题目
对报文进行重传和重排序是常用的可靠性机制,重传缓冲区内有一定数量的子报文,每个子报文在原始报文中的顺序已知,现在需要恢复出原始报文。
输入描述
输入第一行为N,表示子报文的个数,0<N <= 1000。
输入第二行为N个子报文,以空格分开,子报文格式为字符串报文内容+后缀顺序索引,字符串报文内容由(a-Z ,A-Z)组成。后缀为整形值,表示顺序。顺序值唯一 ,不重复。
输出描述:
输出恢复出的原始报文。按照每个子报文的顺序值的升席排序,顺序后缀需要从恢复出的报文中删除掉
用例1
输入:
rolling3 stone4 like1 a2
输出:
like a rolling stone
说明:
4个子报文的内容分别为roling,stone,like,a,顺序值分别为3, 4,1, 2,按照顺序值升序并删除掉顺序后缀得到恢复的原始报文:
like a rolling stone
用例2
输入:
Lgifts6 and7 Exchanging1 all2 precious5 things8 kinds3 of4
注:这里需要注意and7与Exchanging1有两个空格
输出:
Exchanging all kinds of precious gifts and things
思路
这道题本身不难。大概经过下面3步,即可得到答案。
- 将输入的字符串根据空格拆分为字符串数组
- 遍历数组,对于每一个字符串,找到其第一个数字的索引位置,根据该位置拆分为字符串和顺序值,存入map中(将顺序值作为key,字符串作为val存放)
- 再遍历hashmap,可以直接获得恢复出的原始报文(按照顺序值的从小到大顺序)
问题的关键在于理解,当hashmap中的key为integer时,map自己就是按照从小到大的顺序排序的当然,这需要在一定约束条件下,下面详细分析。
