| 26.文献阅读笔记 | ||
| 简介 | 题目 | Weakly-supervised learning with convolutional neural networks |
| 作者 | Maxime Oquab,Leon Bottou,Ivan Laptev,Josef Sivic,CVPR,2015 | |
| 原文链接 | http://www.cv-foundation.org/openaccess/content_cvpr_2015/papers/Oquab_Is_Object_Localization_2015_CVPR_paper.pdf | |
| 关键词 | CNN,multi-classification | |
| 研究问题 | 通过bounding boxes标注的图像分类具有一定的问题:通过边界框一致地标注物体的位置和尺度,对部分遮挡和裁剪的物体效果不佳;对物体部分的标注很困难。 所以直接对图像内的物体种类进行标注然后训练(弱监督学习)。 | |
| 研究方法 | a weakly supervised convolutional neural network (CNN) for object classification that relies only on image-level labels; 用于物体分类的弱监督卷积神经网络( CNN )仅依赖于图像级别的标签,而不依赖于object bounding boxes。 只标注图片包含的对象列表,而不标注对象的位置。 在Alexnet的基础上. 前五个卷积层是在Imagenet上进行训练的,后面的几层是在Pascal数据集上进行训练的.
First, we treat the last fully connected network layers as convolutions to cope with the uncertainty in object localization. 首先,将最后一个全连接网络层看作卷积层,以应对目标定位中的不确定性。 可以处理几乎任意大小的图像作为输入。 