2023-09 Python六级真题
分数:100
题数:38
测试时长:60min
一、单选题(共25题,共50分)
1. 以下选项中,不是tkinter变量类型的是?(D )(2分)
A.IntVar()
B.StringVar()
C.DoubleVar()
D.FloatVar()
答案解析:tkinter无FloatVar()变量类型。
2. 关于tkinter,以下说法错误的是?(B )(2分)
A.Label是签控件,可以显示文本和位图
B.Radiobutton是发送消息控件
C.Text是文本控件,用于显示多行文本
D.Button是按钮控件,在程序中显示按钮
3. 以下程序中,a= Spinbox(win1,from_=10,to=100)的作用是?( D)(2分)
from tkinter import *
win1= Tk()
a= Spinbox(win1,from_=10,to=100)
a.pack()
mainloop()A.生成10-100之间的随机数
B.只能选择10或者100
C.设置窗口尺寸为10x100
D.限制输入范围是10-100之间,包含10和100
答案解析:a= Spinbox(win1,from_=10,to=100)指定输入范围,包含首尾。
4. 编写一个程序,如下图所示,用于计算输入两个数的和,并通过窗口输出计算结果。空白处应补充的代码是?(D )(2分)
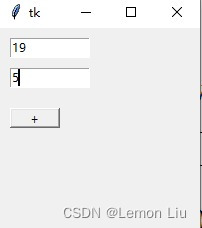
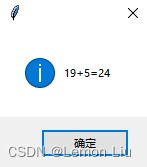
import tkinter as tk
import tkinter.messagebox
win=tk.Tk()
a=tk.IntVar()
b=tk.IntVar()
def jia():
a1=a.get()
b1=b.get()
tk.messagebox.showinfo(message=str(a1)+'+'+str(b1) +'=' + str(a1+b1))
c=tk.Entry(win,textvariable=a)
d=tk.Entry(win,textvariable=b)
ok=tk.Button(win,text='+',command=_________)
c.place(x=10,y=10,width=80,height=20)
d.place(x=10,y=40,width=80,height=20)
ok.place(x=10,y=80,width=50,height=20)
win.mainloop()A.add
B.plus
C.jia()
D.jia
5. 假设你正在开发一个电子商务网站,你需要存储用户订单信息。需要创建一个名为 orders 的表,下面哪个 SQL 语句最合适?(A )(2分)
A.CREATE TABLE orders (id INTEGER PRIMARY KEY, user_id INTEGER, product_name TEXT, quantity INTEGER, price REAL)
B.CREATE TABLE orders (user_id INTEGER, product_name TEXT, quantity INTEGER, price REAL)
C.CREATE TABLE orders (id INTEGER PRIMARY KEY, user_id INTEGER, product_name TEXT)
D.CREATE TABLE orders (id INTEGER, user_id INTEGER, product_name TEXT, quantity INTEGER, price REAL)
答案解析:选项A包含了所有必要的列(ID、用户ID、产品名称、数量和价格),并将ID列设置为主键。因此,正确答案是A。
6. 以下哪个Python代码片段正确地执行了一个SQL查询并获取了所有结果?( B)(2分)
A.
cursor.execute("SELECT * FROM students")
results = cursor.scroll()
B.
cursor.execute("SELECT * FROM students")
results = cursor.fetchall()
C.
results = cursor.execute("SELECT * FROM students").fetchone()
D.
