目录
一、栈
1、栈的概念
1.2 栈的结构
2、栈的创建及初始化
3、压栈操作
4、出栈操作
5、显示栈顶元素
6、显示栈空间内元素的总个数
7、释放栈空间
8、测试栈
二、队列
1、队列的概念
1.2 队列的结构
2、队列的创建及初始化
3、入队
4、出队
5、显示队头、队尾数据
5.1 显示队头数据
5.2 显示队尾数据
6、显示队列的数据个数
7、释放队列
8、测试队列
结语:
前言:
栈和队列都是一种特殊的线性表,线性表是一种被广泛应用的数据结构。之所以叫线性表是因为其在逻辑上是连续的,可以将他想象成一条线把数据都连了起来,但在物理上并不一定是连续的。在用线性表存储数据的时候,通常以链式结构和数组形式来进行数据的存储。本文介绍的栈和队列就是使用数组和链表实现的。
一、栈
1、栈的概念
栈的特点是只能从固定的一端进行数据的输入和输出,通常称为压栈和出栈。数据必须满足先入后出的状态,把数据的输入和输出端口称为栈顶,另一端称为栈底,随着不断的进行压栈操作,原先栈顶的元素就会被压到栈底。出栈时,栈底元素必须等上面栈顶元素都出栈了才能出栈。
1.2 栈的结构

栈中的数据输入和输出始终遵循着先入后出的法则。

接下来就使用代码来实现栈,分析栈的各个功能:压栈、出栈、显示栈顶元素、显示栈空间元素的个数、释放栈空间。
2、栈的创建及初始化
这里用数组的方式来实现栈,因为数组的优势在于尾插尾删的时候,数组的效率还是很高的,当然如果用数组进行头插头删则每一次的插入和删除都需要将整个数组进行移动,效率就非常低了。但是栈的特点是只有一端进行输入输出数据即可,所以我们把数组的末尾当成栈的栈顶来看待,则用不到数组头插头删的功能。
首先创建栈的结构体:
typedef int STDataType;//int类型重定义
typedef struct Stack
{
STDataType* arr;//arr可以理解为数组首地址,后续用该指针开辟空间
int top;//表示栈顶的元素,即数组的最后一个元素
int capacity;//栈的容量
}ST栈的初始化:
void STInit(ST* pst)//初始化栈
{
assert(pst);
pst->arr = NULL;//初始化的时候先置空,后续插入数据时在开辟空间
pst->top = 0;//最开始没有元素因此栈顶为0
pst->capacity = 0;//初始化容量也可以设置为0
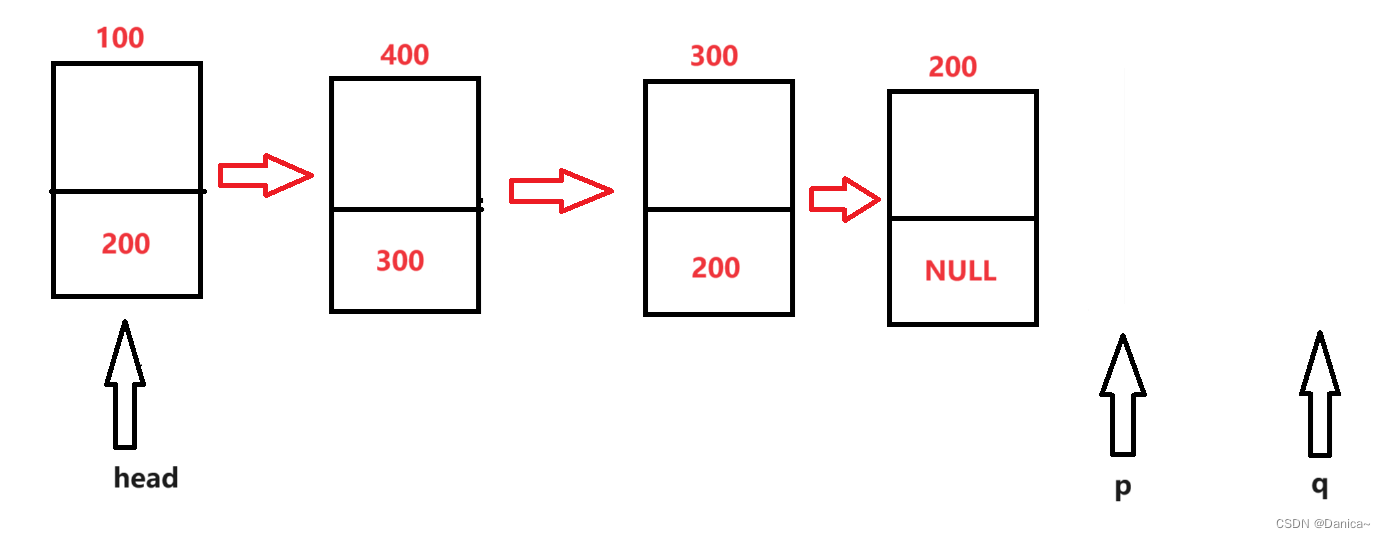
}这里有一个注意点:top的位置是栈顶元素的下一个位置,如下图所示:

3、压栈操作
压栈就是将数据放到数组的末尾处,因为数组的末尾对应的是栈顶位置,压栈就是从栈顶放入元素。压栈完成后top++,代码如下:
void STPush(ST* pst, STDataType x)//压栈
{
assert(pst);
if (pst->capacity == pst->top)//创建一个数组,同时还能达到扩容的效果
{
int newcapacity = pst->capacity == 0 ? 4 : 2 * pst->capacity;//三目操作
STDataType* temp = (STDataType*)realloc(pst->arr,sizeof(STDataType*) * newcapacity);//在arr指针指向空的时候,realloc也具有malloc的效果
if (temp == NULL)//检查开辟空间是否成功
{
perror("STPush");
return;
}
pst->arr = temp;//若开辟成功,则将开辟好的空间给到arr指针
pst->capacity = newcapacity;//更新数组大小
}
pst->arr[pst->top] = x;//压栈操作,将数组压进数组(栈)内
pst->top++;//更新top至下一个位置