Second, we introduce a max-pooling layer that hypothesizes the possible location of the object in the image. 其次,在输出端添加单个全局最大池化层显式搜索图像中得分最高的对象位置。 Third, we modify the cost function to learn from image-level supervision.
将任务视为每个类单独的二分类问题。因此,损失函数是K个二元Logistic回归损失之和。 k ∈ {1 · · · K}  F:分类结果 Y:标签值 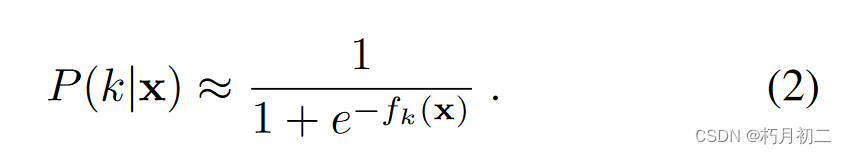 每一个类别分数fk (x)可以解释为一个后验概率,表示图像x中k类的存在 解决多尺度问题:对所有训练图像进行缩放,使其最大边长为500像素,并将其补零至500 × 500像素。然后,每个训练小批量的16幅图像通过在0.7到1.4之间均匀采样的比例因子进行缩放。这使得网络可以看到图像中不同尺度的物体。 定位的衡量标准,作者是将max-pooling的输出映射到原图,然后将结果与bounding-box标注的结果进行比较,容忍度为18个像素,即将bounding-box向外扩18个像素,如果结果在此之内,则认为定位正确。 | |
| 研究结论 | 可以从包含多个物体的杂乱场景中学习。 修改后的CNN架构在仅训练输出图像级标签的同时,对训练图像中的物体或其独特部分进行了定位。 弱监督网络可以预测场景中物体的大致位置(在x , y位置的形式),但不能预测物体的范围(包围盒)。 在测试时间内只搜索六个不同的尺度就足以达到良好的分类性能。在比例尺上增加更宽或更细的搜索并没有带来额外的好处。 | |
| 创新不足 | 判断定位的标准是作者定义的,不是通用的 | |
| 额外知识 | none | |
(论文阅读26/100)Weakly-supervised learning with convolutional neural networks
news2025/4/13 14:45:26
