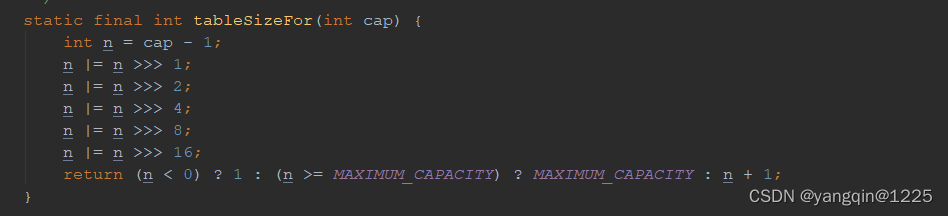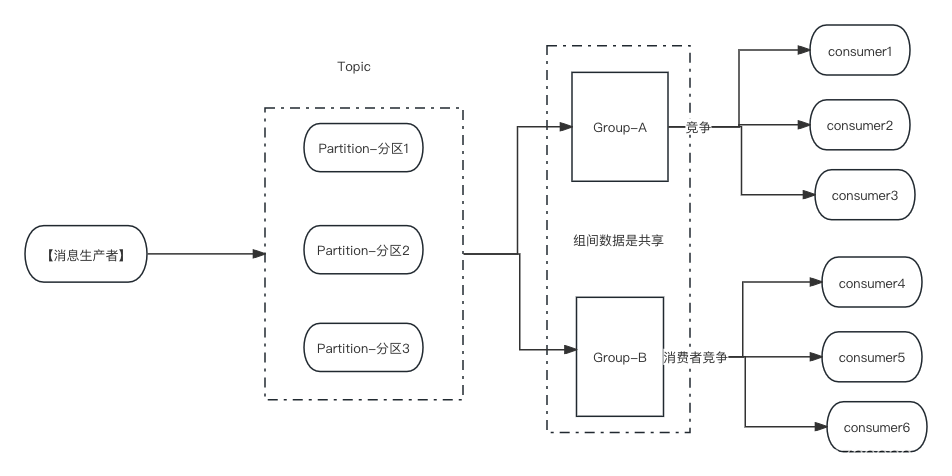
Kafka的结构图
多个Parttion共同组成这个topic的所有消息。
每个consumer都属于一个consumer group,每条消息只能被consumer group中的一个Consumer消费,
但可以被多个consumer group消费。即组间数据是共享的,组内数据是竞争的。
二、消费模型
1、点对点消息传递模式
【发布者】-【queue】-【消费者】
点对点消息系统中,消息持久化到一个queue(队列)中。此时,将有一个或多个消费者消费队列中的数据。
但是一条消息只能被消费一次。当一个消费者消费了队列中的某条数据之后,该条数据则从消息队列中删除,
也就是消费者从Queue里面抢消息。
2、发布-订阅消息传递模式
【发布者】-【Topic】-【消费者】
发布-订阅消息系统中,消息被持久化到一个topic中。与点对点消息系统不同的是,消费者可以订阅一个或多个topic(分类),
消费者可以消费该topic中所有的数据,同一条数据可以被多个消费者消费,数据被消费后不会立马删除。
