {
private String name;
private int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public int getAge() {
return age;
}
@Override
public String toString() {
return "Person{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}
结果:
Collectors的toList/toSet/toMap
package com.liudashuai;
import java.util.*;
import java.util.stream.Collectors;
public class Test {
public static void main(String[] args) {
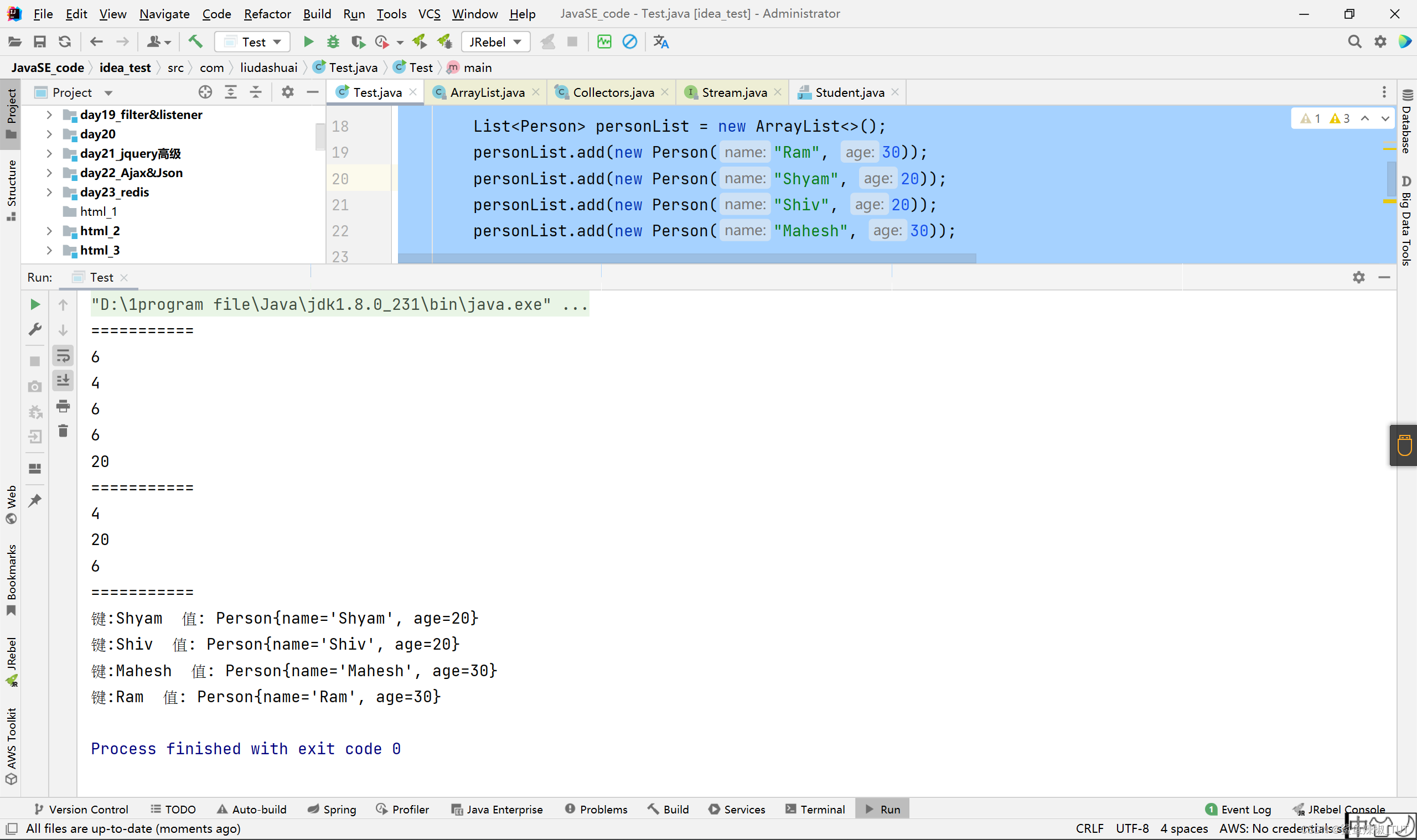
List<Integer> list = Arrays.asList(1, 6, 3, 4, 6, 7, 9, 6, 20);
List<Integer> listNew = list.stream().filter(x -> x % 2 == 0).collect(Collectors.toList());
System.out.println("===========");
listNew.forEach(System.out::println);
Set<Integer> set = list.stream().filter(x -> x % 2 == 0).collect(Collectors.toSet());
System.out.println("===========");
set.forEach(System.out::println);
List<Person> personList = new ArrayList<>();
personList.add(new Person("Ram", 30));
personList.add(new Person("Shyam", 20));
personList.add(new Person("Shiv", 20));
personList.add(new Person("Mahesh", 30));
//相当于是toMap的第一个参数是返回的Map的键,执行collect方法的stream流对象中的每个元素(p -> p中前面的p就是指执行collect方法的stream流对象中的每个元素,后面的p是指返回到Map中的值)为返回的Map的值
Map<String, Person> collect = personList.stream().collect(Collectors.toMap(Person::getName, p -> p));
System.out.println("===========");
collect.forEach((k, v) -> System.out.println("键:" + k + " 值: " + v));
}
}
class Person {
private String name;
private int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public int getAge() {
return age;
}
@Override
public String toString() {
return "Person{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}
执行结果:
Collectors的partitioningBy
package com.liudashuai;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
import java.util.stream.Collectors;
public class Test {
public static void main(String[] args) {
List<Person> personList = new ArrayList<>();
personList.add(new Person("Ram", 33));
personList.add(new Person("Shyam", 25));
personList.add(new Person("Shiv", 20));
personList.add(new Person("Mahesh", 30));
//按年龄进行分区,大于25的在一个区,不大于25的在一个区
Map<Boolean, List<Person>> part = personList.stream().collect(Collectors.partitioningBy(x -> x.getAge() > 25));
part.forEach((k, v) -> System.out.println("键:" + k + " 值: " + v));
}
}
class Person {
private String name;
private int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public int getAge() {
return age;
}
@Override
public String toString() {
return "Person{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}
Collectors的joining
package com.liudashuai;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
import java.util.stream.Collectors;
public class Test {
public static void main(String[] args) {
List<Person> personList = new ArrayList<>();
personList.add(new Person("Ram", 33));
personList.add(new Person("Shyam", 25));
personList.add(new Person("Shiv", 20));
personList.add(new Person("Mahesh", 30));
// 可以写一个分隔符
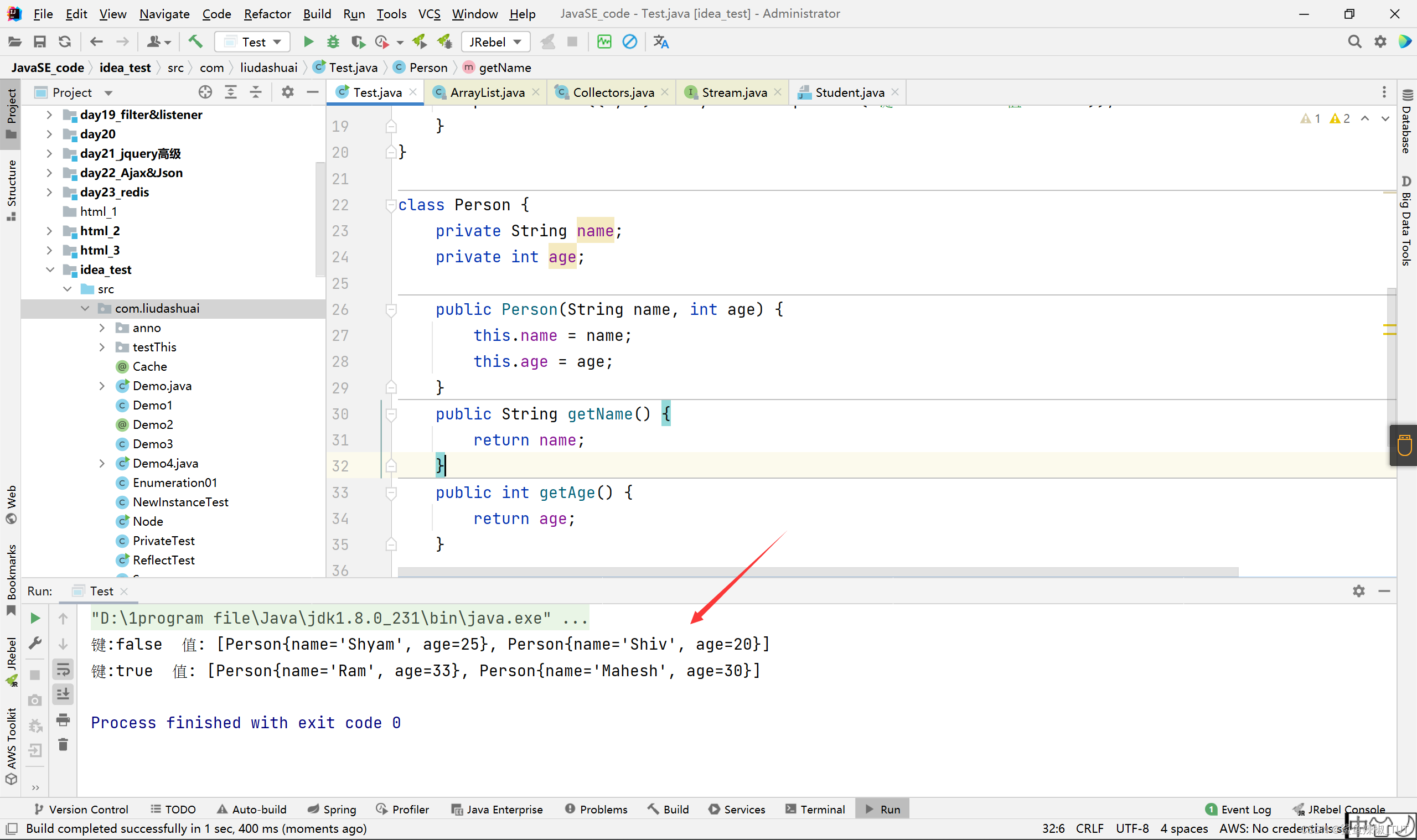
String collect = personList.stream().map(Person::getName).collect(Collectors.joining(" "));
System.out.println("所有员工的姓名(中间用空格隔开):"+collect);
//可以写前缀、后缀、分隔符都写
List<String> list = Arrays.asList("A", "B", "C");
String string = list.stream().collect(Collectors.joining("+","#","@"));
System.out.println("拼接后的字符串:" + string);
}
}
class Person {
private String name;
private int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public int getAge() {
return age;
}
@Override
public String toString() {
return "Person{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}
Collectors的reducing
reducing的重载有三个:
-
一个参数的
javapublic static <T> Collector<T, ?, Optional<T>> reducing(BinaryOperator<T> op)参数说明:
BinaryOperator op 归集操作函数 输入参数T返回T
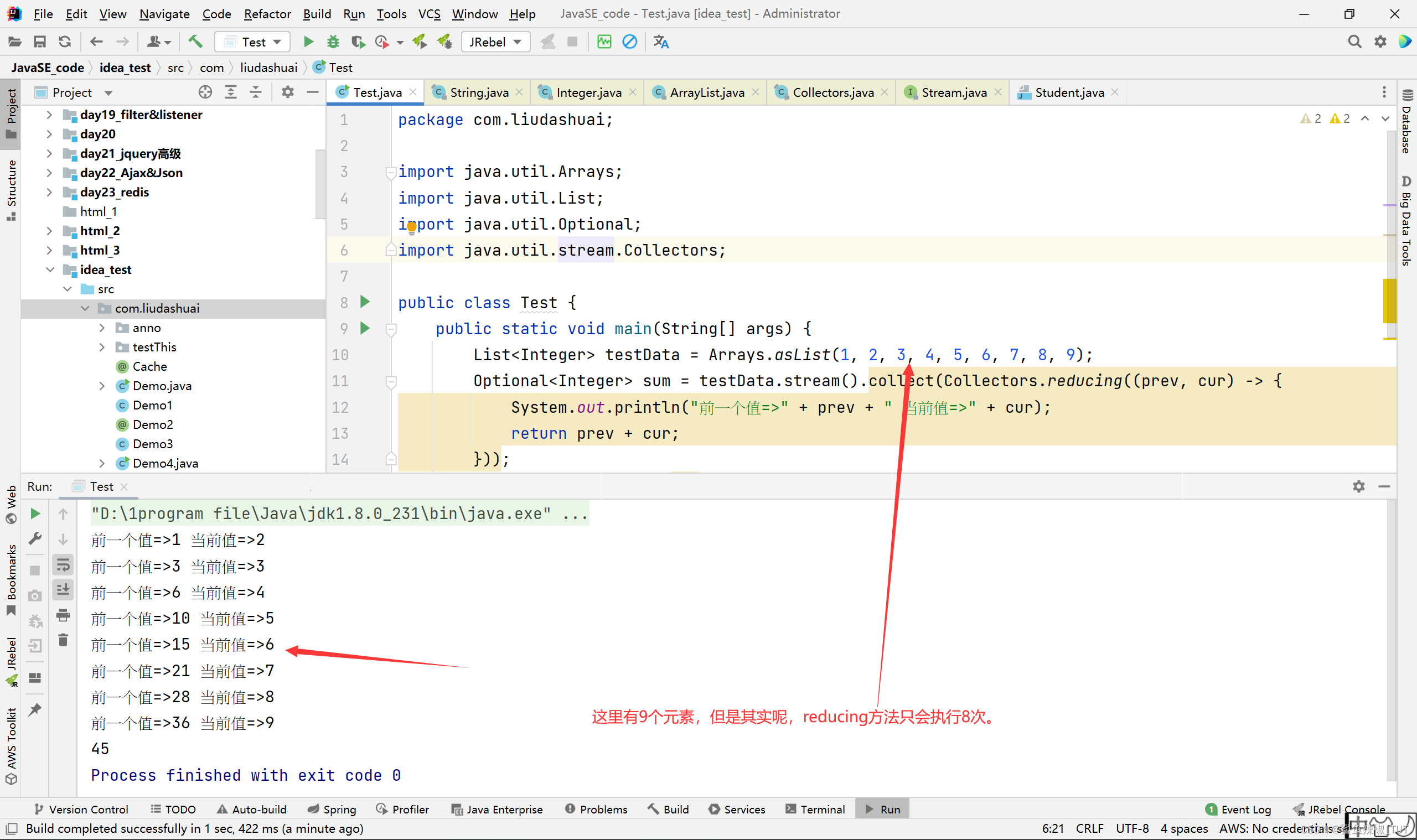
例子:我们这里实现一个简单的求和功能