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/1201902.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!相关文章
![[SOC] MBIST (Memory Built-In Self Test) and Memory Built-in Self Repair (BISR)](https://img-blog.csdnimg.cn/8b427e9c7f6e4e61996d604742678b6b.png)
[SOC] MBIST (Memory Built-In Self Test) and Memory Built-in Self Repair (BISR)
存储器构成了 VLSI 电路的很大一部分。存储系统设计的目的 是存储大量数据。[1] 存储器不包括逻辑门和触发器。因此,需要不同的故障模型和测试算法来测试存储器。
MBIST 是一种自测试和修复机制,它通过一组有效的算法来测试存储器,以检测典型…
Lightroom Classic 2023 v12.4
Lightroom Classic 2023是一款图像处理软件,是数字摄影后期制作的重要工具之一。与其他图像处理软件相比,Lightroom Classic具有以下特点:
高效的图像管理:Lightroom Classic提供了强大的图像管理功能,可以轻松导入、…
C++标准模板(STL)- 类型支持 (受支持操作,检查类型是否有拥有移动赋值运算符)
类型特性 类型特性定义一个编译时基于模板的结构,以查询或修改类型的属性。
试图特化定义于 <type_traits> 头文件的模板导致未定义行为,除了 std::common_type 可依照其所描述特化。
定义于<type_traits>头文件的模板可以用不完整类型实例…
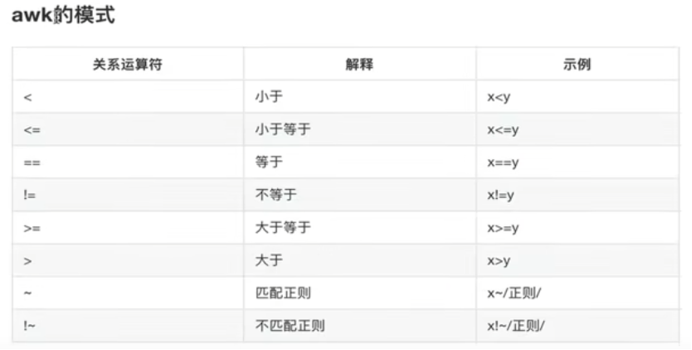
Linux-AWK(应用最广泛的文本处理程序)
目录
一、awk基础
二、awk工作原理
三、OFS输出分隔符
四、awk的格式化输出
五、awk模式pattern 一、awk基础 使用案例:
1.准备工作
