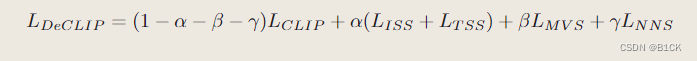Hink-on-Graph:基于知识图的大型语言模型的深层可靠推理
- 摘要
- 1 引言
- 2 方法
- 2.1图上思考
- 2.1.1图的初始化
- 2.1.2 探索
- 2.1.3推理
- 2.2 基于关系的Think on graph

摘要
尽管大型语言模型(LLM)在各种任务中取得了巨大的成功,但它们经常与幻觉问题作斗争,特别是在需要深入和负责任的推理的场景中。这些问题可以通过在LLM推理中引入外部知识图(KG)来部分解决。在本文中,我们提出了一个新的LLM-KG集成范式“LLM KKG”,它把LLM作为一个代理,以交互式地探索相关的实体和KGs上的关系,并进行推理的基础上检索到的知识。我们通过引入一种称为图上思维(ToG)的新方法进一步实现了这种范式,其中LLM代理迭代地在KG上执行波束搜索,发现最有希望的推理路径,并返回最可能的推理结果。我们通过一系列精心设计的实验来检验和说明ToG的以下优点:
- 1)与LLM相比,ToG具有更好的深度推理能力;
- 2)ToG通过利用LLM推理和专家反馈,具有知识可追溯性和知识可纠正性;
- 3)ToG为不同的LLM、KG和提示策略提供了一个灵活的即插即用框架,而不需要任何额外的训练成本;
- 4)在某些场景下,具有小LLM模型的ToG的性能可以超过诸如GPT-4的大LLM,这降低了LLM部署和应用的成本。
作为一种具有较低计算成本和较好通用性的免训练方法,ToG在9个数据集中的6个数据集中实现了整体SOTA,而大多数以前的SOTA依赖于额外的训练。
1 引言
大型语言模型(LLM)在各种自然语言处理任务中表现出了卓越的性能。这些模型利用了应用于大量文本语料库的预训练技术,以生成连贯和上下文适当的响应。尽管LLM具有令人印象深刻的性能,但在面对复杂的知识推理任务时,LLM具有很大的局限性,需要深入和负责任的推理。
- 首先,LLM通常无法提供准确的答案,要求专业知识超出预培训阶段(图1a中的过时知识),或者需要长逻辑链和多跳知识推理的问题。
- 其次,LLM缺乏责任感,可解释性和透明度,担心出现幻觉或错误文本的风险。
- 第三,LLM的培训过程通常昂贵且耗时,使其知识保持最新具有挑战性。
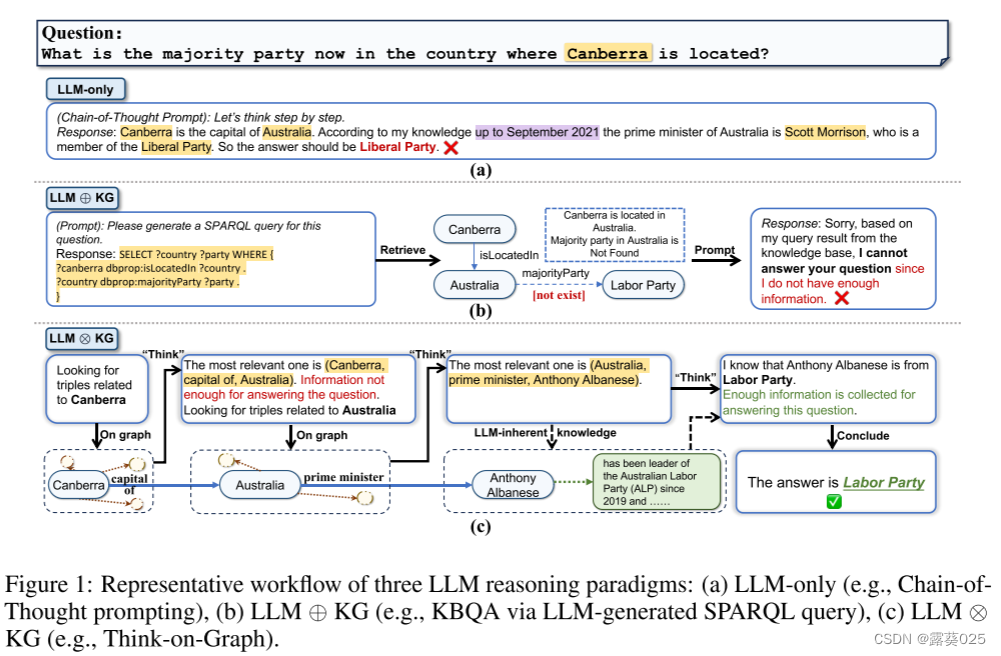
认识到这些挑战,一个自然和有前途的解决方案是结合外部知识,如知识图(KG),以帮助改善LLM推理。KG提供了结构化的、明确的和可编辑的知识表示,提出了一种补充策略来减轻LLM的局限性。研究人员探索了使用KG作为外部知识来源,以减轻LLM的幻觉。
这些方法遵循常规:从KG检索信息,相应地增加提示,并将增加的提示输入LLM(如图1b所示)。在本文中,我们将这种范式称为“LLM⊕LKG”。虽然LLM的目的是整合的力量和KG,在这个范式中,LLM扮演翻译器的角色,将输入的问题转换为机器可理解的命令KG搜索和推理,但它不直接参与图推理过程。不幸的是,松耦合LLM⊕KG范式有其自身的局限性,其成功在很大程度上取决于KG的完整性和高质量。例如,在图1b中,尽管LLM成功地识别了回答问题所需的必要关系类型,但关系“majority party” 的缺失导致检索正确答案的失败。