package com.liudashuai; import java.util.Arrays; import java.util.List; import java.util.Optional; import java.util.stream.Collectors; public class Test { public static void main(String[] args) { List<Integer> testData = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9); Optional<Integer> sum = testData.stream().collect(Collectors.reducing((prev, cur) -> { System.out.println("前一个值=>" + prev + " 当前值=>" + cur); return prev + cur; })); System.out.print(sum.get()); // 45 } }效果:
-
两个参数的
public static <T> Collector<T, ?, T> reducing(T identity, BinaryOperator<T> op)参数说明:
T identity 返回类型T初始值
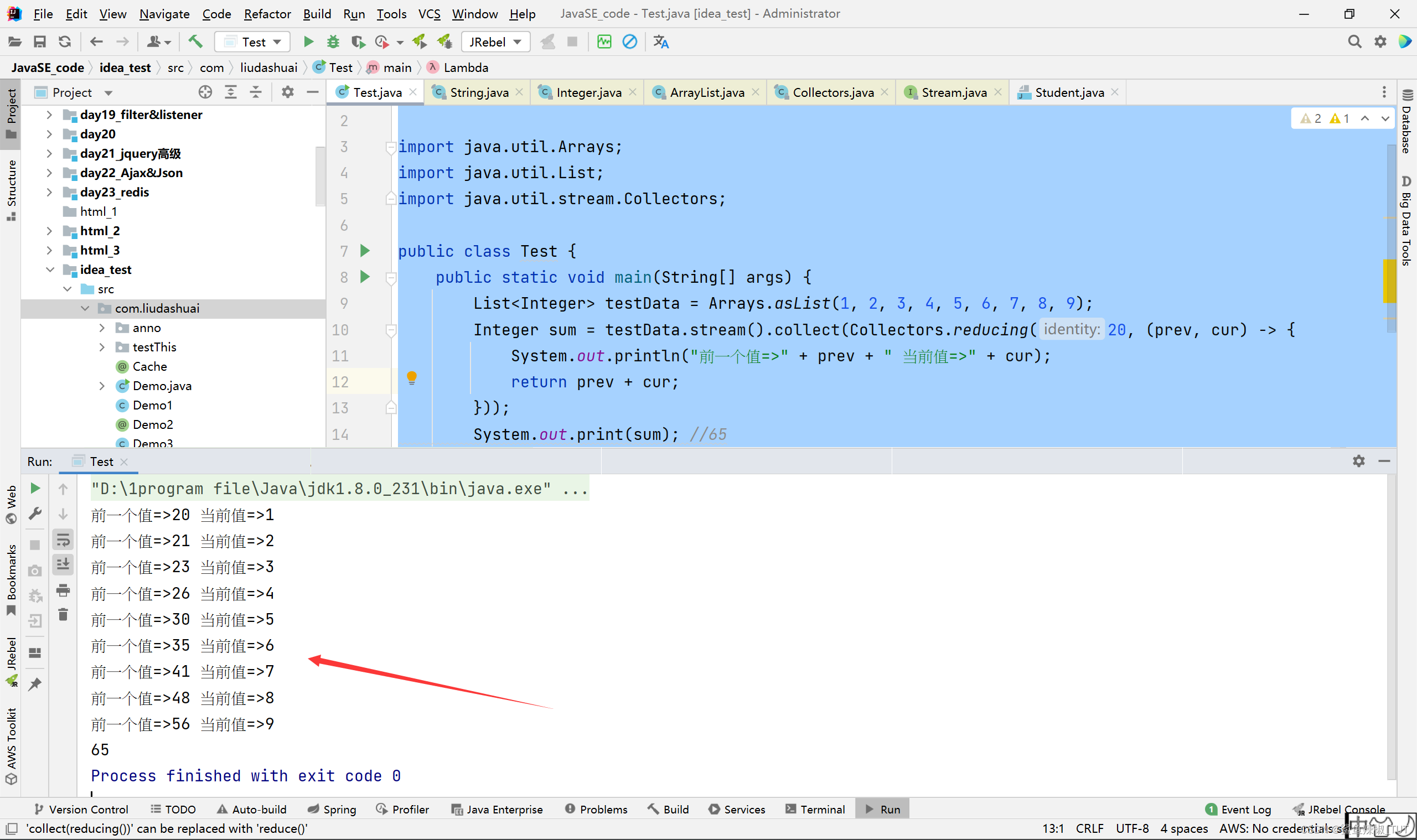
BinaryOperator op 归集操作函数 输入参数T返回T例子:我们这里实现一个简单的求和且加上20的功能
package com.liudashuai; import java.util.Arrays; import java.util.List; import java.util.stream.Collectors; public class Test { public static void main(String[] args) { List<Integer> testData = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9); Integer sum = testData.stream().collect(Collectors.reducing(20, (prev, cur) -> { System.out.println("前一个值=>" + prev + " 当前值=>" + cur); return prev + cur; })); System.out.print(sum); //65 } }效果(看到初始值为20,这里执行了9次reducing方法):
-
三个参数的
public static <T, U> Collector<T, ?, U> reducing(U identity,Function<? super T, ? extends U> mapper,BinaryOperator<U> op)这个函数才是真正体现reducing(归集)的过程。调用者要明确知道以下三个点:
- 需要转换类型的初始值
- 类型如何转换
- 如何收集返回值
参数说明:
U identity 最终返回类型U初始值
Function<? super T, ? extends U> mapper 将输入参数T转换成返回类型U的函数
BinaryOperator op 归集操作函数 输入参数U返回U例子:我们这里实现一个简单数字转字符串并按逗号进行拼接的功能
package com.liudashuai; import java.util.Arrays; import java.util.List; import java.util.stream.Collectors; public class Test { public static void main(String[] args) { List<Integer> testData = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9); String joinStr = testData.stream().collect(Collectors.reducing("转换成字符串", in -> { return in + ""; }, (perv, cur) -> { return perv + "," + cur; })); System.out.print(joinStr); // 转换成字符串,1,2,3,4,5,6,7,8,9 } }效果:
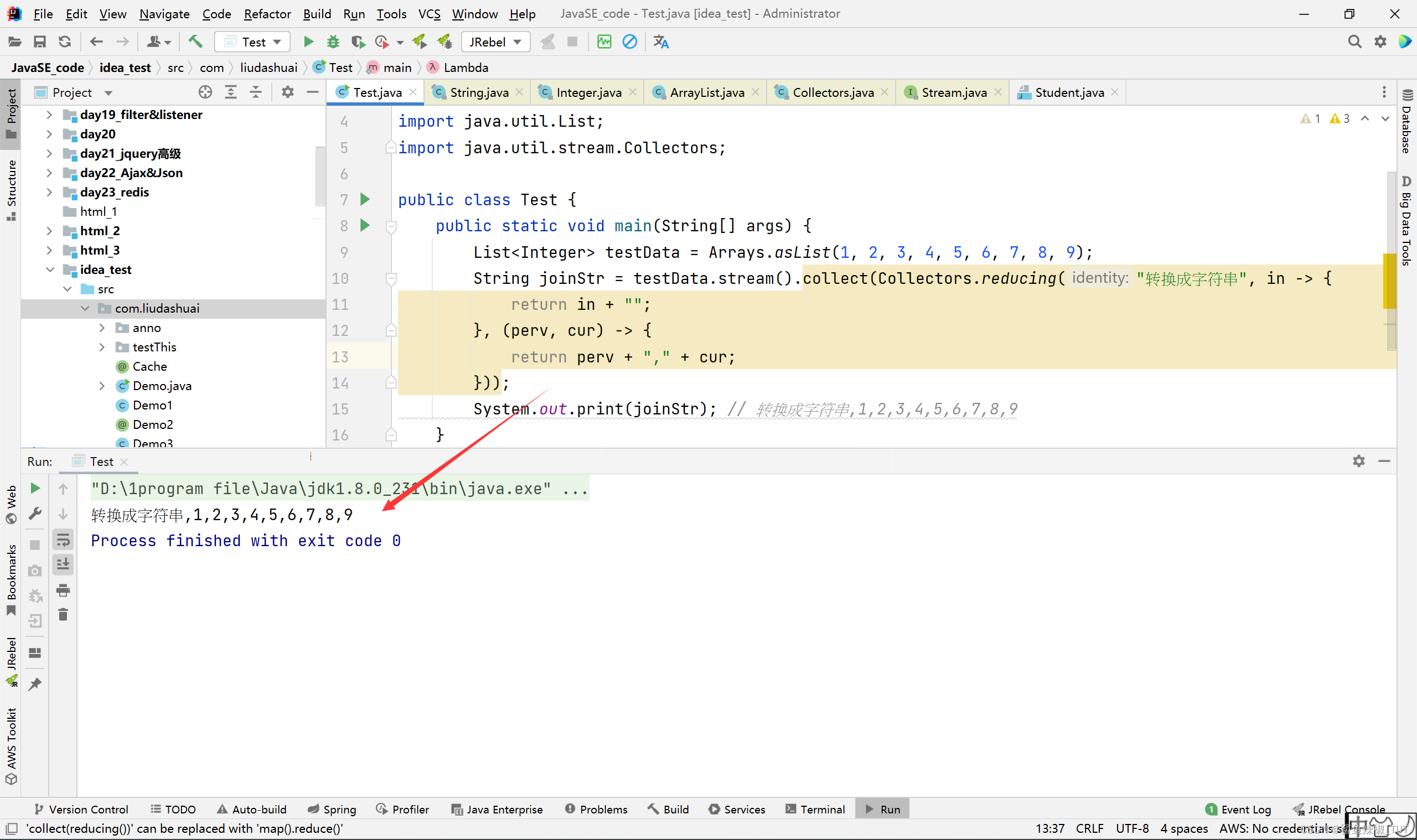
更多例子:
package com.liudashuai;
import java.util.ArrayList;
import java.util.List;
import java.util.Optional;
import java.util.stream.Collectors;
public class Test {
public static void main(String[] args) {
List<Person> personList = new ArrayList<Person>();
personList.add(new Person("Tom", 8900, 23, "male", "New York"));
personList.add(new Person("Jack", 7000, 25, "male", "Washington"));
personList.add(new Person("Lily", 7800, 21, "female", "Washington"));
// 每个员工工资减去2000住宿费后的薪资就是公司要支付的钱
Integer sum = personList.stream().collect(Collectors.reducing(0, Person::getSalary, (i, j) -> (i + j - 2000)));
System.out.println("公司总共要付工资:" + sum);
// stream的reduce
Optional<Integer> sum2 = personList.stream().map(Person::getSalary).reduce(Integer::sum);
System.out.println("员工不算住宿的薪资总和:" + sum2.get());
}
}
class Person {
private String name; // 姓名
private int salary; // 薪资
private int age; // 年龄
private String sex; //性别
private String area; // 地区
// 构造方法
public Person(String name, int salary, int age,String sex,String area) {
this.name = name;
this.salary = salary;
this.age = age;
this.sex = sex;
this.area = area;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getSalary() {
return salary;
}
public void setSalary(int salary) {
this.salary = salary;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public String getSex() {
return sex;
}
public void setSex(String sex) {
this.sex = sex;
}
public String getArea() {
return area;
}
public void setArea(String area) {
this.area = area;
}
@Override
public String toString() {
return "Person{" +
"name='" + name + '\'' +
", salary=" + salary +
", age=" + age +
", sex='" + sex + '\'' +
", area='" + area + '\'' +
'}';
}
}
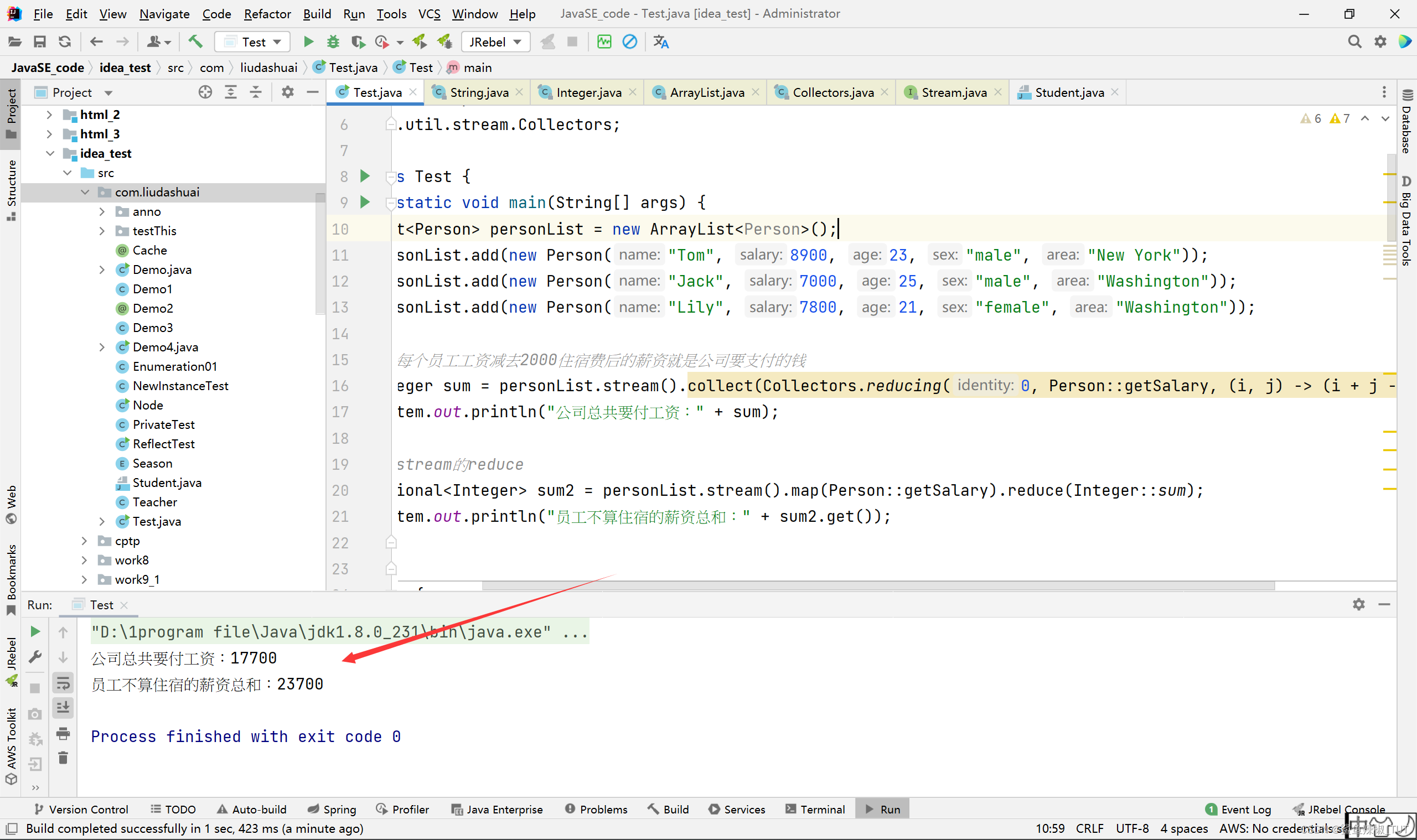
reducing和reduce的区别
Stream流有一个reduce方法,Stream流的collect方法的参数还有一个常用的Collectors.reducing方法。他们的效果都差不多。reduce是减少的意思,此处意为聚合,即聚拢、合并的意思。
他们效果差不多,那么他们有什么区别呢?