请在Linux中执行以下指令
cat -n /etc/passwd > ./passwd 练习:
1.从文件 passwd 中提取并打印出第五行的内…
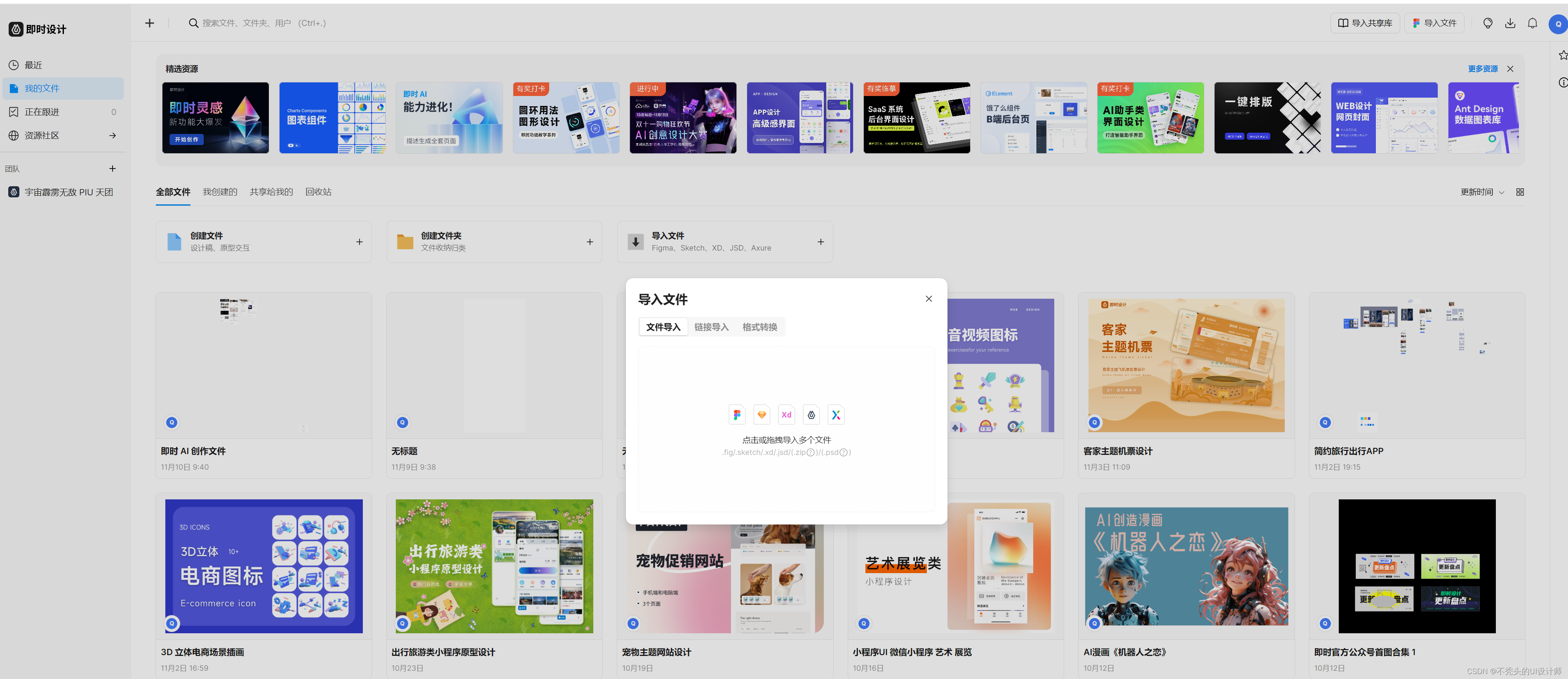
初学者向导:Sketch设计软件自学教程大全
Sketch软件是Mac平台上流行的矢量图形编辑软件,旨在帮助用户创建各种设计原型,如网站、移动应用程序、图标等。Sketch软件的设计风格简单明了,界面操作简单易用,非常适合UI/UX设计师、平面设计师等数字创意人员。本文作为软件自学…

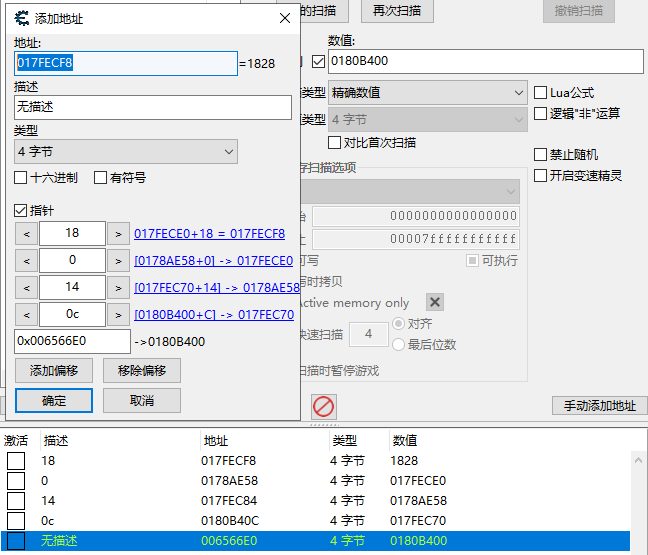
2.7 CE修改器:多级指针查找
在本步骤中,你需要使用多级指针的概念来查找健康值真正的地址并修改它。多级指针就是一个指针的指针,也就是第一个指针指向第二个指针,第二个指针指向第三个指针,以此类推,最终指向你想要访问的地址。
首先࿰…
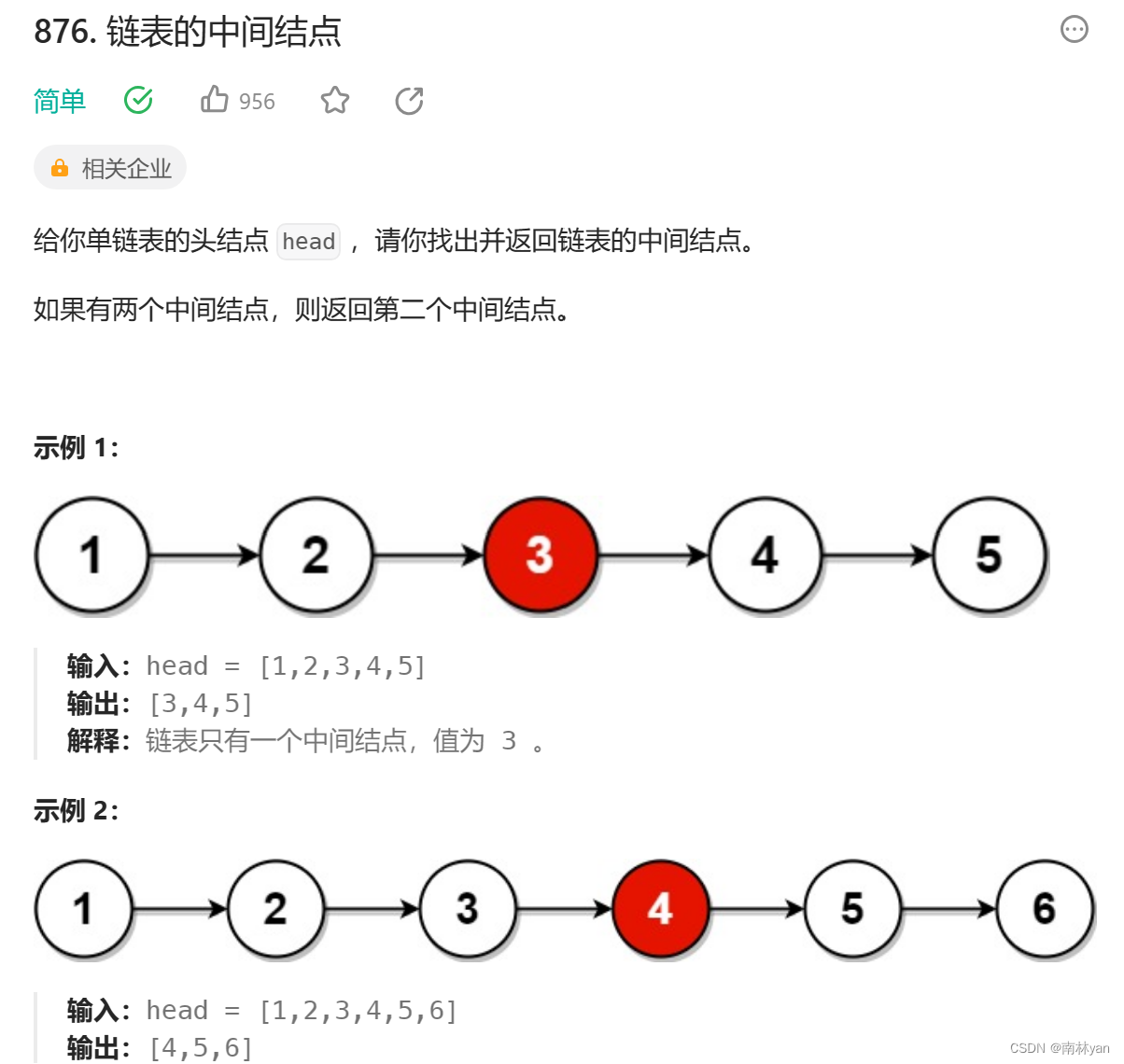
leetcode:876. 链表的中间结点
一、题目 函数原型: struct ListNode* middleNode(struct ListNode* head) 二、思路 要找到链表的中间结点,有两种思路: 暴力解法:先遍历一遍链表,计算出链表的长度,再次遍历链表,找到中间结点。…

马达加斯加市场开发攻略,收藏一篇就够了
马达加斯加是位于非洲南部一个国家,虽然经济是比较落后的一个国家,但是一直以来跟中国的关系都还不错,生产生活资料也是比较依赖进口的,市场潜力还是不错的。今天就来给大家分享一下马达加斯加的相关攻略。大家点赞收藏关注慢慢看…

北大联合智源提出训练框架LLaMA-Rider
大语言模型因其强大而通用的语言生成、理解能力,展现出了成为通用智能体的潜力。与此同时,在开放式的环境中探索、学习则是通用智能体的重要能力之一。因此,大语言模型如何适配开放世界是一个重要的研究问题。 北京大学和北京智源人工智能研究…

Django中Cookie和Session的使用
目录
一、Cookie的使用
1、什么是Cookie?