}4、出栈操作
出栈操作就很简单了,因为出栈意味着将该元素移出数组,而且栈遵循先入先出,数组最先进来的元素肯定是末尾的元素,因此直接将末尾的元素“删除”即可,但是我们知道数组不存在删除一个元素的说法,因此使用top--的方式,让top往前移一位,等到下次压栈新的元素会覆盖出栈的元素,达到出栈的效果。
这里有一个细节:进行出栈操作的时候要注意此时栈不能为空,因此特意写一个对栈判空的函数,判空函数如下:
bool Empty(ST* pst)
{
assert(pst);
return pst->top == 0;//如果栈为空则返回真
}出栈代码如下:
void STPop(ST* pst)//出栈
{
assert(pst);
//若Empty函数为空返回真,这里对其结果取非就可以达到检查栈是否为空的效果
assert(!Empty(pst));//断言使用函数Empty返回值进行判空
pst->top--;//top--之后,下一次新的数据压栈会覆盖原来的数据
}5、显示栈顶元素
显示栈顶元素就很简单了,直接返回数组末尾的元素即可,因为数组末尾等于栈顶。这里也要注意若调用此函数则栈不能为空,因为栈为空了也就不存在栈顶元素。
显示栈顶元素代码如下:
STDataType STtop(ST* pst)//显示栈顶元素
{
assert(pst);
assert(!Empty(pst));//判空
return pst->arr[pst->top - 1];//数组末尾即top的位置减1
}6、显示栈空间内元素的总个数
之所以让top指向栈顶元素的后一位的好处:此时top的值就是栈空间的元素总和,因此直接返返回top的值即可。
栈元素总和代码如下:
STDataType STsize(ST* pst)//显示栈的所有元素的个数
{
assert(pst);
return pst->top;
}这里跟前面的情况不一样了,栈为空表示栈里一个元素没有,即为0,因此无需对栈进行判空。
7、释放栈空间
栈空间是在堆上申请而来的,因此使用完之后应该手动释放。
释放栈空间代码如下:
void STDestroy(ST* pst)//释放空间
{
assert(pst);
free(pst->arr);//释放arr,也就是栈的空间
pst->capacity = 0;
pst->top = 0;
}8、测试栈
在准备了栈的各个功能,接下来就对这些功能进行测试。
测试代码如下:
#include"stack.h"
test1()
{
ST st;//创建一个结构体变量st,其实操作栈就是通过操作该结构体st中的指针arr实现的
STInit(&st);//初始化,传st的地址,这样就能够通过其地址对st里的成员进行操作
STPush(&st, 1);//压栈
STPush(&st, 2);
STPush(&st, 3);
STPush(&st, 4);
printf("size:%d\n", STsize(&st));//打印栈空间内元素个数
while (!Empty(&st))
{
printf("%d ", STtop(&st));//打印栈顶元素
STPop(&st);//出栈
}
STDestroy(&st);//释放栈
}
int main()
{
test1();
return 0;
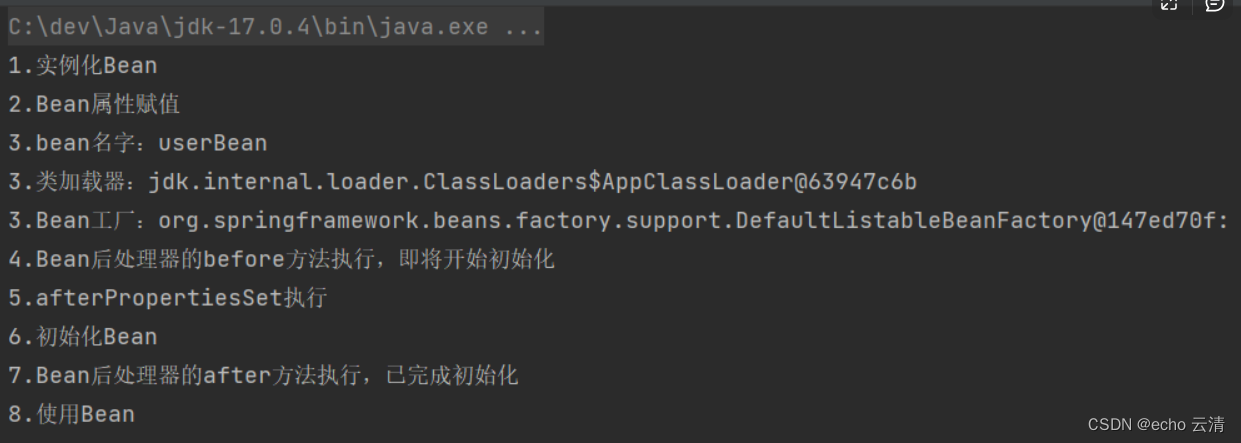
}运行结果:

从运行结果来看,出栈的顺序是4 3 2 1,而我们入栈的顺序是1 2 3 4,顺序刚好与栈的特点先入后出对应上。
二、队列
1、队列的概念
栈是只有一个端口可以进行输入输出数据,而队列是有两个端口可以操作,其中一个端口进行的是输入数据,也叫入队。另一个端口进行输出数据(删除数据),叫出队。其中队列满足先进先出的准则,即数据从队尾进入,然后从队头输出。
1.2 队列的结构

举例说明:如果入队的顺序是1 2 3 4,那么出队的顺序也是1 2 3 4,与栈的特点相反。
