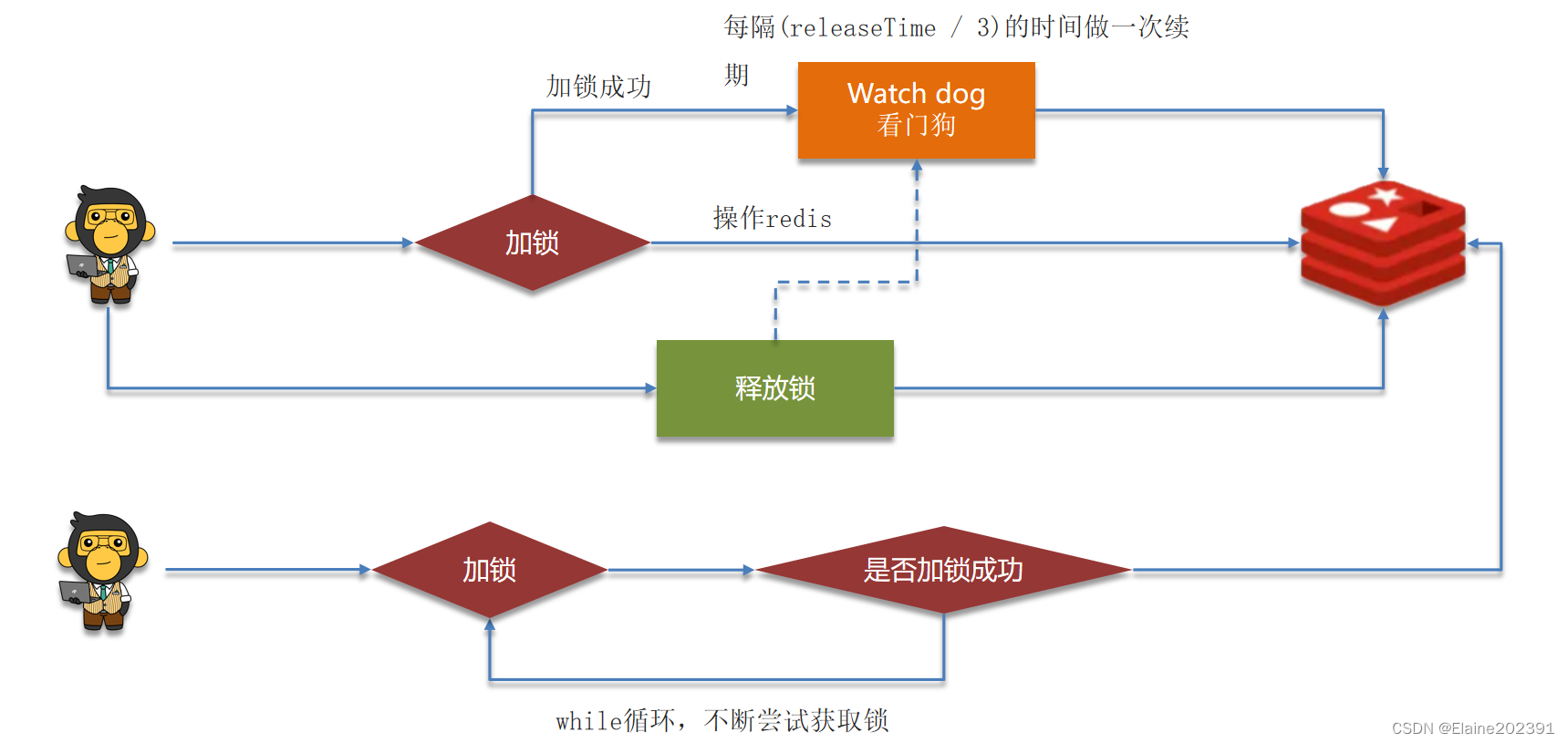
基于TM的低功耗语音关键字识别
- 摘要
- 1介绍
- 2TM的介绍
- 3KWS的音频预处理技术
- 4实验结果
- MFC4.1C设置
- 分位数数量
- 4.3增加关键词数量
- 4.4 声音相似的关键词
- 4.5 每个类别的子句数量
- 对KWS-TM的比较学习收敛和复杂性分析
摘要
在本文中,我们探讨了一种基于TM的关键词识别(KWS,以展示与NN(神经网络)相比更低的复杂性和更快的收敛速度。此外,我们研究了随着关键词数量的增加,TM的性能变化,并探讨了实现芯片上低功耗KWS的潜力。
1介绍
为了兼顾KWS的实时性和有效性,相比神经网络选择TM去实验。
2TM的介绍
参考以前的TM Book。