基于这些考虑,我们提出了一个新的紧耦合的“LLM ⊕ KG”范式,其中KG和LLM协同工作,在图推理的每个步骤中相互补充。图1c提供了一个示例,说明了LLM ⊕ KG的优势。在这个例子中,导致图1b中失败的缺失关系“多数党”可以由具有动态推理能力的LLM代理发现的参考三元组(澳大利亚,总理,Anthony Albanese)补充,以及安东尼艾博年的政党成员来自法学硕士的固有知识。通过这种方式,LLM成功地利用从KG检索的可靠知识生成正确答案。作为这种范式的实现,我们提出了一个算法框架“图上思考”(意思是:LLM“思考”沿着推理路径”知识“图”一步一步,以下简称为ToG),深入、负责、高效的LLM推理。在KG/LLM推理中使用波束搜索算法。ToG允许LLM在KG中动态探索许多推理路径并相应地做出决策。给定输入问题,ToG首先识别初始实体,然后迭代地调用LLM以通过探索(经由“在图上”步骤在KG中寻找相关三元组)和推理(经由“思考”步骤决定最相关的三元组)从KG检索相关三元组,直到信息足够通过波束搜索中的前N个推理路径来回答问题(由LLM在“思考”步骤中判断)或达到预定义的最大搜索深度。
ToG的优势可以概括为:
- (1) 深度推理:ToG从KG中提取多样的多跳推理路径作为LLM推理的基础,增强了LLM对知识密集型任务的深度推理能力。
- (2) 负责任的推理:显式的、可编辑的推理路径提高了LLM推理过程的可解释性,并能够跟踪和纠正模型输出的起源。
- (3) 灵活性和效率:
-
- a)ToG是一个即插即用的框架,可以无缝地应用于各种LLM和KG。
-
- b)在ToG框架下,知识更新可以通过KG来实现,而不是LLM,后者的知识更新昂贵且缓慢
-
- c)ToG增强了小型LLM的推理能力(例如,LLAMA 2 - 70 B)与大型LLM(例如,GPT-4)。
2 方法
ToG通过要求LLM在知识图上执行波束搜索来实现“LLM⊗KG”范式。具体地,它提示LLM迭代地探索KG上的多个可能的推理路径,直到LLM确定可以基于当前推理路径来回答问题。ToG不断更新和维护前N条推理路径P = {p1,p2,…,pN},其中N表示波束搜索的宽度。ToG的整个推理过程包括初始化、探索和推理3个阶段。
2.1图上思考
2.1.1图的初始化
给定一个问题,ToG利用底层LLM在知识图上定位推理路径的初始实体。该阶段可以被视为前N个推理路径P的初始化。ToG首先提示LLM自动提取所讨论的主题实体,并获得前N个主题实体E0 = {e01,e02,…,e0N}的问题。注意,主题实体的数量可能小于N。
2.1.2 探索
在第D次迭代开始时,每条路径pn由D-1个三元组组成,即pn ={(eds,n, rdj,n, edo,n)}D−1d=1。其中eds,n,和edo,n表示主体和客体实体,rdj,n是它们之间的特定关系,(eds,n, rdj,n, edo,n)和((ed+1s,n, rd+1j,n, ed+1o,n))彼此连接。P中的尾实体和关系的集合表示为ED-1 = {eD-11,eD-12,.,eD-1N }和RD−1 = {rD−11,rD−12,… ,rD−1N }。