下面我们来看看两个方法的区别吧。
-
只有一个参数的reducing和reduce方法的区别。一个参数的Collectors.reducing(Integer::sum)或者reduce(Integer::sum)返回的都是一个Optional对象。因为reducing或者reduce的结果可能是null。Optional是一个可以为null的容器对象,它的主要作用就是为了避免Null检查,防止NullpointerException,如果Stream的reduce或者reducing方法不是返回一个Optional对象,那么聚合的时候,就可能出现空指针异常,所以,这里java设计reduce或者reducing方法返回一个Optional对象。
package com.liudashuai; import java.util.Optional; import java.util.stream.Collectors; import java.util.stream.Stream; public class Test { public static void main(String[] args) { Optional<Integer> sumOpt = Stream.iterate(0, i -> ++i).limit(10).collect(Collectors.reducing(Integer::sum)); System.out.println(sumOpt); // 打印:Optional[45] sumOpt = Stream.iterate(0, i -> ++i).limit(10).reduce(Integer::sum); System.out.println(sumOpt); // 打印:Optional[45] } }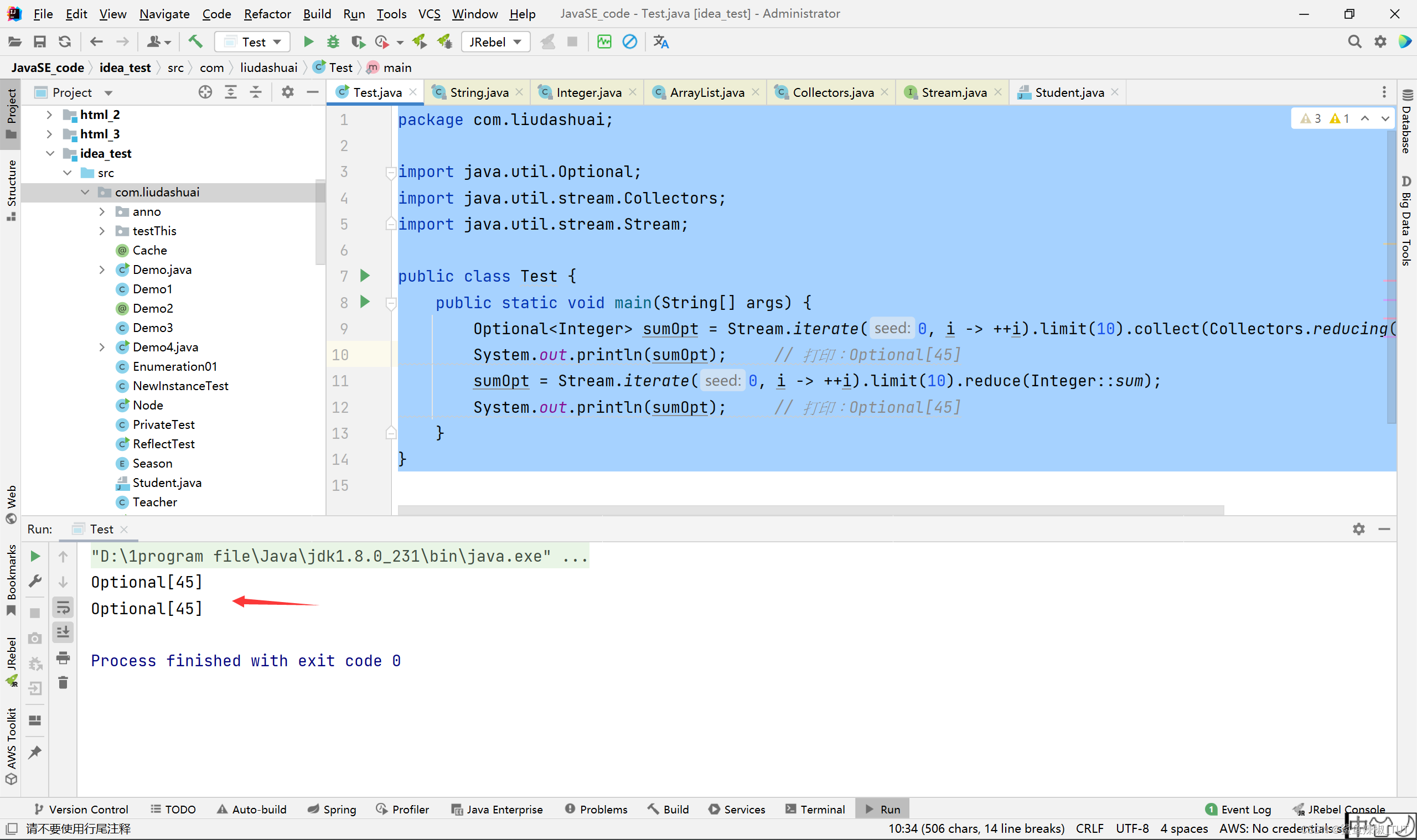
比如:
package com.liudashuai; import java.util.Optional; import java.util.stream.Collectors; import java.util.stream.Stream; public class Test { public static void main(String[] args) { Optional<Integer> sumOpt = Stream.iterate(0, i -> ++i).limit(0).collect(Collectors.reducing(Integer::sum)); System.out.println(sumOpt); // 打印:Optional[45] sumOpt = Stream.iterate(0, i -> ++i).limit(0).reduce(Integer::sum); System.out.println(sumOpt); // 打印:Optional[45] } }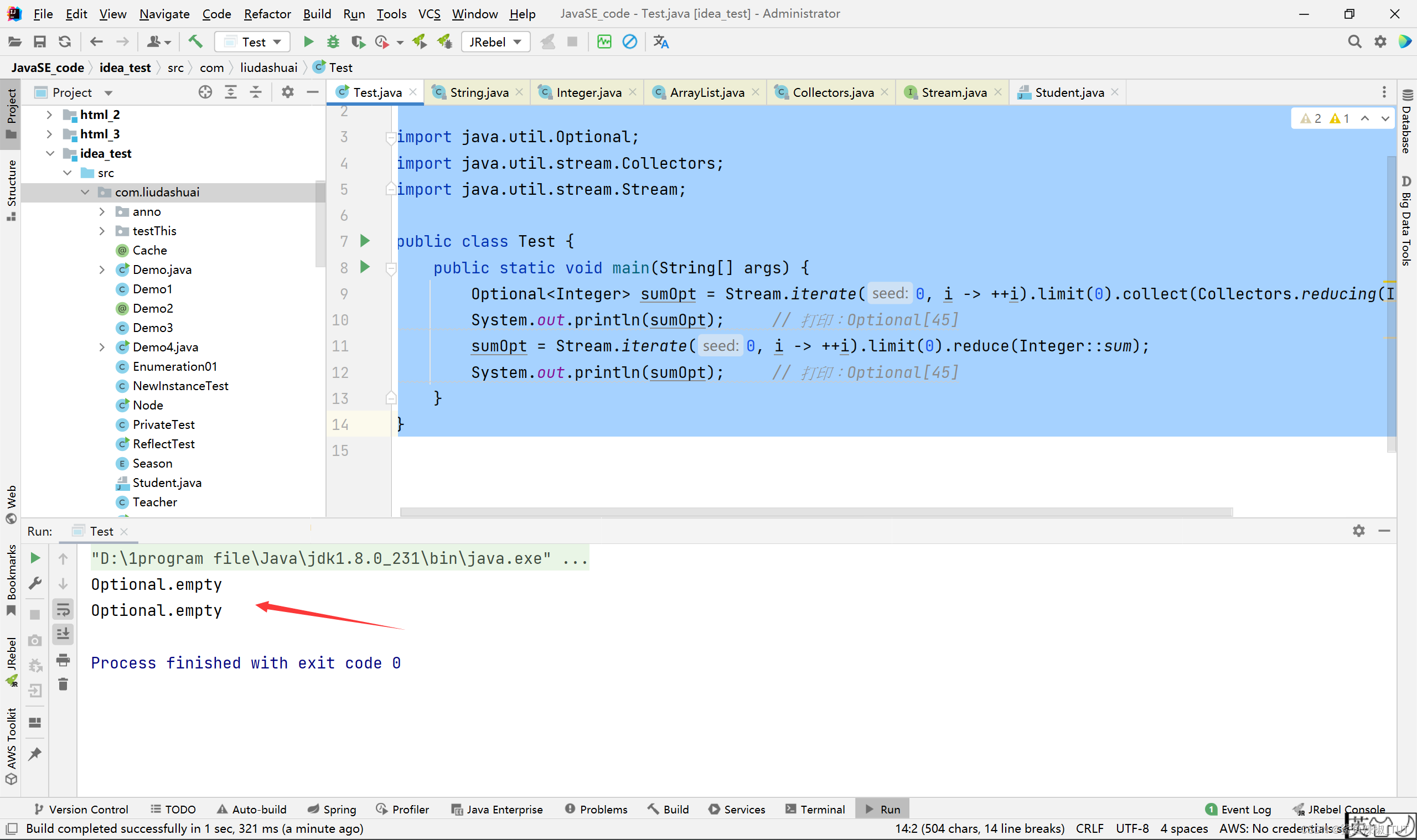
如果要获取Optional中的reduce或者reducing的结果。
我们可以这样:
package com.liudashuai; import java.util.Optional; import java.util.stream.Collectors; import java.util.stream.Stream; public class Test { public static void main(String[] args) { Optional<Integer> sumOpt = Stream.iterate(0, i -> ++i).limit(10).collect(Collectors.reducing(Integer::sum)); System.out.println(sumOpt.get()); sumOpt = Stream.iterate(0, i -> ++i).limit(10).reduce(Integer::sum); System.out.println(sumOpt.get()); } }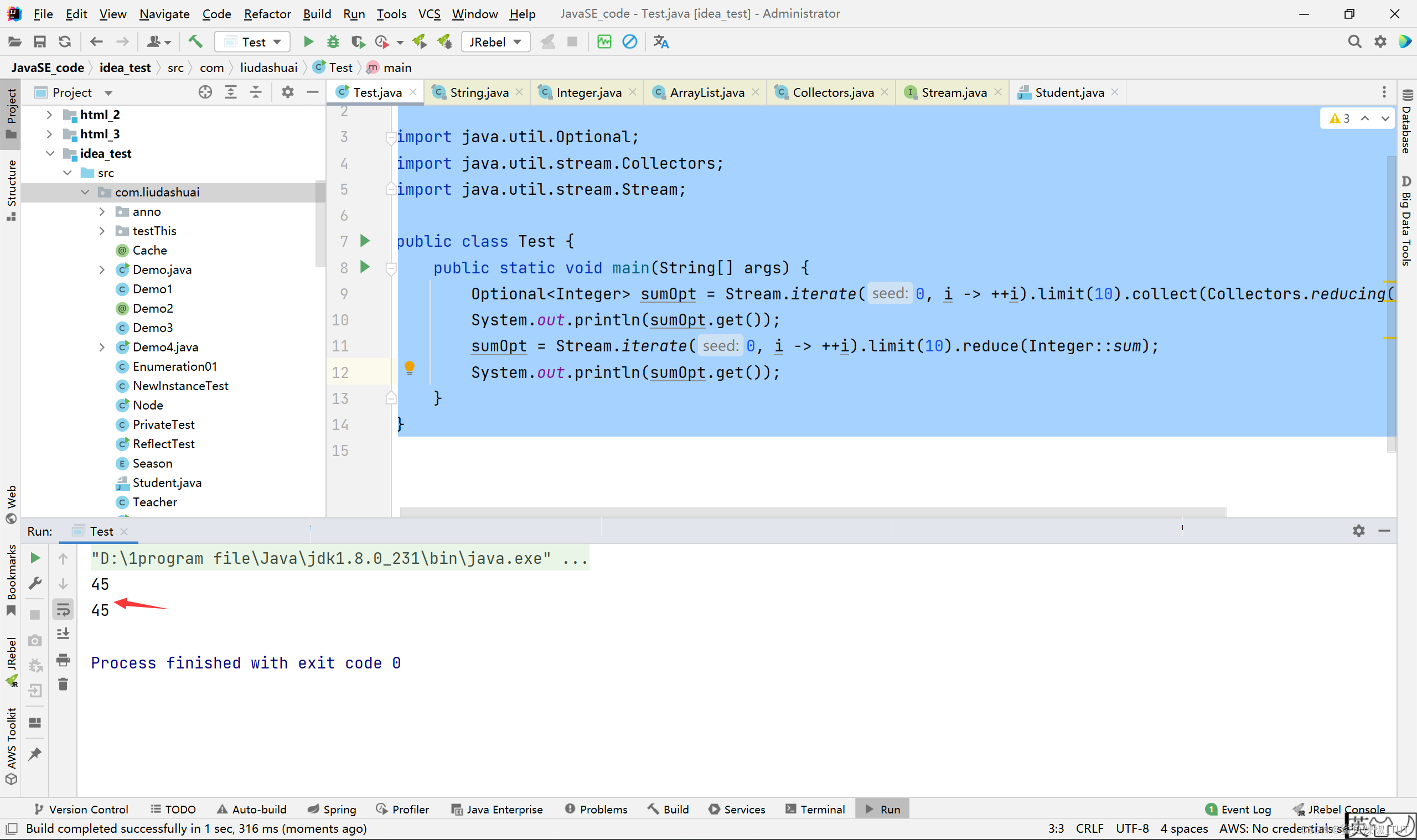