接下来就使用代码来实现队列,分析队列的各个功能:入队、出队、显示队头数据、显示队尾数据、显示队列大小等功能。
2、队列的创建及初始化
首先因为队列涉及到两个端口的操作,因此用数组实现队列会遇到这样一个问题:即进行数组头部数据的更改。我们都知道如果操作数组头部数据的代价是很大的,因为要移动整个数组的元素,效率非常之低。
所以我们选择用单链表的结构实现队列,只不过此单链表被两个指针维护,一个是头指针,一个是尾指针,刚好对应队列的两个端口。头指针实现出队操作,尾指针实现入队操作。
队列的创建代码如下:
typedef int QueueDataType;//int类型重定义
typedef struct QNode//节点的结构体
{
struct QNode* next;//节点里的指针
QueueDataType data;//数据
}QNode;
typedef struct Queue//队列的结构体
{
struct QNode* head;//队列头指针
struct QNode* tail;//队列尾指针
int size;//队列数据的个数
}Queue;为什么会有两个结构体呢?第一个结构体是组成链表的节点的结构体。第二个结构体是因为要记录队列的头尾指针,和队列的大小,因此这三个变量放在一个结构体中很省事,调用起来也很方便,因此又创建了一个结构体。
队列的初始化代码:
void QueueInit(Queue* pq)//初始化
{
assert(pq);
pq->head = NULL;//最开始一个节点都没有,因此头指针置空
pq->tail = NULL;//尾指针也是如此
pq->size = 0;//最开始没有任何节点,因此队列数据个数为0
}3、入队
把链表的尾部看成队尾,因此入队操作从队尾开始进行,即尾插的概念。
入队代码如下:
QNode* BuyNode(QueueDataType x)//创建节点函数
{
QNode* newnode = (QNode*)malloc(sizeof(QNode));
if (newnode == NULL)
{
perror("BuyNode");
return NULL;
}
newnode->next = NULL;
newnode->data = x;
return newnode;
}
void QueuePush(Queue* pq, QueueDataType x)//入队
{
assert(pq);
QNode* newnode = BuyNode(x);//创建一个节点
//判断两种情况
if (pq->head == NULL)//1是链表为空时,尾插入的第一个数据也要改变head指针的指向
{
assert(pq->tail==NULL);
pq->head = pq->tail = newnode;//head和tail都指向newnode节点
}
else//2是链表中存在节点,则直接改变tail指针的指向即可
{
pq->tail->next = newnode;
pq->tail = newnode;
}
pq->size++;//入队成功后,队列数据个数+1
}4、出队
既然入队是在链表尾部实现的,那么出队就在链表的另一端口实现,即链表的头指针负责实现出队,用到的是头删的概念。既然是头删的概念,则需要注意链表为空的情况,因此需要对链表进行判空,判空的逻辑与上文栈判空逻辑一样。
出队代码如下:
bool Empty(Queue* pq)//判空函数
{
assert(pq);
return pq->head == NULL
|| pq->tail==NULL;//若头、尾指针都为空则返回真
}
void QueuePop(Queue* pq)//出队
{
assert(pq);
assert(!Empty(pq));//函数Empty返回值为真,则对其取非触发断言效果,则会报错
