经过AstBuilder的处理,得到了Unresolved LogicalPlan。该逻辑算子树中未被解析的有UnresolvedRelation和UnresolvedAttribute两种对象。Analyzer所起到的主要作用就是将这两种节点或表达式解析成有类型的(Typed)对象。在此过程中,需要用到Catalog的相关信息。
因为继承自RuleExecutor类,所以Analyzer执行过程会调用其父类RuleExecutor中实现的run方法,主要的不同之处是Analyzer中重新定义了一系列规则,即RuleExecutor类中的成员变量batches,如下图所示。
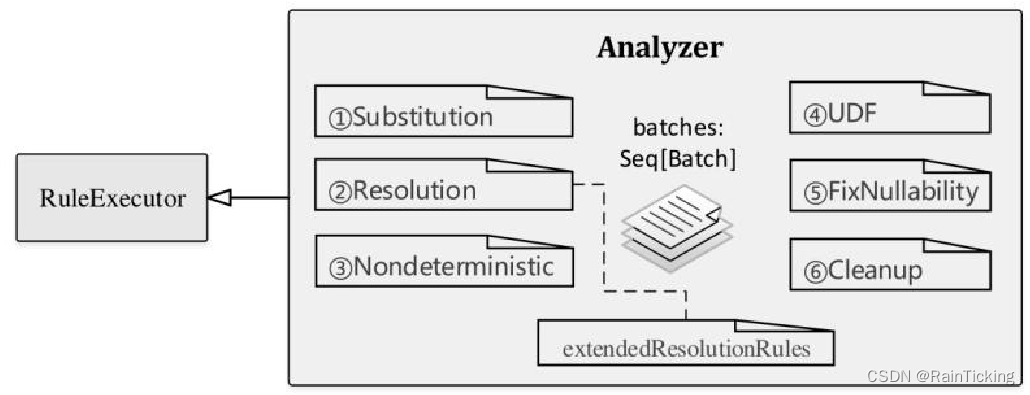
在Spark 2.1版本中,Analyzer默认定义了6个Batch,共有34条内置的规则外加额外实现的扩展规则(上图中extendedResolutionRules)。在分析Analyzed LogicalPlan生成过程之前,先对这些Batch进行简单的介绍,读者可结合代码阅读。
Note:Analyzer中用到的规则比较多,因篇幅所限不方便一一展开分析。本小节对这些规则仅做概述性的分析,从宏观层面介绍规则所起到的主要作用,旨在把握规则体系的轮廓,后续章节在具体的查询分析时会对其中常用的重要规则进行讲解。
(1)Batch Substitution
顾名思义,Substitution含义是替换,因此这个Batch对节点的作用类似于替换操作。目前在Substitution这个Batch中,定义了4条规则,分别是CTESubstitution、WindowsSubstitution、EliminateUnions和 SubstituteUnresolvedOrdinals。
- CTESubstitution:CTE对应的是With语句,在SQL中主要用于子查询模块化,因此CTESubstitution规则也就是用来处理With语句的。在遍历逻辑算子树的过程中,当匹配到With(child,relations)节点时,将子LogicalPlan替换成解析后的CTE。由于CTE的存在,SparkSqlParser对SQL语句从左向右解析后会产生多个LogicalPlan。这条规则的作用是将多个LogicalPlan合并成一个LogicalPlan。
- WindowsSubstitution:对当前的逻辑算子树进行查找,当匹配到WithWindowDefinition(windowDefinitions,child)表达式时,将其子节点中未解析的窗口函数表达式(Unresolved-WindowExpression)转换成窗口函数表达式(WindowExpression)。
- EliminateUnions:在Union算子节点只有一个子节点时,Union操作实际上并没有起到作用,这种情况下需要消除该Union节点。该规则在遍历逻辑算子树过程中,匹配到Union(children)且children的数目只有1个时,将Union(children)替换为children.head节点。