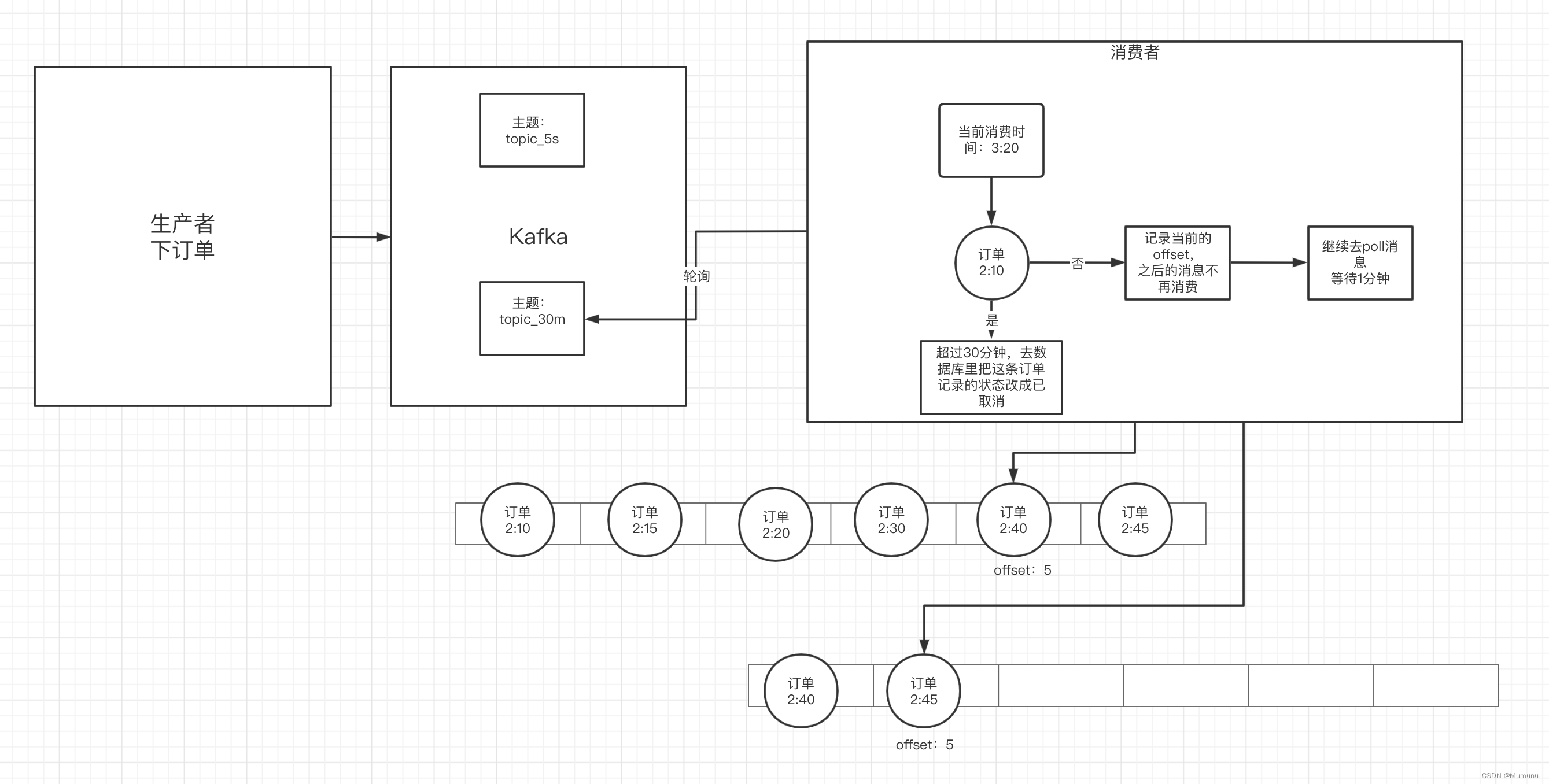
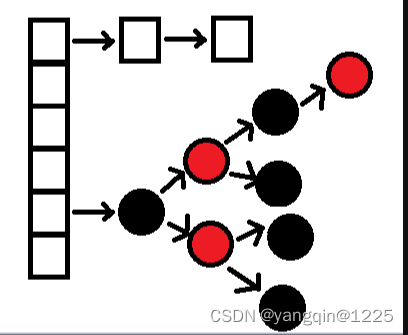
这需要从hashmap的存放逻辑说起。下图是hashmap的逻辑结构。
通过上图,可以看到hashmap是由数组、链表+红黑树构成。默认情况下,hashmap的初始容量为16,也就是数组个数为16个。
当存放的元素个数大于16 * 0.75(负载因子)时,hashmap会触发扩容操作(原来的2倍,即16扩成32)。
再来看hashmap存放键的逻辑(key类型为Integer),即put(key,val)到底怎么做的?
通过源码很容易找到下述逻辑:
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
hashmap是通过hash(key)计算存放位置的,而hash函数是返回的key的hashcode和其右移16位的的异或值。比如key值是16,那么其hashcode为16(Integer类型的hashcode返回其本身)。再通过异或计算得到的值还是为16.计算过程如下:
0000 0000 0001 0000 ^ //16的二进制表示
0000 0000 0000 0000 //右移16位,全为0。右移的原因是,可以让最后结果含有hashcode高16位的特征,使其在hashmap中存放得更均匀。
=0000 0000 0001 0000 //还是得到了16
上面通过hash函数(有人称扰动函数)获得了16,接下来看看怎么利用16计算其在hashmap的位置的(即存放hashmap数组的哪个索引?)