//两种情况
if (pq->head == pq->tail)//1是当链表只有一个节点的情况,需要将tail也置空
{
free(pq->head);
pq->head = pq->tail = NULL;
}
else//2是多个节点的情况,无需将tail置空,只需要将head指针更新
{
QNode* poi = pq->head;
pq->head = pq->head->next;
free(poi);
}
pq->size--;//删除完毕后链表中数据的个数-1
}5、显示队头、队尾数据
5.1 显示队头数据
队头就是头指针指向的节点,即返回头指针指向节点的数值即可。
代码如下:
QueueDataType QueueFront(Queue* pq)//显示队头数据
{
assert(pq);
assert(!Empty(pq));//链表判空,链表为空不能显示队头数据
return pq->head->data;//返回头指针指向节点的数值
}5.2 显示队尾数据
队尾就是尾指针指向的节点,因此直接返回尾指针指向的节点的数值即可。
代码如下:
QueueDataType QueueBack(Queue* pq)//显示队尾数据
{
assert(pq);
assert(!Empty(pq));//链表判空,链表为空不能显示队尾数据
return pq->tail->data;//返回尾节点的数值
}6、显示队列的数据个数
这里就体现出size的作用,直接返回size即可。
代码如下:
int QueueSize(Queue* pq)//显示队列大小
{
assert(pq);
return pq->size;
}7、释放队列
因为队列是由malloc在堆上申请的空间,因此使用完之后要手动释放。
释放代码如下:
void QueueDestroy(Queue* pq)//释放队列
{
assert(pq);
QNode* cur = pq->head;//cur指针代替head去遍历链表
while (cur)
{
QNode* poi = cur->next;//poi标记下一个节点的位置
free(cur);//释放cur指针指向的节点
cur = poi;//更新cur指针
}
pq->head = pq->tail = NULL;//最后head和tail都需要手动置空
pq->size = 0;//size重新置为0
}8、测试队列
测试一下写出来队列的各个功能,测试代码如下:
#include"Queue.h"
int main()
{
Queue p;//创建结构体p
QueueInit(&p);//结构体p的初始化
QueuePush(&p, 1);//入队
QueuePush(&p, 2);
QueuePush(&p, 3);
printf("%d ", QueueFront(&p));//查看当前队头数据
QueuePop(&p);//出队
QueuePush(&p, 4);
printf("size:%d\n", QueueSize(&p));//查看当前队列里数据的个数
while (!Empty(&p))//循环打印队头的数据
{
printf("%d ", QueueFront(&p));
QueuePop(&p);
}
QueueDestroy(&p);//释放队列
return 0;
}运行结果:
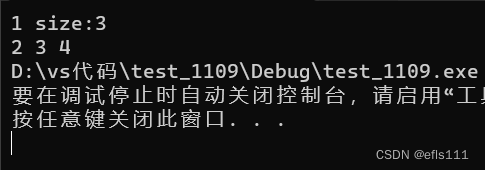
入队顺序是1 2 3 4。从结果来看,即使中途出队一个数据,整体出队的顺序还是没有改变, 出队顺序依然是1 2 3 4,符合队列的特点:先入先出。
结语:
以上就是关于栈和队列的实现与解析,希望本文可以带给你更多的收获,如果本文对你起到了帮助,希望可以动动小指头帮忙点赞👍+关注😎+收藏👌!如果有遗漏或者有误的地方欢迎大家在评论区补充~!!谢谢大家!!(❁´◡`❁)