2、Cookie的优点
3、Cookie的缺点
4、Django中Cookie的使用
二、Session的使用
1、什么是Session?
2、Session的优点
3、Session的缺点
4、Django中Session的使用
三、Cookie和Session的对比
总结 D…
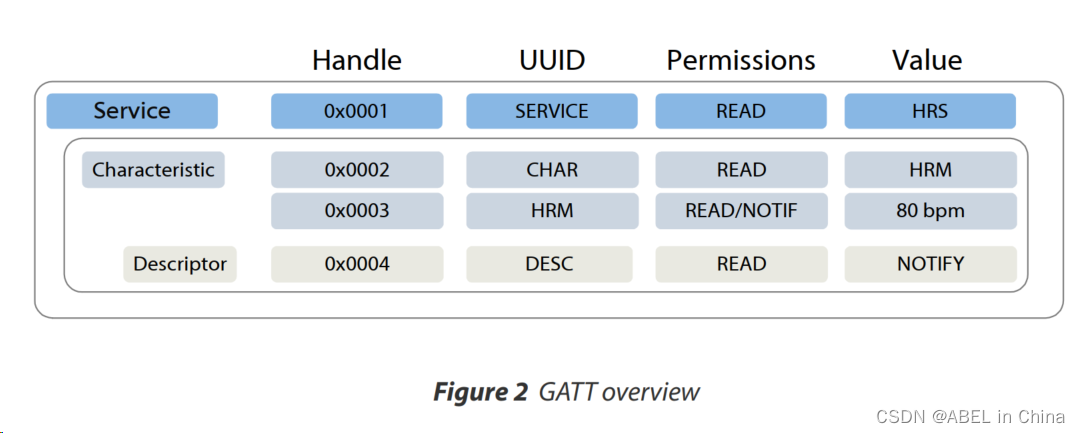
低功耗蓝牙技术 > GAP和GATT介绍
GAP(Generic Access Profile)和GATT(Generic Attribute Profile)简介
在蓝牙技术的发展中,GAP和GATT两个协议扮演着关键的角色,为BLE(低功耗蓝牙)设备之间的通信提供了规范和框架。…
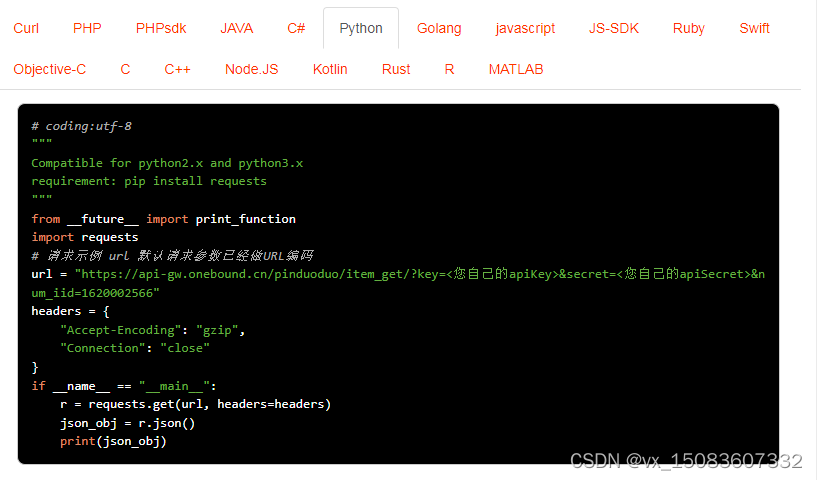
拼多多API接口,打造智能化电商平台
近年来,电商行业的崛起给人们的购物带来了极大的方便。随着电商行业的发展,拼多多作为新兴电商平台已经成为市场焦点。
同时,随着技术的发展,API(Application Programming Interface,应用程序编程接口&…
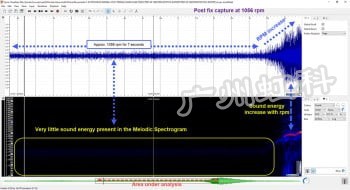
振动异响振动案例 | 本田思域怠速时发动机异响
虽然未来可能是“电动”的,但内燃机(ICE)在永远消失之前还有很多年。但是,我确信它永远不会。从目前的立法来看,到2030年,传统的汽油和柴油汽车/货车将被禁止销售,插电式混合动力车将延长到2035…

java--String使用时的注意事项
1.String使用时的注意事项
第一点:
①String对象的内容不可改变,被称为不可变字符串对象。(因为字符串是引用类型,每次都是引用一个地址,就相当于你有车,但是你不可能天天把车踹兜里,只能把钥匙踹兜里&am…