cursor.begin("SELECT * FROM students")
results = cursor.fetchmany()
答案解析:正确答案:B。要执行一个SQL查询并获取所有结果,首先使用游标的execute()方法执行查询,然后使用fetchall()方法获取所有结果。
7. 在使用SQLite数据库时,游标的主要作用是?(D )(2分)
A.管理数据库连接
B.用于数据库的备份和恢复
C.储存数据库的表结构
D.执行SQL查询并获取结果
答案解析:正确答案:D。游标(Cursor)是SQLite数据库中用于执行SQL查询并获取结果的对象。游标可以执行各种SQL命令,如SELECT、INSERT、UPDATE和DELETE,并通过如fetchone()、fetchmany()、fetchall()等方法获取查询结果。
8. 给定以下 Python 代码,连接到一个 SQLite 数据库并查询表 students。请问,查询结果中包含多少个学生?(C )(2分)
import sqlite3
conn = sqlite3.connect(":memory:")
cursor = conn.cursor()
cursor.execute("""
CREATE TABLE students (
id INTEGER PRIMARY KEY,
name TEXT NOT NULL,
score INTEGER NOT NULL
);
""")
cursor.execute("INSERT INTO students (name, score) VALUES ('小明', 90)")
cursor.execute("INSERT INTO students (name, score) VALUES ('小芳', 85)")
cursor.execute("INSERT INTO students (name, score) VALUES ('轩轩', 92)")
cursor.execute("INSERT INTO students (name, score) VALUES ('乐乐', 88)")
conn.commit()
cursor.execute("SELECT * FROM students WHERE score >= 90")
result = cursor.fetchall()
conn.close()
print(result)A.0
B.1
C.2
D.3
答案解析:正确答案:C。该代码首先创建了一个 SQLite 数据库并创建了一个名为 students 的表。表中有4条学生记录,分别为小明、小芳、轩轩 和 乐乐。然后查询分数大于等于90的学生,结果为 小明 和 轩轩,共2个学生。
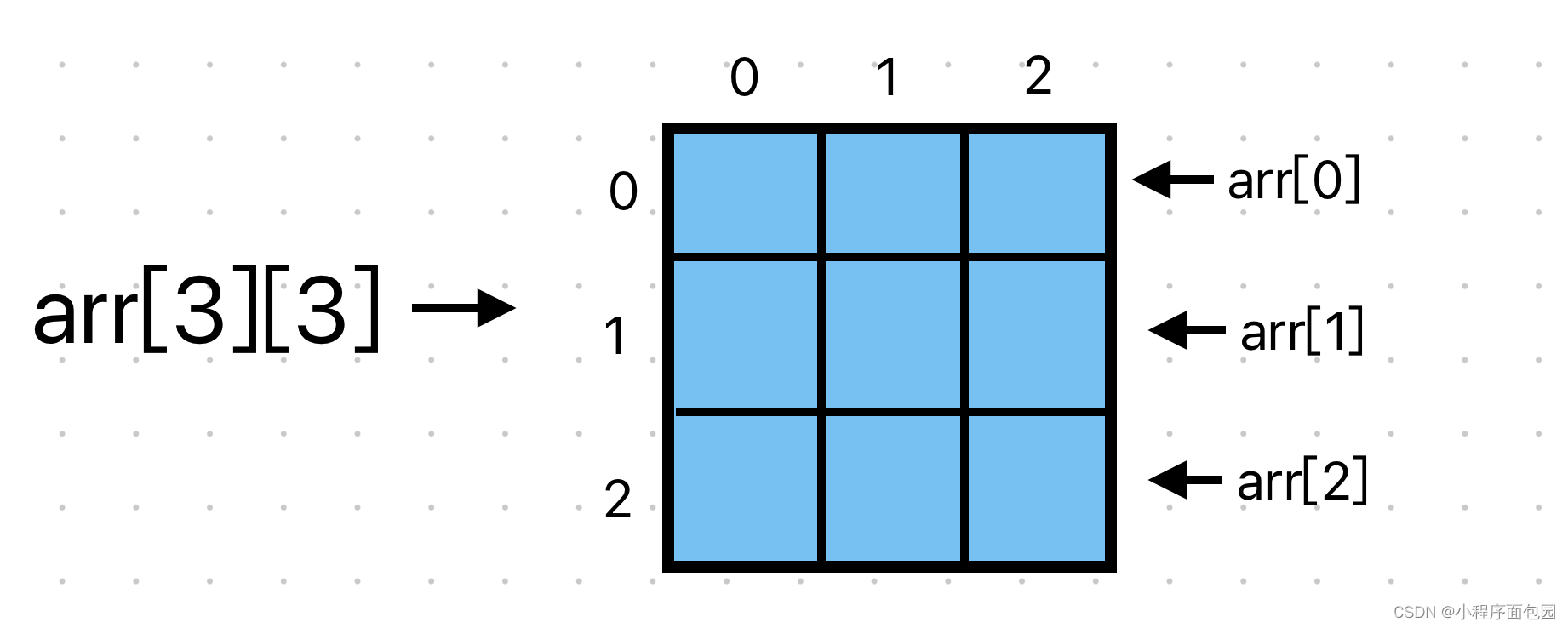
9. 在一个Python表示的二维数组b=[[3,5,9,4],[5,1,6,11],[2,1,6,6]]的第三列位置插入一列新的数据后,能够实现访问该数组中数据11的语句是?( D)(2分)
A.b[1][3]
B.b[2][3]
C.b[2][1]
D.b[1][4]