第D次迭代中的探索阶段旨在利用LLM基于问题x从当前前N个实体集合ED-1的相邻实体中识别最相关的前N个实体ED,并使用ED扩展前N个推理路径P。为了解决使用LLM处理众多相邻实体的复杂性,我们实现了两步探索策略:首先发掘出有意义的关系,然后用所选择的关系指导实体发掘。
关系探索
关系探索是一个波束搜索过程,深度为1,宽度为N,从ED-1到RD。整个过程可以分解为两个步骤:搜索和修剪。LLM作为代理自动完成此过程。
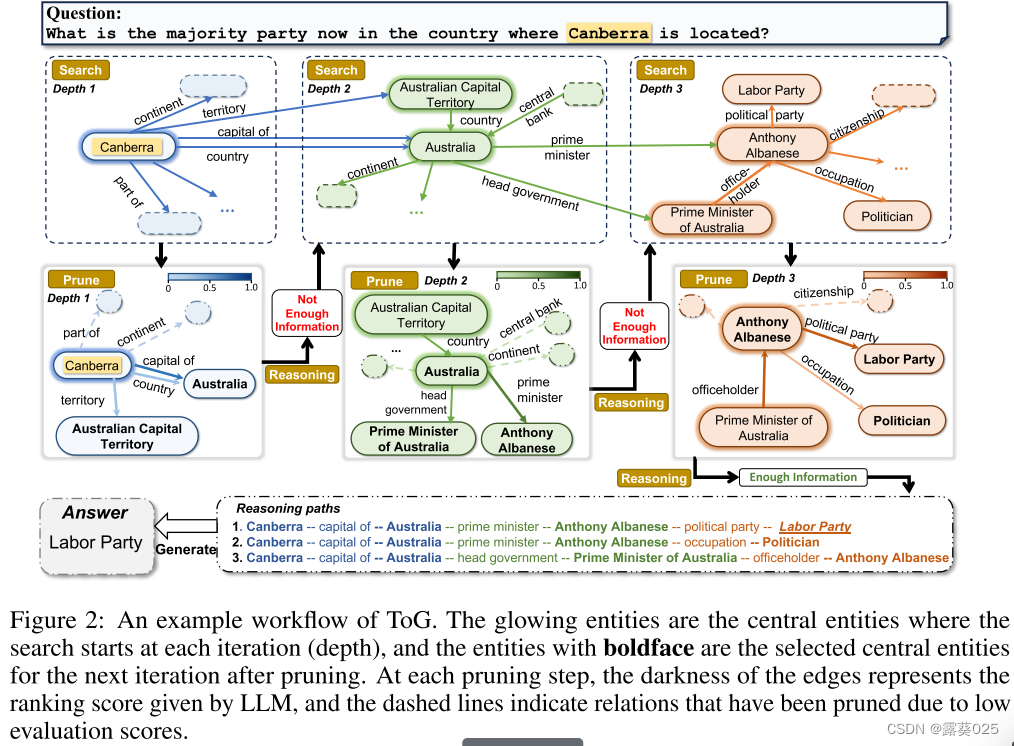
- 搜索 在第D次迭代开始时,关系探索阶段首先为每个推理路径pn搜索链接到尾实体eD-1n的关系RDcand,n。这些关系被聚合成RDcand。在图2的情况下,E1 = {堪培拉},R1cand表示向内或向外链接到堪培拉的所有关系的集合。值得注意的是,搜索过程可以通过执行附录E.1和E.2中所示的两个简单的预定义正式查询来轻松完成,这使得ToG能够很好地适应不同的KG,而无需任何培训成本。
- 剪枝 一旦我们已经从关系搜索中获得候选关系集RDcand和扩展的候选推理路径Pcand,我们就可以利用LLM基于问题x的文字信息和候选关系RDcand从Pcand中选出以尾部关系RD结尾的新的前N个推理路径P。此处使用的提示可参见附录E.3.1。如图2所示,LLM在第一次迭代中从链接到实体堪培拉的所有关系中选择前3个关系{capital of,country,territory}。由于堪培拉是唯一的主题实体,所以前3个候选推理路径被更新为{(堪培拉,首都),(堪培拉,国家),(堪培拉,领土)}。
实体探索 与关系探索类似,实体探索也是由LLM从RD到ED执行的波束搜索过程,并且包括两个步骤,搜索和修剪。
- 搜索 一旦我们已经从关系探索获得了新的前N个推理路径P和新的尾关系RD的集合,对于每个关系路径pn ∈ P,我们可以通过查询(eD-1n,rDn,?)或(?,rDn,eD−1n),其中eD−1n,rn表示pn的尾实体和关系。我们可以聚合
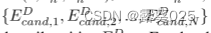
扩展为EDcand,并利用尾部实体EDcand扩展前N条推理路径P到Pcand。对于所示的情况,E1cand可以表示为{Australia,Australia,澳大利亚首都直辖区}。 - 剪枝 由于每个候选集合EDcand中的实体是用自然语言表达的,因此我们可以利用LLM来从Pcand中选择以尾部实体艾德结束的新的前N个推理路径P。此处使用的提示可参见附录E.3.2。如图2所示,澳大利亚和澳大利亚首都直辖区被评分为1,因为关系capital of、country和territory仅分别链接到一个尾实体,并且当前推理路径p被更新为{(堪培拉,capital of,Australia),(Canberra,country,Australia),(Canberra,territory,澳大利亚首都直辖区)}。