-
两个参数的reducing和reduce方法的区别,效果都是默认值+累加后的结果
package com.liudashuai; import java.util.stream.Collectors; import java.util.stream.Stream; public class Test { public static void main(String[] args) { Integer sum = Stream.iterate(0, i -> ++i).limit(10).collect(Collectors.reducing(10, Integer::sum)); System.out.println(sum); // 55 sum = Stream.iterate(0, i -> ++i).limit(10).reduce(10, Integer::sum); System.out.println(sum); // 55 } }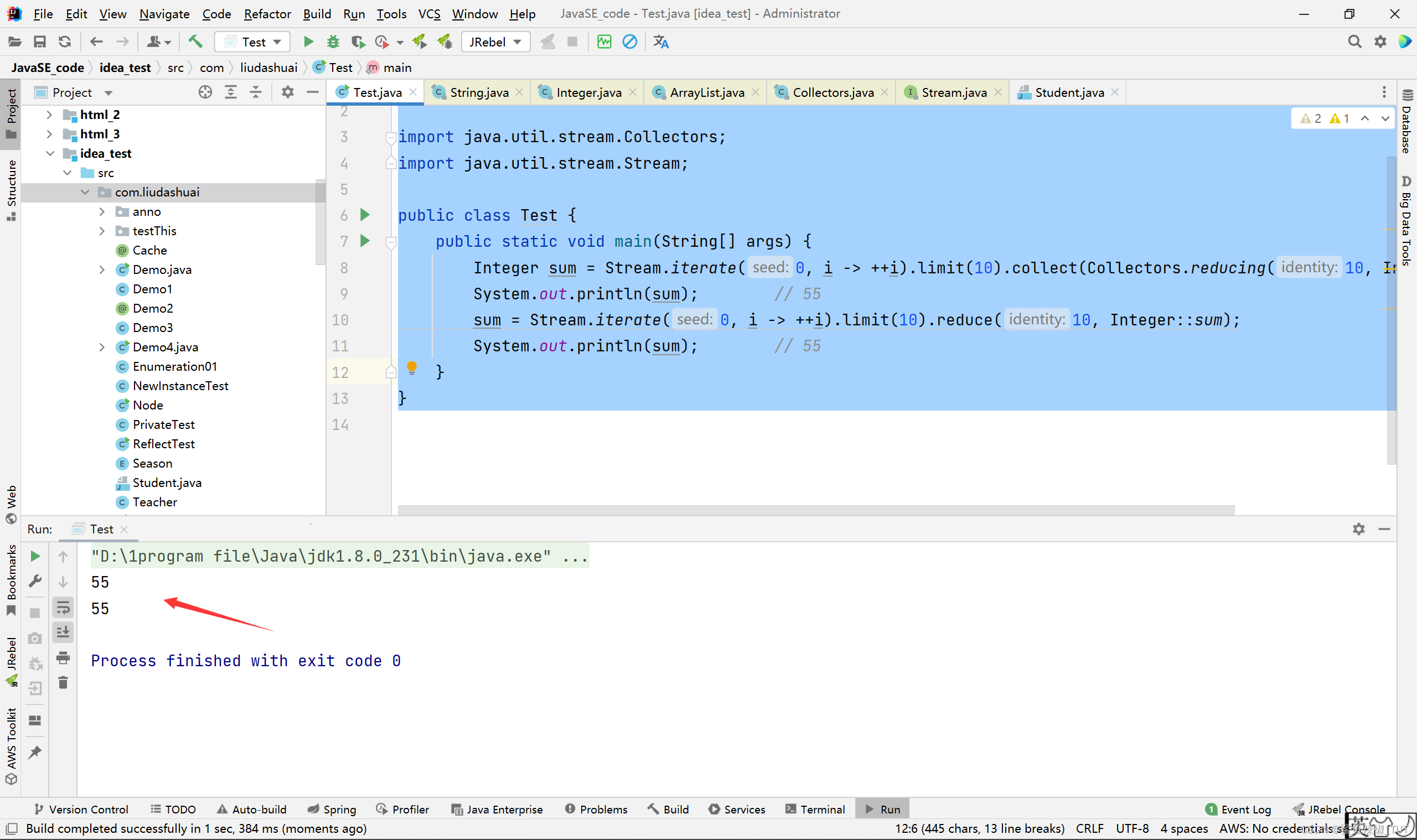
这里两个参数的reducing和reduce方法,因为有初始值,所以,结果不会是空值,所以java设计reducing和reduce两个参数的方法的时候就没有设计返回Optional了。
package com.liudashuai; import java.util.stream.Collectors; import java.util.stream.Stream; public class Test { public static void main(String[] args) { Integer sum = Stream.iterate(0, i -> ++i).limit(0).collect(Collectors.reducing(99, Integer::sum)); System.out.println(sum); sum = Stream.iterate(0, i -> ++i).limit(0).reduce(22, Integer::sum); System.out.println(sum); } }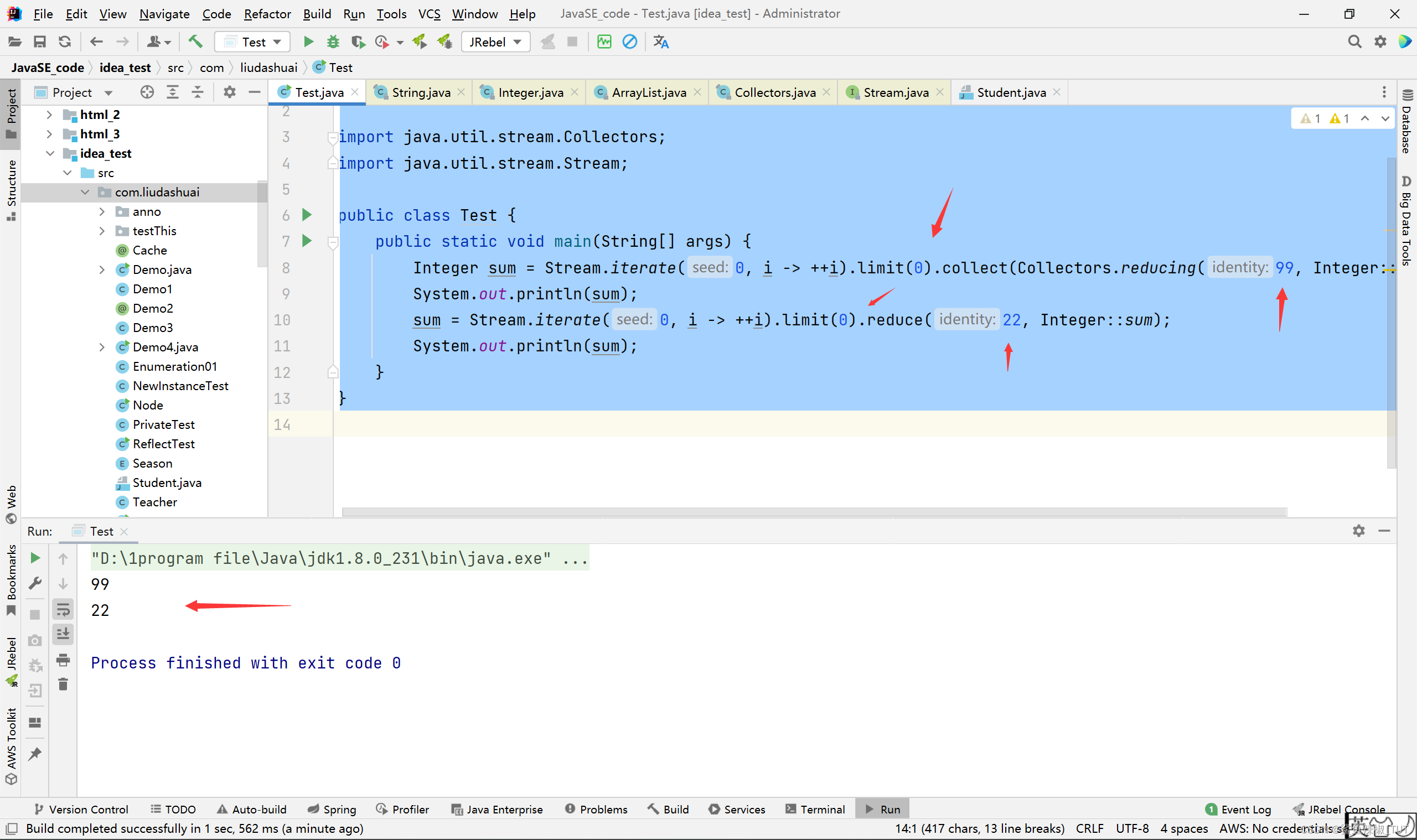
前面两种方式效果都是一样的。reducing和reduce方法的不同点在与三个参数的这个方法。
-
下面是三个参数的。第一个参数还是默认值,第二个参数和第三个参数就有区别了。
package com.liudashuai; import java.math.BigDecimal; import java.util.stream.Collectors; import java.util.stream.Stream; public class Test { public static void main(String[] args) { BigDecimal sumDecimal = Stream.iterate(0, i -> ++i).limit(10).collect( Collectors.reducing(BigDecimal.ZERO, BigDecimal::new, BigDecimal::add)); System.out.println(sumDecimal); // 45 sumDecimal = Stream.iterate(0, i -> ++i).limit(10) .reduce(BigDecimal.ZERO, (d, i) -> d.add(new BigDecimal(i)), BigDecimal::add); System.out.println(sumDecimal); // 45 } }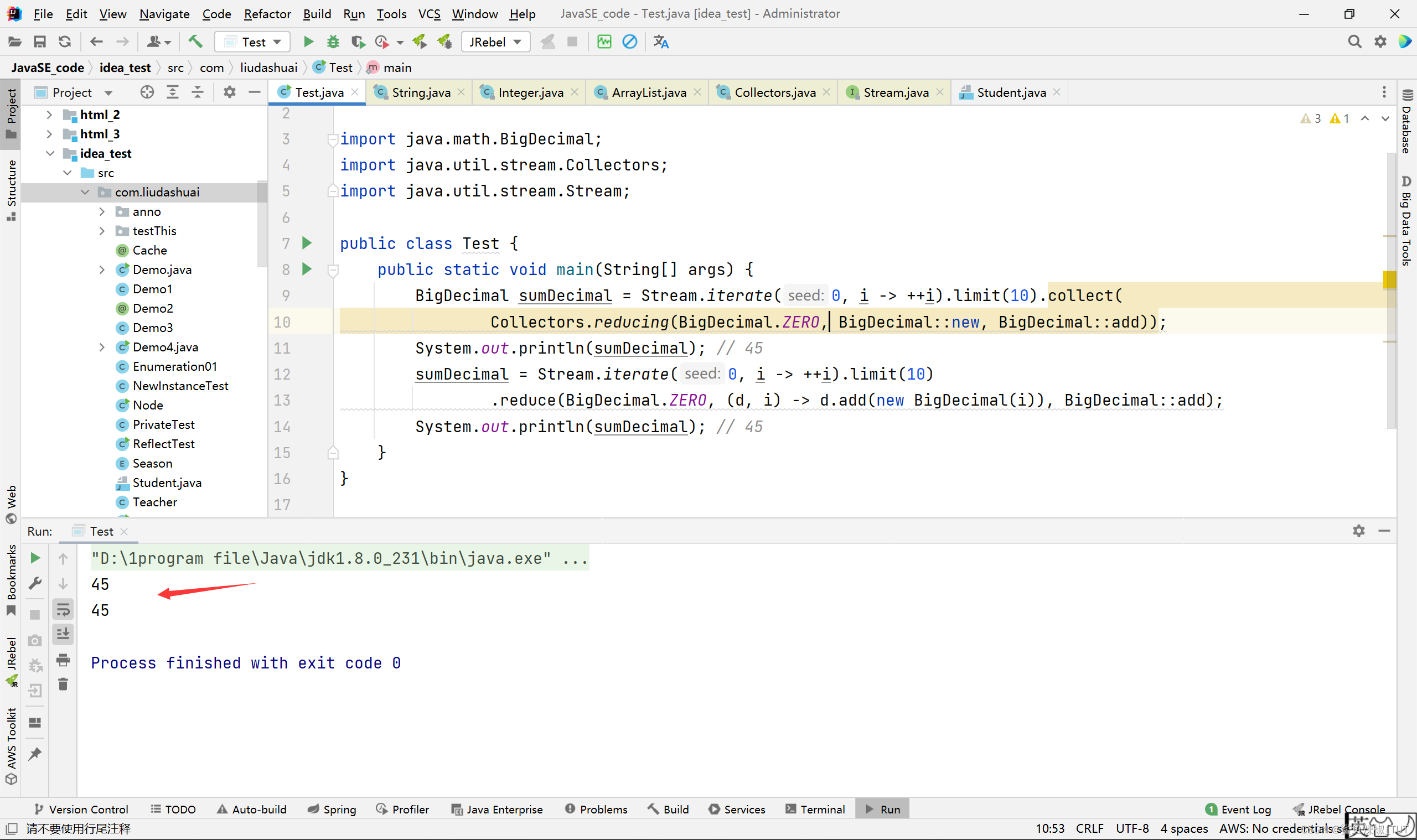
可以看出我们的