- SubstituteUnresolvedOrdinals:Spark从2.0版本开始,在“Order By”和“Group By”语句中开始支持用常数来表示列的下标。例如,假设某行数据包括A、B、C 3列,那么1对应A列,2对应B列,3对应C列;此时“Group By 1,2”等价于“Group By A,B”语句。而在2.0版本之前,这种写法会直接被当作常数而忽略。新版本中这种特性通过配置参数“spark.sql.orderByOrdinal”和“spark.sql.groupByOrdinal”进行设置,默认都为true,表示该特性开启。SubstituteUnresolvedOrdinals这条规则的作用就是根据这两个配置参数将下标替换成UnresolvedOrdinal表达式,以映射到对应的列。
(2)Batch Resolution
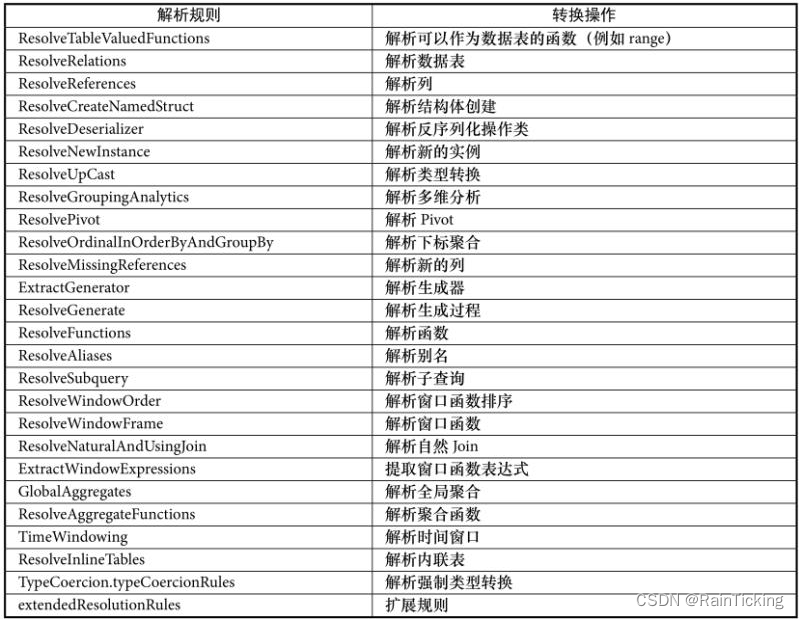
该Batch中包含了Analyzer中最多同时也最常用的解析规则,如下表所示。表中规则从上到下的顺序也是规则被RuleExecutor执行的顺序。
根据表可知,Resolution中加入了25条分析规则,以及一个extendedResolutionRules扩展规则列表用来支持Analyzer子类在扩展规则列表中添加新的分析规则。整体上来讲,表中的这些规则涉及了常见的数据源、数据类型、数据转换和处理操作等。根据规则名称很容易看出,这些规则都针对特定的算子节点,例如ResolveUpCast规则用于DataType向DataType的数据类型转换。考虑到后续具体查询分析中会涉及这些规则,因此这里不展开分析。
(3)Batch Nondeterministic⇒PullOutNondeterministic
该Batch中仅包含PullOutNondeterministic这一条规则,主要用来将LogicalPlan中非Project或非Filter算子的nondeterministic(不确定的)表达式提取出来,然后将这些表达式放在内层的Project算子中或最终的Project算子中。
(4)Batch UDF⇒HandleNullInputsForUDF
对于UDF这个规则,Batch主要用来对用户自定义函数进行一些特别的处理,该Batch在Spark2.1版本中仅有HandleNullInputsForUDF这一条规则。HandleNullInputsForUDF规则用来处理输入数据为Null的情形,其主要思想是从上至下进行表达式的遍历(transform ExpressionsUp),当匹配到ScalaUDF类型的表达式时,会创建If表达式来进行Null值的检查。
(5)Batch FixNullability⇒FixNullability
该Batch中仅包含FixNullability这一条规则,用来统一设定LogicalPlan中表达式的nullable属性。在DataFrame或Dataset等编程接口中,用户代码对于某些列(AttribtueReference)可能会改变其nullability属性,导致后续的判断逻辑(如isNull过滤等)中出现异常结果。在FixNullability规则中,对解析后的LogicalPlan执行transform Expressions操作,如果某列来自于其子节点,则其nullability值根据子节点对应的输出信息进行设置。
(6)Batch Cleanup⇒CleanupAliases