需要注意上面两种模式,是有条件的,只有Gruop组和Consumer达到一定的数量比,才会触发。
1、当某个Topic只有一个消费组订阅,且该消费组只有一个消费者时,就是队列(queue)下的点对点消费模式。
2、当某个Topic有多个消费组订阅,且每个消费组只有一个消费者时,就是发布订阅模式。
三、消费过程
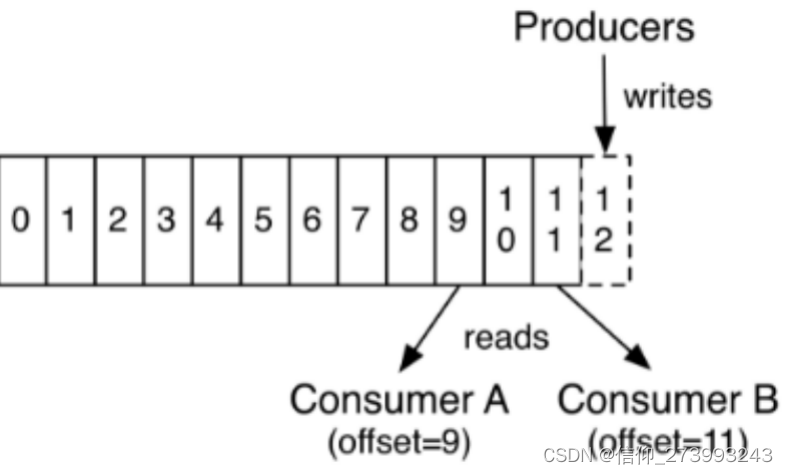
当2个消费者在消费同一个分区时,2个消费者都在在各自里面记录当前的offset。
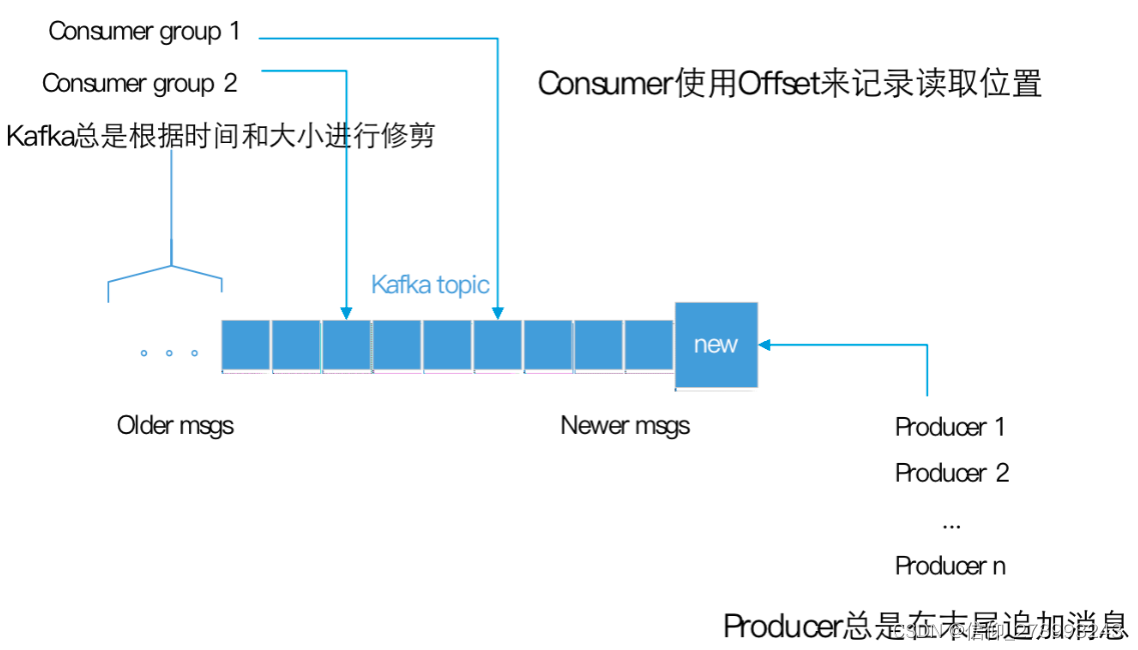
生产者生产消息,添加到topIc时,每次都是追加到末尾。
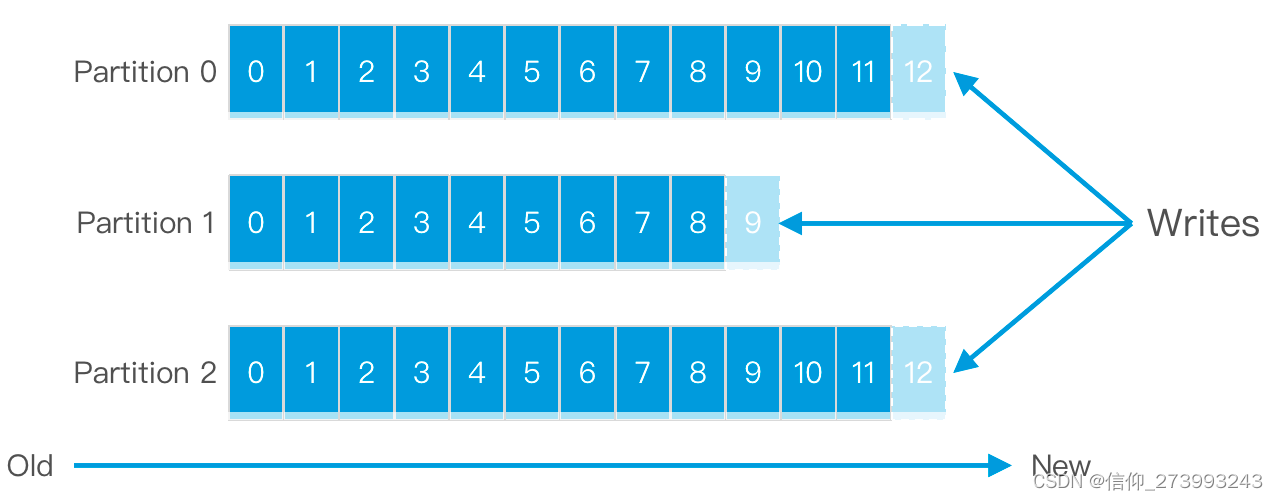
为了提高Kafka的吞吐量,物理上把Topic分成一个或多个Partition,每个Partition都是有序且不可变的消息队列。
每个Partition在物理上对应一个文件夹,该文件夹下存储这个Partition的所有消息和索引文件。
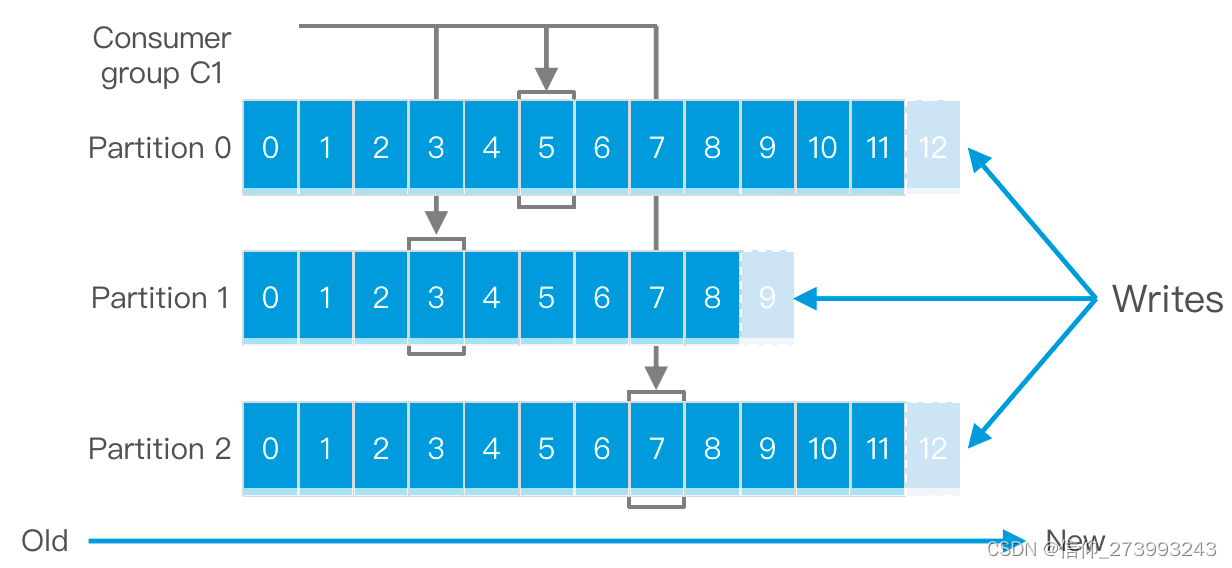
消费者组,在不同的分区有不同的offset。
四、分区策略
所谓分区策略是决定【生产者】将消息发送到哪个分区的算法。Kafka为我们提供了
默认的分区策略,同时它也支持自定义分区策略。
1、轮询策略:Round-robin 策略,即顺序分配。
轮询策略有非常优秀的负载均衡表现,它总是能保证消息最大限度地被平均分配到所有分区上,故默认情况下它是最合理的分区策略,也是最常用的分区策略之一。
2、随机策略-Randomness 策略。随机就是随意地将消息放置到任意一个分区上。
4、按消息键保序策略-Key-ordering 策略。
Kafka 允许为每条消息定义消息键,简称为 Key。这个 Key 的作用非常大,它可以是一个有着明确业务含义的字符串;也可以用来表征消息元数据。一旦消息被定义了 Key,那么你就可以保证同一个 Key 的所有消息都进入到相同的分区里面,由于每个分区下的消息处理都是有顺序的,故这个策略被称为按消息键保序策略。
默认分区规则
1、如果指定的partition,那么直接进入该partition
2、如果没有指定partition,但是指定了key,使用key的 hash一选择partition。
3、如果既没有指定partition,也没有指定key,使用轮询一的方式进入partition。