Collectors.reducing第二个参数是一个Function<Integer,BigDecimal>。这里第二个参数的对象不是进行聚合运算的,而是进行了一个转换的。第三个参数才是我们的累加操作。Stream#reduce中,第二个参数是一个BiFunction<BigDecimal, Integer, BigDecimal>。第二个参数的对象是用来进行汇总操作的。其中,d表示上一个累加的结果。i表示要当前这轮遍历要进行累加的数。第三个参数是个BinaryOperator<BigDecimal>类型的对象,只在并行流场景下会用到,这里不展开讲,总之就是说,我们在串行流中哪怕将Stream#reduce的第三个参数,改为任意的语句,他都是不影响执行的。package com.liudashuai; import java.math.BigDecimal; import java.util.stream.Collectors; import java.util.stream.Stream; public class Test { public static void main(String[] args) { BigDecimal sumDecimal = Stream.iterate(0, i -> ++i).limit(10).collect( Collectors.reducing(BigDecimal.ZERO, BigDecimal::new, BigDecimal::add)); System.out.println(sumDecimal); // 45 sumDecimal = Stream.iterate(0, i -> ++i).limit(10) .reduce(BigDecimal.ZERO, (d, i) -> { System.out.println(d+" "+i); return d.add(new BigDecimal(i)); }, BigDecimal::add); System.out.println(sumDecimal); // 45 } }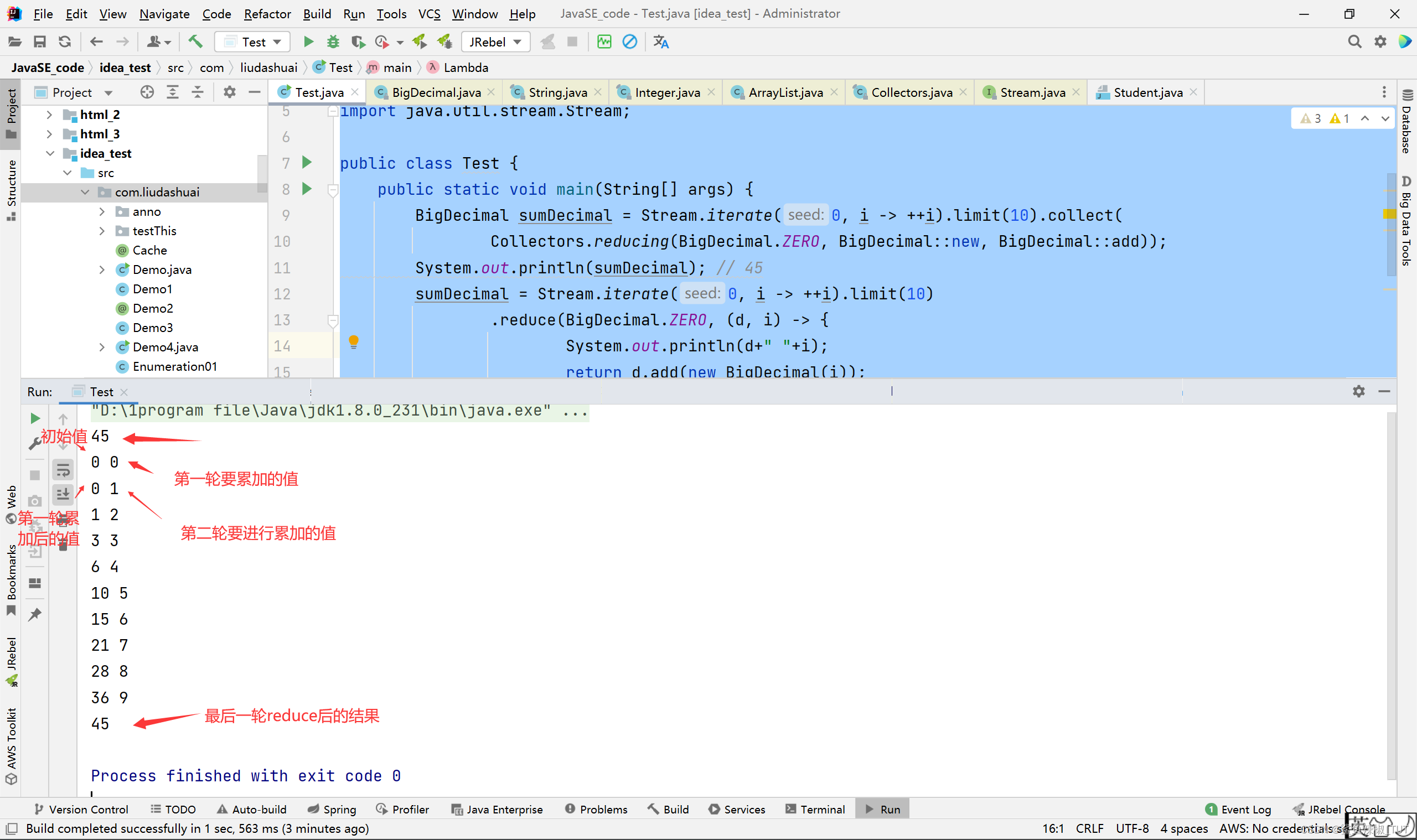
这里我试一下
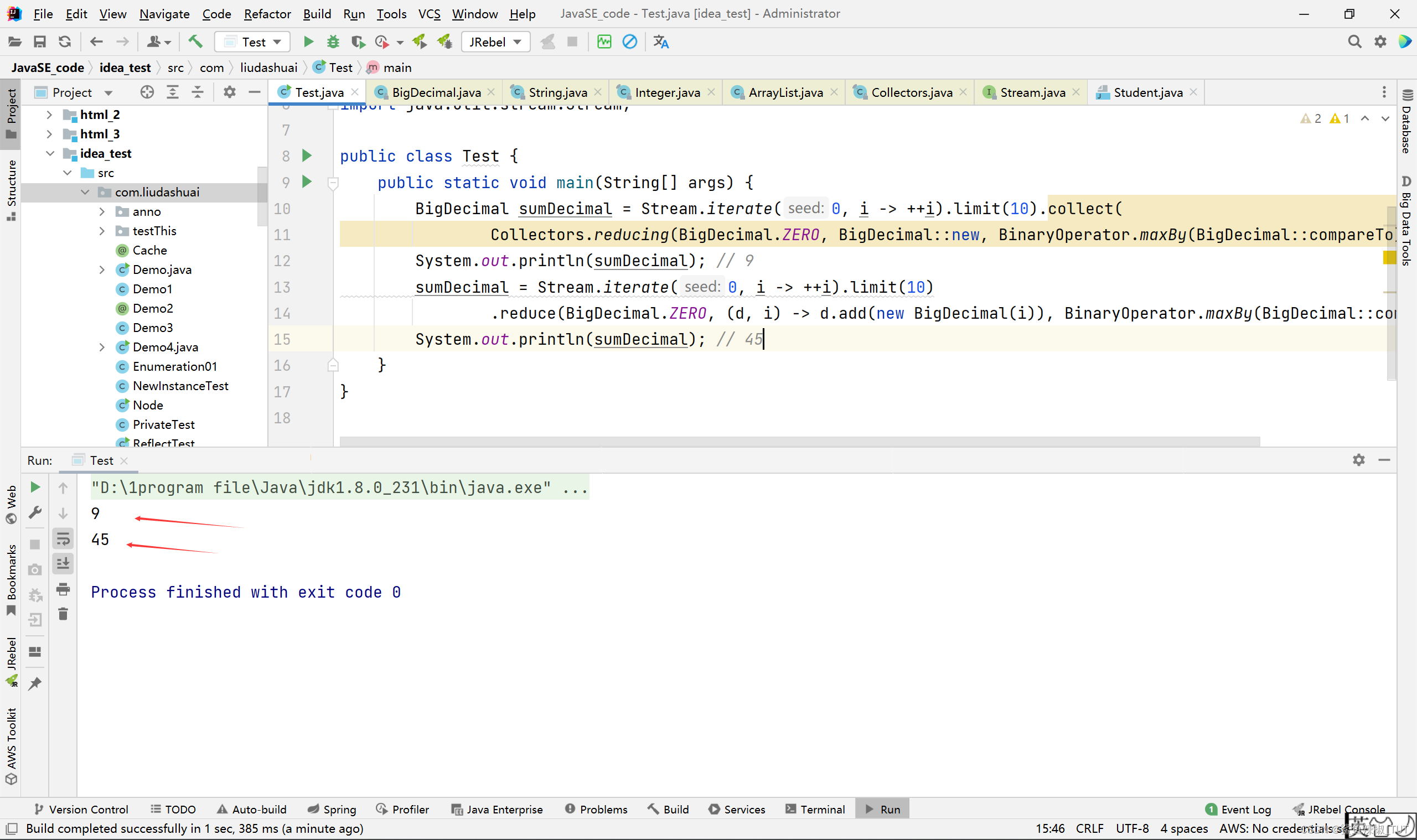
Stream#reduce中的第三个参数。看看到底有没有影响结果。我们在串行流中哪怕将
Stream#reduce的第三个参数,改为任意操作,他都是不影响结果执行的,例如我们这里取最大值:package com.liudashuai; import java.math.BigDecimal; import java.util.function.BinaryOperator; import java.util.stream.Collectors; import java.util.stream.Stream; public class Test { public static void main(String[] args) { BigDecimal sumDecimal = Stream.iterate(0, i -> ++i).limit(10).collect( Collectors.reducing(BigDecimal.ZERO, BigDecimal::new, BinaryOperator.maxBy(BigDecimal::compareTo))); System.out.println(sumDecimal); // 9 sumDecimal = Stream.iterate(0, i -> ++i).limit(10) .reduce(BigDecimal.ZERO, (d, i) -> d.add(new BigDecimal(i)), BinaryOperator.maxBy(BigDecimal::compareTo)); System.out.println(sumDecimal); // 45 } }结果:
哪怕我们改为