答案解析:题目要求插入的是一列数据,也就是在该二维数组中,每一行都多出一个数据,且该数据排列在第三位,也就是下标为2的位置上,原本在该位置的数据及其之后的数据都需要后移。原数组中数据11在b[1][3]的位置,所以后移后数据11的位置变为b[1][4]。
10. 假设有一个名为"Person"的类,如何创建一个名为"john"的类的实例?(C )(2分)
A.person = Person()
B.person = john.Person()
C.john = Person()
D.john = person.Person()
答案解析:使用类名后跟括号,可以调用类的构造函数创建实例。在这个例子中,使用"Person()"创建了一个名为"john"的实例。
11. 运行以下Python代码,结果是?(A)(2分)
class Person():
def __init__(self, name, age):
self.name = name
self.age = age
def say_hello(self):
print(f"Hello, my name is {self.name}. I am {self.age} years old.")
person1 = Person("Alice", 25)
person2 = Person("Bob", 30)
person1.say_hello() A.Hello, my name is Alice. I am 25 years old.
B.Hello, my name is Bob. I am 30 years old.
C.Hello, my name is Bob. I am 25 years old.
D.Hello, my name is Alice. I am 30 years old.
答案解析:代码中,定义了一个名为Person的类。这个类有一个初始化方法__init__,用于设置实例的属性name和age。还有一个类方法say_hello,用于打印实例的名字和年龄。然后,创建了两个Person类的实例person1和person2,并通过调用实例的方法say_hello来输出实例person1的信息。
12. 下面定义类的方法正确的是?(D )(2分)
A.def cat()
B.def Cat()
C.class cat()
D.class Cat()
13. 运行以下Python代码,结果是?(B)(2分)
class Parent():
def __init__(self, name):
self.name = name
def greetings(self):
print("Parent: Hi, I'm", self.name)
class Child(Parent):
def greetings(self):
super().greetings()
print("Child: Hello!")
parent = Parent("Alice")
child = Child("Bob")
child.greetings()A.
Parent: Hi, I'm Alice
Child: Hello!
B.
Parent: Hi, I'm Bob.
Child: Hello!
C.
Parent: Hi, I'm Bob
D.
Child: Hello!