2.1.3推理
在通过探索过程获得当前推理路径P后,我们提示LLM评估当前推理路径是否足以生成答案。如果评估结果是肯定的,我们将提示LLM使用推理路径生成答案,并将查询作为输入,如图2所示。用于评估和生成的提示可在附录E.3.3和E.3.4中找到。相反,如果评估得到否定的结果,我们重复探索和推理步骤,直到评估是肯定的或达到最大搜索深度Dmax。如果算法还没有结束,这意味着即使在达到Dmax时,TOG仍然无法探索推理路径来解决问题。在这种情况下,TOG完全基于LLM中的固有知识来生成答案。TOG的整个推理过程包括D个探索阶段和D个评估步骤,以及一个生成步骤,最多需要2ND+D+1次LLM调用。
2.2 基于关系的Think on graph
先前的KBQA方法,特别是基于语义解析的KBQA方法,主要依赖于问题中的关系信息来生成正式查询。受此启发,我们提出了基于关系的ToG(ToG-R),其探索前N个关系链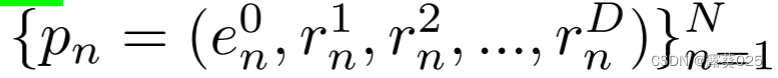
,从主题实体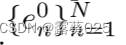 开始,而不是基于三元组的推理路径。ToG-R在每次迭代中依次执行关系搜索、关系修剪和实体搜索,这与ToG相同。然后ToG-R基于实体搜索获得的以EDcand结尾的所有候选推理路径执行推理步骤。如果LLM确定检索到的候选推理路径不包含LLM回答问题的足够信息,则我们从候选实体EDcand中随机采样N个实体,并继续进行下一次迭代。假设每个实体集合
开始,而不是基于三元组的推理路径。ToG-R在每次迭代中依次执行关系搜索、关系修剪和实体搜索,这与ToG相同。然后ToG-R基于实体搜索获得的以EDcand结尾的所有候选推理路径执行推理步骤。如果LLM确定检索到的候选推理路径不包含LLM回答问题的足够信息,则我们从候选实体EDcand中随机采样N个实体,并继续进行下一次迭代。假设每个实体集合 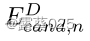 中的实体可能属于同一实体类并且具有相似的相邻关系,则修剪实体集合
中的实体可能属于同一实体类并且具有相似的相邻关系,则修剪实体集合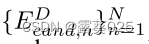 的结果可能对随后的关系探索具有很小的影响。因此,我们使用随机波束搜索代替ToG中的LLM约束波束搜索来进行实体修剪,称为随机修剪。算法1和2显示了ToG和ToG-R的实现细节。ToG-R最多需要ND +D + 1个到LLM的调用。与ToG相比,ToG-R提供了两个关键优势:
的结果可能对随后的关系探索具有很小的影响。因此,我们使用随机波束搜索代替ToG中的LLM约束波束搜索来进行实体修剪,称为随机修剪。算法1和2显示了ToG和ToG-R的实现细节。ToG-R最多需要ND +D + 1个到LLM的调用。与ToG相比,ToG-R提供了两个关键优势:
1)它消除了使用LLM修剪实体的过程,从而降低了整体成本和推理时间。
2)ToG-R主要强调关系的文字信息,当中间实体的文字信息缺失或不熟悉时,减轻误导推理的风险。