null也是不会影响Stream#reduce的执行结果的:package com.liudashuai; import java.math.BigDecimal; import java.util.stream.Collectors; import java.util.stream.Stream; public class Test { public static void main(String[] args) { BigDecimal sumDecimal = Stream.iterate(0, i -> ++i).limit(10).collect( Collectors.reducing(BigDecimal.ZERO, BigDecimal::new, (l, r) -> null)); System.out.println(sumDecimal); // null sumDecimal = Stream.iterate(0, i -> ++i).limit(10) .reduce(BigDecimal.ZERO, (d, i) -> d.add(new BigDecimal(i)), (l, r) -> null); System.out.println(sumDecimal); // 45 } }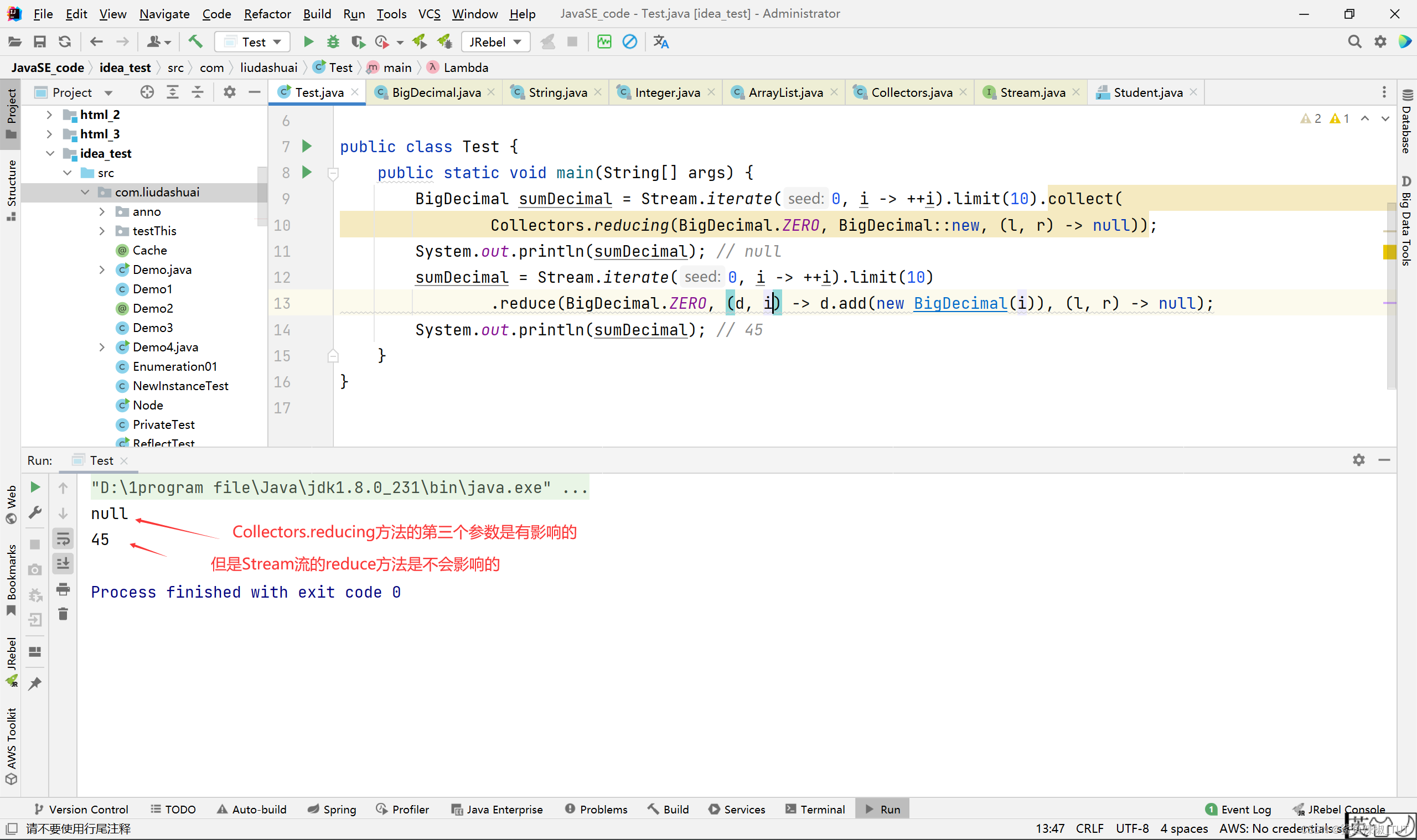
当然哈,这里并没有要求reducing和reduce的几个参数一定要和BigDecimal有关哈。比如下面这样也行的:
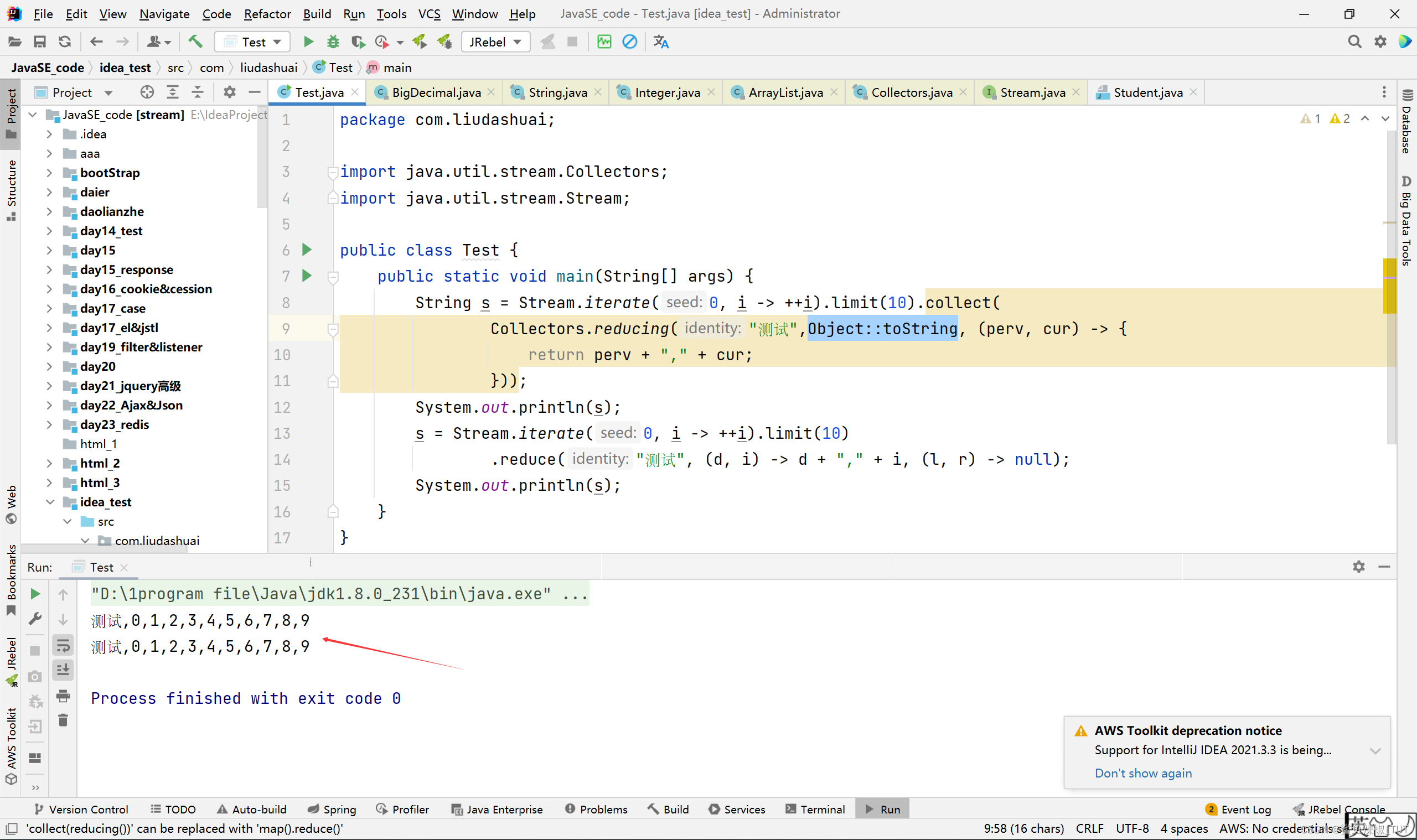
package com.liudashuai; import java.util.stream.Collectors; import java.util.stream.Stream; public class Test { public static void main(String[] args) { String s = Stream.iterate(0, i -> ++i).limit(10).collect( Collectors.reducing("测试",in -> { return Integer.toString(in); }, (perv, cur) -> { return perv + "," + cur; })); System.out.println(s); s = Stream.iterate(0, i -> ++i).limit(10) .reduce("测试", (d, i) -> d + "," + i, (l, r) -> null); System.out.println(s); } }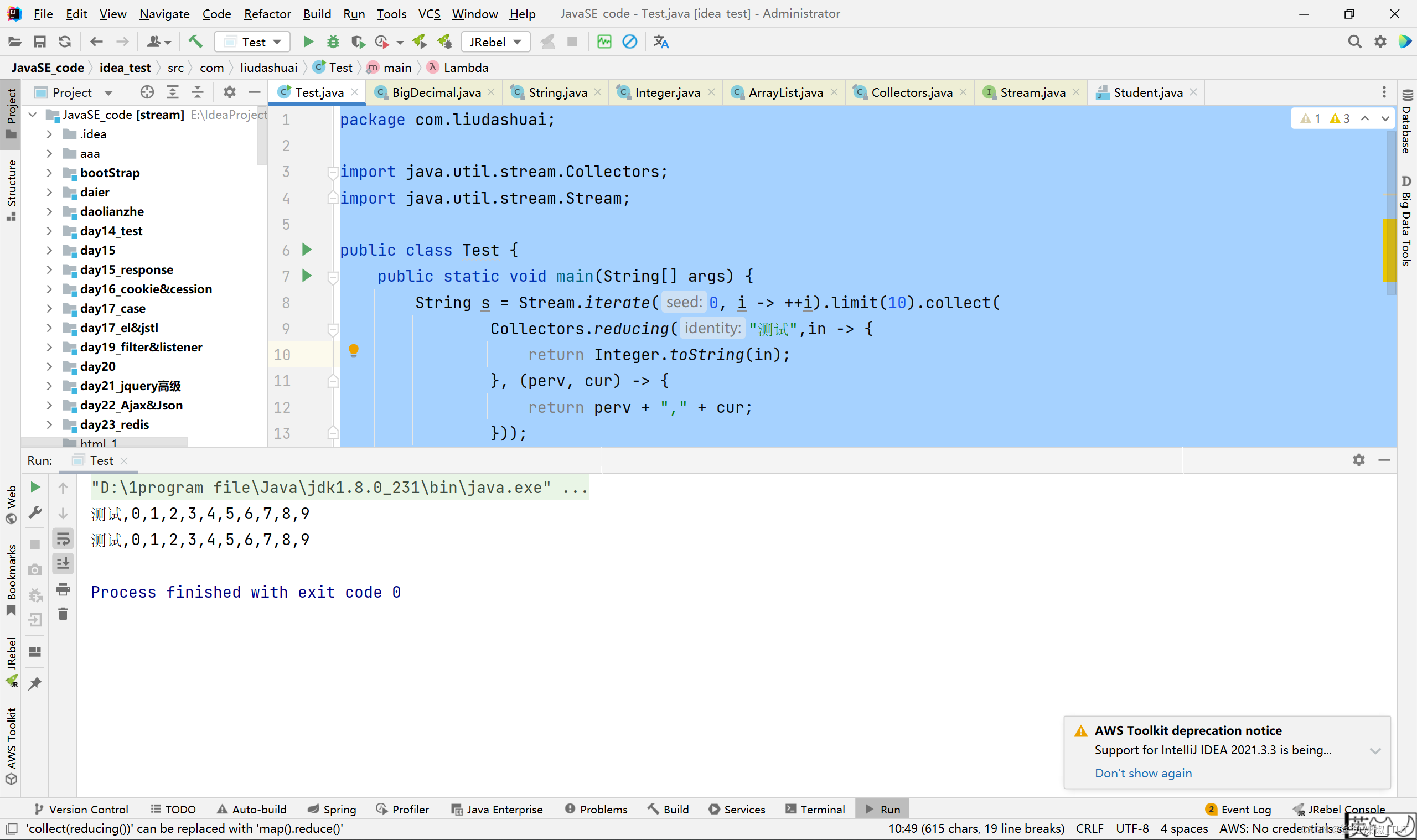
注意:这里不好直接用Integer::toString,因为Integer中的多个toString都可能会匹配到Integer::toString,方法引用表达式Integer::toString可以表示引用Integer类的toString静态方法Functionf=t->Integer.toString(t)也可以表示引用任意Integer实例的toString成员方法Functionf=t->t.toString()编译器无法判断应该使用哪个解释。具体可以看https://www.imooc.com/article/22608。
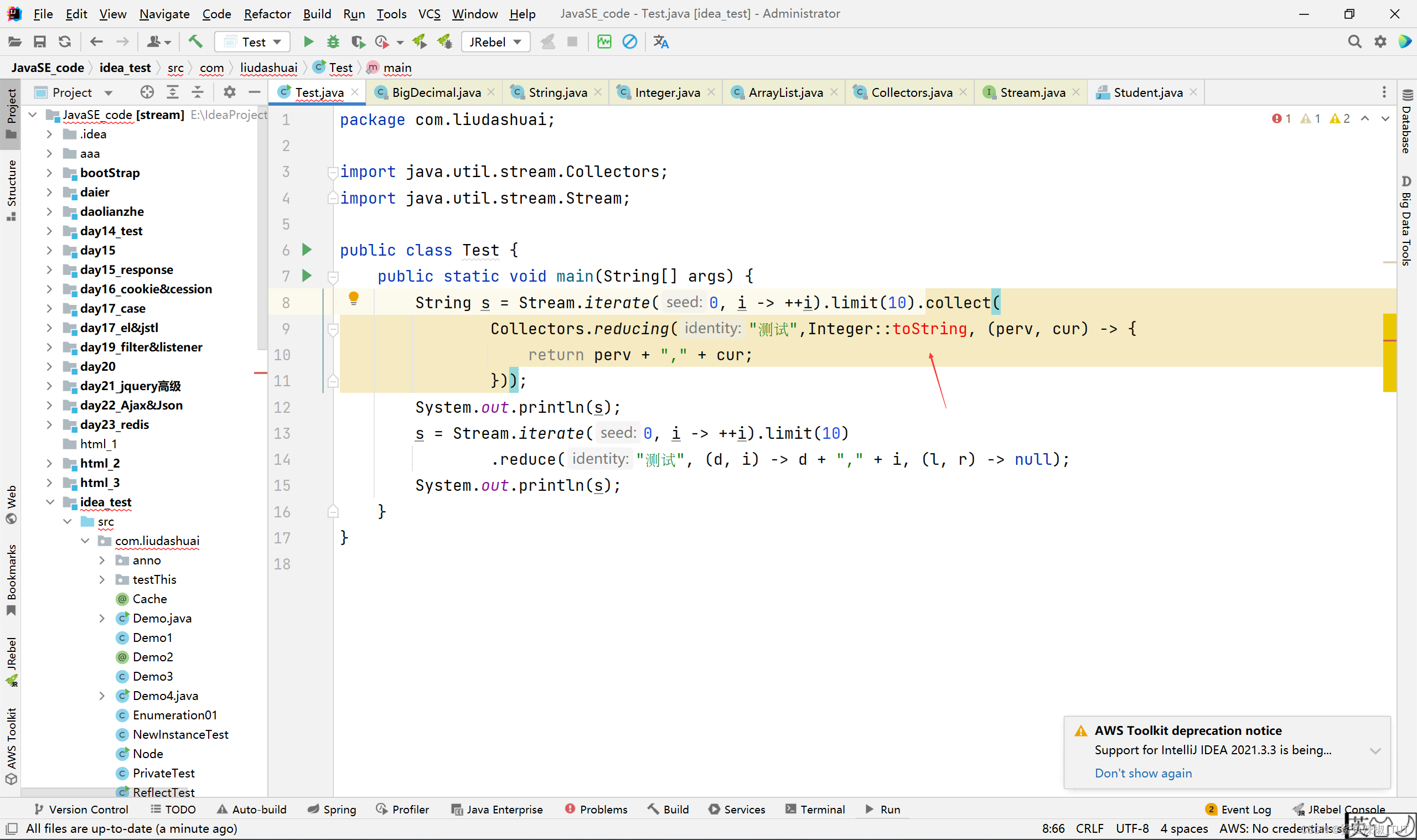
当然哈,Object::toString可以,因为Object中没有多个可能和Object::toString这个方法引用匹配的方法。
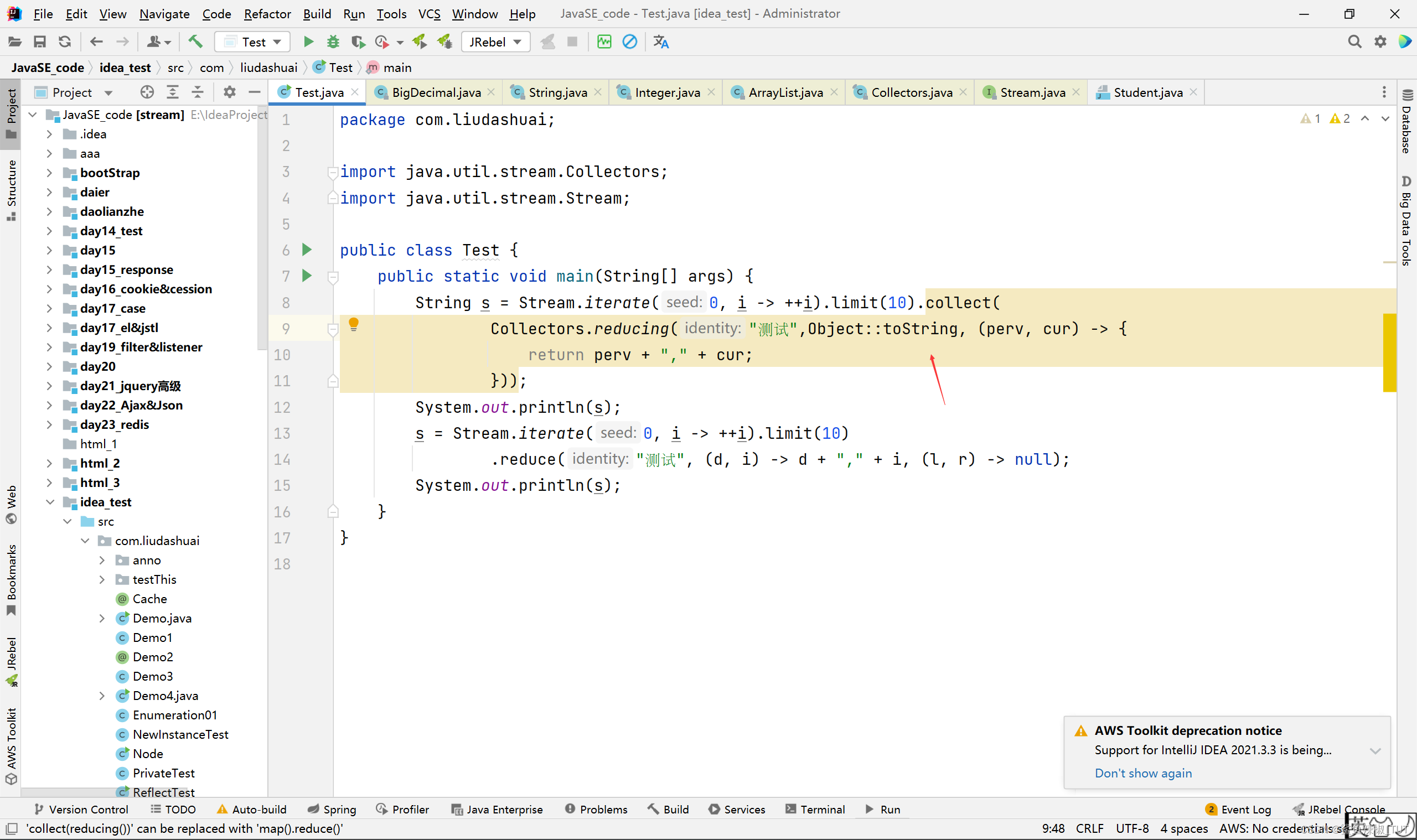
结果:
Collectors的toCollection
Collectors.toCollection(Supplier<C> collectionFactory) 方法是 Java 中 Collectors 类提供的一个用于将流中的元素收集到指定类型的集合中的方法。
该方法接受一个参数,即一个类型为 Supplier<C> 的函数式接口,其中 C 是要创建的集合类型。例如,如果我们想要创建一个 LinkedList 集合,可以这样使用该方法:
List<Integer> list = Stream.of(1, 2, 3, 4, 5)
.collect(Collectors.toCollection(LinkedList::new));
在上述示例中,我们使用 Collectors.toCollection() 方法,并传入一个 LinkedList::new 函数,表示创建一个 LinkedList 类型的集合对象。然后把流中的数据都放到这个LinkedList对象里面去。