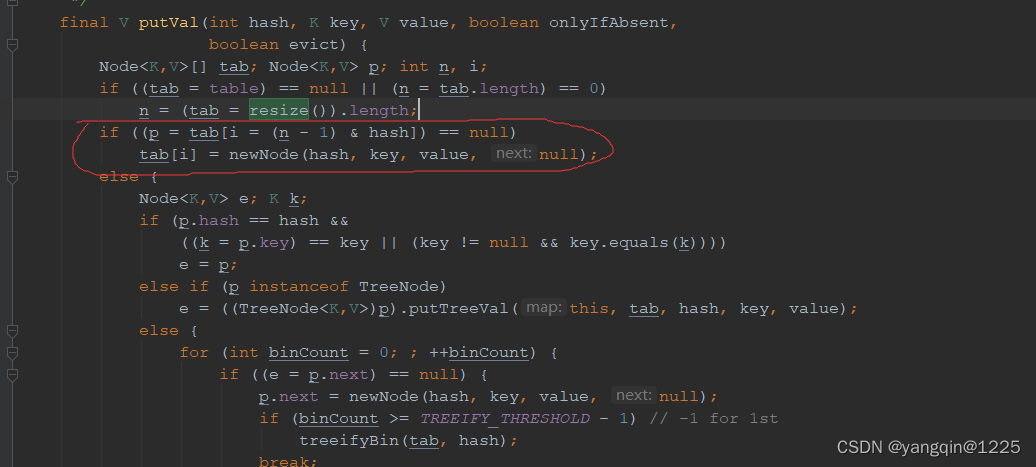
如上图所示,只关注圈出来的部分。计算位置i的方式为:i=(n - 1) & hash,其中n为当前hashmap的容量,hash为上一步hash(key)计算出来的值。所以当hash=16时,位置i=(16-1)&16=0。也就是在索引0处存放值。计算过程如下:
0000 1111 & //16-1=15的二进制表示
0001 0000 //16的二进制表示
=0000 0000 //结果为0,其实就是16%16的值。这也是为什么容量要设置为2的整数次幂的原因,因为对n等于2的整数次幂来说。x&(n-1)=x%n
结合上面的描述,我们用个具体实例来演示下hashmap的存放过程。
通过上面的过程,可以看到,在hashMapkey为Integer时,在一定条件下,可以直接按照key的从小到大的顺序输出。比如上面的步骤3,输出结果是0,2。步骤6输出结果是:0 2 3 4 5 6 7 8 9 10 11 16 17。但是步骤4输出的结果为:0 16 2。
现在需要考虑什么时候不能正确排序?显然,当hashmap不扩容时,输入的key又不小于当前容量时,会造成某个节点存放多个值,最后无法按照从小到大的顺序输出。
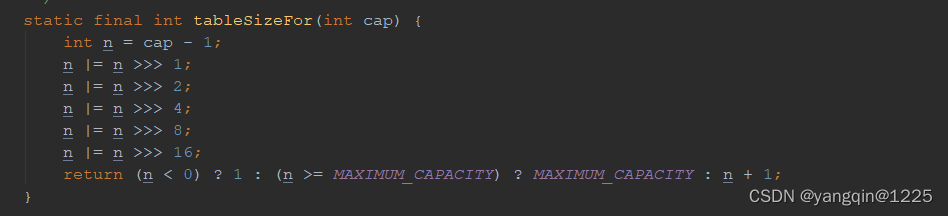
但是就我们这道题目来说,输入的数据范围只能是1~n这样连续的数字,n<=1000。不设置hashmap初始容量的情况下,hashmap的容量扩容过程应该为:16 32 64 128 256 1024。通过不断扩容最终不会存在某个节点有多个值的情况,所以可以按照key值从小到大的顺序输出。当然扩容不可避免的降低了效率。因为我们知道字符串的总量。我们可以在初始化hashmap时直接指定容量大小(不必我们自己计算为2的整数次幂,hashmap会自动完成这个操作)。

题解
package hwod;
import java.util.HashMap;
import java.util.Map;
import java.util.Scanner;
public class MessageSort {
static Map<Integer, String> map;
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
int N = sc.nextInt();
sc.nextLine();
map = new HashMap<>(N);
String[] inputs = sc.nextLine().split("\\s+");
System.out.println(messageSort(inputs));
}
private static String messageSort(String[] inputs) {
for (int i = 0; i < inputs.length; i++) {
int idx = getFirstNum(inputs[i]);
int num = Integer.parseInt(inputs[i].substring(idx));
String val = inputs[i].substring(0, idx);
map.put(num, val);
}
StringBuilder sb = new StringBuilder();
//可以直接遍历map(key为Interger的hashmap在一定条件下可以按照key的从小到大排序)
//也可以遍历1~N,直接取map.get(1)、map.get(2)……这样就不用利用上面分析的hashmap的特性了。
for (Integer k : map.keySet()) {
if (sb.length() != 0) {
sb.append(" ");
}
sb.append(map.get(k));
}
return sb.toString();
}
private static int getFirstNum(String input) {
char[] chars = input.toCharArray();
for (int i = 0; i < chars.length; i++) {
if (Character.isDigit(chars[i])) {
return i;
}
}
return -1;
}
}
推荐
如果你对本系列的其他题目感兴趣,可以参考华为OD机试真题及题解(JAVA),查看当前专栏更新的所有题目。