该Batch中仅包含CleanupAliases这一条规则,用来删除LogicalPlan中无用的别名信息。一般情况下,逻辑算子树中仅Project、Aggregate或Window算子的最高一层表达式(分别对应project list、aggregate expressions和window expressions)才需要别名。CleanupAliases通过trimAliases方法对表达式执行中的别名进行删除。
以上内容介绍的是Spark 2.1版本Analyzer中内置的分析规则整体情况,在不同版本的演化中,这些规则也会有所变化,读者可自行分析。现在回到之前案例查询中生成的Unresolved LogicalPlan中。接下来的内容将会重点探讨Analyzer对该逻辑算子树进行分析的详细流程。
在QueryExecution类中可以看到,触发Analyzer执行的是execute方法,即RuleExecutor中的execute方法,该方法会循环地调用规则对逻辑算子树进行分析。
val analyzed: LogicalPlan = analyzer.execute(logical)
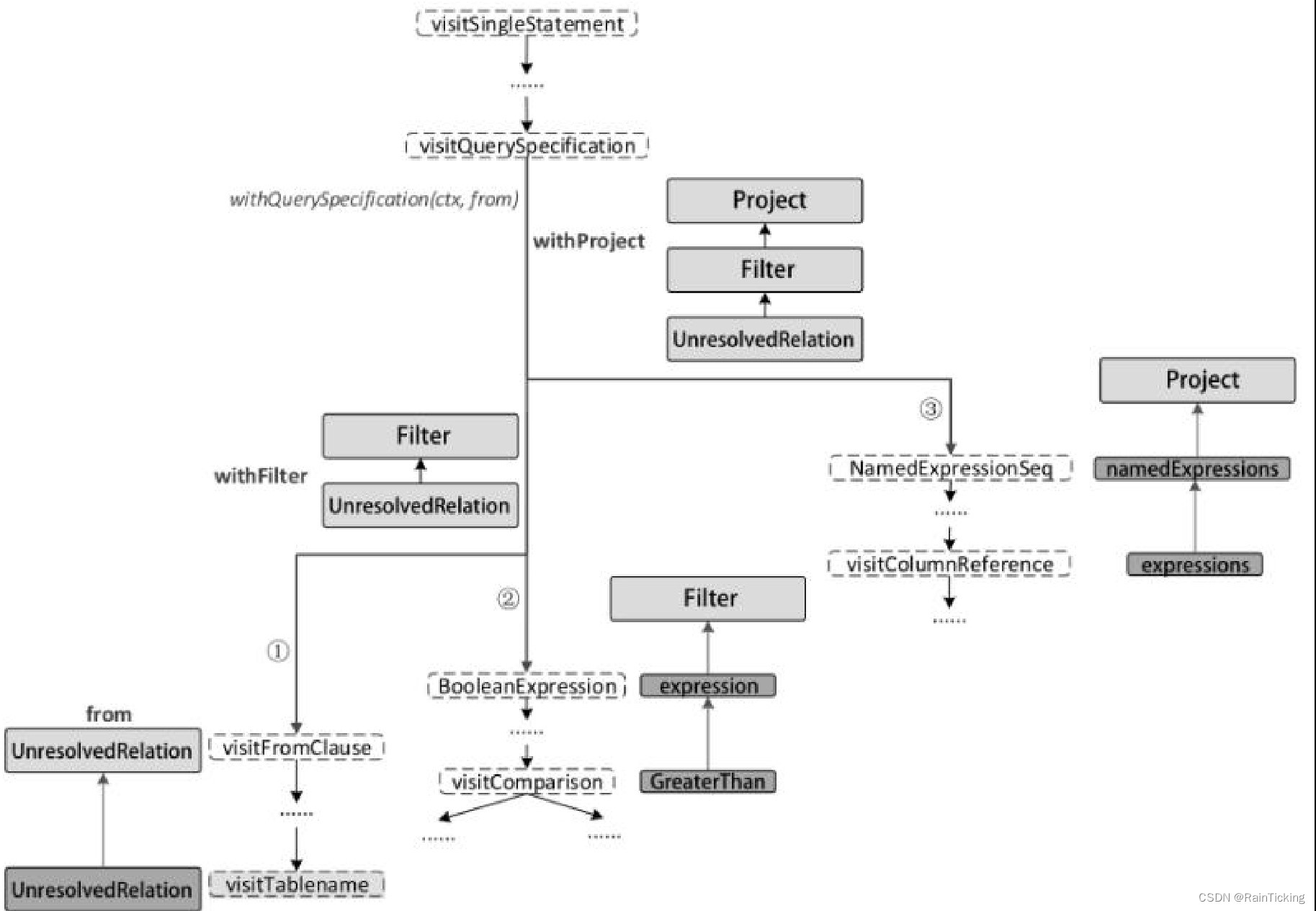
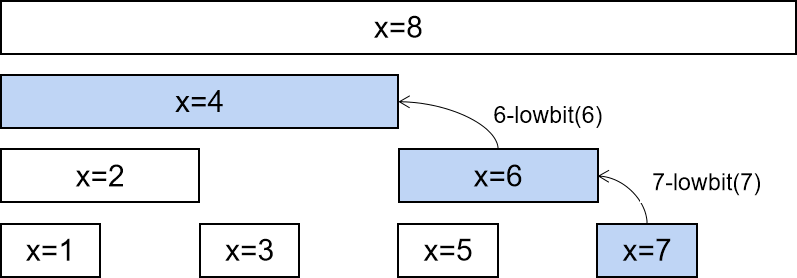
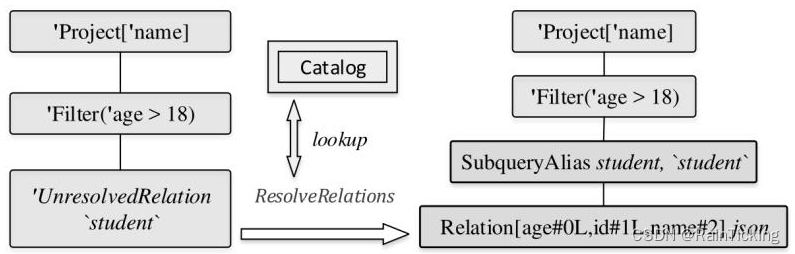
对于上图中的Unresolved LogicalPlan,Analyzer中首先匹配的是ResolveRelations规则。执行过程如下图所示,这也是Analyzed LogicalPlan生成的第1步。
object ResolveRelations extends Rule[LogicalPlan] {
private def lookupTableFromCatalog(u: UnresolvedRelation): LogicalPlan = {
try {
catalog.lookupRelation(u.tableIdentifier, u.alias)
} catch {
case _: NoSuchTableException => u.failAnalysis(s "Table or view not found: ${u.tableName}")
}
}
def apply(paln: LogicalPlan): LogicalPlan = plan resolveOperators {
case i @ InsertIntoTable(u: UnresolvedRelation, parts, child, _, _)
if child.resolved => i.copy(table = EliminateSubqueryAliases(lookupTableFromCatelog(u)))
case u: UnresolvedRelation =>
val table = u.tableIdentifier
if(table.database.isDefined && conf.runSQLonFile && !catalog.isTemporaryTable(table)
&& (!catalog.databaseExists(table.database.get) || !catalog.tableExists(table))) {