答案解析:代码中,定义了一个Parent类和一个Child类,Child类继承自Parent类。Child类中的greetings方法使用super()函数调用了父类Parent的方法,并在其基础上添加了额外的逻辑print("Child: Hello!")。
14. 有如下Python程序段:
n=3
m=2
a=[[0 for i in range(n)] for j in range(m)]
a.append([0,0,n-m])
a.insert(-1,[n for i in range(n)])
print(a)执行程序后,下列选项中值为1的是?(B )(2分)
A.a[m][n]
B.a[n][m]
C.a[len(a)-1][0]
D.a[m][0]
答案解析:程序运行结束后,a的值为[[0,0,0], [0,0,0],[3,3,3],[0,0,1]]。选项B即a[3][2],值为1。
15. 利用Python列表创建一个二维数组,不正确的方法是?(C )(2分)
A.a=[[1,1,3],[2,6,7],[4,7,1]]
B.b=[[0 for i in range(3)] for j in range(2)]
C.c=[0]*4*4
D.d=[[0]*3,[9]*3,[4]*3]
16. 有如下Python程序段,执行程序后,输出的结果是?( A)(2分)
import csv
with open('123.csv', 'w',newline='') as f:
w=csv.writer(f)
w.writerows([('hello','world'), ('I','love','you')])
with open('123.csv', 'r') as f:
sp= csv.reader(f)
for row in sp:
print(row[0],end=',')A.hello,I,
B.hello,world
C.I,you
D.程序有误
答案解析:w.writerows([('hello','world'), ('I','love','you')])语句是对‘123.csv’文件写入两行内容,print(row[0],end=',')语句是将每行的第一个元素输出,所以选A。
17. 有如下Python程序段:
a=[1,2,3,5,6,8,9,11,15,0] #0表示该位置未存储元素
num=int(input( "输入需要插入的数据:"))
for i in range(len(a)):
if a[i]>num:
for j in range(len(a)-1,i-1,-1):
a[j]=a[j-1]
a[i]=num
break
else:
a[-1]=num
print(a)执行程序后,输入数字9,则位置下标发生改变的数据个数?(B )(2分)
A.3
B.2
C.1
D.0
答案解析:当数组arr中的元素arr[i]大于新数据num时,则将位置i及其之后的数据都向后移动,所以当输入的数字为9时,11大于num,则11和15的位置下标将发生改变。
18. 文件水果.txt中的内容如图所示:
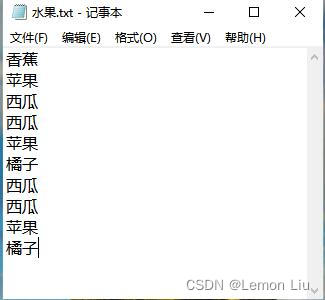
执行如下Python代码,输出的结果是?(C)(2分)
s={}
with open('水果.txt') as f:
a=f.readlines()
for i in a:
if i in s:
s[i]+=1
else:
s[i]=1
print(s["苹果"])A.1
B.2
C.3
D.4
答案解析:本题将读入的文件数据存放到字典s中,最后输出s["苹果"]的值,即苹果出现的次数,共3次。答案为C。
19. 执行如下代码:
fname = input("请输入要写入的文件:")
fo = open(fname, "w+")
ls=["清明时节雨纷纷,","路上行人欲断魂,","借问酒家何处有?","牧童遥指杏花村。"]
fo.writelines(ls)
fo.seek(0)
for line in fo:
print(line)
fo.close ()以下选项中描述错误的是?(C)(2分)
A.执行代码时,从键盘输入“清明.txt”,则清明.txt 被创建
B.代码主要功能为向文件写入一个列表类型,并打印输出结果
C.fo.seek(0)这行代码可以省略,不影响输出效果
D.fo.writelines(ls)将元素全为字符串的 ls列表写入文件
答案解析:答案为C 写入数据之后,光标停留在最后写入的位置,需要移到开头位置,以便于输出数据。
20. 对于二维数据文件fname,下面代码中的变量 x,以下选项中描述最合理的是?(D )(2分)
fo = open (fname, "r")
for x in fo:
print(x)
fo. close ()A.变量x表示文件中的一个字符
B.变量x 表示文件中的一组字符
C.变量x表示文件中的全体字符
D.变量x表示文件中的一行字符
答案解析:答案:D 读取文件按行读取,每次读取一行数据
21. 已知文件1.txt内容为:abcdefghijklmnopqrstuvwxyz,文件1.txt与程序文件保存在同一个目录,运行以下程序,输出结果是?( C)
with open("1.txt","r") as f:
f.seek(10)
print(f.read(1))A.j
B.a
C.k
D.l
22. 创建一个3*3的数组,下面代码错误的是?( B)(2分)
A.
import numpy as np
np.arange(0,9).reshape(3,3)B.
import numpy as np
np.random.random([3,3,3])C.
import numpy as np
np.eye(3)D.
import numpy as np
np.mat('1,2,3;4,5,6;7,8,9')答案解析:np.random.random([3,3,3]) 生成的是个三维数组,每个数组都是3行3列。
23.