使用Collectors的toCollection的好处是,比较灵活,我们可以随便指定把流放到某个类型的集合里面。你看,如果使用的是Collectors.toList()方法就只能把流中的数据放到List里面去,不能用这个toList方法把流中的数据放到Set或者某个Map里面去。
例子1:
package com.liudashuai;
import java.util.ArrayList;
import java.util.List;
import java.util.stream.Collectors;
import java.util.stream.Stream;
public class Test {
public static void main(String[] args) {
List<Integer> numbers = Stream.of(1,2,3,4,5)
.collect(Collectors.toCollection(ArrayList::new));
numbers.forEach(System.out::println);
}
}
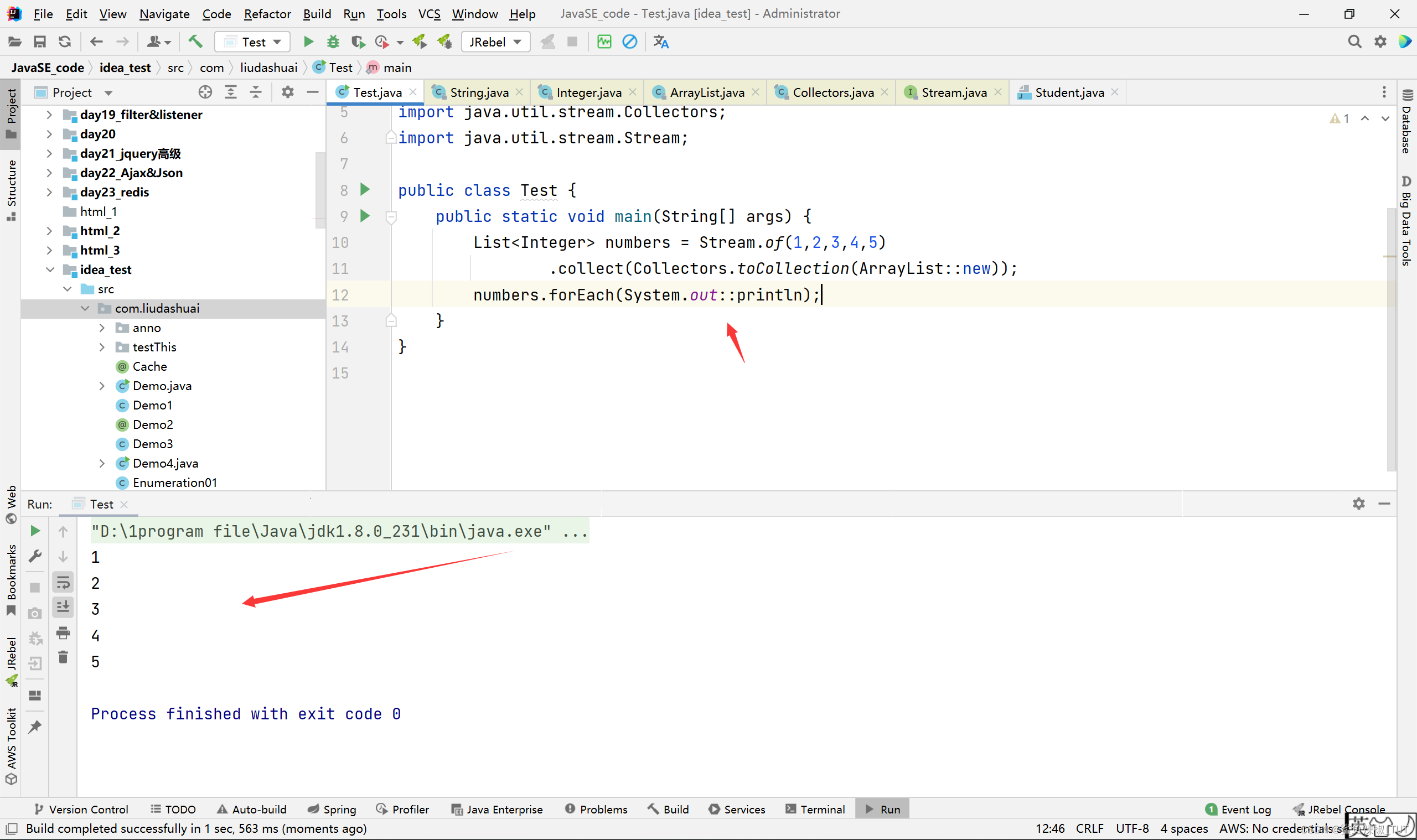
例子2:
package com.liudashuai;
import java.util.TreeSet;
import java.util.stream.Collectors;
import java.util.stream.Stream;
public class Test {
public static void main(String[] args) {
Stream<String> stream = Stream.of("20", "50", "80", "100", "130", "150", "200");
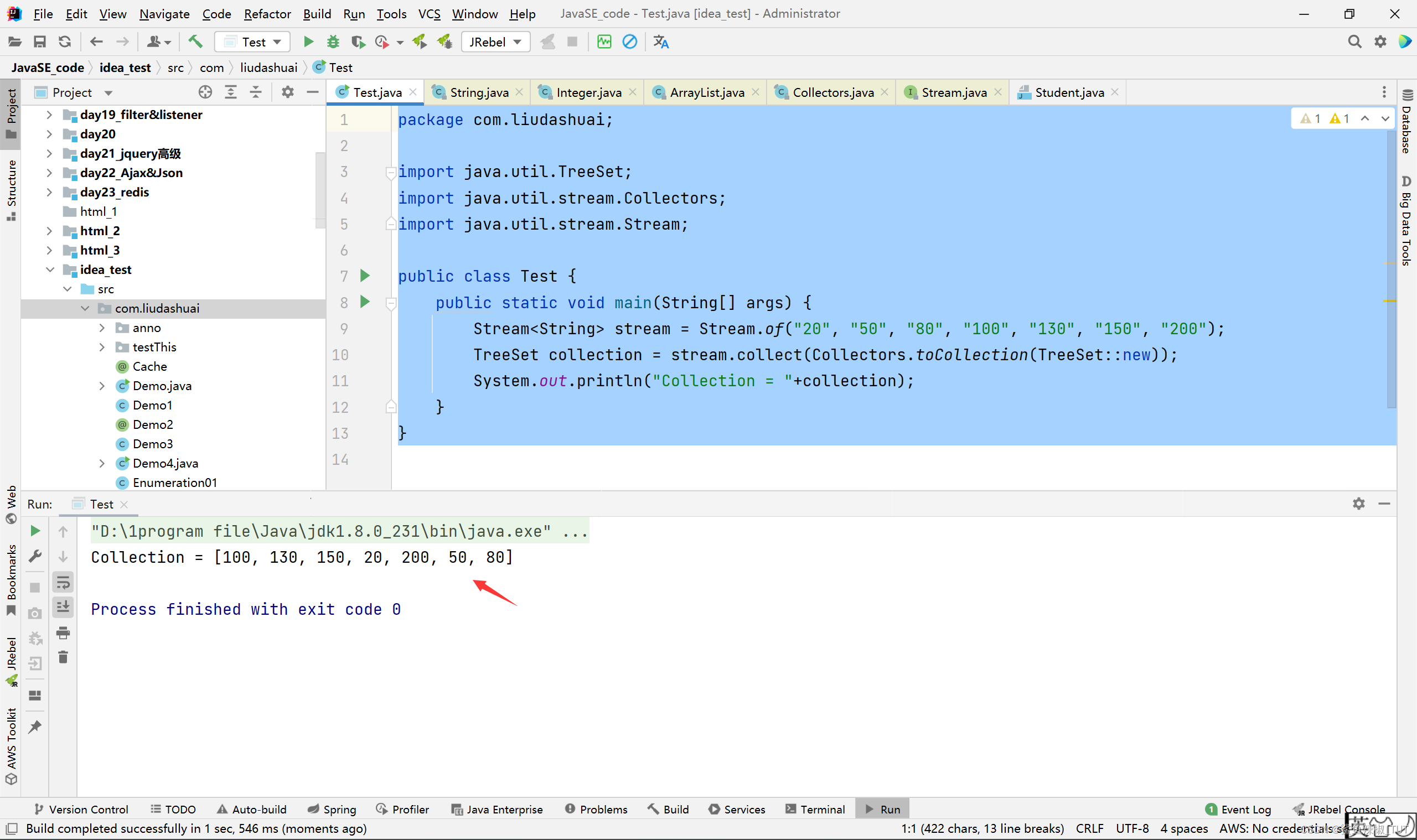
TreeSet collection = stream.collect(Collectors.toCollection(TreeSet::new));
System.out.println("Collection = "+collection);
}
}
例子3:
package com.liudashuai;
import java.util.Arrays;
import java.util.LinkedList;
import java.util.List;
import java.util.TreeSet;
import java.util.concurrent.CopyOnWriteArrayList;
import java.util.stream.Collectors;
import java.util.stream.Stream;
public class Test {
public static void main(String[] args) {
//直接创建treeSet数据 [1, 3, 4]
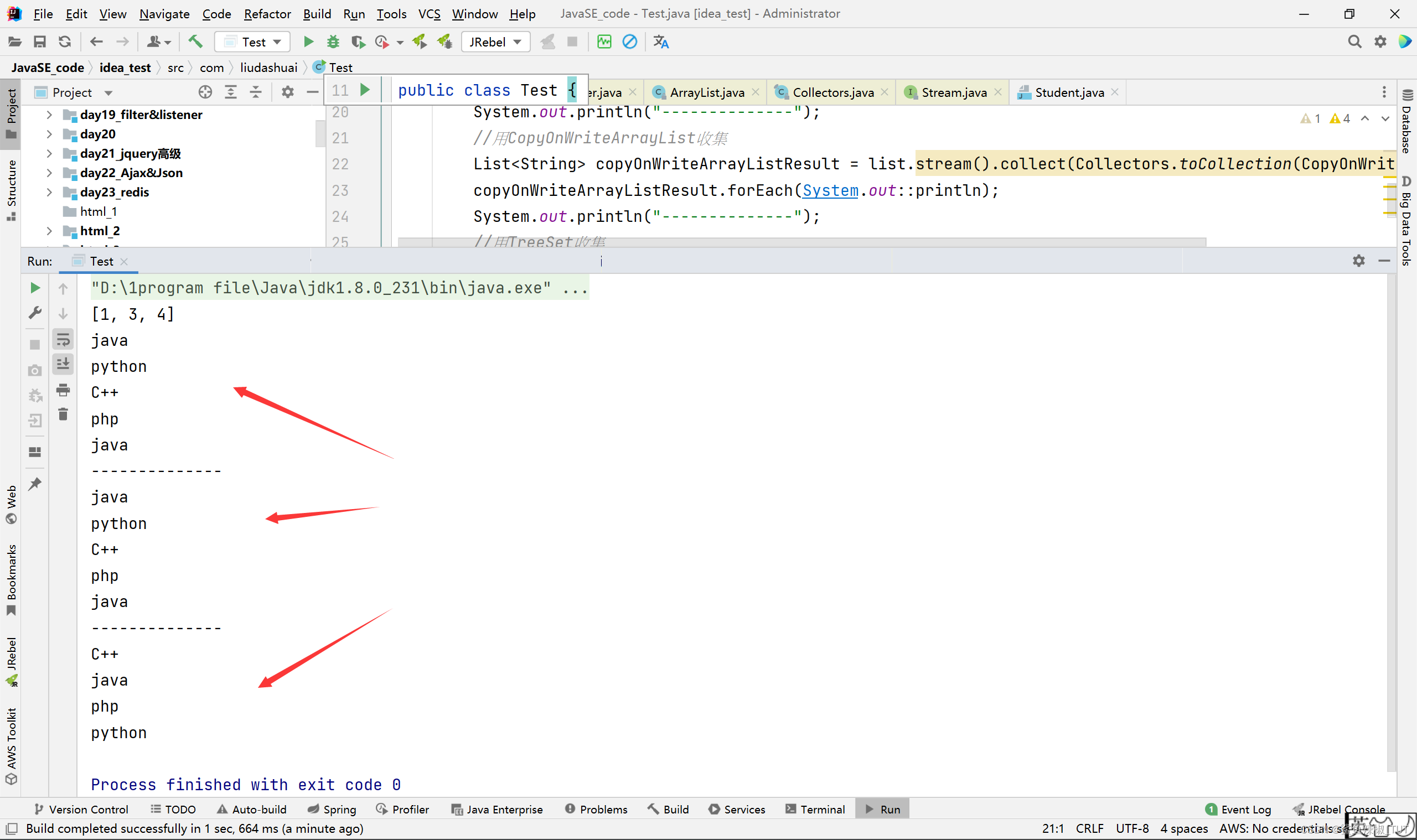
TreeSet<Integer> collect3= Stream.of(1, 3, 4).collect(Collectors.toCollection(TreeSet::new));
System.out.println(collect3.toString());
List<String> list = Arrays.asList("java", "python", "C++","php","java");
//用LinkedList收集
List<String> linkedListResult = list.stream().collect(Collectors.toCollection(LinkedList::new));
linkedListResult.forEach(System.out::println);
System.out.println("--------------");
//用CopyOnWriteArrayList收集