u
} else {
lookupTableFromCatalog(u)
}
}
}
从上述ResolveRelations的实现中可以看到,当遍历逻辑算子树的过程中匹配到UnresolvedRelation节点时,对于本例会直接调用lookupTableFromCatalog方法从SessionCatalog中查表。实际上,该表在案例SQL查询的上一步中就已经创建好并以LogicalPlan类型存储在InMemoryCatalog中,因此lookupTableFromCatalog方法直接根据其表名即可得到分析后的LogicalPlan。
需要注意的是,在Catalog查表后,Relation节点上会插入一个别名节点。此外,Relation中列后面的数字表示下标,注意其数据类型,age和id都默认设定为Long类型(“L”字符)。
接下来,进入第2步,执行ResolveReferences规则,得到的逻辑算子树如下图所示。可以看到,其他节点都不发生变化,主要是Filter节点中的age信息从Unresolved状态变成了Analyzed状态(表示Unresolved状态的前缀字符单引号已经被去掉)。
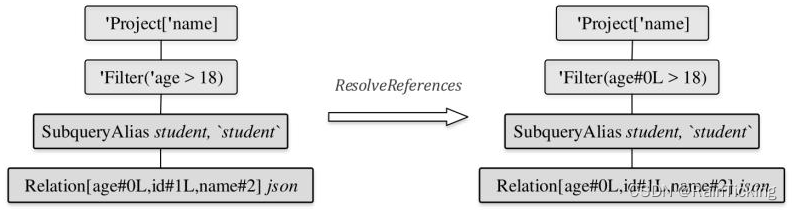
在ResolveReferences规则中与本例相关的匹配逻辑如以下代码所示。当碰到UnresolvedAttribute时,会调用LogicalPlan中定义的resolveChildren方法对该表达式进行分析。需要注意的是,resolveChildren并不能确保一次分析成功,在分析对应表达式时,需要根据该表达式所处LogicalPlan节点的子节点输出信息进行判断。在对Filter表达式中的age属性进行分析时,因为Filter的子节点Relation已经处于resolved状态,因此可以成功;而在对Project中的表达式name属性进行分析时,因为Project的子节点Filter此时仍然处于unresolved状态(注:虽然age列完成了分析,但是整个Filter节点中还有“18”这个Literal常数表达式未被分析),因此解析操作无法成功,留待下一轮规则调用时再进行解析。
object ResolveReferences extends Rule[LogicalPlan] {
def apply(plan: LogicalPlan): LogicalPlan = plan resolveOperators {
case q: LogicalPlan =>
q transformExpressionsUp {
case u @ UnresolvedAttribute(nameParts) =>
val result = withPosition(u) {
q.resolveChildren(nameParts, resolver).getOrElse(u)
}
result
case UnresolvedExtractValue(child, fieldExpr)
if child.resolved => ExtractValue(child, fieldExpr, resolver)
}
}
}