import numpy as np
np.arange(16).reshape(4,4),求点(3,2)的值是?(A )(2分)
A.14
B.9
C.10
D.6
答案解析:(3,2)求的是索引位3的行,索引位2列的数,索引是从0开始,所求的值应该是位于数组的第4行第3列,故为14。
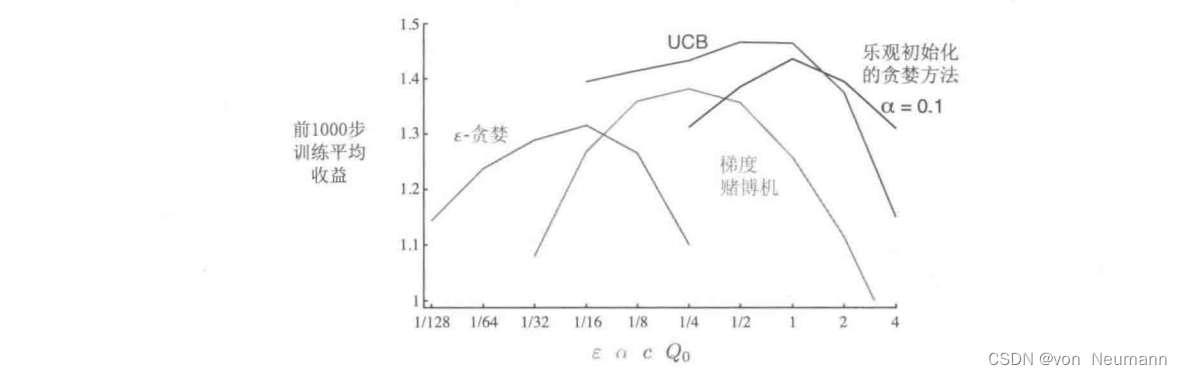
24. 有关数据可视化常用图表,下面说法错误的是?(C )(2分)
A.折线图用于查看因变量随自变量改变的趋势
B.柱形图直观展示对象之间数值的大小关系
C.散点图无法反映特征之间的统计关系
D.直方图比较直观地看出数据特征的分布状态
答案解析:散点图是使用坐标点的分布形态反映特征间统计关系的一种图形。
25. 关于matplotlib模块中函数的功能,下列描述正确的是?(A )(2分)
A.scatter()函数用于绘制散点图
B.bar()函数用于绘制折线图
C.plot()函数用于绘制水平柱形图
D.barh()函数用于绘制垂直柱形图
答案解析:scatter()函数用于绘制散点图,bar()函数用于绘制垂直柱形图,plot()函数用于绘制折线形图,barh()函数用于绘制水平柱形图,故选A。
二、判断题(共10题,共20分)
26. 运行以下程序,程序不会报错,将打开窗口,显示文字为"成功"。(错 )
from tkinter import *
messagebox.showinfo('提示信息','成功')答案解析:需要先导入tkinter.messagebox。
from tkinter import *
from tkinter import messagebox
messagebox.showinfo('提示信息','成功')
27. 在Python中,当不再需要使用SQLite数据库时,应关闭游标和数据库连接以释放资源。(对 )
答案解析:正确。应当在不再需要使用SQLite数据库时关闭游标和数据库连接。这可以通过调用游标的close()方法和数据库连接的close()方法来实现。这样做有助于避免资源泄漏和潜在的数据库问题。
28. 在Python中,子类可以调用父类的方法,并且可以通过重写父类的方法来修改其行为。(对 )
答案解析:在Python中,子类可以调用父类的方法,并且通过重写(覆盖)父类的方法来修改或扩展其行为。
29. 下列代码输出结果是10。( 错)
class MyClass():
class_attribute = 10
MyClass.class_attribute = 20
print(MyClass.class_attribute) 答案解析:代码中,定义了一个名为MyClass的类,并给它添加了一个类属性class_attribute,初始值为10。只需使用类名和属性名称进行赋值操作,语句MyClass.class_attribute = 20 修改类属性的值为20,最后结果输出20。 需要注意的是,修改类属性的值将影响到所有该类的实例对象。类属性是所有实例对象所共享的。
30. 在python的json库中,json.dumps 用于将 Python 对象编码成 JSON 字符串。( 对)
答案解析:json.dumps 用于将 Python 对象编码成 JSON 字符串。
31. 有如下Python代码:
import json
Data1 = '{"a":1,"b":2,"c":3,"d":4,"e":5}';
text = json.loads(Data1)
print(text)输出的text是dict类型数据。(对 )
答案解析:json.loads作用是将已编码的JSON字符串解码为Python对象,由代码可知text为字典类型。
32. 对文件进行读写操作之后必须关闭文件以防止文件丢失。(对 )
答案解析:对文件进行读写时,文件必需关闭否则会丢失读写数据。
33. 执行语句 f=open('demo.txt', 'r'),demo.txt 文件必须己经存在,否则会报错。(对 )
答案解析:执行语句 f=open('demo.txt', 'r') 在打开文件时,如果demo.txt文件不存在,将会抛出FileNotFoundError异常。
34. 使用 matplotlib.figure的作用是构建一张空白的画布,可以在空白的figure上直接绘图。(错 )
答案解析:在空白的画布上,需要使用add_subplot来创建子图。
35. 在用matplotlib绘图时,修改X轴、Y轴的标签和绘制的图形没有先后。(对 )
答案解析:在用matplotlib绘图时,修改X轴、Y轴的标签和绘制的图形没有先后。
三、编程题(共3题,共30分)
36. 钢筋问题
统计三角形数量及钢筋总长度。某工程需要很多由钢筋组成的三角形,在文本文件“data.txt”中每一行的三个数字分别表示三根钢筋的长度(整数,单位:厘米,数字间用空格隔开),若这三根钢筋能组成三角形,要求统计并输出三角形数量以及这些钢筋材料的总长度(若不能组成三角形则不对这些数据进行统计),文本文件数据如图a所示,程序运行界面如图b所示。