「得力集团」启动采购供应链协同项目,携手企企通打造文创科技产业行业标杆
近期,国内最大的办公与学习用品产业集团、多工作场景整体解决方案的领导者「得力集团有限公司」与企企通成功签约,并顺利召开采购供应链协同项目启动会。 本次会议中,双方高层领导与项目团队成员就项目的功能需求、实施方案、资源支持等问题进…
Direct3D拾取
假设在屏幕上单击,击中的位置为点s(x,y)。由图可以看出,用户选中了茶壶。但是仅给出点s,应用程序还无法立即判断出茶壶是否被选中。所以针对这类问题,我们需要采用一项称为“拾 取(Picking)”的技术。
茶壶和屏幕点s之间的一种联…

谷歌竞价排名10个引爆利器揭秘分享-华媒舍
谷歌是目前世界上最受欢迎的搜索引擎之一,而竞价排名则是企业在谷歌平台上提升在线曝光度的重要手段。本文将介绍10个能够帮助企业轻松提高谷歌竞价排名的利器,让您的产品或服务脱颖而出。 第一利器:关键词优化
关键词优化是提升竞价排名的基…

Accelerate 0.24.0文档 一:两万字极速入门
文章目录 一、概述1.1 PyTorch DDP1.2 Accelerate 分布式训练简介1.2.1 实例化Accelerator类1.2.2 将所有训练相关 PyTorch 对象传递给 prepare()方法1.2.3 启用 accelerator.backward(loss) 1.3 Accelerate 分布式评估1.4 accelerate launch1.4.1 使用accelerate launch启动训…

垃圾/垃圾桶识别相关开源数据集汇总
垃圾箱图片数据集
数据集下载链接:http://suo.nz/3cvbiC 垃圾箱多类检测数据集
数据集下载链接:http://suo.nz/2eluH3 蒙得维亚的垃圾箱图片
数据集下载链接:http://suo.nz/2lRHLK 垃圾桶满溢检测数据集
数据集下载链接:http:…