3KWS的音频预处理技术
通过MFCC进行特征提取,然后通过基于分位数的分箱进行离散化控制以进行布尔化。

在提取特征之前增加了预加重步骤,用于补偿人类声道的结构并提供初始的噪声过滤。在说话时产生声门音时,声道通过声道将较高频率的声音减弱,可以将其表征为信号频谱中的一个阶跃滚降。预加重步骤,正如其名字所示,增强(强调)高频区域的能量,从而导致信号的整体归一化。
接着是一系列的数据处理。
分箱,布尔化。
4实验结果
操纵窗口长度和窗口步长以控制生成的MFCC数量。
探索不同分位数箱的效果,以改变布尔特征的数量。
使用从2到9的不同数量的关键词,探索可扩展性。
测试声学不同和相似关键词对性能的影响。
通过操纵从句计算模块的数量,通过调整反馈控制参数s和T来优化性能,改变TM的大小。
MFC4.1C设置
控制窗口步长和窗口长度
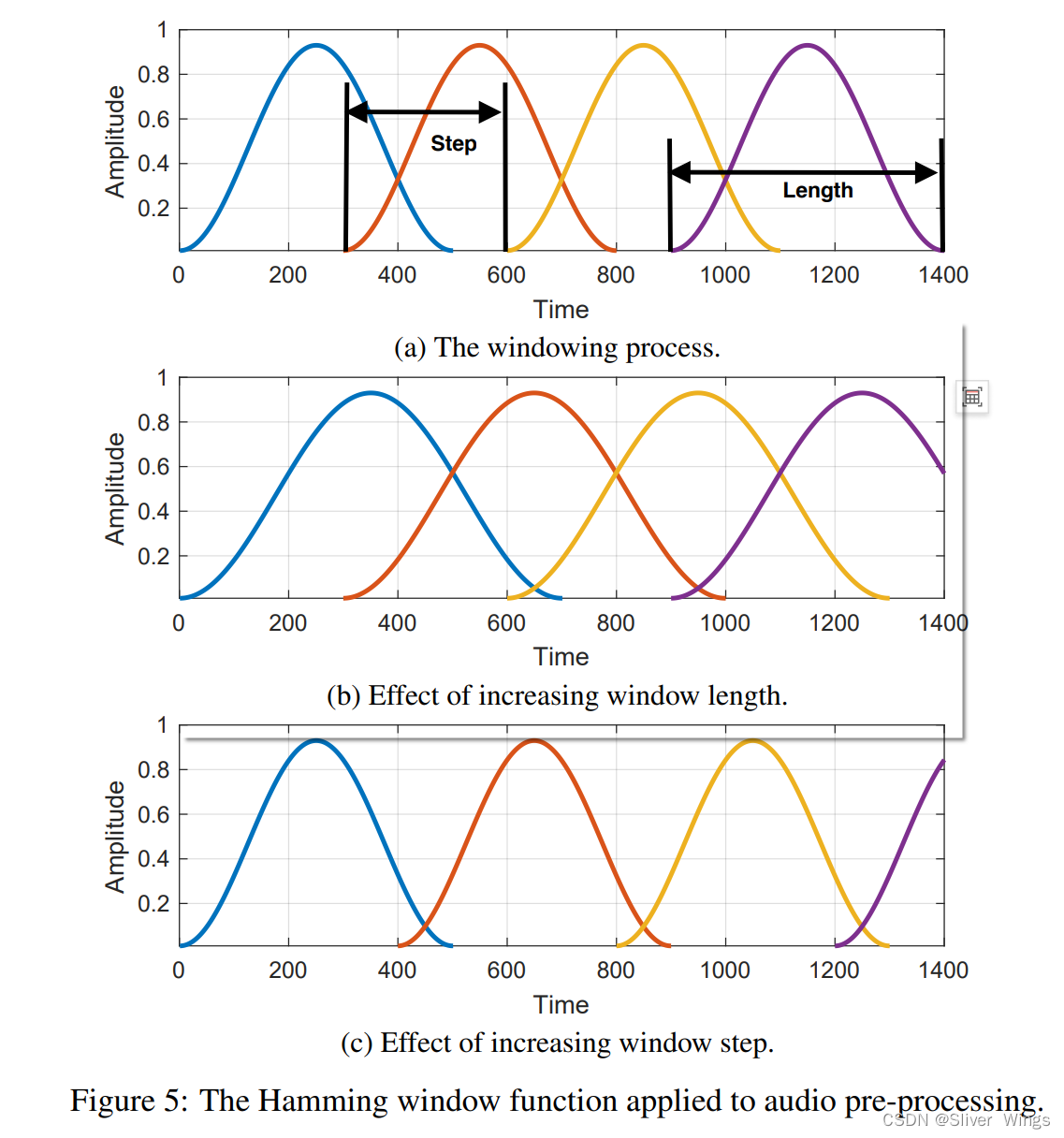
增加窗口步长非常有效,可以减少所有帧上的总MFCC系数的数量,但准确率下降。
分位数数量
4.3增加关键词数量
随着关键词数量的增加,训练、测试和验证准确性呈线性下降趋势。
4.4 声音相似的关键词
当类别重叠存在时,准确率下降。
4.5 每个类别的子句数量
通过大量从句可以实现非常高的准确性。
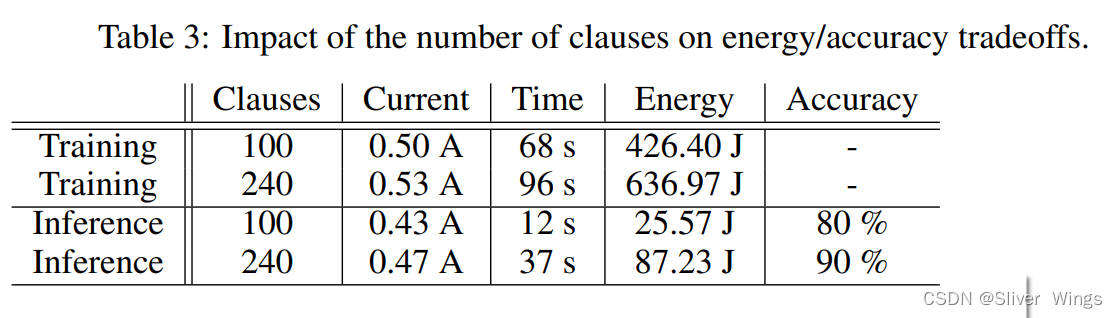
对KWS-TM的比较学习收敛和复杂性分析
更快的训练速度和更低的参数量。
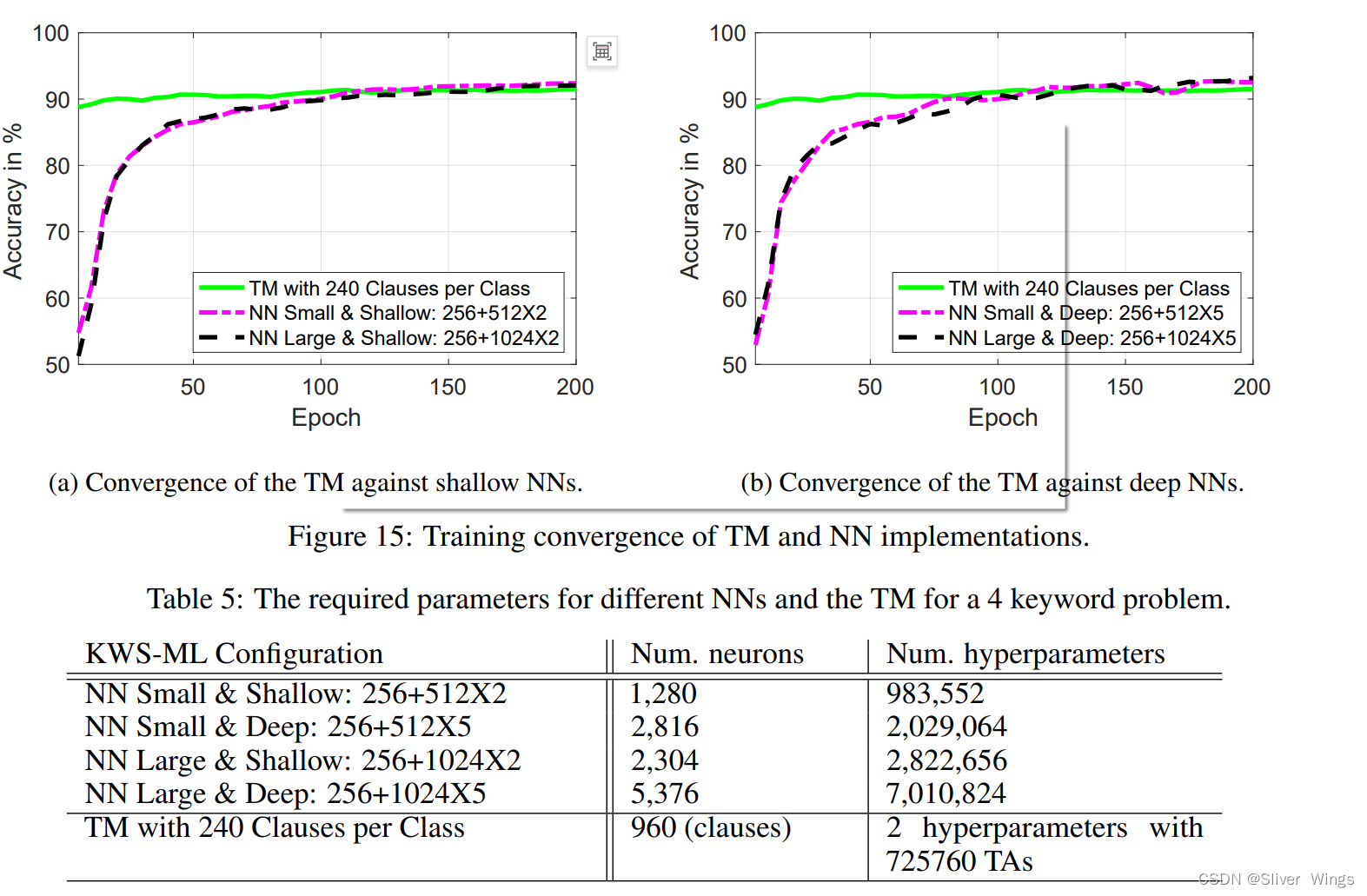
为未来在硬件加速器中实现更好的性能和低功耗的芯片级KWS提供了可能性。