List<String> copyOnWriteArrayListResult = list.stream().collect(Collectors.toCollection(CopyOnWriteArrayList::new));
copyOnWriteArrayListResult.forEach(System.out::println);
System.out.println("--------------");
//用TreeSet收集
TreeSet<String> treeSetResult = list.stream().collect(Collectors.toCollection(TreeSet::new));
treeSetResult.forEach(System.out::println);
}
}
toCollection和groupingBy一起用
package com.liudashuai;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
import java.util.Map;
import java.util.stream.Collectors;
public class Test {
public static void main(String[] args) {
Student student1 = new Student(1, 10);
Student student2 = new Student(1, 10);
Student student3 = new Student(2, 20);
Student student4 = new Student(2, 30);
Student student5 = new Student(3, 30);
Student student6 = new Student(3, 40);
Student student7 = new Student(4, 100);
Student student8 = new Student(4, 100);
Student student9 = new Student(4, 20);
Student student10 = new Student(4, 10);
List<Student> list = Arrays.asList(student1, student2, student3, student4, student5, student6, student7, student8, student9, student10);
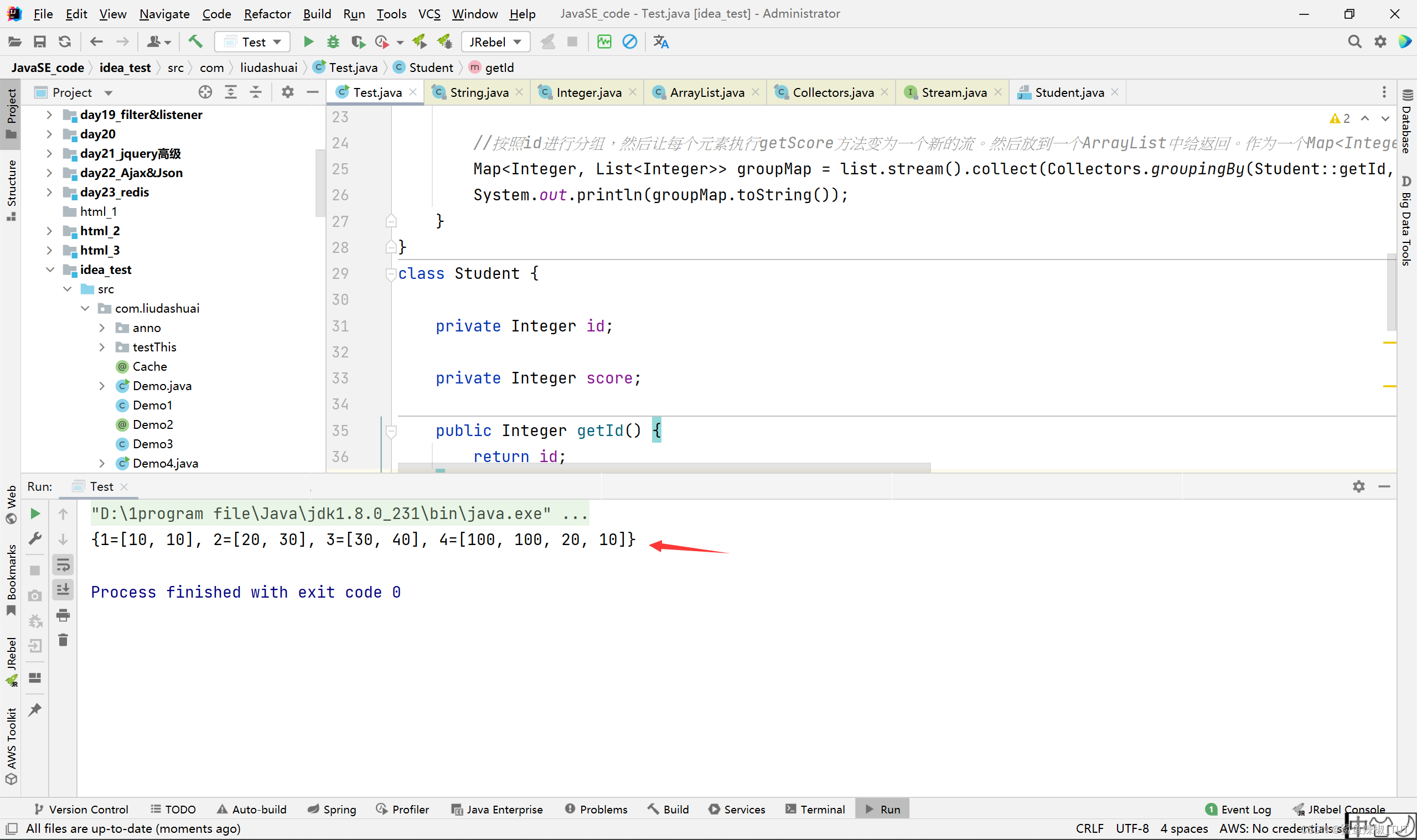
//按照id进行分组,然后让每个元素执行getScore方法变为一个新的流。然后放到一个ArrayList中给返回。作为一个Map<Integer, List<Integer>>的一个键值对对象中的值,分组的那个依据作为键(即,getScore方法返回的值作为键)。
Map<Integer, List<Integer>> groupMap = list.stream().collect(Collectors.groupingBy(Student::getId, Collectors.mapping(Student::getScore, Collectors.toCollection(ArrayList::new))));
System.out.println(groupMap.toString());
}
}
class Student {
private Integer id;
private Integer score;
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public Integer getScore() {
return score;
}
public void setScore(Integer score) {
this.score = score;
}
public Student(Integer id, Integer score) {
this.id = id;
this.score = score;
}
}