完成该任务的思路是:首先从文本文件“data.txt”读取文本内容到变量line,提取边长数据后,统计数据并输出结果。
相关代码如下,请补全代码:
def readfile(filename):
f = open(filename,encoding = "utf-8")
m=[]; n=[]; k=[]
line = f.readline()
while line:
x=line.strip().split(" ")
m.append(int(x[0]))
n.append(int(x[1]))
k.append(int(x[2]))
_____①_______
f.close()
return m,n,k
def triangle(x,y,z): # 判断数据x、y、z能否组成三角形
flag=False
if _____②_______:
flag=True
return flag
a,b,c=readfile("/data/ ______③_______ ") #读入文件
n=len(a);count=0;sum=0
print("能组成三角形的数据有:")
for i in range(n):
if ________④________:
sum+=a[i]+b[i]+c[i]
print(a[i],b[i],c[i])
count+=1
print("能组成三角形的共有:",count,"组")
print("共需要材料长度共是:",sum)参考程序:
def readfile(filename):
f = open(filename,encoding = "utf-8")
m=[]; n=[]; k=[]
line = f.readline()
while line:
x=line.strip().split(" ")
m.append(int(x[0]))
n.append(int(x[1]))
k.append(int(x[2]))
line = f.readline()
f.close()
return m,n,k
def triangle(x,y,z): # 判断数据x、y、z能否组成三角形
flag=False
if x+y>z and x+z>y and y+z>x:
flag=True
return flag
a,b,c=readfile("/data/data.txt") #读入文件
n=len(a);count=0;sum=0
print("能组成三角形的数据有:")
for i in range(n):
if triangle(a[i],b[i],c[i]):
sum+=a[i]+b[i]+c[i]
print(a[i],b[i],c[i])
count+=1
print("能组成三角形的共有:",count,"组")
print("共需要材料长度共是:",sum)评分标准:
(1)line = f.readline();(3分)
(2)x+y>z and x+z>y and y+z>x;(2分)
(3)data.txt;(2分)
(4)triangle(a[i],b[i],c[i])。(3分)
37. 工资管理
编写简单的工资管理程序,系统中包含工人(worker)和经理(manage),所有员工都有员工号、姓名、基本工资等属性。
工人:工人具有工作小时数和时薪的属性,工资计算方法为基本工资 + 工作小时数 * 时薪;
经理: 具有固定的月薪,计算方法为固定月薪。
根据以上的要求设计类,显示人员的信息和工资情况,运行结果如下:
工号:001,姓名:King,本月工资:10000
King的月薪是:10000
工号:002,姓名:Lily,本月工资:20000
Lily每天的工作时长:10小时
Lily的月薪是: 20000
class Person():
def __init__(self,id,name,salary):
self.id = id
self.name = name
______ ① _______
def __str__(self):#查看对象,触发执行print语句
msg = '工号:{},姓名:{},本月工资:{}'.format(self.id,self.name,self.salary)
return msg
class Worker(Person):
def __init__(self,id,name,salary,hours,per_hour):
super().__init__(id,name,salary)
self.hours = hours
self.per_hour = per_hour
def getSalary(self):
money = self.hours * self.per_hour
_____②______
return ______③________
class Manage(Person):
def __init__(self,id,name,salary,time):
super().__init__(id,name,salary)
self.time = time
def getSalary(self):
return self.salary,self.time