完成第2步之后会调用TypeCoercion规则集中的ImplicitTypeCasts规则,对表达式中的数据类型进行隐式转换,这是Analyzed LogicalPlan生成的第3步,如下图所示。因为在Relation中,age列的数据类型为Long,而Filter中的数值“18”在Unresolved LogicalPlan中生成的类型为IntegerType,所以需要将“18”这个常数转换为Long类型。
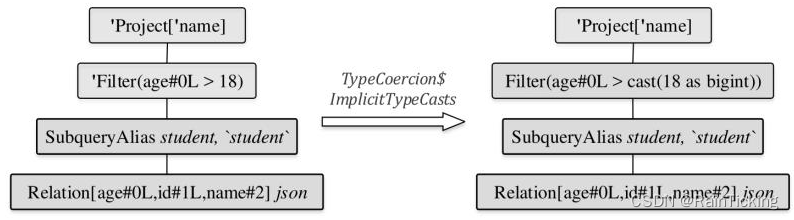
上述分析转换过程如上图所示,可以看到常数表达式“18”换为“cast(18 as bigint)”表达式(注:在Spark SQL类型系统中,BigInt对应Java中的Long类型)。ImplicitTypeCasts规则对于案例的逻辑算子树的处理过程如以下代码所示。对于BinaryOperator表达式,该规则会调用findTightestCommonTypeOfTwo找到对于左右表达式节点来讲最佳的共同数据类型。经过该规则的解析操作,可以看到上图中Filter节点已经变为Analyzed状态,节点字符前缀单引号已经被去掉。
object ImplicitTypeCasts extends Rule[LogicalPlan] {
def apply(plan: LogicalPlan): LogicalPlan = plan resolvedExpressions {
case b @ BinaryOperator(left, right)
if left.dataType != right.dataType =>
findTightestCommonTypeOfTwo(left.dataType, right.dataType).map {
commonType =>
if(b.inputType.acceptsType(commonType)) {
val newLeft = if(left.dataType == commonType) left else Cast(left, commonType)
val newRight = if(right.dataType = commonType) right else Cast(right, commonType)
b.withNewChildren(Seq(newLeft, newRight))
} else {
b
}
}.getOrElse(b)
}
}
经过上述3个规则的解析之后,剩下的规则对逻辑算子树不起作用。此时逻辑算子树中仍然存在Project节点未被解析,接下来会进行下一轮规则的应用。第4步也是最后一步,再次执行ResolveReferences规则。
如下图所示,经过上一步Filter节点已经处于resolved状态,因此逻辑算子树中的Project节点能够完成解析。Project节点的“name”被解析为“name#2”,其中“2”表示name在所有列中的下标。
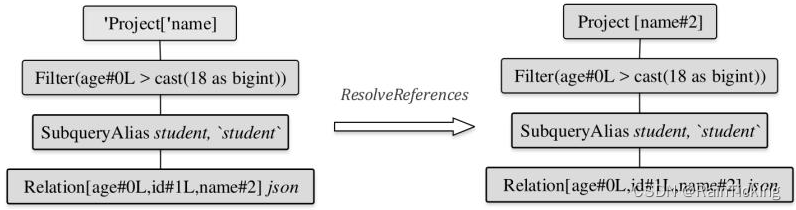
至此,Analyzed LogicalPlan就完全生成了。从上述步骤可以看出,逻辑算子树的解析是一个不断的迭代过程。实际上,用户可以通过参数(spark.sql.optimizer.maxIterations)设定RuleExecutor迭代的轮数,默认配置为50轮,对于某些嵌套较深的特殊SQL,可以适当地增加轮数