worker = Worker('001','King',2000,160,50)
sal = worker.getSalary()
print(worker)
print('King的月薪是:{}'.format(sal))
manage = Manage('002','Lily',20000,10)
_____④_____, work_time = manage.getSalary()
print(manage)
print('{}每天的工作时长:{}小时'.format('Lily',_______⑤________))
print('Lily的月薪是:',sal)标准答案:
class Person():
def __init__(self,id,name,salary):
self.id = id
self.name = name
self.salary = salary
def __str__(self):
msg = '工号:{},姓名:{},本月工资:{}'.format(self.id,self.name,self.salary)
return msg
class Worker(Person):
def __init__(self,id,name,salary,hours,per_hour):
super().__init__(id,name,salary)
self.hours = hours
self.per_hour = per_hour
def getSalary(self):
money = self.hours * self.per_hour
self.salary += money
return self.salary
class Manage(Person):
def __init__(self,id,name,salary,time):
super().__init__(id,name,salary)
self.time = time
def getSalary(self):
return self.salary,self.time
worker = Worker('001','King',2000,160,50)
sal = worker.getSalary()
print(worker)
print('King的月薪是:{}'.format(sal))
manage = Manage('002','Lily',20000,10)
sal,work_time = manage.getSalary()
print(manage)
print('{}每天的工作时长:{}小时'.format('Lily',work_time))
print('Lily的月薪是:',sal)评分标准:
(1)self.salary = salary;(2分)
(2)self.salary += money;(2分)
(3)self.salary;(2分)
(4)sal;(2分)
(5)work_time。(2分)
38. 考试成绩处理
将某班级的期末考试成绩存放于data.db数据库文件的score数据表内,部分成绩截图如下。
现要求求出english成绩大于或等于80的所有学生的总分平均分,并输出结果。(无需运行通过,写入代码即可)
import sqlite3
conn=sqlite3.connect("data.db")
cur=conn.cursor( )
sql="select * from score ______①______ "
cur.execute(sql)
______②______
conn.commit()
cur.close()
conn.close()
zf=0
for i in range(len(list1)):
zf+=sum( ______③_______)
pjf=zf/len(list1)
print("english大于或等于80分同学的总分平均分是",pjf)参考程序:
import sqlite3
conn=sqlite3.connect("data.db")
cur=conn.cursor()
sql="select * from score where english >=80"
cur.execute(sql)
list1 =cur.fetchall()
conn.commit()
cur.close()
conn.close()
zf=0
for i in range(len(list1)):
zf+=sum(list1[i][1:])
pjf=zf/len(list1)
print("english大于或等于80分同学的总分平均分是",pjf)评分标准:
(1)where english >=80或其他同等答案;(3分)
(2)list1 =cur.fetchall()或其他同等答案;(3分)
(3)list1[i][1:]或其他同等答案。(4分)




![文件上传 [ACTF2020 新生赛]Upload1](https://img-blog.csdnimg.cn/7614308207a84c67b39d215a4a7986e5.png)